







 这篇博客详细介绍了Python的基础知识,包括内置函数、数据类型、字符串操作、字典、集合、元组、浮点型转整型的方法、文件操作、异常处理、模块、并发编程、数据库操作、测试框架pytest的使用等。同时,提到了一些开发工具和库的使用,如mongodb、pyqt5、allure报告、yaml文件和git的使用技巧。内容涵盖了Python编程的多个方面,适合初学者和进阶者学习。
这篇博客详细介绍了Python的基础知识,包括内置函数、数据类型、字符串操作、字典、集合、元组、浮点型转整型的方法、文件操作、异常处理、模块、并发编程、数据库操作、测试框架pytest的使用等。同时,提到了一些开发工具和库的使用,如mongodb、pyqt5、allure报告、yaml文件和git的使用技巧。内容涵盖了Python编程的多个方面,适合初学者和进阶者学习。
functools
常用高阶函数
合并多个字典的方法
1. 使用 | 运算符(Python 3.9+)
最简洁的方式,直接合并多个字典,后面的字典会覆盖前面的同名键:
dict1 = {"a": 1, "b": 2}
dict2 = {"b": 3, "c": 4}
dict3 = {"d": 5}
merged = dict1 | dict2 | dict3
print(merged) # 输出: {'a': 1, 'b': 3, 'c': 4, 'd': 5}
2. 使用 ** 解包语法
适用于 Python 3.5+,通过解包字典键值对到新字典:
merged = {**dict1,** dict2, **dict3}
print(merged) # 输出: {'a': 1, 'b': 3, 'c': 4, 'd': 5}
3. 使用 update() 方法 ** 原地修改第一个字典,适合不需要保留原字典的场景:
merged = dict1.copy() # 先复制避免修改原字典
merged.update(dict2)
merged.update(dict3)
print(merged) # 输出: {'a': 1, 'b': 3, 'c': 4, 'd': 5}
4. 使用 collections.ChainMap(不合并实际数据)** 创建一个链式视图,不真正合并字典,查找时按顺序搜索(适合多配置合并)
from collections import ChainMap
merged = ChainMap(dict1, dict2, dict3)
print(merged["b"]) # 输出: 2(取第一个出现的键值)
print(dict(merged)) # 转换为普通字典: {'a': 1, 'b': 2, 'c': 4, 'd': 5}
5. 处理动态数量的字典(如列表中的字典)** 使用循环或 functools.reduce 合并列表中的所有字典
from functools import reduce
dicts = [dict1, dict2, dict3]
merged = reduce(lambda x, y: {** x, **y}, dicts)
print(merged) # 输出: {'a': 1, 'b': 3, 'c': 4, 'd': 5}
关键说明:
-** 键冲突处理 :所有方法中,后面的字典会覆盖前面的同名键(ChainMap 除外,它保留第一个出现的键)。
- 内存效率 :ChainMap 最省内存,因为它不复制数据,仅创建视图。
- 版本兼容性 **:| 运算符是 Python 3.9 新增的,低版本需用 ** 或 update()。
io.StringIO模块
作用: 提供了一种在内存中模拟文件操作的方式,它允许你像操作文件一样操作字符串



1.测试代码
在编写单元测试时,有时需要模拟文件输入输出操作。使用 StringIO 可以避免创建实际的文件,从而使测试更加高效和独立。
import io
from unittest.mock import patch
def read_file_content(file):
return file.read()
def test_read_file_content():
test_content = "这是一段测试文本。"
# 使用 StringIO 模拟文件对象
mock_file = io.StringIO(test_content)
result = read_file_content(mock_file)
assert result == test_content
test_read_file_content()2. 数据处理与转换
当需要对文本数据进行处理和转换时,StringIO 可以作为临时的缓冲区,避免频繁地读写文件
import io
# 假设我们有一个包含多行数据的字符串
data = "1,2,3\n4,5,6\n7,8,9"
# 创建 StringIO 对象
buffer = io.StringIO(data)
# 处理每一行数据
processed_lines = []
for line in buffer:
numbers = [int(num) for num in line.strip().split(',')]
squared_numbers = [num ** 2 for num in numbers]
processed_lines.append(','.join(map(str, squared_numbers)))
# 将处理后的数据重新组合成一个字符串
processed_data = '\n'.join(processed_lines)
print(processed_data)3. 日志记录
在某些情况下,你可能希望将日志信息存储在内存中,而不是立即写入文件。StringIO 可以用来实现这一目的
import io
import logging
# 创建一个 StringIO 对象作为日志的输出目标
log_buffer = io.StringIO()
# 配置日志记录器
logging.basicConfig(stream=log_buffer, level=logging.INFO)
logger = logging.getLogger()
# 记录一些日志信息
logger.info("这是一条信息日志。")
logger.warning("这是一条警告日志。")
# 获取日志内容
log_content = log_buffer.getvalue()
print(log_content)描述符
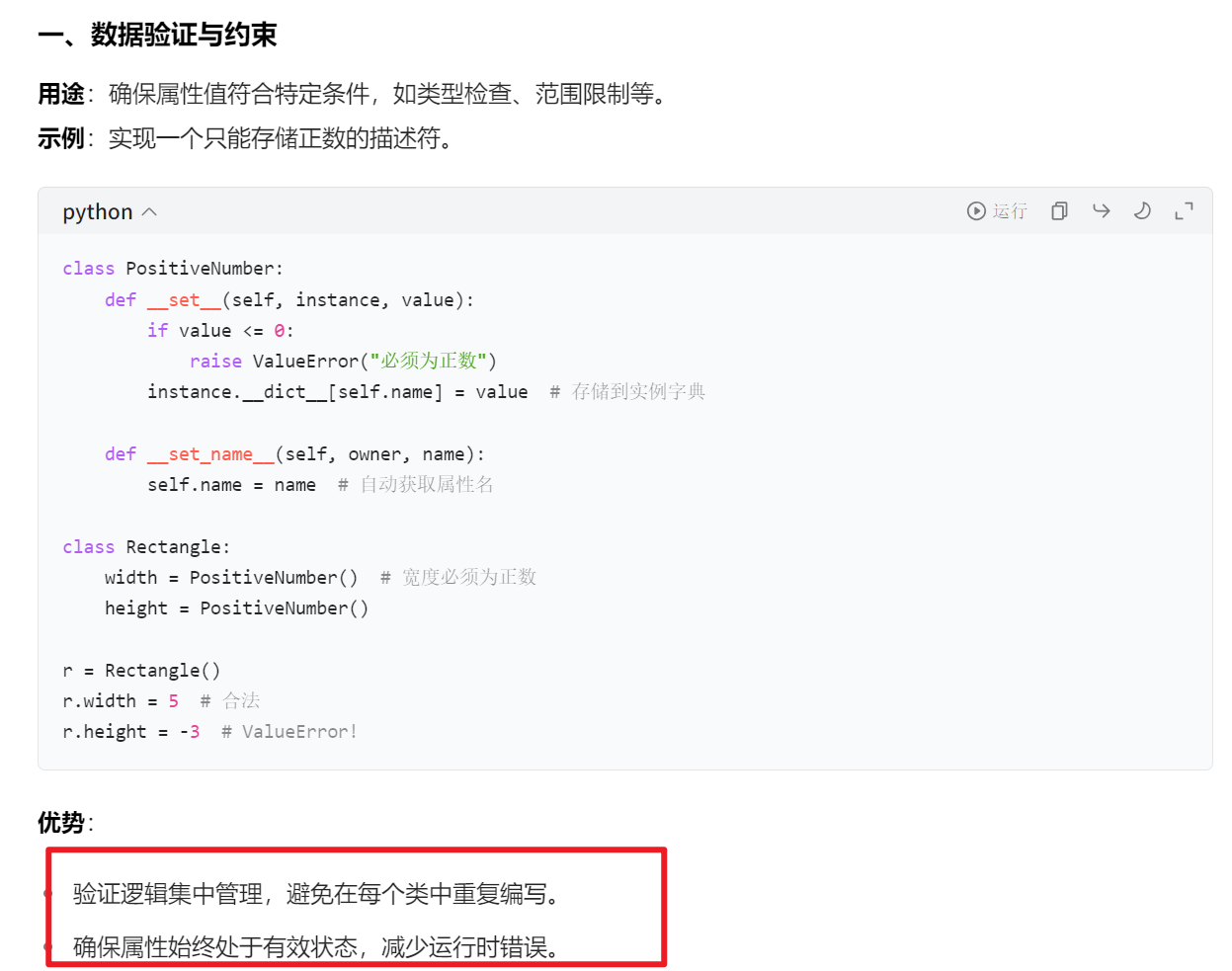
描述符是 Python 中一个很有用的概念,它可以允许你自定义属性访问的行为。简单来说,描述符就是一个类,它实现了__get__、__set__和__delete__这三个方法中的一个或多个。这三个方法分别对应获取属性值、设置属性值和删除属性的操作
描述符协议方法
__get__(self, instance, owner)
用于获取属性值
instance:调用描述符的实例(如果是实例调用)
owner:所有者类
__set__(self, instance, value)
用于设置属性值
instance:调用描述符的实例
value:要设置的值
__delete__(self, instance)
用于删除属性
instance:调用描述符的实例
根据实现的方法不同,描述符分为两类:
数据描述符:同时实现了
__get__和__set__的描述符。
优先级高于实例属性,即当实例字典中存在同名属性时,优先调用描述符。非数据描述符:仅实现了
__get__的描述符(如函数、方法)。
优先级低于实例属性,即当实例字典中存在同名属性时,优先使用实例属性。
class PositiveNumber: def __set__(self, instance, value): if value <= 0: raise ValueError("数值必须为正数") instance.__dict__[self.name] = value # 关键点:存储到实例字典 def __get__(self, instance, owner): if instance is None: return self return instance.__dict__.get(self.name) # 从实例字典读取 def __set_name__(self, owner, name): self.name = name # 存储属性名(Python 3.6+ 支持) class Rectangle: width = PositiveNumber() height = PositiveNumber() r1 = Rectangle() r2 = Rectangle() r1.width = 5 # 存储到 r1 的实例字典 r2.width = 10 # 存储到 r2 的实例字典 print(r1.width) # 5(从 r1 的实例字典读取) print(r2.width) # 10(从 r2 的实例字典读取)

Unicode 字符串
一 基本定义
-
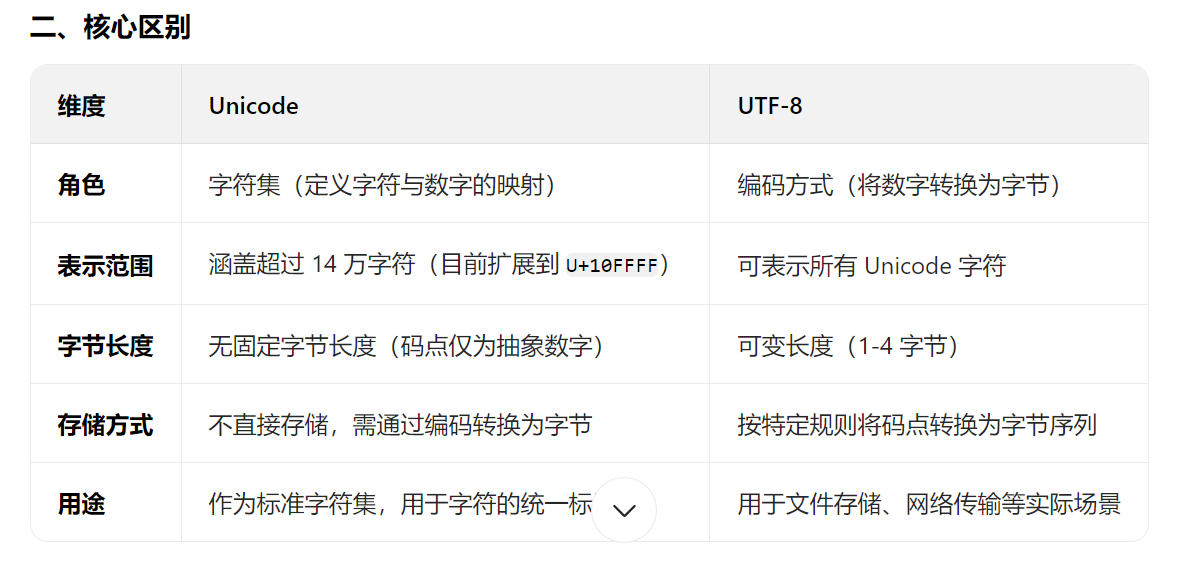
Unicode(统一码)
是一种字符集(Character Set),为世界上几乎所有的字符(包括字母、符号、 emoji 等)分配了唯一的数字编号(称为码点,Code Point)。
例如:A的 Unicode 码点是U+0041中的 Unicode 码点是U+4E2D- 😊 的 Unicode 码点是
U+1F60A
- UTF-8(8-bit Unicode Transformation Format)
是一种编码方式(Encoding),用于将 Unicode 码点转换为计算机可存储和传输的字节序列。
它是 Unicode 的一种实现方式,并非唯一的实现(其他还有 UTF-16、UTF-32 等)
编程语言:Python 3 的字符串(str)默认是 Unicode,需通过 encode()/decode() 转换为 UTF-8 字节
常见的字符集

在Python2中,普通字符串是以8位ASCII码进行存储的,而Unicode字符串则存储为16位unicode字符串,这样能够表示更多的字符集。使用的语法是在字符串前面加上前缀 u。
在Python3中,所有的字符串都是Unicode字符串
Python上下文管理器详解
1. 基本定义
上下文管理器是一个实现了__enter__()和__exit__()方法的对象,用于定义在代码块执行前后应当发生的行为
2.工作原理
执行流程
with ContextManager() as x:
# 执行代码块
...
实际执行顺序:
-
调用
ContextManager().__enter__() -
将
__enter__()返回值赋给x(如果有as子句) -
执行
with代码块 -
无论代码块是否发生异常,都调用
__exit__()
自定义异常
class ErrorHandler:
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
if exc_type is ValueError:
print("处理ValueError")
return True # 抑制异常
# 其他异常会正常传播
with ErrorHandler():
raise ValueError("测试错误") # 这个异常会被捕获
Python标准库中已经内置了许多有用的上下文管理器:
-
open():文件操作 -
threading.Lock():线程锁 -
decimal.localcontext():Decimal运算上下文 -
tempfile.TemporaryFile():临时文件 -
unittest.mock.patch():测试mock
Python 中的 __enter__ 和 __exit__ 方法详解
这两个特殊方法共同构成了 Python 的上下文管理器协议(Context Manager Protocol),用于实现 with 语句的功能,主要作用是资源管理和异常处理
核心作用
1. __enter__ 方法
-
进入上下文时调用:在
with语句开始时执行 -
返回值:可以返回一个对象,该对象会被
as关键字接收 -
典型用途:资源分配(如打开文件、获取锁、连接数据库)
2. __exit__ 方法
-
退出上下文时调用:在
with代码块执行完毕后调用 -
处理异常:可以捕获并处理代码块中发生的异常
-
典型用途:资源释放(如关闭文件、释放锁、断开连接)
__exit__ 方法的三个参数
当 with 代码块中出现异常时,__exit__ 会接收到异常信息:
-
exc_type:异常类型(如ValueError) -
exc_val:异常对象实例 -
exc_tb:traceback 对象
class FileHandler:
def __init__(self, filename, mode):
self.filename = filename
self.mode = mode
def __enter__(self):
self.file = open(self.filename, self.mode)
return self.file # 这个返回值会被 as 接收
def __exit__(self, exc_type, exc_val, exc_tb):
self.file.close()
# 如果返回True,则不会抛出with块内的异常
# 返回None或False则会正常抛出异常
# 使用示例
with FileHandler('test.txt', 'w') as f:
f.write('Hello, context manager!')
# 文件会自动关闭,即使写入时发生异常
关键特点总结
-
资源安全:确保资源总是被正确释放
-
异常处理:可以优雅地处理代码块中的异常
-
代码简洁:避免大量的
try-finally语句 -
可组合性:多个上下文管理器可以嵌套使用
with open('a.txt') as f1, open('b.txt') as f2:
# 同时处理两个文件
data1 = f1.read()
data2 = f2.read()
# 两个文件都会自动关闭
yield用法
yield是Python中用于创建生成器(generator)的关键字,它可以让函数变成一个生成器函数,实现惰性计算和状态保持
1. 创建简单生成器
def simple_generator():
yield 1
yield 2
yield 3
gen = simple_generator()
print(next(gen)) # 输出: 1
print(next(gen)) # 输出: 2
print(next(gen)) # 输出: 3
# print(next(gen)) # 抛出StopIteration异常
2.生成器表达式
numbers = (x for x in range(10) if x % 2 == 0) print(list(numbers)) # 输出: [0, 2, 4, 6, 8]
3.使用send()方法传递值
def accumulator():
total = 0
while True:
value = yield total
if value is None:
break
total += value
acc = accumulator()
next(acc) # 启动生成器
print(acc.send(10)) # 输出: 10
print(acc.send(20)) # 输出: 30
print(acc.send(5)) # 输出: 35
acc.close() # 关闭生成器
4. yield from语法(Python 3.3+)
用于从另一个生成器委托产出值:
def sub_generator():
yield 1
yield 2
def main_generator():
yield '开始'
yield from sub_generator()
yield '结束'
for item in main_generator():
print(item)
# 输出: 开始 1 2 结束
5.协程实现
yield可以用于实现简单的协程:
def coroutine():
while True:
received = yield
print(f"收到: {received}")
co = coroutine()
next(co) # 启动协程
co.send("消息1") # 输出: 收到: 消息1
co.send("消息2") # 输出: 收到: 消息2
sorted用法
sorted()是Python内置的高阶函数,用于对可迭代对象进行排序并返回一个新的已排序列表
sorted(iterable, *, key=None, reverse=False)
参数 说明 iterable要排序的可迭代对象(列表、元组、字符串、字典、集合等) key指定一个函数,用于从每个元素中提取比较键(可选参数) reverse布尔值,True表示降序排序,False表示升序排序(默认为False)
对元组进行排序
tuples = [(1, 'b'), (2, 'a'), (0, 'a')]
tuples_sorted = sorted(tuples, key= lambda x: x[0]) # 前面的tuples要是可迭代的, key是从迭代的元素中获取
print(tuples_sorted)
# 按字符串长度排序 words = ["banana", "pie", "apple", "orange"] words_sorted = sorted(words, key=lambda x: len(x)) print(words_sorted) # 输出: ['pie', 'apple', 'banana', 'orange']
#多条件排序
students = [
{"name": "Alice", "score": 85},
{"name": "Bob", "score": 90},
{"name": "Charlie", "score": 85}
]
sorted_students = sorted(students, key=lambda x: (-x["score"], x["name"]))
print(sorted_students)
#对字典按照键 或者键值排序
grades = {'Alice': 85, 'Bob': 90, 'Charlie': 78} # 按键排序 sorted_by_name = sorted(grades.items()) print(sorted_by_name) # [('Alice', 85), ('Bob', 90), ('Charlie', 78)] # 按值排序 sorted_by_grade = sorted(grades.items(), key=lambda x: x[1]) # 注意这里要使用grades.items() ,因为是grades.items()才是可迭代的 print(sorted_by_grade) # [('Charlie', 78), ('Alice', 85), ('Bob', 90)]
collections模块
1. defaultdict
功能:带有默认值的字典,当访问不存在的键时不会抛出KeyError
使用场景:统计、分组、构建字典的字典等
from collections import defaultdict
# 示例1:统计单词出现次数
word_counts = defaultdict(int) # 默认值为0
for word in ['apple', 'banana', 'apple', 'orange']:
word_counts[word] += 1
# defaultdict(<class 'int'>, {'apple': 2, 'banana': 1, 'orange': 1})
# 示例2:按首字母分组
words_by_letter = defaultdict(list) # 默认值为空列表
for word in ['apple', 'banana', 'orange', 'avocado']:
words_by_letter[word[0]].append(word)
# defaultdict(<class 'list'>, {'a': ['apple', 'avocado'], 'b': ['banana'], 'o': ['orange']})
# 按照类别分组
data = [('apple', 'fruit'), ('banana', 'fruit'), ('carrot', 'vegetable')]
categories = defaultdict(list)
for name , categorie in data:
categories[categorie].append(name)
print(dict(categories))
和 dict.setdefault() 的对比
d = {'a': 1, 'b': 2}# 键不存在的情况 print(d.setdefault('c', 3)) # 输出: 3 print(d) # 输出: {'a': 1, 'b': 2, 'c': 3}
setdefault与普通赋值的比较
传统方式(使用if判断)
d = {} if 'count' not in d: d['count'] = 0 d['count'] += 1使用setdefault()简化
d = {} d['count'] = d.setdefault('count', 0) + 1
2. Counter
功能:计数器,用于统计可哈希对象的出现次数
使用场景:频率统计、TopN问题等
from collections import Counter
# 示例1:统计元素出现次数
cnt = Counter(['red', 'blue', 'red', 'green', 'blue', 'blue'])
print(cnt) # Counter({'blue': 3, 'red': 2, 'green': 1})
# 示例2:获取出现次数最多的2个元素
print(cnt.most_common(2)) # [('blue', 3), ('red', 2)]
# 示例3:统计文本中的单词频率
words = "how many times does each word show up in this sentence".split()
word_counts = Counter(words)
print(word_counts.most_common(3))
3. deque
功能:双端队列,线程安全,两端都能高效地添加和删除元素
使用场景:队列、栈、滑动窗口、广度优先搜索等
from collections import deque
# 示例1:作为队列使用
d = deque()
d.append('a') # 右端添加
d.appendleft('b') # 左端添加
print(d) # deque(['b', 'a'])
d.pop() # 右端删除
d.popleft() # 左端删除
# 示例2:固定大小队列
last_three = deque(maxlen=3)
for i in range(5):
last_three.append(i)
print(last_three)
# deque([0], maxlen=3)
# deque([0, 1], maxlen=3)
# deque([0, 1, 2], maxlen=3)
# deque([1, 2, 3], maxlen=3)
4. namedtuple
功能:命名元组,创建带有字段名的元组子类
使用场景:替代简单的类,使代码更易读
from collections import namedtuple
# 示例1:定义Point结构
Point = namedtuple('Point', ['x', 'y'])
p = Point(11, y=22) # 可以通过位置或关键字参数创建
print(p.x, p.y) # 11 22
print(p[0], p[1]) # 11 22 (也支持索引访问)
# 示例2:替代简单类
Person = namedtuple('Person', ['name', 'age', 'gender'])
bob = Person(name='Bob', age=30, gender='male')
print(f"{bob.name} is {bob.age} years old")
5. OrderedDict (Python 3.7+中dict已有序)
功能:有序字典,记住键的插入顺序
使用场景:需要保持插入顺序的字典操作
from collections import OrderedDict # 示例1:保持插入顺序 d = OrderedDict() d['a'] = 1 d['b'] = 2 d['c'] = 3 print(list(d.keys())) # ['a', 'b', 'c']
6. ChainMap
功能:将多个字典或映射链接在一起,作为一个单独的视图
使用场景:多层级配置、变量作用域模拟等
from collections import ChainMap
# 示例1:合并多个字典
dict1 = {'a': 1, 'b': 2}
dict2 = {'b': 3, 'c': 4}
combined = ChainMap(dict1, dict2)
print(combined['a']) # 1 (来自dict1)
print(combined['b']) # 2 (来自dict1,dict1优先)
print(combined['c']) # 4 (来自dict2
json
json的概念: JavaScript 对象表示法(JavaScript Object Notation) , 是轻量级的文本数据交换格式
import json
# Python 字典类型转换为 JSON 对象
data1 = {
'no' : 1,
'name' : 'Runoob',
'url' : 'http://www.runoob.com'
}
json_str = json.dumps(data1)
print ("Python 原始数据:", repr(data1))
print ("JSON 对象:", json_str)
# 将 JSON 对象转换为 Python 字典
data2 = json.loads(json_str)
print ("data2['name']: ", data2['name'])
print ("data2['url']: ", data2['url'])如果你要处理的是文件而不是字符串,你可以使用 json.dump() 和 json.load() 来编码和解码JSON数据
import json
# 准备要存储的Python数据结构
data = {
"name": "张三",
"age": 30,
"is_student": False,
"courses": ["数学", "英语", "计算机"],
"address": {
"street": "人民路123号",
"city": "北京"
}
}
# 将数据写入JSON文件
with open('user_data.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
print("数据已写入 user_data.json")
# 从JSON文件读取数据
with open('user_data.json', 'r', encoding='utf-8') as f:
loaded_data = json.load(f)
print("从文件加载的数据:")
print(loaded_data)json 和 字典的区别
| 特性 | JSON | Python 字典(dict) |
|---|---|---|
| 本质 | 一种数据交换格式(字符串) | Python 内置的数据结构(内存中的对象) |
| 键的类型 | 只能是字符串(必须用双引号 " 包裹) |
可以是任意可哈希类型(字符串、数字、元组等) |
| 值的类型 | 支持字符串、数字、布尔值、null、列表、JSON 对象 |
支持 Python 所有数据类型(如 None、tuple、set、函数等) |
| 语法细节 | 字符串必须用双引号 ";末尾不能有逗号 |
字符串可用单引号 ' 或双引号 ";末尾可有逗号 |
| 布尔值 | true、false(小写) |
True、False(大写) |
| 空值 | null |
None |
| 注释 | 不支持注释 | 支持注释(作为 Python 代码的一部分) |
| 用途 | 数据传输(如 API 接口)、数据存储 | Python 程序内部的数据处理 |
正则表达式
正则表达式的模式可以包括以下内容
-
字面值字符:例如字母、数字、空格等,可以直接匹配它们自身
-
特殊字符:例如点号
.、星号*、加号+、问号?等,它们具有特殊的含义和功能
. |
匹配任意字符(除换行符) | a.c → 'abc', 'a c' |
记忆: 任意一点 |
-
字符类:用方括号
[ ]包围的字符集合,用于匹配方括号内的任意一个字符。
| [ ] | 匹配括号内的任意一个字符 | [abc] 匹配字符a,b或者c | 记忆:像购物清单[ ],选一个 |
| ` | ` | 或 | b 记忆: 像管道分流→ "左边或右边" |
( ... ) |
分组捕获 |
|
记忆:括号→ "圈起来当一组" |
| | | 竖线 | 是 逻辑“或”运算符,用于匹配多个模式中的任意一个 |
-
元字符:例如
\d、\w、\s等,用于匹配特定类型的字符,如数字、字母、空白字符等
\d |
数字([0-9]) |
\d+ → '123' |
记忆: Digit 数字(0-9 的单个字符) |
\D |
非数字([^0-9]) |
\D+ → 'abc' |
|
\s |
空白字符(空格、制表符等) | a\sb → 'a b' |
记忆:space 空格(ASCII 32),最常见的空白字符 |
\S |
非空白字符 | \S+ → 'abc' |
|
\w |
单词字符([a-zA-Z0-9_]) ,匹配字母、数字、下划线 |
\w+ → 'abc_123' |
记忆:Word 单词 |
\W |
非单词字符 | \W+ → '@#$' |
-
量词:例如
{n}、{n,}、{n,m}等,用于指定匹配的次数或范围。
* |
0 次或多次 | a* → '', 'a', 'aa' |
记忆:* 像0 |
+ |
1 次或多次 | a+ → 'a', 'aa' |
记忆:加号→ "至少一个" |
? |
0 次或 1 次 | a? → '', 'a' |
记忆:? 到底值0 还是 1 |
{n} |
精确匹配 n 次 | a{2} → 'aa' |
|
{n,} |
至少 n 次 | a{2,} → 'aa', 'aaa' |
|
{n,m} |
n 到 m 次 | a{2,3} → 'aa', 'aaa' |
-
边界符号:例如
^、$、\b、\B等,用于匹配字符串的开头、结尾或单词边界位置
| ^ | 匹配字符串开头 | ^abc → 以 'abc' 开头 |
场景:正则行首 , 命名为: 脱字符 , 作用:匹配字符串开头 记忆:像箭头↑指向开头 场景: 字符组内 , 命名为:否定符, 作用:排除指定字符(如 |
$ |
匹配字符串结尾 | abc$ → 以 'abc' 结尾 |
记忆:美元符号结尾 |
| \b | 匹配单词边界 用于匹配单词的开始或结束位置,而不是实际的字符 |
匹配单词的开头:以word开头的单词 \bword 匹配单词的结尾: word\b 匹配整个单词: \bword\b |
记忆:boundary(边界) |
| \B | 匹配非单词边界 |
| 语法 | 作用 | 示例 |
|---|---|---|
\bword |
匹配以 "word" 开头的单词 |
"word", "wordless" |
word\b |
匹配以 "word" 结尾的单词 |
"password", "myword" |
\bword\b |
精确匹配独立单词 | "this is a word" |
\Bword\B |
匹配单词中间部分 | "sword" 中的 "word" |
举例:
邮箱验证
-
模式:
\w+@\w+\.\w+-
\w+是单词字符,@和.是字面符号 →user@example.com -
其中 \. 是将. 做了转义
-
在正则中,以下字符需用
\转义才能匹配字面意义. * ? + ^ $ [ ] { } ( ) | \
真实邮箱验证需更严谨的正则:
r'^[\w.-]+@[\w.-]+\.[a-zA-Z]{2,}$'
正则验证地址:regex101: build, test, and debug regex
正则表达式中: ?=、?<=、?!、?<! 的使用和区别 (后续再看,todo)
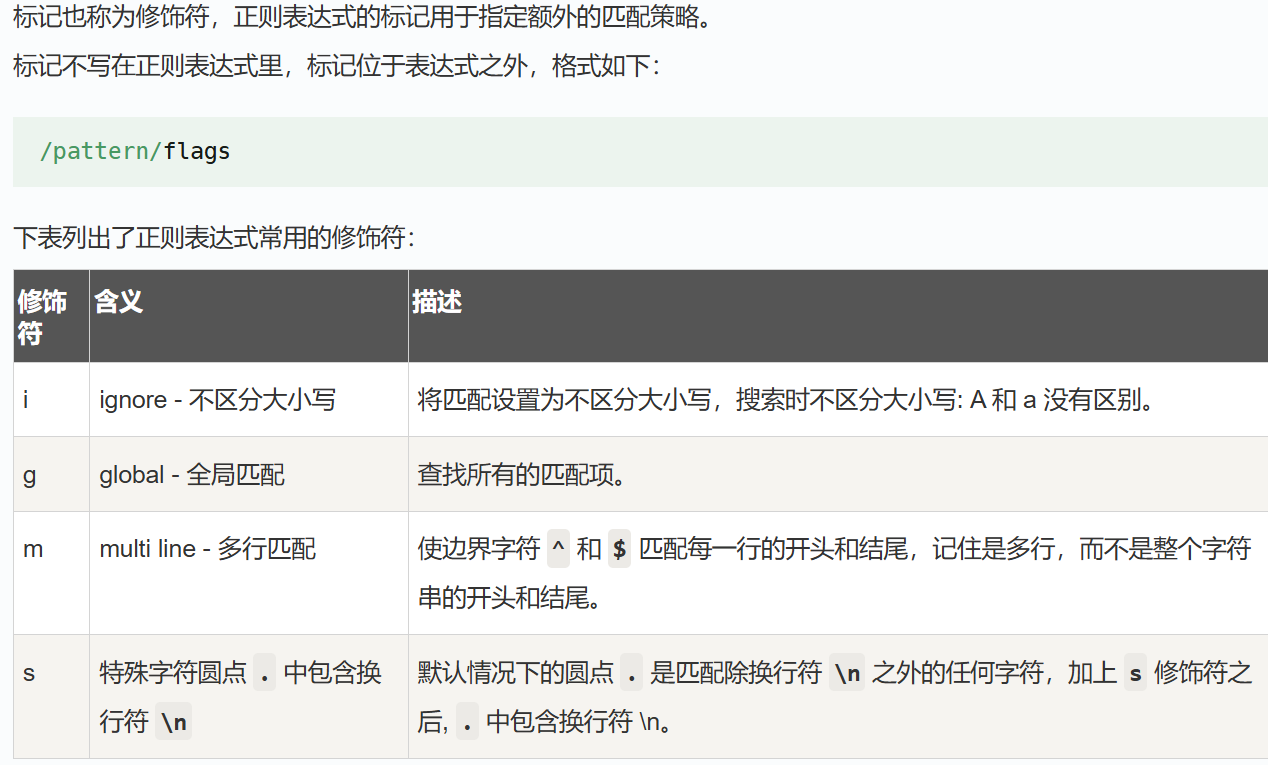
正则表达式-修饰符
123.raise的使用
1. 基本用法
1.1 引发内置异常
# 引发一个简单的 ValueError raise ValueError("这是一个错误消息") # 等价于 raise ValueError("这是一个错误消息")输出:
Traceback (most recent call last):
File "D:\File\StudyPython\test.py", line 1552, in <module>
raise ValueError("error")
ValueError: error
1.2 重新引发当前异常
在异常处理块中,可以使用不带参数的 raise 重新引发当前正在处理的异常:
try:
# 某些可能出错的代码
x = 1 / 0
except ZeroDivisionError:
print("捕获到除零错误")
raise # 重新引发相同的异常
与 try-except 的关系:raise 和 try-except 通常配合使用:
def process_data(data):
if not data:
raise ValueError("数据不能为空")
# 处理数据...
try:
process_data(None)
except ValueError as e:
print(f"捕获到错误: {e}")
122.pickle模块(序列化 和反序列化)
pickle 是 Python 的标准模块,用于对象序列化和反序列化(即 Python 对象的持久化存储和恢复) ,它可以将 Python 对象转换为字节流(序列化),也可以从字节流重建对象(反序列化)
#序列化
import pickle
data = {
'name': 'Alice',
'age': 30,
'hobbies': ['reading', 'hiking']
}
# 序列化到文件
with open('data.pkl', 'wb') as f:
pickle.dump(data, f)
# 序列化为字节串
data_bytes = pickle.dumps(data)
print(data_bytes) # 输出字节串
#反序列化
# 从文件反序列化
with open('data.pkl', 'rb') as f:
loaded_data = pickle.load(f)
print(loaded_data)
# 从字节串反序列化
original_data = pickle.loads(data_bytes)
print(original_data)
121.python中对象销毁(垃圾回收)
在 Python 中,对象回收是通过垃圾回收机制(Garbage Collection, GC)来管理的。Python 使用引用计数作为主要的内存管理机制,并结合循环垃圾收集器来处理循环引用的情况。以下是 Python 对象回收的详细说明
1. 引用计数(Reference Counting)
Python 中的每个对象都有一个引用计数,用于记录有多少个引用指向该对象。当引用计数降为 0 时,对象就会被立即回收。
引用计数的规则:
-
当对象被创建时,引用计数为 1。
-
当对象被赋值给变量、添加到容器(如列表、字典)或作为参数传递时,引用计数增加。
-
当变量被重新赋值、离开作用域或容器被删除时,引用计数减少。
-
当引用计数降为 0 时,对象会被立即销毁,内存被释放。
import sys # 创建一个对象 a = [1, 2, 3] print(sys.getrefcount(a)) # 输出引用计数,此时为 2(a + getrefcount 的参数) # 增加引用 b = a print(sys.getrefcount(a)) # 输出引用计数,此时为 3(a, b + getrefcount 的参数) # 减少引用 del b print(sys.getrefcount(a)) # 输出引用计数,此时为 2(a + getrefcount 的参数) # 减少引用 del a # 此时引用计数为 0,对象被回收
2. 循环垃圾收集器(Cycle Detector)
引用计数无法处理循环引用的情况。例如,两个对象互相引用,但没有外部引用指向它们,它们的引用计数永远不会降为 0,导致内存泄漏。为了解决这个问题,Python 引入了循环垃圾收集器。
循环垃圾收集器的工作原理:
-
Python 的垃圾收集器会定期检查对象之间的引用关系。
-
如果发现一组对象互相引用,但没有外部引用指向它们,这组对象就会被标记为垃圾并回收。
class Node:
def __init__(self, value):
self.value = value
self.next = None
# 创建循环引用
node1 = Node(1)
node2 = Node(2)
node1.next = node2
node2.next = node1
# 删除外部引用
del node1
del node2
# 此时 node1 和 node2 互相引用,但引用计数不为 0
# 循环垃圾收集器会检测到这种情况并回收它们
3.垃圾回收的触发时机
Python 的垃圾回收机制会在以下情况下触发:
-
引用计数降为 0:对象会被立即回收。
-
显式调用
gc.collect():手动触发垃圾回收。 -
达到阈值:Python 的垃圾收集器会根据对象的分配和释放情况动态调整阈值,当达到阈值时会自动触发垃圾回收。
示例:手动触发垃圾回收
import gc # 创建一些对象 a = [1, 2, 3] b = [4, 5, 6] a.append(b) b.append(a) # 删除外部引用 del a del b # 手动触发垃圾回收 gc.collect() # 返回回收的对象数量
4. __del__ 方法
Python 提供了一个 __del__ 方法,可以在对象被回收时执行一些清理操作。但需要注意:
-
__del__的调用时机依赖于垃圾回收器,不能保证立即执行。 -
如果对象之间存在循环引用,
__del__可能不会被调用。
class MyClass:
def __init__(self, name):
self.name = name
def __del__(self):
print(f"Object {self.name} is being destroyed")
# 创建对象
obj = MyClass("example")
# 删除对象
del obj # 输出: Object example is being destroyed
120. file中的seek方法使用
在 Python 中,io.UnsupportedOperation: can't do nonzero cur-relative seeks 错误通常发生在尝试以文本模式('r' 或 'w')打开文件并使用 seek() 方法时,传递了非零的 offset 和 from=1(相对当前位置)或 from=2(相对文件末尾)参数
错误原因
在文本模式下,Python 的文件对象不支持基于当前位置或文件末尾的非零偏移量(cur-relative seeks 或 end-relative seeks)。这是因为文本模式下的文件内容可能会被编码(如 UTF-8),导致字节偏移量与字符偏移量不一致,从而无法准确计算位置
解决方法
方法 1:使用二进制模式
如果你需要基于当前位置或文件末尾进行 seek() 操作,可以以二进制模式('rb' 或 'wb')打开文件。二进制模式下,seek() 的行为是精确的,支持任意偏移量和参考位置。
with open('example.txt', 'rb') as f: # 以二进制模式打开文件 f.seek(5, 1) # 从当前位置移动5个字节 data = f.read(10) # 读取10个字节 print(data)但是这种情况下返回的是二进制的文本
需要再将decode转文本格式
data = data.decode(encoding="utf-8", errors="strict")
方法 2:仅使用从文件开头的 seek()
如果你必须在文本模式下操作,可以只使用从文件开头(from=0)的 seek(),这是文本模式下唯一支持的方式。
with open('example.txt', 'r') as f: # 以文本模式打开文件
f.seek(10) # 从文件开头移动10个字节
data = f.read(5) # 读取5个字符
print(data)
方法 3:手动计算位置
如果你需要从文件末尾或当前位置移动指针,可以先用 tell() 获取当前位置,然后手动计算偏移量,再使用 seek(offset, 0)。
with open('example.txt', 'r') as f:
current_pos = f.tell() # 获取当前位置
f.seek(current_pos + 5, 0) # 手动计算偏移量,从文件开头移动
data = f.read(5)
print(data)
119. 列表推导式
示例:
# 生成平方式列表
s = [x**2 for x in range(10)]
# 嵌套列表推导式
matrix = [ [i +j for j in range(3) ] for i in range(3)]
等效于:
matrix = [] # 初始化一个空列表
for i in range(3): # 外层循环,i 从 0 到 2
row = [] # 初始化一个空行
for j in range(3): # 内层循环,j 从 0 到 2
row.append(i + j) # 将 i + j 的结果添加到当前行
matrix.append(row) # 将当前行添加到矩阵中
# 带条件生成列表
num = [i for i in numbers if i >0 and i < 5 ]列表推导式 和 map filter 对比:
# map, filter
numbers = [1, 2, 3, 4, 5]
squared_evens = list(map(lambda x: x ** 2, filter(lambda x: x % 2 == 0, numbers)))
# 列表推导式
numbers = [1, 2, 3, 4, 5]
squared_evens = [x ** 2 for x in numbers if x % 2 == 0]
118. python 函数的参数传递
-
不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
-
可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
117.calendar模块的使用
(1) 判断闰年
使用 isleap() 函数判断某年是否为闰年。
print(calendar.isleap(2024)) # True
print(calendar.isleap(2023)) # False&nbs
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3274
3274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









