







一. Scala开发环境搭建(略)
二. Scala中的基本语法(重点)
val n =10
def f1: Int = {
for(i <- 1 to 20)
{
if (i == n) return 9
println(i)
i
}
}
块表达式:块表达式的代码块的返回值默认为最后一行的返回值。
最后一行是表达式,所以这个Result代码块的返回值为最后一行的返回值Unit。

最后一行内容的值,表达式的背后是代码块,代码块的返回值为最后一行的值,所以这里整个代码块的返回值默认为最后一行的值10。

占位符

readLind本身具有方法重载,同时也有默认构造的参数,即不传参数的默认为空, 且不需要后面的(),这带来了编写的方便性。
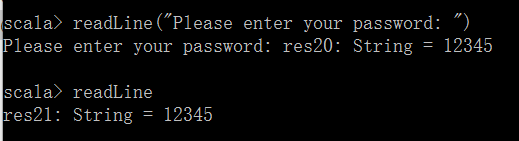
while循环
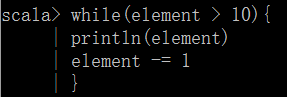
相对而言,for循环用的更多些。其中if i%2 == 0为守卫条件。
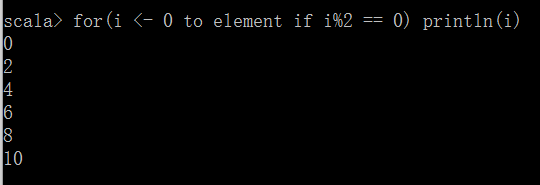
(0 to element) 本身就是一个集合

break其实 相当于实现了return, 因此只打印了1,2,3。
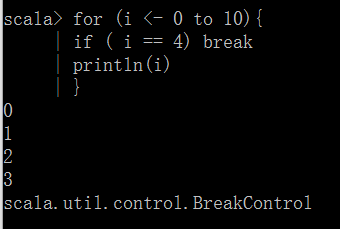
通常情况下在函数里面做循环的时候才去做return的动作。
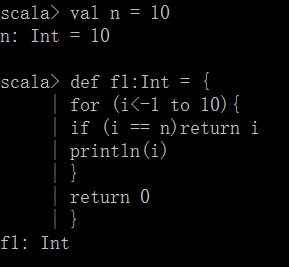
当我们把最后一行 return 0去掉时,系统会报错如下。
从函数调用的角度,系统并不关心内部是怎么回事,要求返回具体的整数类型,而这个语句块执行之后内部产生的副作用是,实际上最后一次执行的是println,而println的返回类型是unit 类型
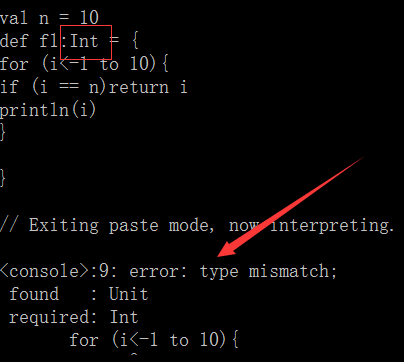
正确的做法:
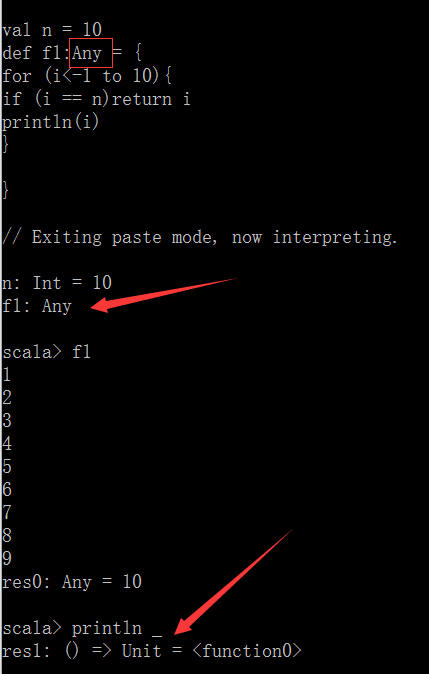
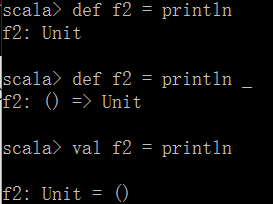
函数可以赋值给函数本身,也可以赋值给变量本身
传参
默认参数:函数f3的返回类型为String
系统启动时会有自己的默认配置,系统框架运行时,会读取默认配置文件中的内容,然后把默认配置的具体内容赋值给默认参数,或者直接讲内容写成默认参数本身,这对于系统的正常运行非常重要

带名参数
Scala中,调用函数参数时可以不按照函数中的参数顺序来传递参数,而是使用这种带名字的参数

变长参数
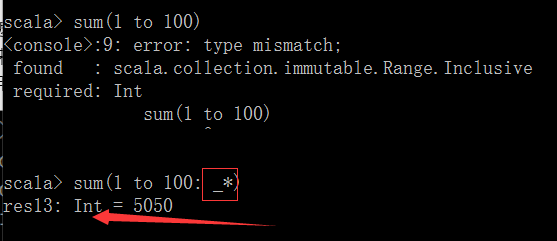
*表示有很多个numbers参数

要求的返回值是Int 类型,但(1 to 10)本身不是Int类型,而_*表示把(1 to 10)中的每个元素提取出来,此时,每个元素即可符号Int类型的要求,这个语法特别常见,操作集合数组,tail中递归调用或者循环遍历表时经常用到这个语法。
过程,即没有结果,只有Unit返回值的函数。
过程的两种表现形式如下:
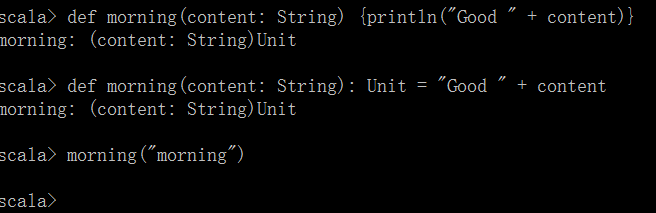
相对应的函数的表达形式
Lazy
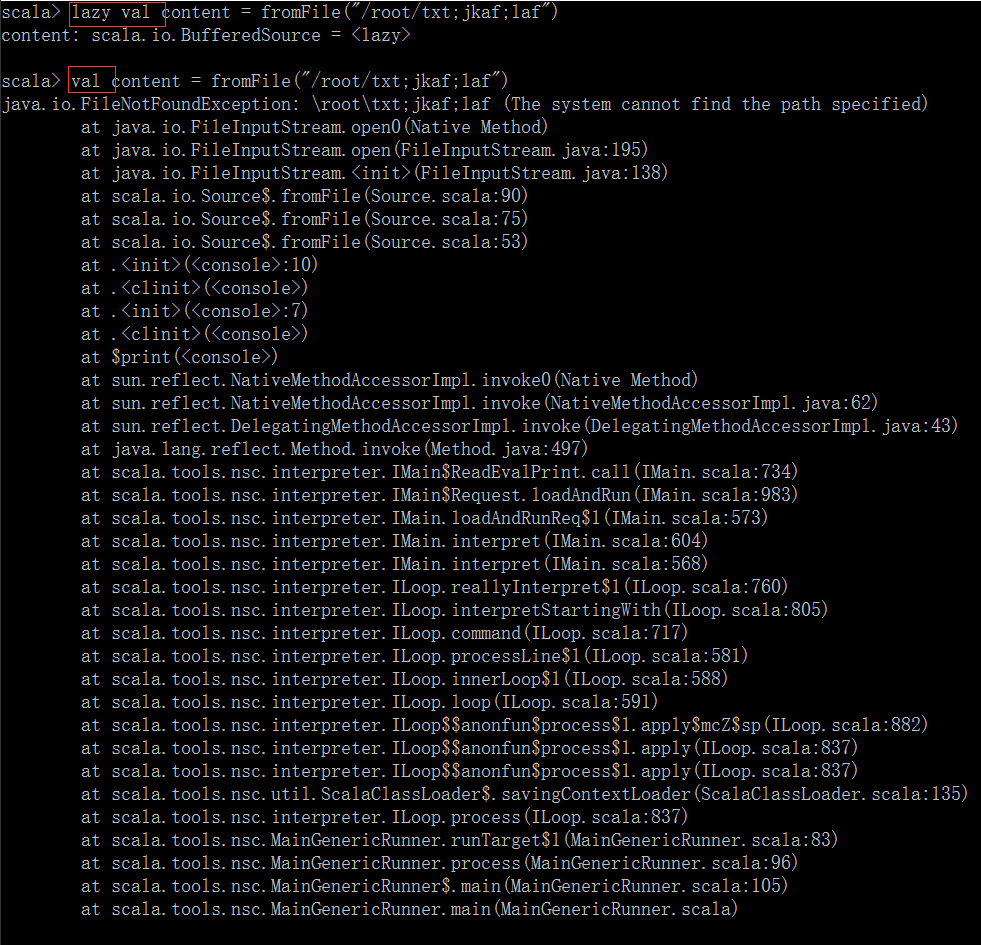
这里系统返回的是一个BufferedSource的迭代器
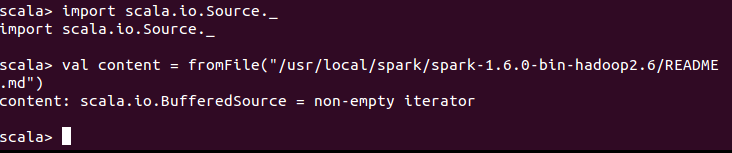
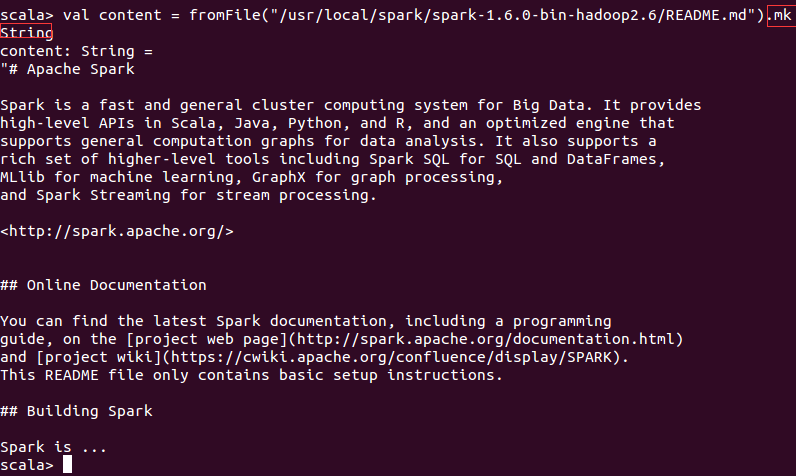
加载参数mkString显示出文件内容
而当我们在其前面加入lazy时,文件内容不会被即时打印出来。

而只有当我们去访问这个content时,函数才会被执行并显示文件内容。
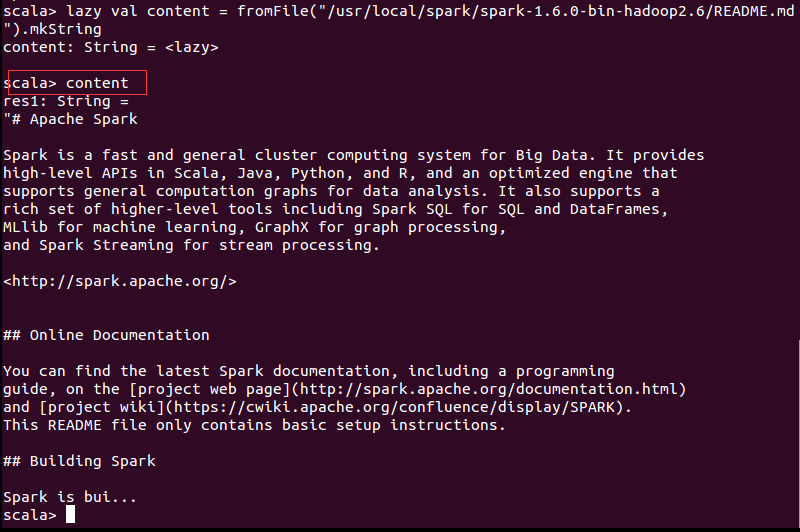
在大型分布式集群中,特别是比较耗时的操作中,lazy非常的重要。
Scala在底层读取文件时用的是Java的功能
异常
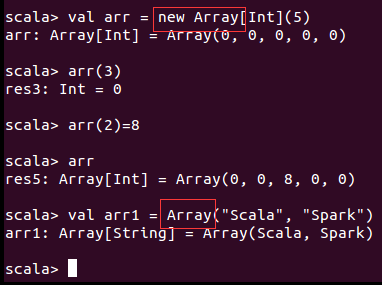
数组
此处定义的val数组arr,指的是arr本身指向的对象不可以修改,对象不可修改指的是对象的地址,而我们修改的是对象的内容,而该地址里的内容是可以修改的。这里修改的是对象的内容而不是对象的地址。
[Int]的类型指的是泛型。
实际上在大数据Spark中更常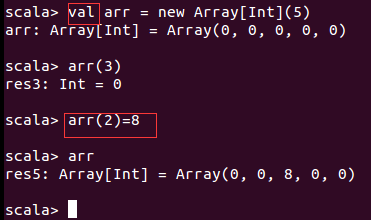
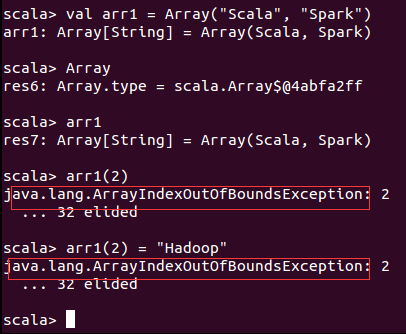
不可变数组Array本身一旦创建,是不可变的。
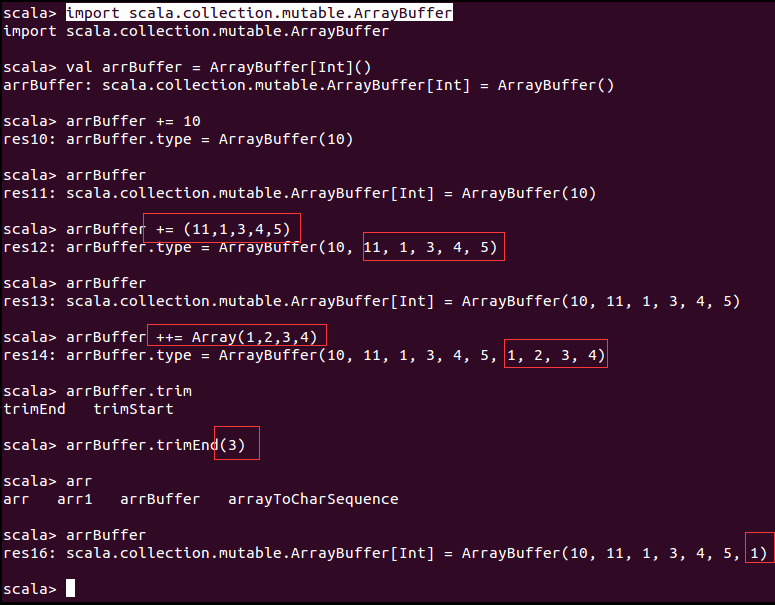
可变数组
Scala中提供了可变数组ArrayBuffer可以向数组中增加元素,它是可变的,所以可以直接向定义的数组元素赋值或者其他直接对元素的操作。
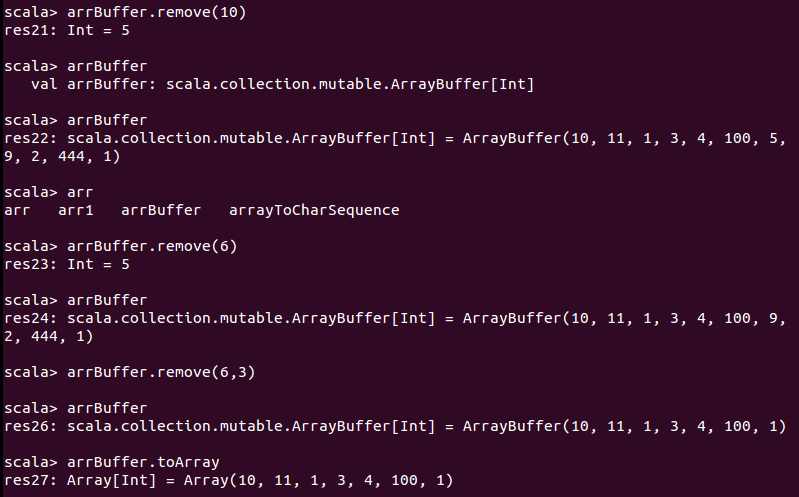
可变数组和不可变数组的转换:
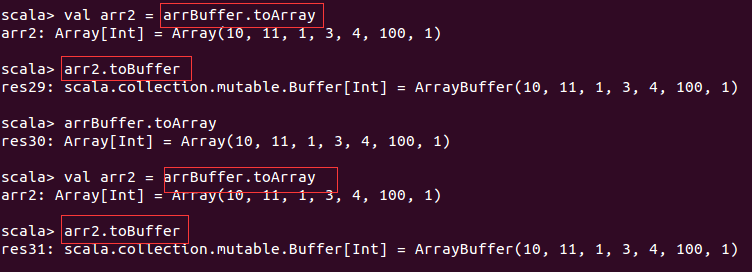
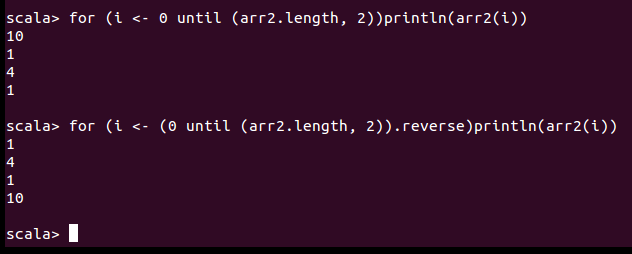
数组的循环遍历:从头和从尾部遍历
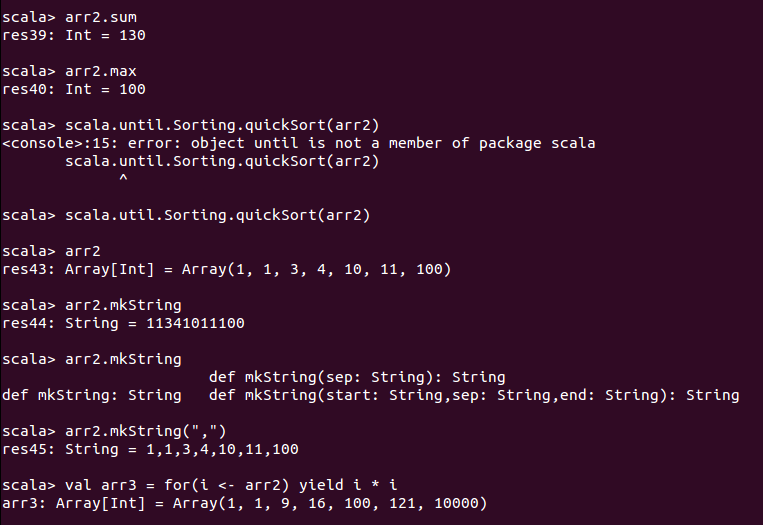
对数组的其他操作:
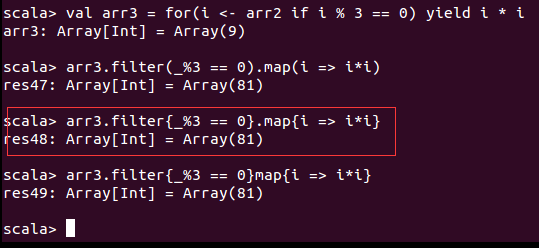
Scala中常用的方式如下框,这里就比较有函数式编程的味道了。
Map
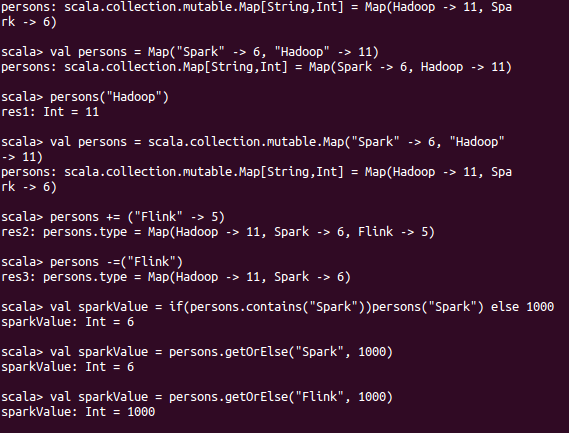
理论上讲,所有的数据都可以表达为key/value的方式。Map本身也是不可变集合,不可以直接增加和删除元素,但可以通过mutable map的方式进行集合内容的增删等操作。
A mutable collection can be updated or extended in place. This means you can change, add, or remove elements of a collection as a side effect. Immutable collections, by contrast, never change.
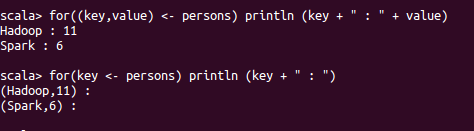
增强for 循环的应用
SortedMap会根据key的值进行排序

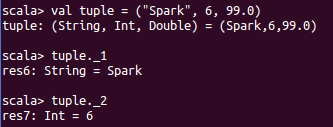
Tuple
Tuple和数组 下标不同,是从1开始的。
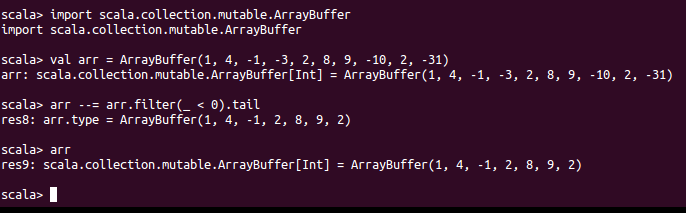
作业:移除一个数组中第一个负数之后所有的负数
**配套视频链接:http://www.tudou.com/home/_79823675/playlist
课程及技术交流QQ:460507491**















 261
261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









