






kafka
参考:Kafka基本原理详解(超详细!)-腾讯云开发者社区-腾讯云
概念
kafka是一款分布式的基于发布/订阅模式的消息队列,是目前比较主流的消息中间件,Kafka对消息保存时根据Topic(主题)进行归类,发送消息者称为Producer,消息接受者称为Consumer
kafka的特点 (两高两可一容错)
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
- 高并发:支持数千个客户端同时读写
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
Kafka 的核心概念
1.1 Topic(主题)
-
Topic 是 Kafka 中数据存储的逻辑分类,类似于数据库中的表。
-
生产者将消息发布到特定的 Topic,消费者从 Topic 订阅并消费消息。
-
一个 Kafka 集群可以有多个 Topic。
1.2 Partition(分区)
-
每个 Topic 可以分为多个 Partition,分区是 Kafka 实现高吞吐量和并行处理的基础。
-
每个分区是一个有序的、不可变的消息队列。
-
分区允许 Topic 的数据分布在多个服务器上,从而实现水平扩展。
1.3 Producer(生产者)
-
Producer 是向 Kafka Topic 发布消息的客户端。
-
生产者可以将消息发送到指定的 Topic 和 Partition。
1.4 Consumer(消费者)
-
Consumer 是从 Kafka Topic 订阅并消费消息的客户端。
-
消费者可以以组(Consumer Group)的形式工作,组内的消费者共同消费一个 Topic 的消息,实现负载均衡。
1.5 Broker(代理)
-
Broker 是 Kafka 集群中的单个服务器节点。
-
每个 Broker 负责存储和管理一个或多个 Partition。
-
多个 Broker 组成一个 Kafka 集群。
一台kafka服务器就是一个broker。一个集群由多个broker组成,每个broker就是一个kafka的实例
1.6 Offset(偏移量)
-
Offset 是消息在 Partition 中的唯一标识,表示消息的位置。
-
消费者通过维护 Offset 来记录自己消费到的位置。
1.7 Consumer Group(消费者组)
-
Consumer Group 是一组消费者的集合,共同消费一个 Topic 的消息。
-
Kafka 会将 Topic 的 Partition 分配给组内的消费者,确保每条消息只被组内的一个消费者消费。
1.8 Replication(副本)
-
Kafka 通过 Replication 实现数据的高可用性。
-
每个 Partition 可以有多个副本,其中一个副本是 Leader,负责处理读写请求,其他副本是 Follower,用于数据备份。
Kafka 的架构
2.1 生产者-消费者模型
-
生产者将消息发布到 Kafka Topic。
-
消费者从 Topic 订阅并消费消息。
2.2 分布式存储
-
Kafka 的数据分布在多个 Broker 上,每个 Broker 存储一部分 Partition。
-
通过分区和副本机制,Kafka 实现了高可用性和负载均衡。
2.3 ZooKeeper 的作用
-
Kafka 依赖 ZooKeeper 来管理集群元数据、Broker 状态、消费者 Offset 等。
-
从 Kafka 2.8.0 开始,Kafka 引入了 KRaft 模式,可以不再依赖 ZooKeeper。
Kafka场景应用
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
- 事件源
python连接kafka
1. confluent-kafka (推荐)
特点
-
底层基于 C 库(librdkafka):性能极高,支持所有 Kafka 特性(如事务、压缩)。
-
官方维护:由 Confluent(Kafka 商业化公司)提供支持,更新及时。
-
生产级稳定性:适合高吞吐、低延迟场景。
pip install confluent-kafkafrom confluent_kafka import Producer, Consumer
from confluent_kafka import Producer, Consumer # 生产者 producer = Producer({ 'bootstrap.servers': 'localhost:9092', 'acks': 'all' # 确保消息不丢失 }) producer.produce('my_topic', key='key', value='message') producer.flush() # 确保所有消息发送完成 # 消费者 consumer = Consumer({ 'bootstrap.servers': 'localhost:9092', 'group.id': 'my_group', 'auto.offset.reset': 'earliest' # 从最早的消息开始消费 }) consumer.subscribe(['my_topic']) while True: msg = consumer.poll(1.0) # 超时时间1秒 if msg is None: continue print(f"Received: {msg.value().decode('utf-8')}")
2. kafka-python
特点
-
纯 Python 实现:易于调试和扩展,但性能低于
confluent-kafka。 -
API 简洁:适合快速原型开发和小规模应用。
-
社区活跃:文档丰富,GitHub 问题响应快
pip install kafka-pythonfrom kafka import KafkaProducer, KafkaConsumer # 生产者 producer = KafkaProducer( bootstrap_servers=['localhost:9092'], value_serializer=lambda x: x.encode('utf-8') ) producer.send('my_topic', value='message') producer.flush() # 消费者 consumer = KafkaConsumer( 'my_topic', bootstrap_servers=['localhost:9092'], group_id='my_group', auto_offset_reset='earliest' ) for msg in consumer: print(f"Received: {msg.value.decode('utf-8')}")
redis
参考:
redis详解: https://zhuanlan.zhihu.com/p/663851226
Redis(Remote Dictionary Server ),即远程字典服务, 开源的(BSD许可)高性能非关系型(NoSQL)的键值对 数据库
Redis常用的五种基本类型
-
string:字符串数据类型
-
list:表示一种线性数据结构,队列或栈
-
hash:类似于对象,map的形式 , 在Redis中,hash哈希被称为字典(dictionary),Redis的字典使用哈希表作为底层实现,一个哈希表里面可以有多个哈希表节点,而每个哈希表节点保存了字典中的一个键值对
-
set:无序不可重复集合 : 集合这种数据类型用来存储一组不重复的数据。这种数据类型也有两种实现方法,一种是基于有序数组,另一种是基于散列表
-
zset:有序不可重复集合
使用redis有哪些好处?
1.速度快,数据存储在内存中
2.支持丰富的数据类型
3.支持事务,操作都是原子性的
4.丰富的特性:可用于缓存消息,按照key设置过期消息,过期后将会自动删除
基本键操作
SET key value # 设置键值 GET key # 获取键值 DEL key [key ...] # 删除键 EXISTS key # 检查键是否存在 TYPE key # 获取键的数据类型
键过期管理
EXPIRE key seconds # 设置键过期时间(秒) TTL key # 查看键剩余生存时间(秒) PERSIST key # 移除键的过期时间
redis过期键的删除策略
1.定时删除:在设置键的过期时间的同时,创建一个定时器,让定时器在键的过期时间来临时,立即执行对键的删除操作
2.惰性删除:放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键,如果没有过期,就返回该键
3.定期删除:每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键
ES (Elasticsearch) 核心概念速查
参考:Elasticsearch(看这一篇就够了)-CSDN博客
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎
基本概念
-
全文搜索引擎 - 基于Lucene的分布式搜索分析引擎
-
近实时(NRT) - 数据写入后约1秒可查
-
RESTful API - 所有操作通过HTTP接口完成
-
JSON文档存储 - 数据以JSON格式存储
常用工具: Kibana - 数据可视化平台
jenkins
Jenkins是一个开源的、提供友好操作界面的持续集成(CI)工具,广泛用于项目开发,具有自动化构建、测试和部署等功能
CI/CD 是持续集成(Continuous Integration,CI)、持续交付(Continuous Delivery,CD)与持续部署(Continuous Deployment,CD)的简称
Jenkins教程(自动化部署) 【转】 - paul_hch - 博客园
rabbitmq
爆肝3万字,为你吃透RabbitMQ,最详细的RabbitMQ讲解(VIP典藏版)-腾讯云开发者社区-腾讯云
RabbitMQ是一个消息中间件:它接受并转发消息
一、消息队列的核心作用
| 功能 | 说明 |
|---|---|
| 解耦 | 生产者和消费者无需直接交互,通过MQ通信。 |
| 异步 | 生产者发送消息后无需等待消费者处理,提高系统响应速度。 |
| 削峰填谷 | 缓冲突发流量,避免系统过载(如秒杀场景)。 |
| 顺序保证 | 通过队列特性保证消息顺序(如Kafka分区)。 |
| 最终一致性 | 分布式事务中,通过MQ实现事务补偿(如订单支付超时取消)。 |
四大核心概念:
- 生产者:产生数据发送消息的程序是生产者
- 交换机:一方面接收来自生产者的消息,一方面将消息推送到队列中。 交换机必须确切知道如何处理它接受到的消息,是将这些消息推送到特定队列还是多个队列,或者是要把消息丢弃,这个得有交换机类型决定
- 队列:队列是rabbitmq内部使用的一种数据结构,许多生产者将消息发送到一个队列,许多消费者可以尝试从一个队列接收数据
- 消费者:等待接收消息的程序
为什么要用rabbitmq
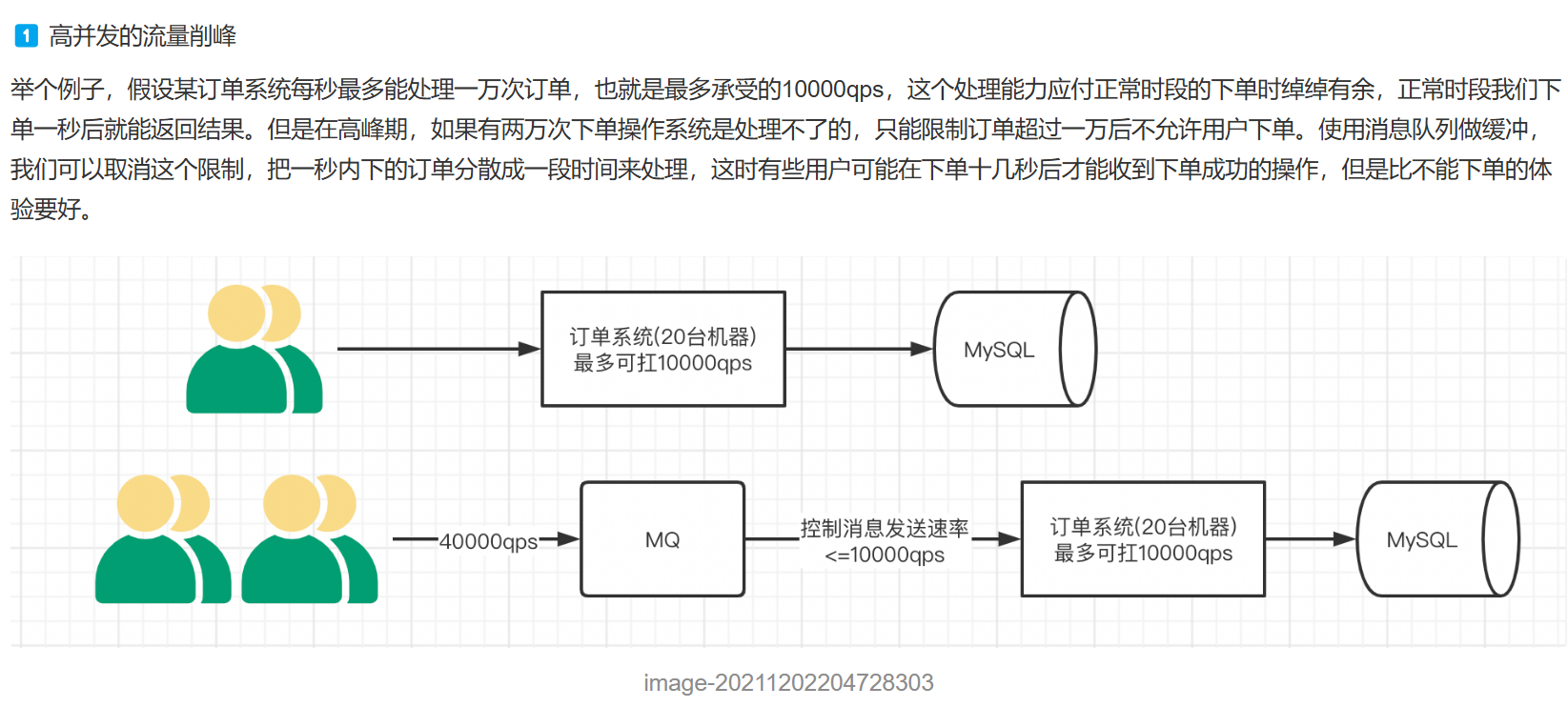
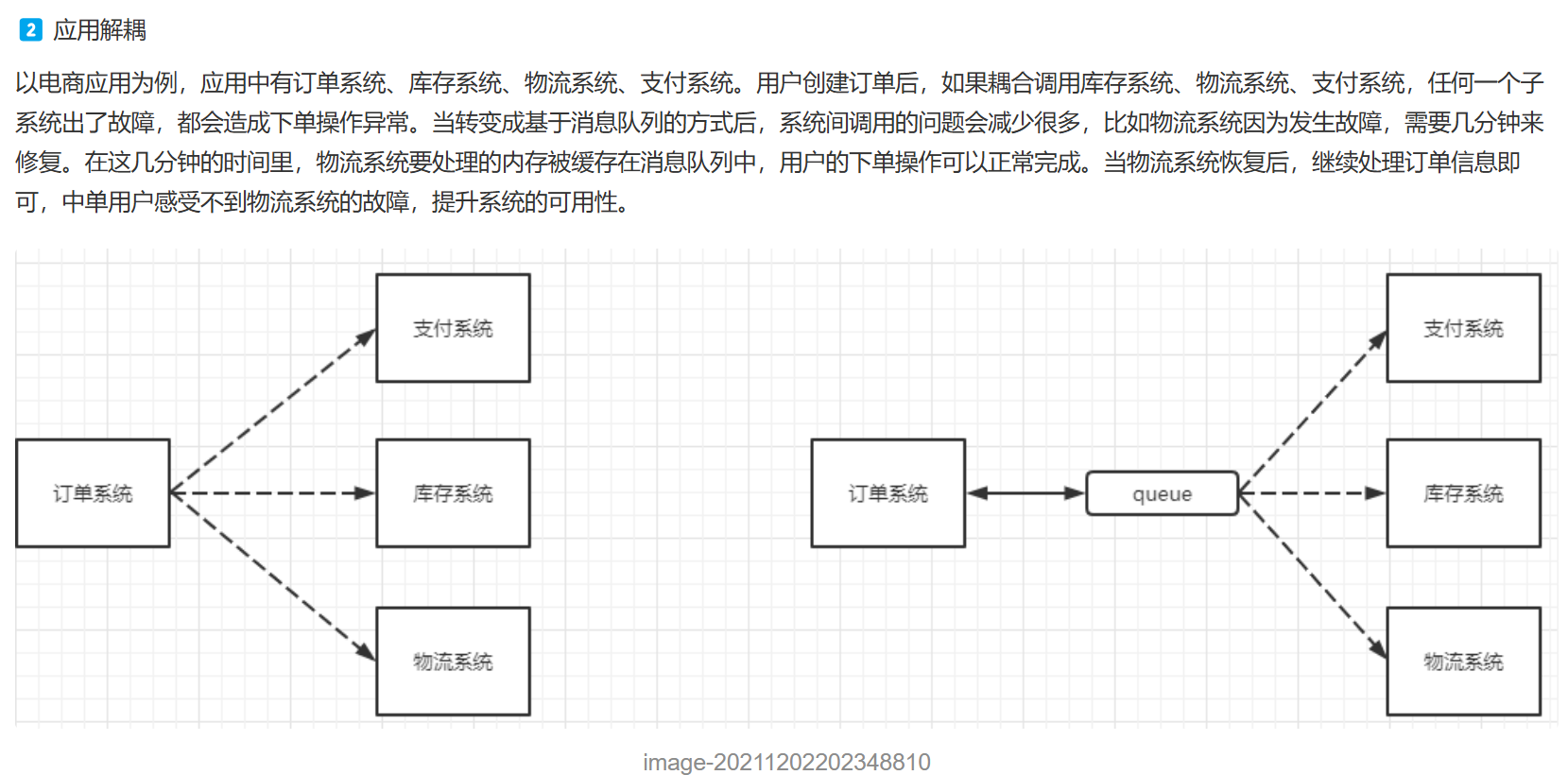
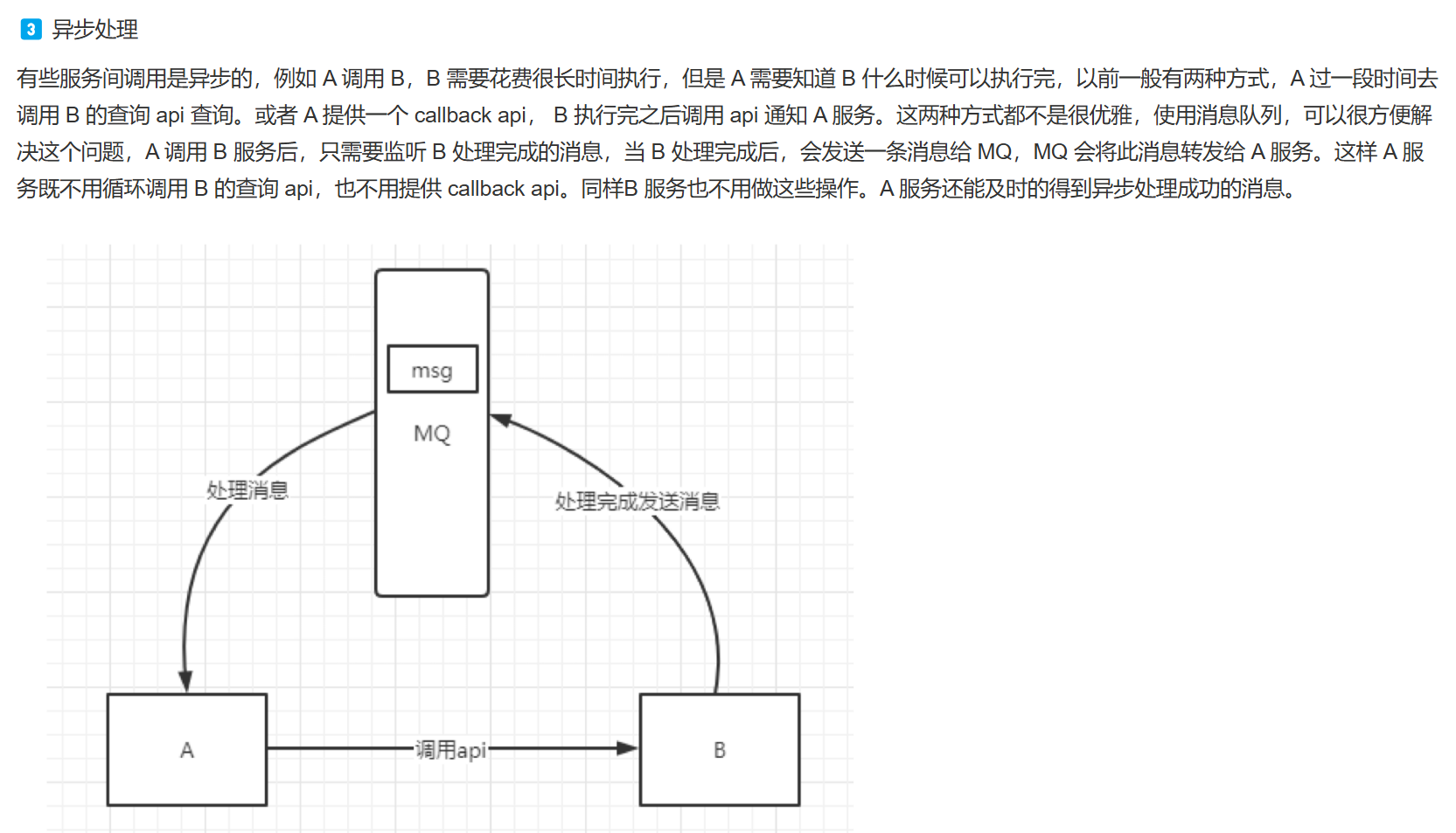
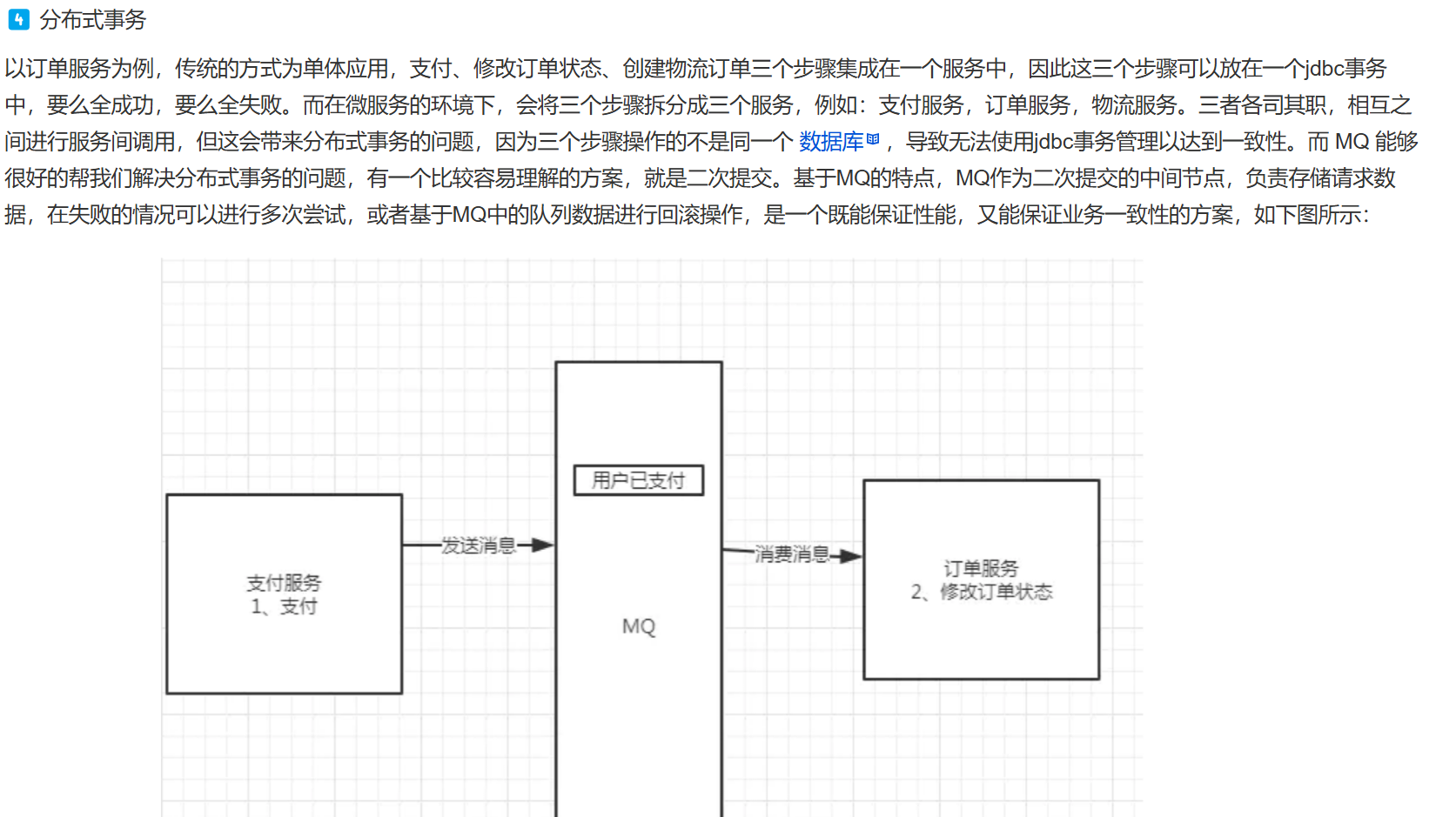
工作原理:
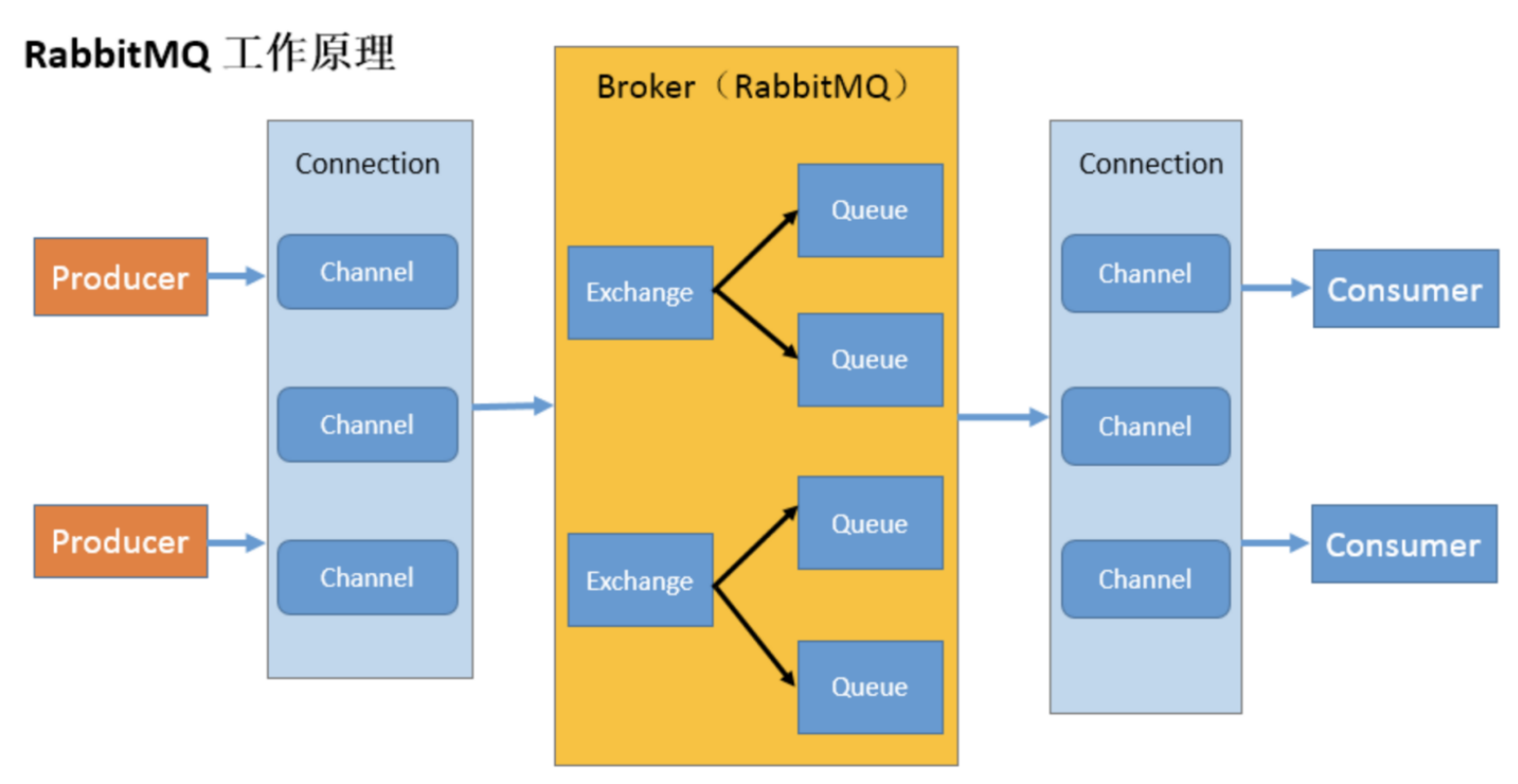
- Producter-Consumer:生产者-消费者
- Broker:接收和分发消息的应用,RabbitMQ Server(RabbitMQ服务器)就是Message Broker(消息实体)
- Connection(连接):publisher/consumer和broker之间的TCP连接
- Channel(信道):如果每一次访问 RabbitMQ 都建立一个Connection,在消息量大的时候建立 TCP Connection的开销将是巨大的,效率也较低。Channel是在connection内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread创建单独的channel进行通讯,AMQP method包含了channel id 帮助客户端和message broker 识别 channel,所以channel之间是完全隔离的。Channel作为轻量级的Connection极大减少了操作系统建立TCP connection的开销
- Exchange(交换机):message 到达 broker 的第一站,根据分发规则,匹配查询表中的 routing key,分发消息到queue 中去。常用的类型有:direct (point-to-point), topic (publish-subscribe) and fanout (multicast)
- Queue(队列):消息最终被送到这里等待consumer取走
- Binding(绑定):exchange和queue之间的虚拟连接,binding中可以包含routing key,Binding信息被保存到exchange中的查询表中,用于message的分发依据
kafka和rabbitmq的对比

kafka 和redis的对比
| kafka | redis | |
| 主要用途 | 基于发布-订阅模式的消息队列, 具有高吞吐量,高并发的特点 | 高性能的非关系型数据库 |
| 使用场景 |
|
|
RESTful的概念
一种通用的前后台交互方式
RESTful一般是指这种格式:
(1)使用HTTP POST(或GET)进行数据交互
(2)请求数据和应答数据均为JSON格式
CPU、内存、磁盘I/O的核心概念详解
CPU(中央处理器)
1. 本质作用
-
计算机的"大脑":负责执行程序指令和数据处理
-
运算核心:所有计算操作最终都由CPU完成
# Linux查看CPU信息命令 $ lscpu Architecture: x86_64 CPU(s): 16 # 逻辑CPU数量 Thread(s) per core: 2 # 每个核心的线程数 Model name: Intel(R) Xeon(R) Gold 6248R CPU MHz: 3000.000 # 主频
2. 性能关注点
-
使用率:非空闲时间占比(理想值:70%以下)
-
负载:运行队列中的平均进程数(1分钟/5分钟/15分钟)
-
上下文切换:进程切换带来的开销
3. 现实类比
就像餐厅的厨师:
-
厨师数量=CPU核心数
-
做菜速度=CPU主频
-
待做订单=CPU队列
内存(RAM)
1. 本质作用
-
临时工作区:存放正在运行的程序和数据
-
CPU与磁盘的缓冲层:比磁盘快100,000倍
# Linux查看内存命令
$ free -h
total used free
Mem: 62G 58G 3.8G # 物理内存
Swap: 8.0G 2.1G 5.9G # 交换分区
2.性能关注点
-
使用率:过高会触发OOM Killer
-
Swap使用:频繁交换说明物理内存不足
-
缓存命中率:越高性能越好
3. 现实类比
像厨师的工作台:
-
台面大小=内存容量
-
食材摆放=内存数据组织
-
从冰箱取料=磁盘交换
磁盘I/O(输入/输出)
1. 本质作用
-
持久化存储:程序关闭后数据仍存在
-
速度最慢的组件:比内存慢5个数量级
# Linux磁盘I/O监控 $ iostat -x 1 Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s await svctm %util vda 0.00 2.00 8.0 12.0 256.0 512.0 5.00 2.50 50.00
2. 现实类比
像餐厅的仓库:
-
仓库大小=磁盘容量
-
取货速度=IOPS
-
货架通道带宽=吞吐量
性能瓶颈判断
-
CPU瓶颈:高使用率+低负载+内存充足
-
内存瓶颈:频繁Swap+高缓存未命中
-
磁盘瓶颈:高await+高%util
实际案例
数据库查询慢的可能原因:
-
CPU过载→查询计算慢
-
内存不足→缓存命中率低
-
磁盘I/O高→数据加载慢
Nginx
Nginx 是一款高性能的 开源 Web 服务器 和 反向代理中间件,广泛用于负载均衡、静态资源托管、API 网关等场景。以下是关于 Nginx 的核心知识点和实用指南
一、核心功能
| 功能 | 说明 |
|---|---|
| 静态资源服务 | 直接托管 HTML、CSS、JS、图片等文件,性能极高。 |
| 反向代理 | 将客户端请求转发到后端服务(如 Node.js、Java、Python 应用)。 |
| 负载均衡 | 分配流量到多个后端服务器(支持轮询、权重、IP Hash 等策略)。 |
| SSL/TLS 终止 | 处理 HTTPS 加密/解密,减轻后端压力。 |
| 缓存加速 | 对静态内容或代理结果进行缓存,减少后端负载。 |
| URL 重写 | 通过正则表达式修改请求路径(常用于 SEO 或旧路径迁移)。 |
测试异步接口
一、异步接口的常见类型
| 类型 | 特点 | 示例场景 |
|---|---|---|
| 轮询(Polling) | 客户端反复查询结果 | 订单状态查询 |
| 回调(Callback) | 服务端处理完成后主动通知客户端 | 支付结果回调 |
| WebSocket | 长连接实时推送 | 聊天室消息 |
| 消息队列(MQ) | 通过中间件异步消费 | 订单生成后触发物流系统 |
二、测试策略与工具
1. 轮询接口测试
步骤:
-
调用异步接口,获取任务ID(如
{"task_id": "123"}) -
定期请求结果查询接口,直到返回完成状态或超时
Python示例(使用 requests + pytest):
import time
import requests
def test_async_polling():
# 1. 触发异步任务
start_resp = requests.post("https://api.example.com/async-jobs", json={"data": "test"})
assert start_resp.status_code == 202
task_id = start_resp.json()["task_id"]
# 2. 轮询结果(最多10次,间隔1秒)
for _ in range(10):
status_resp = requests.get(f"https://api.example.com/jobs/{task_id}")
if status_resp.json()["status"] == "completed":
assert status_resp.json()["result"] == "expected_data"
break
time.sleep(1)
else:
pytest.fail("任务未在预期时间内完成")
2. 回调接口测试
工具:
-
本地回调服务器:使用
Flask或FastAPI搭建临时端点 -
公共回调服务:利用 webhook.site 或 RequestBin
Python示例(Flask 回调服务):
from flask import Flask, request
import threading
app = Flask(__name__)
callback_data = None
@app.route("/callback", methods=["POST"])
def handle_callback():
global callback_data
callback_data = request.json
return {"status": "received"}, 200
def run_callback_server():
app.run(port=5000)
def test_async_callback():
# 启动临时回调服务器
server_thread = threading.Thread(target=run_callback_server)
server_thread.daemon = True
server_thread.start()
# 触发异步任务(携带回调URL)
requests.post("https://api.example.com/async-process",
json={"data": "test", "callback_url": "http://localhost:5000/callback"})
# 等待回调(最长10秒)
for _ in range(10):
if callback_data is not None:
assert callback_data["result"] == "success"
break
time.sleep(1)
else:
pytest.fail("未收到回调")
3. WebSocket 接口测试
工具:
-
websockets库(Python) -
Postman(新版支持WebSocket)
Python示例:
import asyncio
import websockets
import pytest
async def test_websocket():
async with websockets.connect("ws://api.example.com/updates") as ws:
# 发送订阅请求
await ws.send('{"action": "subscribe", "topic": "notifications"}')
# 验证实时消息
response = await asyncio.wait_for(ws.recv(), timeout=10)
assert "new_message" in response
4. 消息队列(MQ)测试
策略:
-
生产者:调用接口触发异步任务
-
消费者:监听MQ队列,验证消息内容和处理结果
Python示例(Kafka):
from confluent_kafka import Consumer, Producer
import json
def test_kafka_async_flow():
# 1. 调用接口发送消息到Kafka
producer = Producer({"bootstrap.servers": "localhost:9092"})
producer.produce("async_tasks", value=json.dumps({"task": "process_data"}))
producer.flush()
# 2. 消费者验证处理结果
consumer = Consumer({
"bootstrap.servers": "localhost:9092",
"group.id": "test_group",
"auto.offset.reset": "earliest"
})
consumer.subscribe(["processed_results"])
# 等待最多10秒
msg = consumer.poll(10.0)
assert msg is not None
result = json.loads(msg.value())
assert result["status"] == "success"
关键验证点
响应状态码
异步任务触发应返回
202 Accepted(而非 200)超时处理
设置合理的轮询超时时间(如 30 秒)
结果一致性
确保最终结果与请求参数匹配
幂等性
重复触发相同任务应返回相同结果
fiddler
Fiddler的基本使用、功能:限速、篡改数据、重定向、发送自定义请求、APP抓包_fiddler使用-CSDN博客
限速:
1. 启动弱网模式
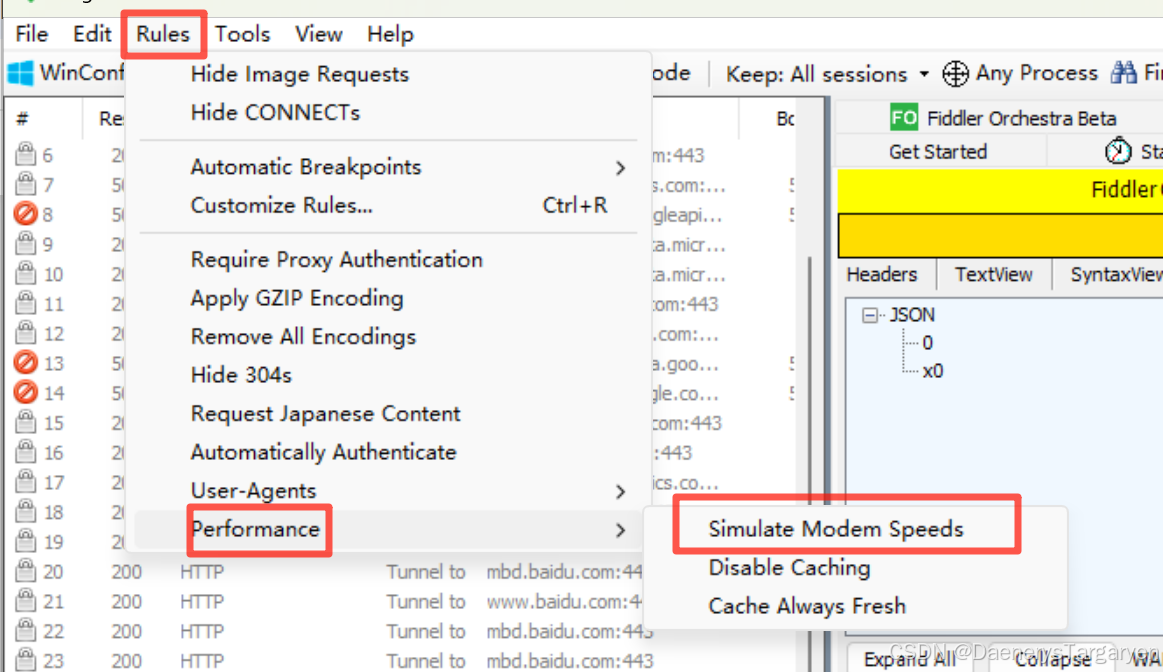
2. 设置弱网参数:rules - customize rules
修改上传/下载每kb数据,所需要的时间来模拟弱网环境 , 单位是ms
if (m_SimulateModem) {
// Delay sends by 300ms per KB uploaded.
oSession["request-trickle-delay"] = "300";
// Delay receives by 150ms per KB downloaded.
oSession["response-trickle-delay"] = "150";
}
如果是发送请求延迟,修改:oSession["request-trickle-delay"] = "3000"; 则模拟请求发送延迟了3秒
如果是响应请求延迟,修改:oSession["response-trickle-delay"] = "3000"; 则模拟响应延迟了3秒
篡改数据
使用断点功能, 修改请求的数据, 修改返回的数据
重定向
重定向是把一个资源定成另外一个资源
app抓包
抓包的原理
将fiddler设置为代理服务器,浏览器发出的所有请求都由fiddler这个工具来代理转发,这样子就可以拦截到客户端给服务器发了什么数据,服务器给客户端响应了什么数据
fiddler打断点的方式
左下角: 可以设置全局断点,取消全局断点
命令行: bpu url 在请求之前断点
bpu 取消所有请求断点
bpafter url 在响应到达时中断
bpafter 取消所有请求断点

















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









