






一:容错安全性
1. ReceivedBlockTracker负责管理Spark Streaming运行程序的元数据。数据层面
2. DStream和JobGenerator是作业调度的核心层面,也就是具体调度到什么程度了,从运行的考虑的。DStream是逻辑层面。
3. 作业生存层面,JobGenerator是Job调度层面,具体调度到什么程度了。从运行的角度的。
谈Driver容错你要考虑Driver中有那些需要维持状态的运行。
1. ReceivedBlockTracker跟踪了数据,因此需要容错。通过WAL方式容错。
2. DStreamGraph表达了依赖关系,恢复状态的时候需要根据DStream恢复计算逻辑级别的依赖关系。通过checkpoint方式容错。
3. JobGenerator表面你是怎么基于ReceiverBlockTracker中的数据,以及DStream构成的依赖关系不断的产生Job的过程。你消费了那些数据,进行到什么程度了。
总结如下:
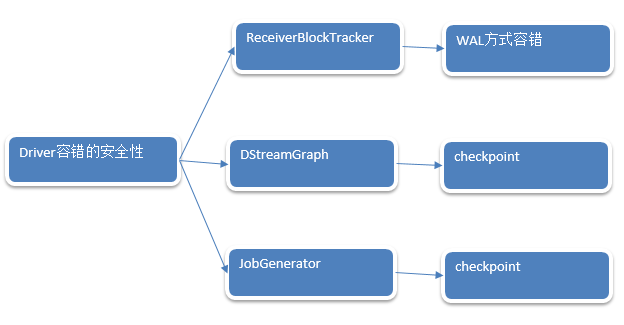
ReceivedBlockTracker:
1. ReceivedBlockTracker会管理Spark Streaming运行过程中所有的数据。并且把数据分配给需要的batches,所有的动作都会被WAL写入到Log中,Driver失败的话,就可以根据历史恢复tracker状态,在ReceivedBlockTracker创建的时候,使用checkpoint保存历史目录。
/**
* This class manages the execution of the receivers of ReceiverInputDStreams. Instance of
* this class must be created after all input streams have been added and StreamingContext.start()
* has been called because it needs the final set of input streams at the time of instantiation.
*
* @param skipReceiverLaunch Do not launch the receiver. This is useful for testing.
*/
private[streaming]
class ReceiverTracker(ssc: StreamingContext, skipReceiverLaunch: Boolean = false) extends Logging {
下面就从Receiver收到数据之后,怎么处理的开始。
2. ReceiverBlockTracker.addBlock源码如下:
Receiver接收到数据,把元数据信息汇报上来,然后通过ReceiverSupervisorImpl就将数据汇报上来,就直接通过WAL进行容错.
当Receiver的管理者,ReceiverSupervisorImpl把元数据信息汇报给Driver的时候,正在处理是交给ReceiverBlockTracker. ReceiverBlockTracker将数据写进WAL文件中,然后才会写进内存中,被当前的Spark Streaming程序的调度器使用的,也就是JobGenerator使用的。JobGenerator不可能直接使用WAL。WAL的数据在磁盘中,这里JobGenerator使用的内存中缓存的数据结构
/* Add received block. This event will get written to the write ahead log (if enabled). /
def addBlock(receivedBlockInfo: ReceivedBlockInfo): Boolean = {
try {
// writeToLog
val writeResult = writeToLog(BlockAdditionEvent(receivedBlockInfo))
if (writeResult) {
synchronized {
//数据汇报上来的时候只有成功写进WAL的时候,才会把ReceivedBlockInfo元数据信息放进Queue
getReceivedBlockQueue(receivedBlockInfo.streamId) += receivedBlockInfo
}
logDebug(s”Stream
receivedBlockInfo.streamIdreceived”+s”block
{receivedBlockInfo.blockStoreResult.blockId}”)
} else {
logDebug(s”Failed to acknowledge stream
receivedBlockInfo.streamIdreceiving”+s”block
{receivedBlockInfo.blockStoreResult.blockId} in the Write Ahead Log.”)
}
writeResult
} catch {
case NonFatal(e) =>
logError(s”Error adding block receivedBlockInfo”, e)
false
}
}
此时的数据结构就是streamIdToUnallocatedBlockQueues,Driver端接收到的数据保存在streamIdToUnallocatedBlockQueues中。
private val streamIdToUnallocatedBlockQueues = new mutable.HashMap[Int, ReceivedBlockQueue]
3. allocateBlocksToBatch把接收到的数据但是没有分配,分配给batch,根据streamId取出Block,由此就知道Spark Streaming处理数据的时候可以有不同的数据来源,例如Kafka,Socket。
到底什么是batchTime?
batchTime是上一个Job分配完数据之后,开始再接收到的数据的时间。
/**
* Allocate all unallocated blocks to the given batch.
* This event will get written to the write ahead log (if enabled).
*/
def allocateBlocksToBatch(batchTime: Time): Unit = synchronized {
if (lastAllocatedBatchTime == null || batchTime > lastAllocatedBatchTime) {
// streamIdToBlocks获得了所有分配的数据
val streamIdToBlocks = streamIds.map { streamId =>
// getReceivedBlockQueue就把streamId获得的数据存储了。如果要分配给batch,//让数据出队列就OK了。
(streamId, getReceivedBlockQueue(streamId).dequeueAll(x => true))
}.toMap
val allocatedBlocks = AllocatedBlocks(streamIdToBlocks)
//获得元数据信息之后并没有立即分配给作业,还是进行WAL
//所以如果Driver出错之后,再恢复就可以将作业的正常的分配那些Block状态
//这里指的是针对于Batch Time分配那些Block状态都可以恢复回来。
if (writeToLog(BatchAllocationEvent(batchTime, allocatedBlocks))) {
//JobGenerator就是从timeToAllocatedBlocks中获取数据。
// 这个时间段batchTime就知道了要处理那些数据allocatedBlocks
timeToAllocatedBlocks.put(batchTime, allocatedBlocks)
//
lastAllocatedBatchTime = batchTime
} else {
logInfo(s”Possibly processed batchbatchTime need to be processed again in WAL recovery”)
}
} else {
// This situation occurs when:
// 1. WAL is ended with BatchAllocationEvent, but without BatchCleanupEvent,
// possibly processed batch job or half-processed batch job need to be processed again,
// so the batchTime will be equal to lastAllocatedBatchTime.
// 2. Slow checkpointing makes recovered batch time older than WAL recovered
// lastAllocatedBatchTime.
// This situation will only occurs in recovery time.
logInfo(s”Possibly processed batch $batchTime need to be processed again in WAL recovery”)
}
}
4. timeToAllocatedBlocks可以有很多的时间窗口的Blocks,也就是Batch Duractions的Blocks。这里面就维护了很多Batch Duractions分配的数据,假设10秒是一个Batch Duractions也就是10s产生一个Job的话,如果此时想算过去的数据,只需要根据时间进行聚合操作即可。
private val timeToAllocatedBlocks = new mutable.HashMap[Time, AllocatedBlocks]
5. 根据streamId获取Block信息
/* Class representing the blocks of all the streams allocated to a batch /
private[streaming]
case class AllocatedBlocks(streamIdToAllocatedBlocks: Map[Int, Seq[ReceivedBlockInfo]]) {
def getBlocksOfStream(streamId: Int): Seq[ReceivedBlockInfo] = {
streamIdToAllocatedBlocks.getOrElse(streamId, Seq.empty)
}
}
6. cleanupOldBatches:因为时间的推移会不断的生成RDD,RDD会不断的处理数据,
因此不可能一直保存历史数据。
/**
* Clean up block information of old batches. If waitForCompletion is true, this method
* returns only after the files are cleaned up.
*/
def cleanupOldBatches(cleanupThreshTime: Time, waitForCompletion: Boolean): Unit = synchronized {
require(cleanupThreshTime.milliseconds < clock.getTimeMillis())
val timesToCleanup = timeToAllocatedBlocks.keys.filter { _ < cleanupThreshTime }.toSeq
logInfo(“Deleting batches ” + timesToCleanup)
//WAL
if (writeToLog(BatchCleanupEvent(timesToCleanup))) {
timeToAllocatedBlocks –= timesToCleanup
writeAheadLogOption.foreach(_.clean(cleanupThreshTime.milliseconds, waitForCompletion))
} else {
logWarning(“Failed to acknowledge batch clean up in the Write Ahead Log.”)
}
}
7. writeToLog
/* Write an update to the tracker to the write ahead log /
private def writeToLog(record: ReceivedBlockTrackerLogEvent): Boolean = {
if (isWriteAheadLogEnabled) {
logTrace(s”Writing record: record”)
try {
writeAheadLogOption.get.write(ByteBuffer.wrap(Utils.serialize(record)),
clock.getTimeMillis())
true
} catch {
case NonFatal(e) =>
logWarning(s”Exception thrown while writing record:record to the WriteAheadLog.”, e)
false
}
} else {
true
}
}
总结:
WAL对数据的管理包括数据的生成,数据的销毁和消费。上述在操作之后都要先写入到WAL的文件中.
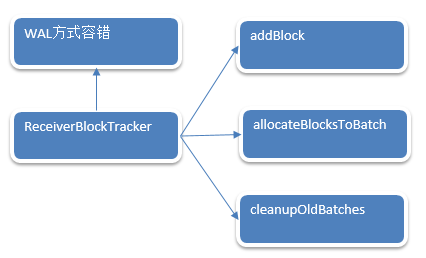
JobGenerator:
Checkpoint会有时间间隔Batch Duractions,Batch执行前和执行后都会进行checkpoint。
doCheckpoint被调用的前后流程:
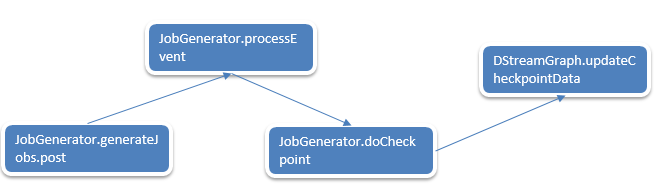
1. generateJobs
/* Generate jobs and perform checkpoint for the given time. /
private def generateJobs(time: Time) {
// Set the SparkEnv in this thread, so that job generation code can access the environment
// Example: BlockRDDs are created in this thread, and it needs to access BlockManager
// Update: This is probably redundant after threadlocal stuff in SparkEnv has been removed.
SparkEnv.set(ssc.env)
Try {
jobScheduler.receiverTracker.allocateBlocksToBatch(time) // allocate received blocks to batch
graph.generateJobs(time) // generate jobs using allocated block
} match {
case Success(jobs) =>
val streamIdToInputInfos = jobScheduler.inputInfoTracker.getInfo(time)
jobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos))
case Failure(e) =>
jobScheduler.reportError(“Error generating jobs for time ” + time, e)
}
//上面自学就那个完之后就需要进行checkpoint
eventLoop.post(DoCheckpoint(time, clearCheckpointDataLater = false))
}
2. processEvent接收到消息
/* Processes all events /
private def processEvent(event: JobGeneratorEvent) {
logDebug(“Got event ” + event)
event match {
case GenerateJobs(time) => generateJobs(time)
case ClearMetadata(time) => clearMetadata(time)
case DoCheckpoint(time, clearCheckpointDataLater) =>
// doCheckpoint被调用
doCheckpoint(time, clearCheckpointDataLater)
case ClearCheckpointData(time) => clearCheckpointData(time)
}
}
3. 把当前的状态进行Checkpoint.
/* Perform checkpoint for the give time. /
private def doCheckpoint(time: Time, clearCheckpointDataLater: Boolean) {
if (shouldCheckpoint && (time - graph.zeroTime).isMultipleOf(ssc.checkpointDuration)) {
logInfo(“Checkpointing graph for time ” + time)
ssc.graph.updateCheckpointData(time)
checkpointWriter.write(new Checkpoint(ssc, time), clearCheckpointDataLater)
}
}
4. DStream中的updateCheckpointData源码如下:最终导致RDD的Checkpoint
/**
* Refresh the list of checkpointed RDDs that will be saved along with checkpoint of
* this stream. This is an internal method that should not be called directly. This is
* a default implementation that saves only the file names of the checkpointed RDDs to
* checkpointData. Subclasses of DStream (especially those of InputDStream) may override
* this method to save custom checkpoint data.
*/
private[streaming] def updateCheckpointData(currentTime: Time) {
logDebug(“Updating checkpoint data for time ” + currentTime)
checkpointData.update(currentTime)
dependencies.foreach(_.updateCheckpointData(currentTime))
logDebug(“Updated checkpoint data for time ” + currentTime + “: ” + checkpointData)
}
5. shouldCheckpoint是状态变量。
// This is marked lazy so that this is initialized after checkpoint duration has been set
// in the context and the generator has been started.
private lazy val shouldCheckpoint = ssc.checkpointDuration != null && ssc.checkpointDir != null
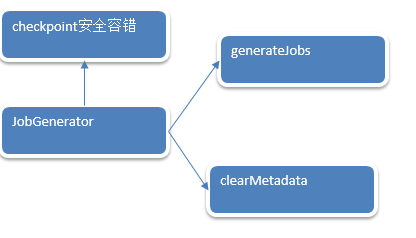
JobGenerator容错安全性如下图:
**配套视频链接:http://www.tudou.com/home/_79823675/playlist
课程及技术交流QQ:460507491**















12-01
 1687
1687
1687
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









