






原文链接:https://doi.org/10.1109/tpami.2022.3231886
author={Xingxing Wei and Ying Guo and Jie Yu and Bo Zhang},
一、摘要
对抗补丁是一种重要的对抗攻击形式,它给深度神经网络的鲁棒性带来极大威胁.现有的方法要么通过在固定粘贴位置的同时优化其扰动值,要么通过在固定补丁内容的同时操纵位置来生成对抗补丁。这表明,位置和扰动对对抗性攻击都是重要的。为此,本文提出了一种新的方法来同时优化对抗补丁的位置和扰动,从而在黑箱环境下获得较高的攻击成功率。在技术上,我们将补丁的位置、预先设计的确定 补丁扰动的超参数作为变量,利用强化学习框架,以较少的查询次数同时求解基于从目标模型获得的奖励的最优解。在人脸识别(FR)任务上进行了大量的实验,在4个典型FR模型上的实验结果表明,该方法能够显著提高攻击成功率和查询效率。此外,在商用FR业务和物理环境下的实验验证了该方法的实际应用价值。将该方法扩展到交通标志识别任务中,验证了该方法的泛化能力。
二、介绍
深度神经网络(DNN)在许多任务中表现出出色的性能[1],[2],[3],但它们容易受到对抗性示例的影响[4],在这些示例中,向图像添加微小的不可感知的扰动可能会使网络混淆。然而,这种形式的攻击不适合于真实的应用,因为图像是通过相机捕获的,并且扰动也需要被捕获。一种可行的方法是使用局部斑块状扰动,其中扰动的大小不受限制。通过将对抗补丁打印出来粘贴在物体上,可以实现对真实的场景中的攻击。对抗补丁[5]给许多任务带来了安全威胁,如交通标志识别[6],[7],图像分类[8],[9],以及人员检测和重新识别[10],[11]。人脸识别(FR)是一项相对安全关键的任务,对抗补丁也已成功应用于该领域[12],[13],[14],[15]。例如,adv-hat [13]和adv-patch [12],[16],[17]将基于梯度生成的补丁放在额头,鼻子或眼睛区域以实现攻击。高级眼镜[14],[18]通过在眼睛处放置印刷的扰动的反射框架来混淆FR系统。上述方法主要集中在优化贴片的扰动,贴片的粘贴位置固定在基于先验知识选择的位置上。另一方面,adv-sticker [15]采用预定义的有意义的对抗补丁,并使用进化算法搜索好的补丁位置来执行攻击,这表明补丁位置是补丁攻击的主要参数之一。上述方法启发我们,如果位置和扰动同时优化,可以获得高的攻击性能。
然而,不能将同时优化视为这两个独立因素的简单组合。位置与扰动之间存在强耦合关系。具体地,实验表明,在面部上的不同位置处生成的扰动趋向于类似于当前面部区域的面部特征(在第3.1节中详细描述)。这说明这两个因素是相互联系、相互影响的。因此,它们应该同时优化,这意味着简单的两阶段方法或交替迭代优化不是最优的。另外,在实际应用中,目标FR模型的详细信息通常无法访问。相反,一些商业在线视觉API(如Face++和微软云服务)通常会返回上传的人脸图像的预测身份和分数。利用这些有限的信息,探索基于查询的黑盒攻击来构造对抗补丁是一种合理的解决方案。在这种情况下,同时优化将导致较大的搜索空间,并进一步给FR系统带来大量的查询。因此,如何设计一种有效的同时优化机制来解决这两个因素在黑箱环境下的优化问题成为一个具有挑战性的问题。
目前,一些工作[19]、[20]、[21]已经研究了位置和扰动的优化。位置优化[19]使用交替迭代策略来优化一个,同时在白盒设置下固定另一个。TPA [20]使用强化学习在黑盒设置中搜索合适的补片纹理和位置。它属于两阶段方法,由于补丁的图案来自于一组预定义的纹理图像,因此需要对目标模型进行数千次查询。GDPA [21]考虑了固有的耦合关系,通过生成器生成它们两者。然而,它是一种白盒攻击,并且还具有其他缺点,例如需要耗时的离线训练,以及仅处理连续参数空间的限制(详见2.1节)。因此,这些方法无法应对挑战。
基于上述考虑,本文提出了一种同时优化对抗补丁位置和扰动的有效方法,以提高有限信息下的黑盒攻击性能。对于扰动,补丁中每个通道的像素值范围从0到255,这导致搜索空间巨大,优化耗时。为了解决这个问题,我们首先减少搜索维度。具体地说,基于攻击的可转移性[22],我们利用在集成代理模型[26]上进行的修改的I-FGSM [23],[24],[25],并调整其超参数(即,攻击步长和每个代理模型的权重)来生成补丁的扰动。在此过程中,黑箱目标模型将被具有适当权重的集合代理模型很好地拟合,从而计算出的可传递扰动可以完美地攻击目标模型。与直接优化像素级扰动值相比,改变攻击步长和模型权值可以大大减小参数空间,提高求解效率。基于该设置,补丁的位置、补丁扰动的超参数(即,代理模型的权重和攻击步长)成为最终需要同时学习的关键变量。
为了搜索最优解,我们使用少量的查询目标模型,以动态调整上述可学习变量。这个过程可以被公式化为强化学习(RL)框架。从技术上讲,我们首先仔细设计每个变量的动作,然后利用基于Unet的代理[27]通过设计每个变量的输入图像和输出动作之间的策略函数来指导这种同步优化。最后根据策略函数确定动作。RL框架中的环境被设置为目标FR模型。通过与环境交互,智能体可以获得奖励信号反馈,以通过最大化该奖励来指导其学习[28]。请注意,我们的方法是一个在线学习过程,我们不需要提前训练代理。给定一个良性图像,代理从随机参数开始。每次迭代中的奖励将引导代理变得越来越好,直到实现攻击。整个方案如图1所示。
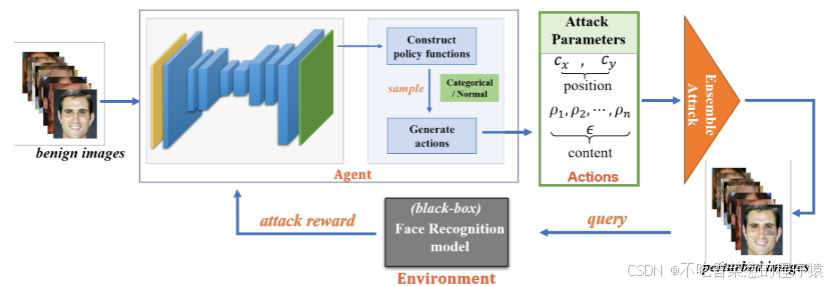
图1.综述了基于强化学习(RL)框架的位置和扰动同时优化方法。将良性镜像提供给代理,并由代理构造RL中的策略。在根据策略进行采样之后,确定针对攻击变量(动作)的具体解。通过集成攻击和对目标模型的查询,获得奖励,并在迭代过程中更新代理的参数。
生成的对抗补丁还可以以精心设计的方式与现有的梯度估计攻击方法[29],[30],[31]进行联合收割机组合,并为它们提供良好的初始化值。因此,可以降低梯度估计过程的高查询成本,并且进一步提高攻击成功率(参见5.3节)。除人脸识别外,该方法也适用于其他场景,如交通标志识别任务。实验在第6节中给出。
综上所述,本文有以下贡献:
·我们实证地说明了对抗补丁的位置和扰动同样重要,并且彼此密切相互作用。因此,利用互相关性,提出了一种有效的方法来同时优化它们,以生成黑盒设置中的对抗补丁。
·我们将优化过程公式化到RL框架中,并精心设计了Agent结构和相应的策略函数,以引导Agent高效地学习最优参数。
·在人脸躲避和模拟任务中的大量实验表明,该方法具有最佳的攻击性能和较高的查询效率(平均11次查询成功率高达96.65%),在商业API和物理环境中的实验证明了该方法的良好应用价值。
·为了显示所提出的方法的灵活性,我们将其与现有的梯度估计攻击方法相结合,以降低其高查询成本,提高攻击性能。此外,我们将所提出的方法扩展到交通标志识别任务,以验证其泛化能力。
三、相关工作
3.1Adversarial patch
与基于Lp范数的对抗性扰动相比,对抗性补丁[5]是一种更适合于现实世界应用的攻击形式,其中对象需要由相机捕获。与像素级不可感知的扰动不同,对抗性补丁不限制扰动的大小。到目前为止,对抗补丁已应用于图像分类器[8],[32],人员检测器[10],交通标志检测器[6],[7]以及许多其他安全关键系统。例如,对抗性T恤[10]通过在T恤的中心打印由优化框架中的梯度生成的补丁来逃避人检测器。[7]中的工作通过将生成对抗网络生成的补丁粘贴在交通标志的先前固定位置上来混淆交通标志检测系统。[6]中的工作通过在日常用品和交通标志上粘贴由鲁棒物理扰动算法生成的贴纸来攻击图像分类器和交通标志检测器。因此,对抗补丁已成为评估部署在真实的生活中的DNN模型鲁棒性的重要方法。
最近,Location-optimization [19]提出联合优化对抗补丁的位置和内容,但有三个局限性:(1)它们属于图像分类的白盒攻击,需要知道目标分类器的详细信息。(2)它们通过交替迭代优化两个因子,其中一个因子在另一个因子求解时是固定的,因此它不是同时优化。(3)在一个位置生成的图案通常更适用于该位置附近的区域。因此,在图案被优化之后,位置变化的范围是有限的,并且不能实现整个图像内的最优位置。作为比较,我们的方法可以更好地应对挑战。
另一篇相关论文在[20]中提出,其中作者通过类特定纹理的字典参数化对抗补丁的外观,然后使用像我们这样的强化学习优化每个补丁的位置和纹理参数。但我们与[20]的不同之处在于:(1)[20]中的位置和纹理没有同时解决。他们探索了一种两步机制,首先学习纹理字典,然后使用RL在字典上搜索补丁的纹理以及输入图像中的位置。这种单独的操作限制了性能。(2)由于公式的缺陷,[20]中的方法表现出较差的查询效率,而我们的方法只需要很少的查询就可以完成黑盒攻击。(3)[20]旨在攻击DNN分类模型,而我们的方法可以对人脸识别和交通标志识别进行攻击。此外,我们在物理世界中显示的有效性。因此,我们的方法比[20]更实用。
此外,GDPA [21]通过训练通用生成器来考虑同步优化,但仍然存在一些差异:(1)它是白盒攻击,其中生成器的训练需要获得模型的梯度信息。而我们的方法是一种黑盒攻击,更适用于真实的生活。(2)输出两个参数的生成器是离线训练的,并且只能用于目标模型和训练时指定的唯一目标标识。当攻击其他模型或其他身份时,生成器需要重新训练。相比之下,我们的方法是在线学习的,并且不限于预先指定的模型和身份。(3)它在连续参数空间中求解,但在某些情况下,有效位置值可能是不连续的(例如,在FR系统中,通常要求贴片位置不覆盖面部特征),并且我们的方法可以处理这种不连续的情况(第3.4节)。(4)在这种方法中,同时优化两个关键因素的动机是直观的,无需仔细分析,但我们提供了更详细的分析和一些可视化结果(第3.1节),以更好地探索这种耦合关系。
3.2Adversarial patch in the face recognition
对抗性补丁也给人脸识别和检测任务带来风险,其攻击形式大致可分为两类。一方面,有些方法是根据经验或先验知识将面片固定在人脸的特定位置上,然后产生面片的扰动。例如,对抗性帽子[13],adv-patch [16]和对抗性眼镜[14],[18]是针对面部识别模型的经典方法,这些方法通过将扰动贴纸放置在前额或鼻子上或将扰动眼镜放在眼睛上来实现。GenAP [17]优化了低维流形上的对抗补丁,并将它们粘贴在眼睛和眉毛区域。这些方法的主要关注点是主要集中在生成可用的对抗扰动模式,但没有考虑补丁的位置对攻击性能的影响。另一方面,一些方法固定对抗补丁的内容,并在面部的有效粘贴区域内搜索最佳粘贴位置。RHDE [15]利用真实的生活中存在的一种固定模式的贴纸,通过基于差分进化思想的RHDE算法改变其位置,对FR系统进行攻击。我们认为,对抗补丁的位置和扰动对攻击人脸识别系统同样重要,如果两者同时优化,可以进一步提高攻击性能。
3.3Deep Reinforcement Learning
深度强化学习(DRL)将深度学习的感知能力与强化学习的决策能力相结合,使智能体可以通过与环境的交互来做出适当的行为[28],[33]。它接收奖励信号,以评估通过代理采取的行动的性能,而无需任何其他监督信息,并可用于解决多个任务,如参数优化和计算机视觉[28]。在本文中,我们应用RL框架来解决的攻击变量,它可以形式化为使用奖励信号来指导智能体的学习过程。因此,一个精心设计的代理提出学习参数选择策略,并产生更好的攻击参数下,通过查询目标模型获得的奖励信号。
四、方法
4.1The interaction of positions and perturbations
为了理解位置和扰动之间的内在耦合关系,我们在1000张人脸图像上进行了实验。首先,在人脸不同区域的固定位置粘贴面片,观察其扰动的差异。为了使效果更明显,我们选择了靠近关键面部特征(即眼睛、眉毛、鼻子、嘴巴等)的位置,并且允许面部特征的小范围覆盖(不超过30个像素)。MI-FGSM [23]生成的两个示例如图2(a)所示。有趣的是,我们发现在人脸上不同位置产生的扰动往往与当前人脸区域的人脸特征相似,但它们的形状已经发生了变化。比如,在图2(a)的最上面一行,贴片贴在左眼附近的区域,生成的图案也像眼睛的形状,但与真实的身份的眼睛不同;在图2(a)的最下面一行中,对抗性贴片贴在左侧眉毛上,并且所产生的图案与眉毛的形状相似,其改变了眉毛的形状,并可能误导人脸识别网络对眉毛特征的提取。这些现象表明,补丁的图案与粘贴位置密切相关.图案往往是它们所处的面部区域的特征,并且补丁的图案在区域与区域之间变化很大。
然后,我们研究了补丁的粘贴位置与一个给定的模式的对抗性攻击。对于图2(a)中所示的补丁模式,我们穷尽地搜索它们的位置(即,补丁的中心点),可以实现对目标错误身份的成功攻击(见图2(B)),并发现对于这些给定的模式,可用的位置(橙子区域的脸)仍然集中在其原始粘贴位置附近。换句话说,在一个位置产生的图案往往只在该位置附近的小区域内具有良好的攻击效果。此外,我们还发现,当斑块的位置逐渐远离其原始位置时,目标错误身份的置信度得分会降低(颜色表示得分)。这表明补丁的最优位置与其模式密切相关,改变补丁的位置将导致不同的对抗性攻击效果。
因此,需要对这两个因素进行同时优化,以优化位置和扰动的匹配,从而在整个参数空间内实现攻击。然而,如上所述,同时优化将导致大的搜索空间,并进一步在黑盒攻击中给FR系统带来大量查询。因此,有效的同时优化是一个具有挑战性的问题。

图2.显示位置和扰动相互作用的例子。在(a)中,我们给出了两个通过固定面片位置同时优化其扰动而生成的例子。图片下方的黑色文字表示真实身份,红色文字表示攻击后的错误身份。在(B)中,我们给出了通过针对给定的固定扰动优化面片的位置而生成的两个例子。我们在面部图像中显示了可导致成功攻击的所有可用位置(橙子区域表示所有可用补丁的中心点),y轴中的t是错误的标识。
4.2Problem formulation
在人脸识别任务中,给定一个干净的人脸图像x,对抗攻击的目标是使人脸识别模型对受扰动的人脸图像xadv预测错误的身份。形式上,具有对抗补丁的扰动面可以用公式表示为Eq.(1)其中,λ是Hadamard乘积,λ x是整个人脸图像上的对抗扰动。A是一个二进制掩码矩阵,用于约束面片的形状和粘贴位置,其中面片面积的值为1。
![]()
以前的方法要么用预先固定的A来优化λ x,要么固定x λ来选择最优的A。在我们的方法中,我们同时优化了A和x,以进一步提高攻击性能。
对于掩模矩阵A的优化,我们固定A中的补丁区域的形状和大小,并改变补丁的左上坐标c =(cx,cy)以调整掩模矩阵。为了不干扰活性检测模块,我们将粘贴位置限制在不覆盖关键面部特征(即眼睛,眉毛,鼻子等)的区域。详情请参见第3.4节。
为了生成扰动,这里使用基于MI-FGSM [23]的集成攻击[26]。对于具有n个代理模型的集成攻击,我们让ρi表示每个代理模型fi的权重,并且让pi表示攻击步长。然后以非目标攻击(或人脸识别情况下的躲避)为例,给定地面真实身份y,我们让fi(x,y)表示模型预测人脸图像x为身份y的置信度得分,然后可以通过迭代的方式计算~x。设t表示第t次迭代,则:
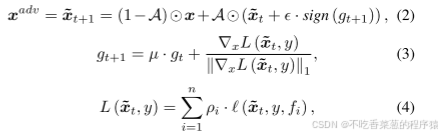
![]()
对于有针对性的攻击(或人脸识别情况下的模仿),给定目标身份y,可以简单地用fi( xt,y)替换。我们的攻击目标是同时优化补丁位置和扰动,以生成良好的对抗补丁来攻击目标模型。因此,补丁的坐标c =(cx,cy),攻击步长在方程中为(2)以及等式中的权重ρi。(4)被设置为学习变量。在下面的章节中,我们称之为攻击变量。为了适应目标模型,我们通过对目标模型的少量查询来动态调整攻击变量。
4.3Attacks based on RL
4.3.1Formulation overviewusing RL
在我们的方法中,优化攻击变量的过程被配制成学习代理的参数在RL框架的目标模型的奖励信号的指导下的过程。具体地,第t个变量的值被定义为代理在策略π的指导下在动作空间a中生成的动作at。输入到智能体的图像被定义为状态s,环境是目标模型F(·)。πθ(a| s)是策略函数,其输出是状态s下动作空间a中每个动作at对应的概率值。它服从一定的概率分布,是智能体用来决定采取什么行动的规则。
奖励反映了当前生成的对抗补丁在目标模型上的表现,智能体的训练目标是学习好的策略以最大化奖励信号。在人脸识别中,躲避攻击的目标是生成尽可能远离真实身份y的图像,而模仿攻击则希望生成尽可能与目标身份y相似的图像。因此,奖励函数R被形式化为:
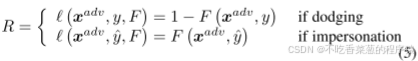
在迭代训练中,Agent首先根据策略π预测一组动作,然后生成基于预测动作的对抗补丁。最后将生成的对抗人脸图像输入到目标模型中获得奖励值。在这个过程中,策略梯度[34]用于指导代理的更新。经过多次训练迭代后,智能体将以很高的概率生成在目标模型上表现良好的动作。
4.3.2Design ofthe agent
agent需要学习位置、权值和攻击步长的策略。为了充分利用位置和扰动之间的耦合关系,需要将这两个因素同时映射到同一个智能体输出的特征图上。考虑到这一点,我们设计了一个基于U-net [27]的结构,它可以实现位置和图像像素之间的对应,并输出与输入图像相同大小的特征图。假设代理模型的数量为n,我们设计代理输出具有n个通道并且与输入图像相同长度h和宽度w的特征图(即大小为n × h ×w)。
在每个通道Mi(i = 1,...,n),每个像素点的相对值代表每个位置对于代理模型fi的重要性,而整个通道的平均值反映了相应代理模型的重要性。我们认为补丁在不同的位置需要不同的攻击强度,因此在代理网络的顶层,使用全连通层将特征图M映射到表示不同攻击步长值的向量V。agent的结构细节如图3所示。
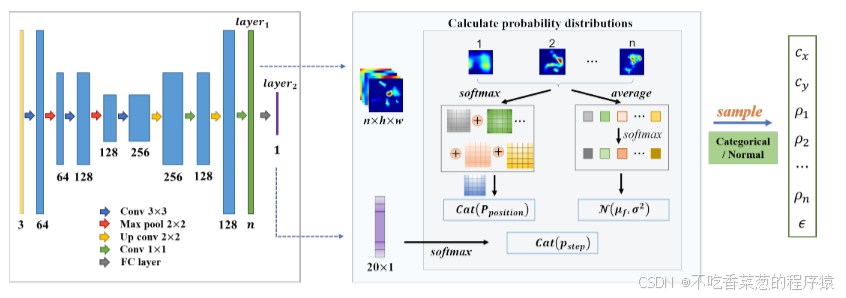
图3.所设计代理的详细信息。左侧显示了agent的网络结构。根据输出的特征图layer1和layer2,右图说明了如何利用它们来构建每个攻击变量的策略概率分布。
具体来说,对于位置动作,位置的可选范围是离散的,因此位置策略π1 θ被设计为遵循分类分布[35]。给定每个所选位置的概率Pposition,计算位置参数(cx,cy)和Pposition:
![]()
对于权重作用,每个代理模型fi上的损失与总体损失的权重比是一个连续值,并且我们将权重策略π2 θ设置为遵循高斯分布[35]。因此,第i个权重参数ρi ~N (µfi,σ2 )(i=1,...,n),μfi计算为:
![]()
其中,Mi是指特征图中第i个通道的平均值,σ是超参数。在实际的采样中,我们使用裁剪操作使权值之和等于1。
对于攻击步长,我们在0.01到0.2的范围内以0.01的间隔设置了20个值,并且由于这些值的离散性,采用分类分布[35]作为步长策略π3 θ。因此,步长参数 Cat(pstep)和每个候选值的概率pstep为:
![]()
通过从相应的分布中抽样,我们可以得到(cx,cy),ρi(i = 1,...,n)和n.
4.3.3 Policy Update
在Agent训练中,目标是使Agent hθ学习到一个好的策略πθ ={πi θ| i = 1,...,T}表示攻击变量的数量,并且在我们的情况下T = 3攻击变量是补丁位置(cx,cy),攻击步长(cy),在等式(1)中)。(2)在Eq.(4)分别)。τ =(s,a1,a2,...,aT)是根据当前代理的策略πθ采样得到的决策结果集合,并形式化为输入状态s和每个攻击变量的采样结果的集合,则最优策略参数θ可以公式化为:
![]()
我们使用策略梯度[34]方法通过梯度上升法求解θ J,并遵循REINFORCE算法[36],使用策略函数分布的N个采样的平均值来近似策略梯度∇θJ(θ):
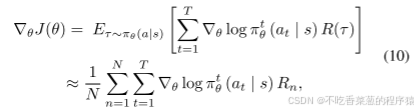
其中Rn是第n次采样的奖励。大的奖励会导致智能体参数θ沿着当前方向沿着有大的更新,而小的奖励则意味着当前方向不理想,相应的更新幅度也会很小。因此,智能体可以学习好的策略函数,θ在增加奖励的方向上更新。
对于遵循分类策略的操作,令p(a)表示动作a在相应的分类概率分布下的概率(即,Cat(Pposition)下位置变量的概率值p(a1),Cat(pstep)下攻击步长变量的概率值p(a3),则对于π1 θ和π3 θ,Eq.(10)可以计算为:
![]()
对于遵循高斯策略分布的动作(即遵循π2 θ的代理模型的权重),高斯分布的平均值µf由代理的输出计算,因此µf可以表示为hθ(s)= µf。因此,对于遵循高斯策略的π2 θ,|s)在Eq.(10)可按以下公式计算:
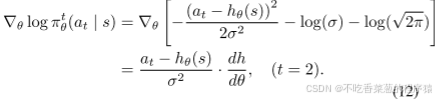
在使用Eq.(10),我们求解最优参数θ θ。从而得到最优的动作策略。
4.4 Optional area of the pasting positions
如何更改对抗补丁的粘贴位置

值得注意的是,为了不干扰活性检测模块,保持攻击方法的隐蔽性,不覆盖人脸面部特征的区域(如脸颊、额头)被视为可选粘贴区域。在实际应用中,活体检测模块常与人脸识别结合使用,确认对象的真实的生理特征,排除用照片、面具等代替真实的人脸的形式[37]。它主要是根据面部皮肤的深度或纹理特征或物体的运动(如眨眼和张嘴),因此补丁不能粘贴在覆盖面部特征的区域(如眼睛和嘴巴)。

图4.多组面及相应的有效粘贴区域。对于每一组,左边是面部图像,右边图像的白色部分代表有效区域。
具体来说,我们使用dlib库提取了81个人脸特征点,并确定了有效粘贴区域。图4示出了与面相对应的有效粘贴区域的一些示例。在计算了等式中的每个位置P位置的概率之后,(6),我们将无效位置的概率设置为0,然后对粘贴位置进行采样。
4.5 Overall framework
我们的方法的完整过程在算法1中给出。在Agent学习的K次迭代中,首先根据Agent的输出计算策略函数,然后根据策略函数的概率分布进行N次采样,生成N组参数。根据每组参数对代理模型进行攻击,生成的对抗性样本输入到人脸识别模型中获得奖励。策略函数最终根据奖励进行更新。在此过程中,如果攻击成功,迭代将提前停止。
5 COMBINED WITH GRADIENT ESTIMATION ATTACK
我们的同时优化方法也可以与梯度估计攻击(例如,零阶(ZO)优化[29],[38],自然进化策略[30],随机梯度估计[31]),以进一步提高攻击性能。梯度估计攻击通过查询模型获得的信息来估计每个像素的梯度。它具有良好的攻击性能,但查询代价高。同时优化的结果可以用作梯度估计的初始值,以提供良好的初始位置和图案。与原始梯度估计中使用的随机初始化相比,具有一定攻击性能的好的初始化值可以提高查询效率。在这里,我们以零阶(ZO)优化[29],[38]为例来描述组合方式。
在零阶优化中,设x表示图像变量,其值为迭代过程中的对抗图像。x的取值范围是[0,1]。为了扩大优化范围,x经常被替换为[29]:
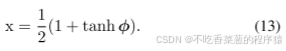
这样,优化x变成优化φ,优化范围扩大到[−∞,+∞]。梯度估计通过在φ处添加小偏移来实现,用于计算对称差商[29],[39]。为了使小偏移的添加对结果产生影响,φ不能处于解空间中的过度平滑的位置,即,x在φ处的梯度(即,φx)不能太小。计算公式如下:
![]()
为了使通过同时优化获得的梯度估计的初始值也满足上述要求,我们需要将此梯度要求添加到同时优化的目标函数中。因此,方程中的损失函数L(·,·)(4)修改为:
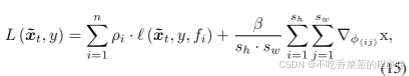
其中sh和sw表示粘贴到表面的扰动补丁的高度和宽度,β是比例因子。给定粘贴坐标(cx,cy),则在贴片的像素点(i,j)处
![]()
替换方程(4)等式(15),保持算法1中的其余过程不变,通过我们的同时优化,我们可以获得适合于梯度估计的对抗初始化结果(即模式x * 和位置c * x,c * y)。在此基础上,我们确定了位置c * x,c * y,并使用梯度估计方法仅对扰动进行精化。通过查询目标模型,我们可以估计第t次迭代中的梯度gt:
![]()
其中ε是小常数,et是标准基向量,其中选择用于更新的像素对应于值1。是损失函数,也就是说,等式的Δ(Δ xt,y,fi)的变体。(4)从x-空间迁移到φ-空间,通过查询模型得到结果。φ0 = arctanh(2 ·x − 1)。在此基础上,我们可以使用ADAM优化方法[29]来优化迭代过程中的图像像素值。由于良好的初始化值,在梯度估计攻击中的查询效率也将得到提高。
六 EXPERIMENTS
6.2.1Performance ofsimultaneous optimization

图5.同步优化过程不同阶段的示例。图像底部的黑色文字表示地面真实身份,红色文字表示攻击后的虚假身份。
图5显示了攻击不同阶段的位置和扰动的一些直观示例。我们可以看到,随着查询次数的增加,生成的敌对面片的位置和扰动逐渐稳定和收敛,直到人脸识别模型预测到目标的错误身份。实验结果表明:该文提出的调整方法具有很好的收敛性。图6显示了更多的可视化结果。对于每三个图像的组,第一个表示干净的图像,第二个表示攻击后的图像,第三个表示与人脸数据库中的错误身份相对应的图像。上述结果是通过确保补片没有粘贴到覆盖面部特征的区域而获得的。
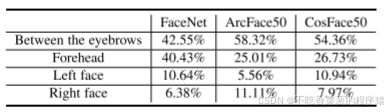
表3攻击FaceNet、ArcFace50和CosFace50时,眉毛之间、前额、左脸和右脸四个区域的补丁比例。
此外,我们还研究了斑块位置的规律性。我们将人脸分为四个区域:眉毛之间、前额、左脸和右脸,并在攻击FaceNet、ArcFace50和CosFace50时统计面片的位置。每个区域的斑块比例如表3所示。可以看出,对于三个模特来说,位于眉毛之间的贴片所占比例最高,分别达到了42.55%、58.32%、54.36%,其次是额头,而左右脸的比例相对较低。这可能是因为眉毛之间的位置靠近关键的面部特征(眼睛、眉毛),所以这些位置对模型的预测有较大的影响。
6.2.2Comparisons with SOTA methods
为了证明其优越性,我们将我们的方法与五种最先进的方法进行了比较:GenAP [17]和ZO-AdaMM [38]分别依赖于可转移性和梯度估计来固定位置和改变扰动。RHDE [15]固定扰动并且仅改变位置,并且位置优化(LO)[19]交替地优化位置和扰动,以及PatchAttack [20]以两步方式优化位置和扰动。在实现中,为了使位置优化(LO)[19]适应黑盒攻击,我们保留了交替迭代的框架,并使用梯度估计来代替白盒梯度计算。对于GenAP,由于我们利用它的可转移性进行黑盒攻击,所以它的NQ为零,我们用“-”来代替它。对于我们的方法,每列中的目标模型都不在相应的系综代理模型内(见表1),因此比较是公平的。三个目标模型的上述结果如表2所示。
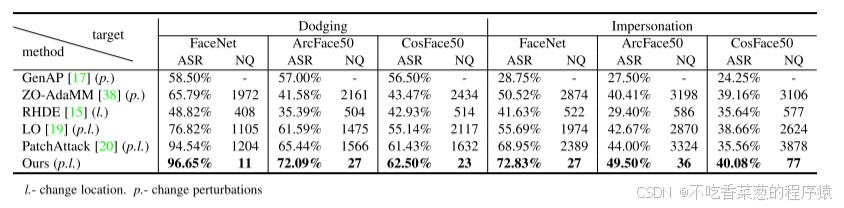
表2我们的方法与其他对抗补丁方法的ASR和NQ比较结果,这些方法仅通过位置固定的可转移性(GenAP)或梯度估计(ZO-AdaMM)来改变扰动,仅改变位置(RHDE)固定扰动,交替改变位置和扰动(LO)以及两步方式(PatchAttack)。
结果表明:(1)对于仅扰动方法,GenAP和ZO-AdaMM的平均成功率分别为42.08%和46.82%;对于仅定位方法,RHDE的平均成功率为38.97%。然而,LO、PatchAttack和我们的分别为55.10%、61.60%和65.61%。因此,考虑这两个因素可以实现显著的改善。(2)我们的同时优化优于LO的交替优化和PatchAttack的两步攻击,这表明同时优化可以更好地利用扰动和位置之间的内在联系,因此优于单独优化两者。(3)我们的方法实现了最佳的查询效率在几种方法中,只需要几十个查询。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









