






原文链接:A data independent approach to generate adversarial patches | Machine Vision and Applications
author={Xingyu Zhou and Zhisong Pan and Yexin Duan and Jin Zhang and Shuaihui Wang},
一、介绍
在图像识别领域,与数字域中的攻击相比,对抗性扰动在物理世界中攻击时遇到更多挑战:
(1)数字世界中的扰动可能非常小,由于传感器的不完善,相机不可能感知到它们。
(2)由许多当前算法产生的扰动是依赖于图像的。如果监控摄像头前的图像发生变化,攻击者需要立即产生相应的新扰动,这在物理攻击中很难实现。
(3)受扰动的图像难以在监控摄像机的视野中保持精确的距离和角度,这要求扰动对各种变换(例如旋转或缩放)和位置具有鲁棒性。
深度神经网络容易受到对抗性示例的影响,即,精心扰动的输入,旨在误导网络在推理时间。最近,对抗补丁,与扰动仅限于一个小的和局部的补丁,出现了在现实世界中的攻击,其容易获得。然而,现有的攻击策略需要在其上训练深度神经网络的训练数据,这使得它们不适合实际攻击,因为攻击者获得训练数据是不合理的。
为了解决这些缺点,我们提出了一种新的数据独立的方法来制作对抗补丁(DiAP)。DiAP的目标是生成一个对抗性补丁,可以在大多数图像上欺骗目标模型,而无需任何关于数据分布的知识。受GD-UAP [14]的启发,DiAP通过欺骗深度神经网络学习的特征来执行非目标攻击。换句话说,我们将其公式化为一个优化问题来计算非目标对抗补丁,它可以欺骗在深度神经网络的每一层上学习的特征,并最终将其错误分类为对抗示例。在生成非目标对抗补丁后,DiAP将其作为重要的背景项,以帮助攻击者提取目标类的特征,从而制作目标对抗补丁。实验结果表明,DiAP生成的对抗补丁具有较强的攻击能力.特别是,通过从非目标补丁中提取关于训练数据的模糊信息,DiAP在黑盒攻击场景中的性能优于最先进的攻击方法。
二、补充
对抗补丁下的对抗扰动:该模型被限制在一个小区域内,可以放置在输入图像上的任何地方。这种攻击基于这样一种假设,即机器学习模型的运行无需人工验证每个输入,因此恶意攻击者可能不关心其攻击的不可感知性。此外,即使人类能够注意到对抗性补丁,他们也可能将其视为一种艺术形式,而不是攻击深度神经网络的某种方式。
对抗补丁(GoogleAP):这些对抗补丁可以打印,添加到任何场景,拍照,并呈现给深度神经网络。即使补丁很小,深度神经网络也无法识别场景中的真实的对象并报告错误的类。对抗补丁是图像独立的,对于旋转和缩放是鲁棒的,可以放置在深度神经网络的视野内的任何地方,并使深度神经网络输出目标类。
三、针对非目标攻击的DiAP
在没有训练数据的情况下,我们欺骗在深度神经网络的各个层学习的特征,最终制作非目标对抗补丁pnt。为了实现这一目标,我们引入了伪激活损失的变体。特别地,训练非目标补丁PNT以优化伪激活目标函数
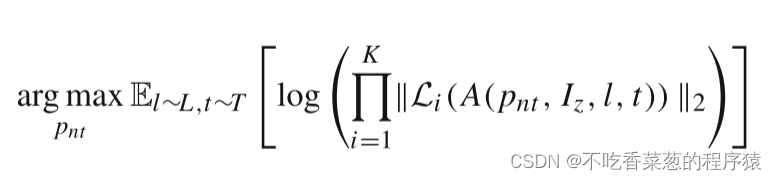
其中L是图像中的位置上的分布,并且T是补丁的变换上的分布。Iz是所有像素的RGB =[0,0,0]的背景图像。Li(A(pnt,Iz,l,t))是当图像A(pnt,Iz,l,t)被馈送到网络f时在层i处的输出张量。K是f中使A(pnt,Iz,l,t)引起的输出最大化的层数。所提出的目标计算产品的输出幅度在所有的各个层。注意,背景图像Iz的RGB值都为零,这不会误导深度神经网络各层提取的特征。因此,网络提取的错误特征实际上是由非目标对抗补丁pnt引起的。
我们希望补丁pnt在所有层上引起尽可能多的强干扰,以欺骗多层提取的特征并攻击网络,即等式中较大的E [·]。(2)PNT引起的污染越大。在训练过程中,补丁被转换,然后数字地插入到背景图像Iz上的随机位置上,并且我们优化Eq.(2)没有任何训练数据。

四、实验1
我们从三个方面对攻击进行了测试:(1)WhiteboxSingleModel攻击在单个模型上训练和评估单个补丁,并在上述模型上重复该过程。(2)白盒包围攻击在五个模型中联合训练单个补丁,然后通过平均所有这些模型的胜率来评估补丁。(3)黑箱攻击类似于leave one方法,在四个ImageNet模型上联合训练一个补丁,然后在第五个模型上评估黑箱攻击。
我们选择了13个缩放参数,即从1%到10%等间隔的5个点和从10%到50%等间隔的8个点。旋转角度限制在[− 45°,45 °]。Inception—V3针对白盒单模型攻击生成的补丁被重新缩放以覆盖10%的输入图像,然后随机旋转并放置在不同测试图像的随机位置。
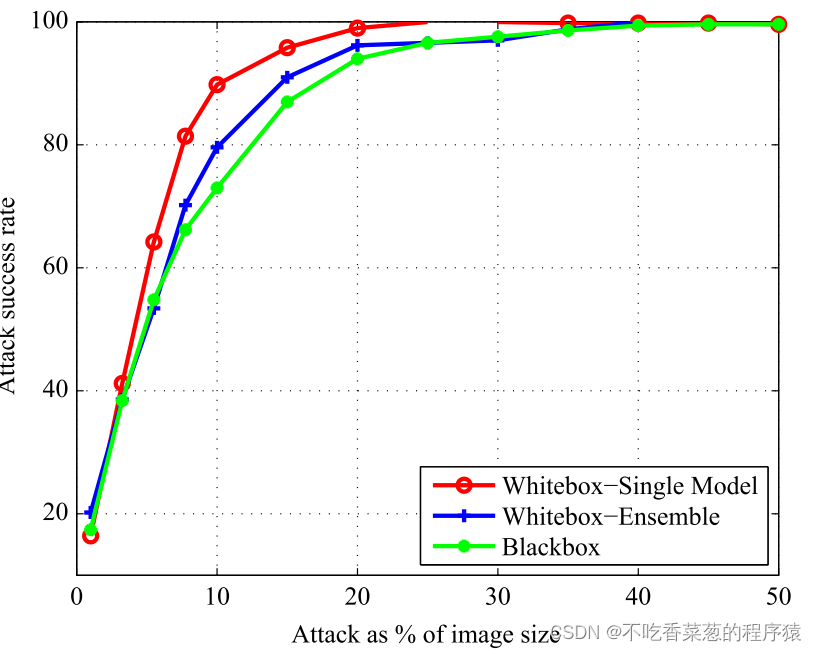
DiAP生成的非针对性对抗补丁的攻击成功率。图中的每个点都是通过平均1000个对抗性示例的结果来计算的,这些示例是通过将补丁应用于这些图像中随机位置的测试图像来制作的。
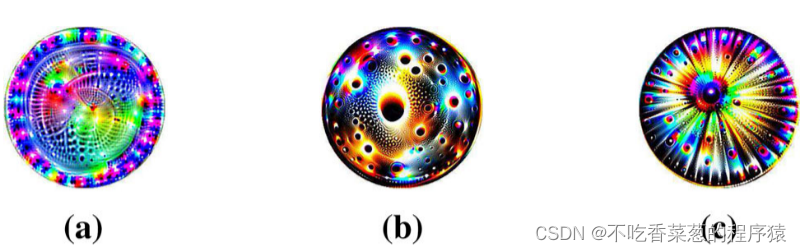
显示了为非目标攻击生成的一些补丁。这些补丁似乎都包含了很多小的圆形图案,并表现出一定的对称性。我们研究了由图4所示的对抗补丁制作的对抗样本的估计标签。当斑块覆盖10%的测试图像时,97.1%的与斑块(a)叠加的对抗性示例被分类为气泡,60.9%的被斑块(b)扰动的图像被识别为作为盐瓶或瓢虫,55.8%的图像被斑片(c)干扰后被识别为气泡或风车。通过优化Eq.(2)DiAP倾向于构造具有圆形模式的补丁,以增强对各种变换的鲁棒性,因此相应的对抗性示例更有可能被归类为圆形对象。
五、DiAP用于定向攻击

由Eq.(2)可以有效地攻击网络,并导致网络将许多对抗性示例识别为主导标签,这意味着补丁可能包含有关训练数据的一些信息。我们认为,这种先验知识有助于在没有训练数据的情况下生成目标补丁pt。为了制作这样一个PT,我们针对以下目标进行优化
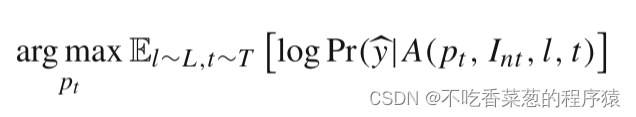

我们将A(pnt,Iz,l,t)作为背景图像。在训练期间,非目标块pnt被随机缩放和旋转,然后被数字地插入到图像Iz上的随机位置上以形成背景图像Int。接下来,目标块pt也被随机变换并数字地插入到背景图像Int上的随机位置上。
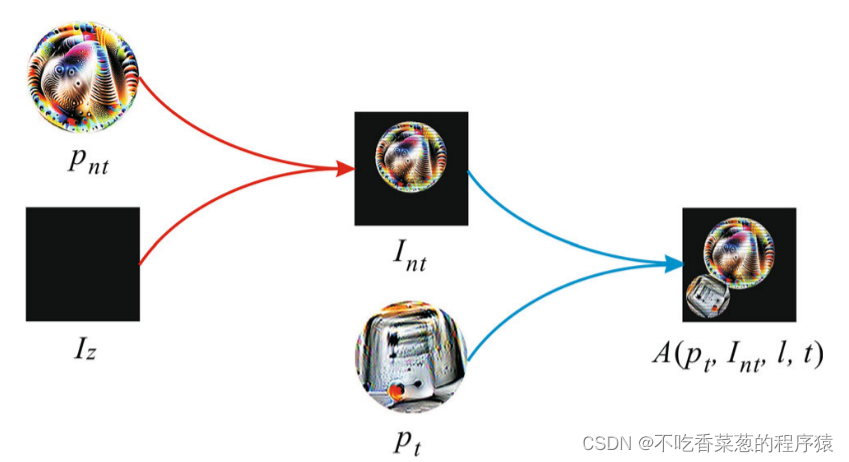
使用A(pnt,Iz,l,t)作为背景图像似乎很奇怪,因为它在等式2中表示。(2)训练非目标攻击补丁pnt。然而,如果我们意识到pnt可能包含关于训练数据的信息,尽管pnt不属于训练数据,这种方法是合理的。我们寻求一种有效的方法来使用非目标补丁pnt中隐含的信息(即优化方程。(4)),使得图像A(pt,Int,l,t)被评估为目标标签Pcky。最后,被目标补丁pt覆盖的对抗样本A(pt,x,l,t)被网络误分类为攻击。
六、实验2
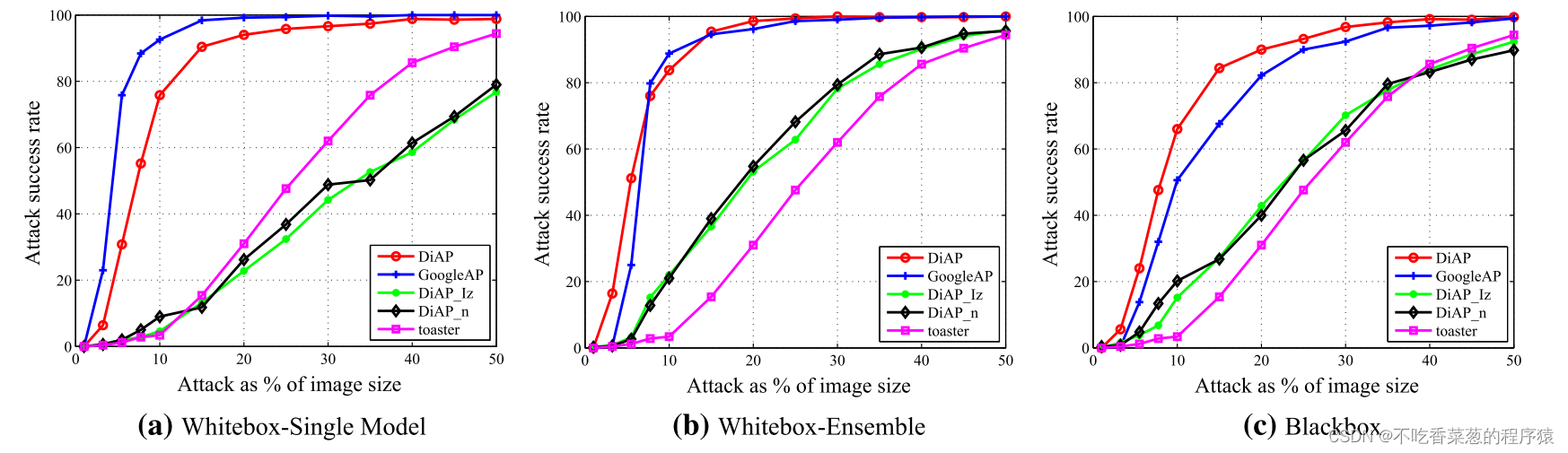
显示了针对性对抗补丁的攻击成功率,目标类是toaster。当补丁占图像大小的10%时,DiAP仍然可以实现约80%的攻击成功率。注意到DiAP完全不知道有关训练数据的任何信息,而GoogleAP使用训练示例进行优化,这个结果似乎违反直觉。我们假设,在不知道被攻击模型的结构(黑盒场景)的情况下,Int提供的关于训练数据的模糊信息使DiAP更具一般性,从而导致比GoogleAP更高的攻击成功率。这表明,当攻击者不熟悉被攻击模型时,关于训练数据的模糊信息可能比准确的示例知识更有利于生成攻击补丁。
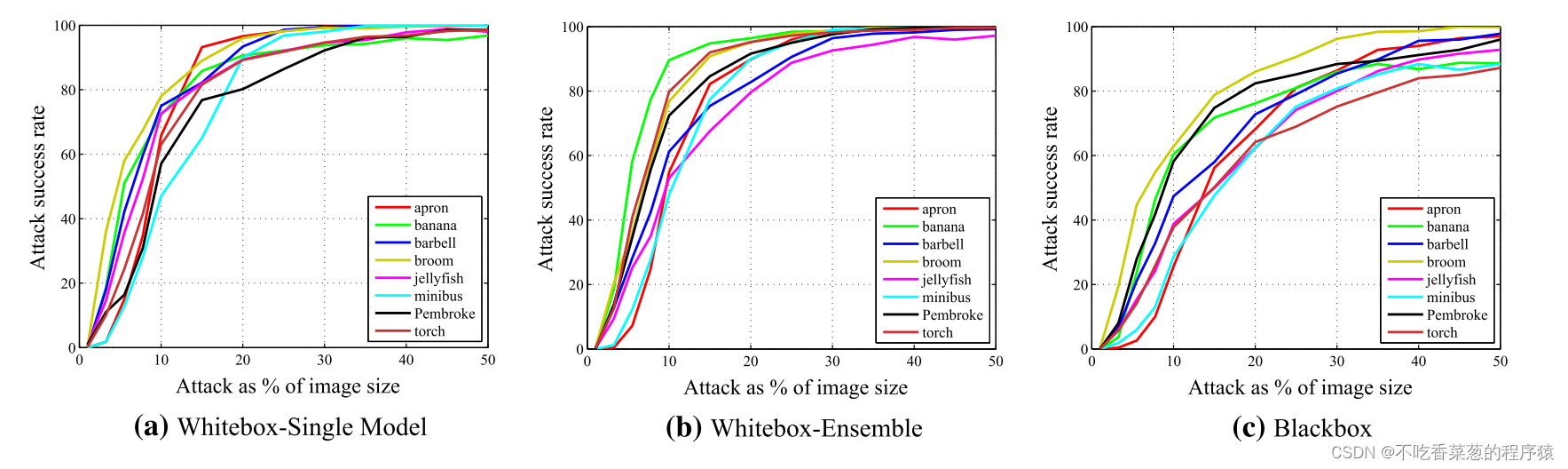 我们随机选择其他8个类别作为目标标签(例如香蕉,水母),实验结果如图所示。对抗补丁由DiAP生成。当补丁占据输入图像面积的20%时,对于所有目标类,两种白盒攻击的成功率都超过80%。攻击成功率与目标类别之间并没有严格的对应关系。
我们随机选择其他8个类别作为目标标签(例如香蕉,水母),实验结果如图所示。对抗补丁由DiAP生成。当补丁占据输入图像面积的20%时,对于所有目标类,两种白盒攻击的成功率都超过80%。攻击成功率与目标类别之间并没有严格的对应关系。
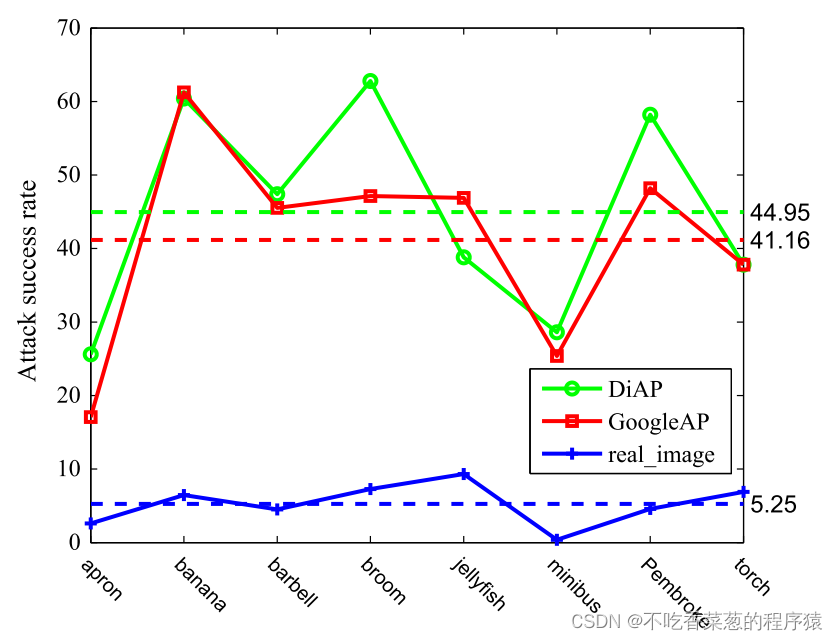
DiAP在黑盒场景下的攻击性能尤其值得注意,这意味着恶意攻击者可以在不知道模型结构、预训练参数和训练数据集的情况下攻击深度神经网络。图显示了当缩放参数为10%时,黑盒攻击场景中的攻击成功率。当补丁占测试图像面积的10%时,我们检验了攻击能力。在大多数情况下,DiAP的性能优于GoogleAP,DiAP的平均攻击成功率为44.95%,而GoogleAP为41.15%。这表明DiAP生成的补丁具有更好的可移植性,更适合黑盒攻击。同时,随机选取8幅真实的图像进行比较,每个目标类一幅。而对真实的图片的攻击成功率均不到10%,平均只有5. 25%。这些结果证实了我们的对抗补丁,而不是目标标签的真实的图像,可以攻击深度神经网络。
七、结论
在本文中,我们提出了一种数据独立的方法来生成对抗补丁。通过污染被攻击网络的每一层提取的特征,DiAP生成非目标对抗补丁。然后,结合非目标补丁所隐含的信息,DiAP提取目标类的特征,以制作有针对性的对抗补丁。在生成补丁的过程中,DiAP完全不使用任何训练数据,有利于在真实的物理场景中进行攻击。在数字世界和物理世界的白盒和黑盒环境下的大量实验结果表明,DiAP具有强大的攻击能力,并达到了最先进的性能。此外,DiAP在黑盒攻击中优于现有的方法,这意味着当网络结构未知时,模糊的示例信息可能比真实的示例更有助于攻击。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









