







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
1.Numpy风格的索引
可以在一个方括号里写完所有索引,之间用逗号隔开就行
import tensorflow as tf
a = tf.random.normal([4, 28, 28, 3])
print(a[1].shape)
print(a[2, 3].shape)
print(a[2, 4, 7].shape)
print(a[2, 4, 7, 2].shape)

2. 范围式索引 用冒号实现
格式: start :end:step
第三个参数代表步长,含义是每隔多少取样一次,可省略,省略时就默认为1
特点:
- 返回的元素索引包含start不包含end
- 这种冒号式的索引还支持倒序 例如 -1 代表倒数第一个元素的索引
- start不填写代表从第一个元素开始,end不填写代表从start到最后一个元素
- 若第三个参数存在,且为负数,则代表逆序采样。就是从start 采样到end+1的位置,step的绝对值代表步长 eg: 7:2:-2 (从索引为7的位置倒序采样到3,并且间隔为2)
b = tf.range(10)
print(b) #返回整个向量
print(b[2:8]) #返回从索引为2到索引为7的向量 因为不包含冒号后面的数字 只能到7
print(b[2:]) #若冒号后面省略,则表示从冒号前的索引一直到最后
print(b[:7]) #若冒号前面省略,则表示从数据的第一个元素一直到冒号后的索引的前一个
print(b[3:-1]) #返回从索引为3的数据到倒数第二个数据
print(b[-3:]) #从倒数第3个数据一直返回到最后
print(b[:]) #若都为空,则返回全体
print(b[::2]) #表示返回全体,但是每隔一个元素取样一次
#只有step参数为负数时,start才能大于end 从索引为7的位置倒序采样到3,并且间隔为2
print(b[7:2:-2])

在多维张量中,冒号索引法同样生效
c = tf.random.normal([4, 5, 6])
print(c[:, :, 3:-1].shape)
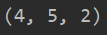
上述代码表示:第一个维度取样所有,第二个维度取样所有,第三个维度取样从索引为3到倒数第2个索引,也就是3到4.。所以打印的shape为(4,5,2)
3. Selective Indexing
上面讲的冒号制的索引方法仍然有一定的弊端,因为那样的方法还是具有一定的规律性》
比如现在有一个张量【4,28,28,3】,第二个维度我想采样索引为26,8,13,9这样毫无规律的索引,冒号索引法就实现不了了。
- tf.gather() 该函数可解决上面的问题,首先一个张量它的坐标轴是有默认编号的,例如一个张量【4,28,28,3】,那么坐标轴依次编号为【0,1,2,3】,gather函数需要指定你在哪一个维度上进行随机采样,并将采样的索引传入即可
d = tf.random.normal([4, 28, 28, 3])
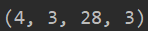
#在第2个维度上随机采样,依次采取18,22,3这3个索引,所以最终的形状为【4,3,28,3】
print(tf.gather(d, axis=1, indices=[18, 22, 3]).shape)
问题又来了:这只是完成了在一个维度上的随机采样,比如我在第2个维度上取18的时候,第3个维度我想取15,在第2个维度上取22的时候,第3个维度我想取7,这样的操作如何实现?
- tf.gatrher_nd()
x = tf.random.normal([4, 35, 8])
#当第二个参数只有一对方括号时,索引方法就是上面提到的numpy风格的索引
print(tf.gather_nd(x, [0]).shape)
print(tf.gather_nd(x, [0, 1]).shape)
print(tf.gather_nd(x, [0, 1, 2]).shape)
#当第二个参数有两对方括号时,内层的每一对括号代表一次索引
#【0,1】代表第一个维度取0,第二个维度取1
#【2,6】代表第一个维度取2,第二个维度取6,内层有多少对方括号就代表取了多少次
print(tf.gather_nd(x, [[0, 1], [2, 6]]).shape)
print(tf.gather_nd(x, [[0, 1, 2]]).shape)
print(tf.gather_nd(x, [[[1, 2, 3], [4, 5, 6], [7, 8, 9]]]).shape)
print(tf.gather_nd(x, [[[1, 2], [4, 5], [7, 8]]]).shape)















 1111
1111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









