






前言
感慨的和怀念的 放不下的 只是那一段时间的你们
大师说过:《少去对比 ,多看自己》
今天就给大家讲一下怎么样爬qq好友空间的留言:
提示:以下是本篇文章正文内容,下面案例可供参考(有三种类型可供选择)
一、分析
1.好友空间需要登陆才能获取,所以我们需要一个cookie
2.然后才能进行我们的一个爬虫
1.获取cookie
进入后先摁下F12,再扫码或者账号密码登录空间。
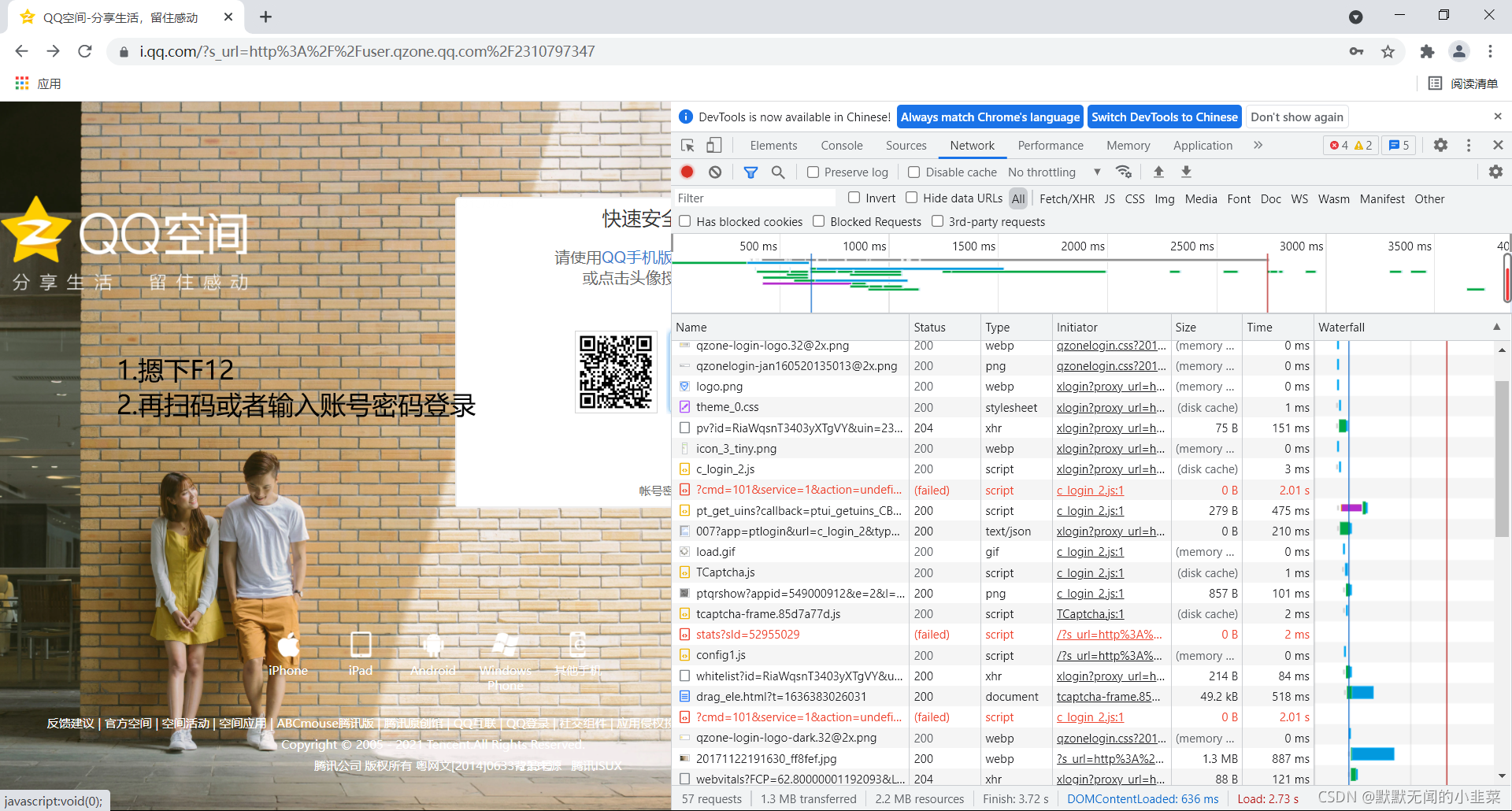
进入空间后点击先Network,选择All,将滚轮滑到最上面,点击第一个含有你qq号的链接,右边出来以后往下滑找到cookie这里的cookie就是我们需要的了。
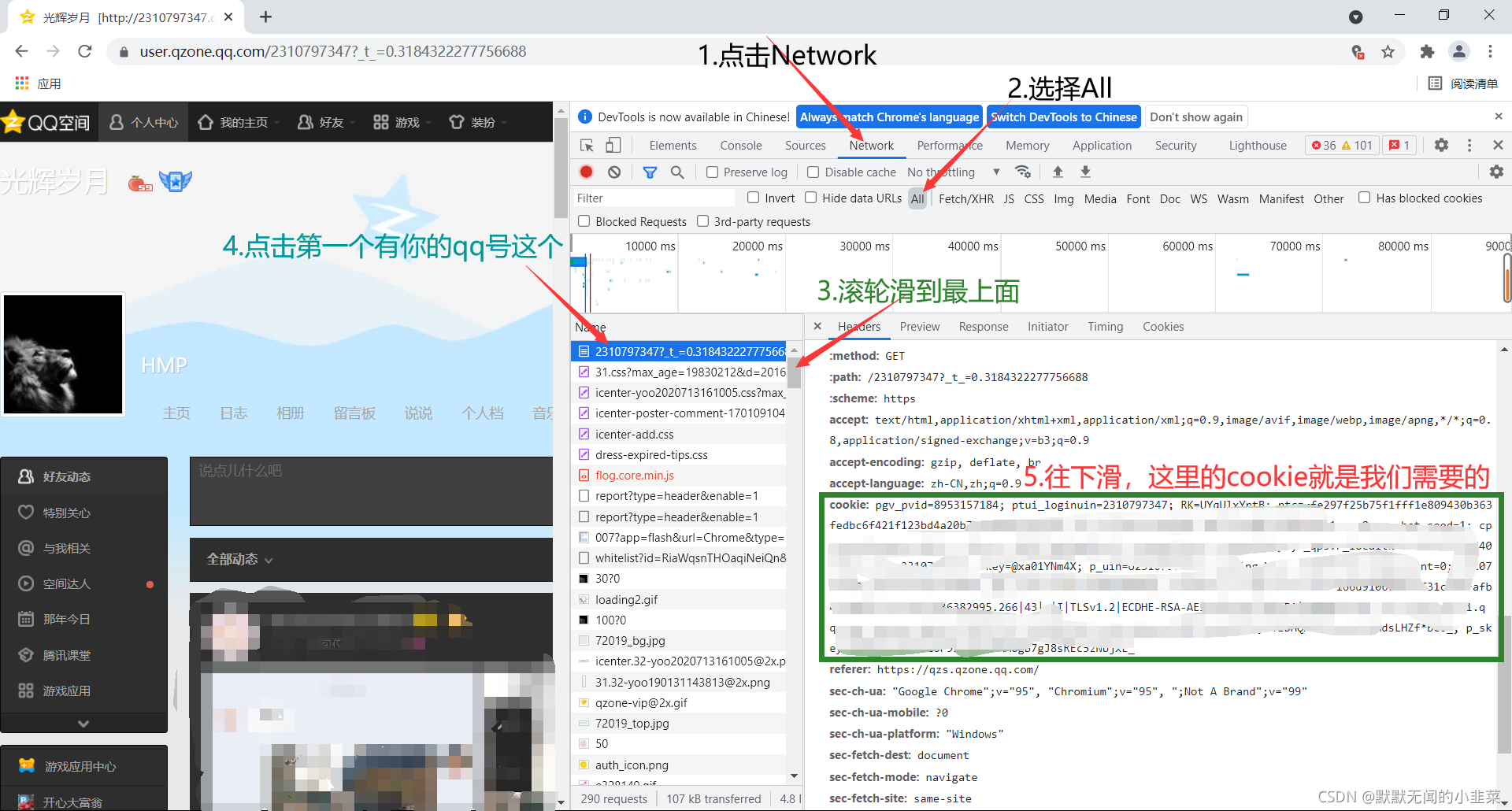
2.分析含留言内容的url
cookie有了我们就来分析好友留言板的链接。
进入好友空间,并点击留言板,摁下F12,选择XHR,然后把网页滑到最下面点击第二页加载完成后点击第三页然后右边name下就会出现类似的几个网页,这里我们需要的留言内容在一个get_msgb开头的链接下。
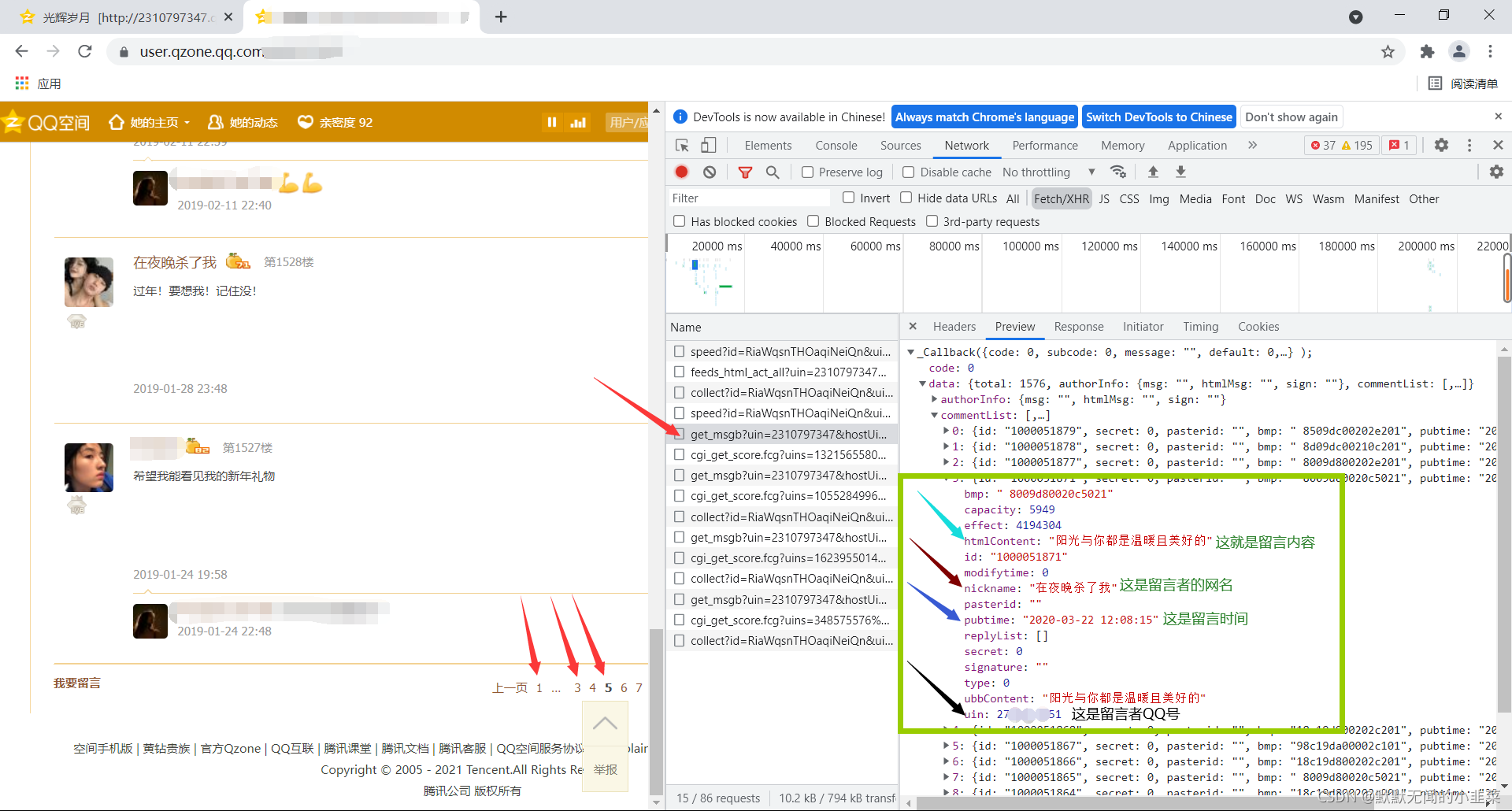
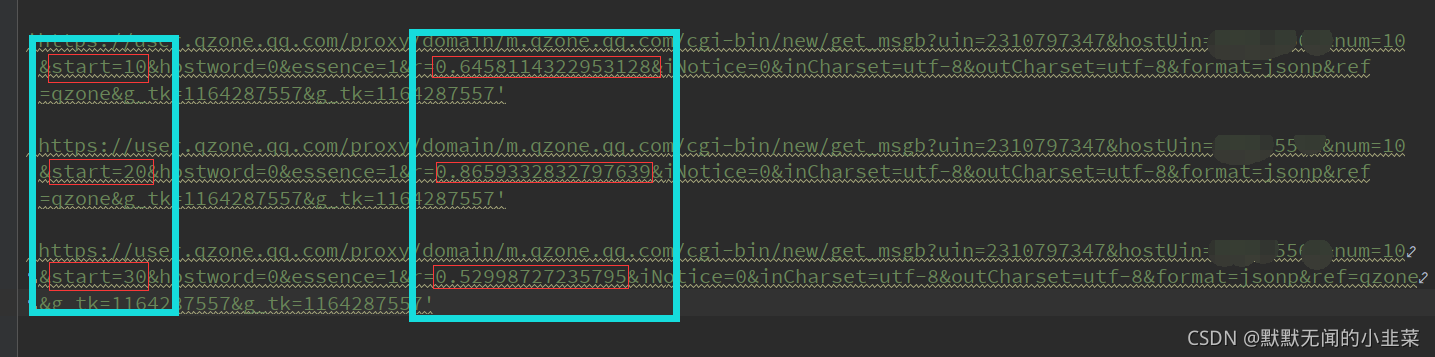
然后再回过头来比较他们的url,这里选择三个相邻的url来作比较。
这里呢我找到两个不同的地方,但是我发现第二个r=后面一串数字好像不加上也没问题,一样请求能得到响应。
那么就来看这第一个不同的地方,这一看是成倍数增长的,那么就可以确定他是(页数-1)*10得来的。
二、代码与效果
1.多线程爬取,保存到txt文本
代码如下(示例):
# -!- coding: utf-8 -!-
import re
import time
import requests
from threading import Thread #多线程
class Qqspider:
def __init__(self):
self.url = 'https://user.qzone.qq.com/proxy/domain/m.qzone.qq.com/cgi-bin/new/get_msgb?uin=#这里是你自己的账号#&hostUin=#好友的账号#&num=10&start={}&hostword=0&essence=1&iNotice=0&inCharset=utf-8&outCharset=utf-8&format=jsonp&ref=qzone&g_tk=1453454822&g_tk=1453454822' #这里的start一定要={}!!!记得复制粘贴的一定要修改!!!
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36',
'cookie':'写入自己空间的cookie',
}
self.lis = []
self.f = open('content1.txt','w',encoding='utf-8') #写入一个txt文本
#请求函数
def get_html(self,url):
response = requests.get(url=url,headers=self.headers)
return response
#数据解析函数
def parse_html(self,regex,html):
content = regex.findall(html)
for i in content:
item = {}
item['qq'] = i[0]
item['name'] = i[1]
item['content'] = i[2]
self.f.write(i[1]+' >>> '+i[2]+'\n')
print(item)
#数据提取函数
def crawl(self,i):
while self.lis:
response = self.get_html(self.lis.pop(0)).text
regex = re.compile('"uin":(.*?),.*?"nickname":"(.*?)",.*?"capacity":.*?,.*?"htmlContent":".*?",.*?"ubbContent":"(.*?)",',re.S)
self.parse_html(regex,response)
print('{}完成一個!'.format(i))
time.sleep(0.2)
# 创建多线程
def job(self):
jobs = []
for i in range(16):
a = Thread(target=self.crawl,args=(i,))
jobs.append(a)
a.start()
[i.join() for i in jobs]
#主函数
def run(self):
for i in range(158): #空间留言的页数
self.lis.append(self.url.format(i*10))
self.job()
self.f.close()
if __name__ == '__main__':
spider = Qqspider()
spider.run()
2.多线程爬取,保存到xlsx
优劣:时间快,但爬取顺序是错乱的
代码如下(示例):
# -!- coding: utf-8 -!-
import re
import time
import requests
from threading import Thread #多线程
import openpyxl
class Qqspider:
def __init__(self):
self.url = 'https://user.qzone.qq.com/proxy/domain/m.qzone.qq.com/cgi-bin/new/get_msgb?uin=#这里是你自己的账号#&hostUin=#好友的账号#&num=10&start={}&hostword=0&essence=1&iNotice=0&inCharset=utf-8&outCharset=utf-8&format=jsonp&ref=qzone&g_tk=1453454822&g_tk=1453454822' #这里的start一定要={}!!!记得复制粘贴的一定要修改!!!
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36',
'cookie':'写入自己空间的cookie',
}
self.lis = []
self.f = open('content1.txt','w',encoding='utf-8') #写入一个txt文本
self.workbook = openpyxl.Workbook()
#请求函数
def get_html(self,url):
response = requests.get(url=url,headers=self.headers)
return response
#数据解析函数
def parse_html(self,regex,html):
content = regex.findall(html)
# content = regex
# print('让我看看',html)
for i in content:
print(i)
item = {}
item['qq'] = i[0]
item['name'] = i[1]
item['content'] = i[2]
item['pubtime'] = i[3]
self.f.write(i[1]+' >>> '+i[2]+'\n')
# 获取默认的工作表
sheet = self.workbook.active
# 写入数据
sheet['A1'] = 'qq'
sheet['B1'] = '姓名'
# sheet['C1'] = '时间'
sheet['D1'] = '内容'
# sheet.append([item['qq'], item['name'],item['pubtime'],item['content']])
sheet.append([item['qq'], item['name'],item['content']])
#数据提取函数
def crawl(self,i):
while self.lis:
response = self.get_html(self.lis.pop(0)).text
regex = re.compile('"uin":(.*?),.*?"nickname":"(.*?)",.*?"ubbContent":"(.*?)"(?:,.*?"pubtime":"(.*?)")?.*?',re.S)
self.parse_html(regex,response)
print('{}完成一個1!'.format(i))
time.sleep(0.1)
# 创建多线程
def job(self):
jobs = []
for i in range(16):
a = Thread(target=self.crawl,args=(i,))
jobs.append(a)
a.start()
[i.join() for i in jobs]
#主函数
def run(self):
for i in range(180): #空间留言的页数
self.lis.append(self.url.format(i*10))
self.job()
self.f.close()
self.workbook.save('example16.xlsx')
if __name__ == '__main__':
spider = Qqspider()
spider.run()
3.单线程爬取,保存到xlsx
优劣:时间慢,但可以顺序爬取的,且容易出现卡顿
代码如下(示例):
# -!- coding: utf-8 -!-
import re
import time
import requests
import openpyxl
class Qqspider:
def __init__(self):
self.url = 'https://user.qzone.qq.com/proxy/domain/m.qzone.qq.com/cgi-bin/new/get_msgb?uin=#这里是你自己的账号#&hostUin=#好友的账号#&num=10&start={}&hostword=0&essence=1&iNotice=0&inCharset=utf-8&outCharset=utf-8&format=jsonp&ref=qzone&g_tk=1453454822&g_tk=1453454822' #这里的start一定要={}!!!记得复制粘贴的一定要修改!!!
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36',
'cookie': '写入自己空间的cookie',
}
self.lis = []
self.f = open('content1.txt', 'w', encoding='utf-8') # 写入一个txt文本
self.workbook = openpyxl.Workbook()
# 请求函数
def get_html(self, url):
response = requests.get(url=url, headers=self.headers)
return response
# 数据解析函数
def parse_html(self, regex, html):
content = regex.findall(html)
for i in content:
print(i)
item = {}
item['qq'] = i[0]
item['name'] = i[1]
item['content'] = i[2]
item['pubtime'] = i[3] if len(i) > 3 and i[3] else 'N/A'
self.f.write(i[1] + ' >>> ' + i[2] + '\n')
sheet = self.workbook.active
sheet['A1'] = 'qq'
sheet['B1'] = '姓名'
sheet['C1'] = '时间'
sheet['D1'] = '内容'
sheet.append([item['qq'], item['name'],item['pubtime'], item['content']])
# 数据提取函数
def crawl(self):
for url in self.lis:
response = self.get_html(url).text
regex = re.compile('"uin":(.*?),.*?"nickname":"(.*?)",.*?"ubbContent":"(.*?)"(?:,.*?"pubtime":"(.*?)")?.*?', re.S)
self.parse_html(regex, response)
time.sleep(0.1)
# 主函数
def run(self):
for i in range(180): # 空间留言的页数
self.lis.append(self.url.format(i*10))
self.crawl()
self.f.close()
self.workbook.save('example21.xlsx')
if __name__ == '__main__':
spider = Qqspider()
spider.run()
一共1800条留言,一条不差
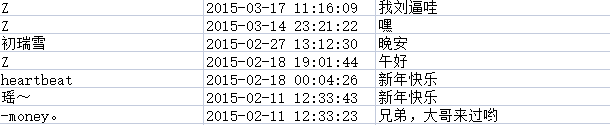
总结
大家有什么不懂得地方可以私信我哦。要是有什么不对的地方还望大佬指出。
谢谢大家的点赞与阅读,
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











