






内容概述
文本编辑工具VIM
各种文本工具
基本正则表达式和扩展正则表达式
文本处理三剑客之grep
文本处理三剑客之sed
文本处理三剑客之awk
-rw-------. 这个点.是selinux系统中的一个标签,selinux一般生产中是禁止使用的,所以一般都会去掉.#getenforce 回车显示Disabled 是禁用了,创建的新文件就没有标签,就会没有点.
怎么禁用:#cat /etc/selinux/config , 会显示一行SELINUX=enforcing , 修改文件:#nano /etc/selinux/config 打开去修改,将SELINUX=enforcing改成SELINUX=disabled。后重启机器。
1 文本编辑工具之神VIM
1.1 vi和vim简介(退出来 :wq存盘退出,q!不保存退出)
在Linux中我们经常编辑修改文本文件,即由ASCII, Unicode 或其它编码的纯文字的文件。之前介绍过nano,实际工作中我们会使用更为专业,功能强大的工具
文本编辑种类:
全屏编辑器:nano(字符工具), gedit(图形化工具),vi,vim
行编辑器:sed
vi
Visual editor,文本编辑器,是 Linux 必备工具之一,功能强大,学习曲线较陡峭,学习难度大
vim VIsual editor iMproved ,和 vi 使用方法一致,但功能更为强大,不是必备软件
其他相关编辑器:gvim 一个Vim编辑器的图形版本
1.2.2 三种主要模式和转换
vim 是 一个模式编辑器,击键行为是依赖于 vim的 的“模式”
三种常见模式:
命令或普通(Normal)模式: 默认模式,可以实现移动光标,剪切/粘贴文本
插入(Insert)或编辑模式: 用于修改文本
扩展命令(extended command )或命令(末)行模式:保存,退出等
#cp /etc/passwd f1.txt(拷贝一个文件 叫fi,txt),#vi /etc/passwd f1.txt(打开),按i ,:wq退出。
命令模式 --> 插入模式
i insert, 在光标所在处输入
I 在当前光标所在行的行首输入
a append, 在光标所在处后面输入
A 在当前光标所在行的行尾输入
o 在当前光标所在行的下方打开一个新行
O 在当前光标所在行的上方打开一个新行
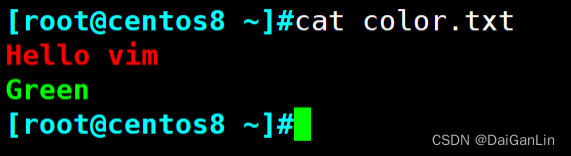
范例: 插入颜色字符
1 切换至插入模式
2 按ctrl+v+[ 三个键,显示^[
3 后续输入颜色信息,如:^[[32mhello^[[0m
4 切换至扩展命令模式,保存退出
5 cat 文件可以看到下面显示

1.3 扩展命令模式
按“:”进入Ex模式 ,创建一个命令提示符: 处于底部的屏幕左侧
1.3.1 扩展命令模式基本命令
w 写(存)磁盘文件
wq 写入并退出
x 写入并退出
X 加密 取消 X 不输入
q 退出
q! 不存盘退出,即使更改都将丢失
r filename 读文件内容到当前文件中
w filename 将当前文件内容写入另一个文件
!command 执行命令
r!command 读入命令的输出
1.3.2 地址定界
格式::start_pos,end_pos CMD
1.3.2.1 地址定界格式
# #具体第#行,例如2表示第2行
#,# #从左侧#表示起始行,到右侧#表示结尾行
#,+# #从左侧#表示的起始行,加上右侧#表示的行数,范例:2,+3 表示2到5行
. #当前行
$ #最后一行
.,$-1 #当前行到倒数第二行
% #全文, 相当于1,$
/pattern/ #从当前行向下查找,直到匹配pattern的第一行,即:正则表达式
/pat1/,/pat2/ #从第一次被pat1模式匹配到的行开始,一直到第一次被pat2匹配到的行结束
#,/pat/ #从指定行开始,一直找到第一个匹配pattern的行结束
/pat/,$ #向下找到第一个匹配patttern的行到整个文件的结尾的所有行
1.3.2.2 地址定界后跟一个编辑命令
d #删除
y #复制
w file #将范围内的行另存至指定文件中
r file #在指定位置插入指定文件中的所有内容
t#行号 将前面指定的行复制到#行后
m#行号 将前面指定的行移动到#行后
前面加行数
1.3.3 查找并替换
格式 s/要查找的内容/替换为的内容/修饰符
说明:要查找的内容:可使用基本正则表达式模式
替换为的内容:不能使用模式,但可以使用\1, \2, ...等后向引用符号;还可以使用“&”引用 前面查找时,找到的整个内容
修饰符:
i #忽略大小写
g #全局替换,默认情况下,每一行只替换第一次出现
gc #全局替换,每次替换前询问
%s 全部选中
1.3.4 定制vim的工作特性(:后的命令)。
扩展命令模式的配置只是对当前vim进程有效,可将配置存放在文件中持久保存
配置文件:
/etc/vimrc #全局
~/.vimrc #个人
行号 显示:set number,简写 set nu, 取消显示:set nonumber, 简写 set nonu
#vim .vimrc (进去加set nu,显示行号)
忽略字符的大小写 启用:set ignorecase,简写 set ic 不忽略:set noic
自动缩进 启用:set autoindent,简写 set ai 禁用:set noai
复制保留格式 启用:set paste 禁用:set nopaste
显示(Tab) ^I和换行符 和$(换行)显示 启用:set list 禁用:set nolist
高亮搜索 启用:set hlsearch 禁用:set nohlsearch 简写:nohl
语法高亮 启用:syntax on 禁用:syntax off
文件格式 启用windows格式:set fileformat=dos 启用unix格式:set fileformat=unix
简写 set ff=dos|unix
Tab 用空格代替 启用:set expandtab 默认为8个空格代替Tab
禁用:set noexpandtab
简写:set et
Tab用指定空格的个数代替 启用:set tabstop=# 指定#个空格代替Tab
简写:set ts=4
设置缩进宽度 #向右缩进 命令模式>>
#向左缩进 命令模式<<
#设置缩进为4个字符
set shiftwidth=4
设置文本宽度 set textwidth=65 (vim only) #从左向右计数
set wrapmargin=15 #从右到左计数
设置光标所在行的标识线 启用:set cursorline,简写 set cul
禁用:set nocursorline
加密 启用: set key=password
禁用: set key=空
了解更多 set 帮助 :help option-list
:set or :set all
1.4 命令模式
命令模式,又称为Normal模式,功能强大,只是此模式输入指令并在屏幕上显示,所以需要记忆大量的快捷按键才能更好的使用
1.4.1 退出VIM
ZZ 保存退出
ZQ 不保存退出
1.4.2 光标跳转
字符间跳转:h: 左
L: 右
j: 下
k: 上
#COMMAND:跳转由#指定的个数的字符
单词间跳转:w:下一个单词的词首
e:当前或下一单词的词尾
b:当前或前一个单词的词首
#COMMAND:由#指定一次跳转的单词数
当前页跳转: H:页首
M:页中间行
L:页底
zt:将光标所在当前行移到屏幕顶端
zz:将光标所在当前行移到屏幕中间
zb:将光标所在当前行移到屏幕底端
行首行尾跳转:^ 跳转至行首的第一个非空白字符
0 跳转至行首
$ 跳转至行尾
行间移动: #G 或者扩展命令模式下
:# 跳转至由第#行
G 最后一行
1G, gg 第一行
句间移动: ) 下一句 (以. 隔开的的句子)
( 上一句
段落间移动:(中间有空行)} 下一段
{ 上一段
命令模式翻屏操作 Ctrl+f 向文件尾部翻一屏,相当于Pagedown
Ctrl+b 向文件首部翻一屏,相当于Pageup
Ctrl+d 向文件尾部翻半屏
Ctrl+u 向文件首部翻半屏
1.4.3 字符编辑
x 剪切光标处的字符
#x 剪切光标处起始的#个字符
xp 交换光标所在处的字符及其后面字符的位置
~ 转换大小写
J 删除当前行后的换行符
1.4.4 替换命令(replace)
r 只替换光标所在处的一个字符
R 切换成REPLACE模式(在末行出现-- REPLACE -- 提示),按ESC回到命令模式
1.4.5 删除命令(delete)
d 删除命令,可结合光标跳转字符,实现范围删除
d$ 删除到行尾
d^ 删除到非空行首
d0 删除到行首
dw
de
db
#COMMAND
dd: 剪切光标所在的行
#dd 多行删除
D:从当前光标位置一直删除到行尾,等同于d$
1.4.6 复制命令(yank)
y 复制,行为相似于d命令
y$
y0
y^
ye
yw
yb
#COMMAND
yy:复制行
#yy 复制多行
Y:复制整行
1.4.7 粘贴命令(paste)
p 缓冲区存的如果为整行,则粘贴当前光标所在行的下方;否则,则粘贴至当前光标所在处的后面
P 缓冲区存的如果为整行,则粘贴当前光标所在行的上方;否则,则粘贴至当前光标所在处的前面
1.4.8 改变命令(change)
命令 c 删除后切换成插入模式
c$
c^
c0
cb
ce
cw
#COMMAND
cc #删除当前行并输入新内容,相当于S
#cc
C #删除当前光标到行尾,并切换成插入模式,相当于c$
1.4.9 查找
/PATTERN:从当前光标所在处向文件尾部查找
?PATTERN:从当前光标所在处向文件首部查找
n:与命令同方向
N:与命令反方向
1.4.10 撤消更改
u 撤销最近的更改,相当于windows中ctrl+z
#u 撤销之前多次更改
U 撤消光标落在这行后所有此行的更改
Ctrl-r 重做最后的“撤消”更改,相当于windows中crtl+y
. 重复前一个操作
#. 重复前一个操作#次
1.4.10 高级用法
<start position><command><end position>
常见Command:y 复制、d 删除、gU 变大写、gu 变小写
0y$ 命令
0 → 先到行头
y → 从这里开始拷贝
$ → 拷贝到本行最后一个字符
范例:粘贴“wang”100次 100iwang [ESC]
di" 光标在” “之间,则删除” “之间的内容
yi( 光标在()之间,则复制()之间的内容
vi[ 光标在[]之间,则选中[]之间的内容
dtx 删除字符直到遇见光标之后的第一个 x 字符
ytx 复制字符直到遇见光标之后的第一个 x 字符
1.5 可视化模式
在末行有”-- VISUAL -- “指示,表示在可视化模式允许选择的文本块
v 面向字符,-- VISUAL --
V 面向整行,-- VISUAL LINE --
ctrl-v 面向块,-- VISUAL BLOCK --
可视化键可用于与移动键结合使用 w ) } 箭头等,突出显示的文字可被删除,复制,变更,过滤,搜索,替换等
范例:在文件指定行的行首插入#
1、先将光标移动到指定的第一行的行首
2、输入ctrl+v 进入可视化模式
3、向下移动光标,选中希望操作的每一行的第一个字符
4、输入大写字母 I 切换至插入模式
5、输入 #
6、按 ESC 键
范例:在指定的块位置插入相同的内容
1、光标定位到要操作的地方
2、CTRL+v 进入“可视块”模式,选取这一列操作多少行
3、SHIFT+i(I)
4、输入要插入的内容
5、按 ESC 键
1.6 多文件模式
vim FILE1 FILE2 FILE3 ...
:next 下一个
:prev 前一个
:first 第一个
:last 最后一个
:wall 保存所有
:qall 不保存退出所有
:wqall保存退出所有
1.7 多窗口模式
1.7.1 多文件分割 vim -o|-O FILE1 FILE2 ...
-o: 水平或上下分割
-O: 垂直或左右分割(vim only)
在窗口间切换:Ctrl+w, Arrow
1.7.2 单文件窗口分割 Ctrl+w,s:split, 水平分割,上下分屏
Ctrl+w,v:vertical, 垂直分割,左右分屏
ctrl+w,q:取消相邻窗口
ctrl+w,o:取消全部窗口
:wqall 退出
1.8 帮助
:help
:help topic
Use :q to exit help
#vimtutor
2 文本常见处理工具
2.1 文件内容查看命令
2.1.1 查看文本文件内容
2.1.1.1 cat
cat 可以查看文本内容 格式: cat [OPTION]... [FILE]...
常见选项 -E:显示行结束符$
-A:显示所有控制符
-n:对显示出的每一行进行编号
-b:非空行编号
-s:压缩连续的空行成一行
范例:
[root@centos8 ~]#cat -A /data/fa.txt
a b$
c $
d^Ib^Ic$
[root@centos8 ~]#cat /data/fa.txt
a b
c
d b c
2.1.1.2 nl 显示行号,相当于cat -b
[root@centos8 ~]#cat /data/f1.txt
a
b
c
d
e
f
g
h
[root@centos8 ~]#nl /data/f1.txt
1 a
2 b
3 c
4 d
5 e
6 f
7 g
8 h
2.1.1.3 tac 逆向显示文本内容
[root@centos8 ~]#cat /data/fa.txt
1
2
3
4
5
[root@centos8 ~]#tac /data/fa.txt
5
4
3
2
1
[root@centos8 ~]#tac
a
bb
ccc 按ctrl+d
ccc
bb
a
[root@centos8 ~]#seq 10 | tac
10
9
8
7
6
5
4
3
2
1
2.1.1.4 rev 将同一行的内容逆向显示
[root@centos8 ~]#cat /data/fa.txt
1 2 3 4 5
a b c
[root@centos8 ~]#tac /data/fa.txt
a b c
1 2 3 4 5
[root@centos8 ~]#rev /data/fa.txt
5 4 3 2 1
c b a
[root@centos8 ~]#rev
abcdef
fedcba
[root@centos8 ~]#echo {1..10} |rev
01 9 8 7 6 5 4 3 2 1
2.1.2 查看非文本文件内容
2.2 分页查看文件内容
2.2.1 more
可以实现分页查看文件,可以配合管道实现输出信息的分页
格式: more [OPTIONS...] FILE... 选项: -d: 显示翻页及退出提示
2.2.2 less
less 也可以实现分页查看文件或STDIN输出,less 命令是man命令使用的分页器
查看时有用的命令包括:
/文本 搜索 文本
n/N 跳到下一个 或 上一个匹配
范例:
#less 配合管道对其它命令的执行结果进行分页显示
[root@centos8 ~]#tree -d /etc |less
/etc
├── alternatives
├── audit
│ ├── plugins.d
│ └── rules.d
├── authselect
│ └── custom
├── auto.master.d
├── bash_completion.d
├── binfmt.d
├── chkconfig.d
├── cifs-utils
├── cron.d
├── cron.daily
...省略...
2.3 显示文本前面或后面的行内容
2.3.1 head 可以显示文件或标准输入的前面行
2.3.2 tail tail 和head 相反,查看文件或标准输入的倒数行
head
-c # 指定获取前#字节
-n # 指定获取前#行,#如果为负数,表示从文件头取到倒数第#前
-# 同上
tail
-c # 指定获取后#字节
-n # 指定获取后#行,如果#是负数,表示从第#行开始到文件结束
-# 同上
-f 跟踪显示文件fd新追加的内容,常用日志监控,相当于 --follow=descriptor,当文件删除再新
建同名文件,将无法继续跟踪文件
-F 跟踪文件名,相当于--follow=name --retry,当文件删除再新建同名文件,将可以继续跟踪文
件
tailf 类似 tail –f,当文件不增长时并不访问文件,节约资源,CentOS8已经无此工具
head 和 tail 总结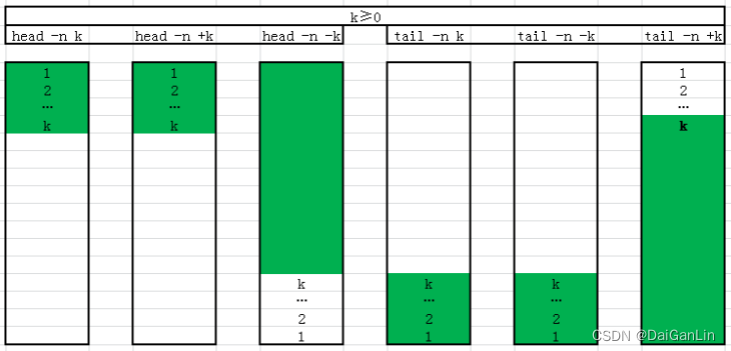
范例: 显示第6行[root@centos8 ~]#seq 20| head -n 6|tail -n1
6
[root@centos8 ~]#seq 20| tail -n +6 |head -n1
6
2.4 按列抽取文本 cut
cut 命令可以提取文本文件或STDIN数据的指定列
常用选项 -d DELIMITER: 指明分隔符,默认tab
-f FILEDS:
#: 第#个字段,例如:3
#,#[,#]:离散的多个字段,例如:1,3,6
#-#:连续的多个字段, 例如:1-6
混合使用:1-3,7
-c 按字符切割
--output-delimiter=STRING指定输出分隔符
范例: 取分区利用率
[root@centos8 ~]#df|tr -s ' ' |cut -d' ' -f5 |tr -d %
[root@centos8 ~]#df|tr -s ' ' '%'|cut -d% -f5
Use
0
0
2
0
3
1
15
0
100
[root@centos8 ~]#df |cut -c 44-46|tail -n +2
0
0
3
0
3
1
13
0
[root@centos8 ~]#df | tail -n +2|tr -s ' ' % |cut -d% -f5
0
0
1
0
3
1
19
0
100
[root@centos8 ~]#df | tail -n +2|tr -s ' ' |cut -d' ' -f5 |tr -d %
0
0
1
0
3
1
19
0
100
2.5 合并多个文件 paste
paste 合并多个文件同行号的列到一行
常用选项:-d #分隔符:指定分隔符,默认用TAB
-s #所有行合成一行显示
范例:
[root@centos8 ~]#cat alpha.log
a
b
c
d
e
f
g
h
[root@centos8 ~]#cat seq.log
1
2
3
4
5
[root@centos8 ~]#cat alpha.log seq.log
a
b
c
d
e
f
g
h
1
2
3
4
5
[root@centos8 ~]#paste alpha.log seq.log
a 1
b 2
c 3
d 4
e 5
f
g
h
[root@centos8 ~]#paste -d":" alpha.log seq.log
a:1
b:2
c:3
d:4
e:5
f:
g:
h:
[root@centos8 ~]#paste -s seq.log
1 2 3 4 5
[root@centos8 ~]#paste -s alpha.log
a b c d e f g h
[root@centos8 ~]#paste -s alpha.log seq.log
a b c d e f g h
1 2 3 4 5
2.6 分析文本的工具
文本数据统计:wc
整理文本:sort
比较文件:diff和patch
2.6.1 收集文本统计数据 wc
wc 命令可用于统计文件的行总数、单词总数、字节总数和字符总数可以对文件或STDIN中的数据统计
常用选项:-l 只计数行数
-w 只计数单词总数
-c 只计数字节总数
-m 只计数字符总数
-L 显示文件中最长行的长度
范例:
wc story.txt
39 237 1901 story.txt
行数 单词数 字节数
2.6.2 文本排序 sort
把整理过的文本显示在STDOUT,不改变原始文件
常用选项:-r 执行反方向(由上至下)整理
-R 随机排序
-n 执行按数字大小整理
-h 人类可读排序,如: 2K 1G
-f 选项忽略(fold)字符串中的字符大小写
-u 选项(独特,unique),合并重复项,即去重
-t c 选项使用c做为字段界定符
-k # 选项按照使用c字符分隔的 # 列来整理能够使用多次
范例:
[root@centos8 data]#cut -d: -f1,3 /etc/passwd|sort -t: -k2 -nr |head -n3
nobody:65534
xiaoming:1002
mage:1001
#统计日志访问量
[root@centos8 data]#cut -d" " -f1 /var/log/nginx/access_log |sort -u|wc -l
201
2.6.3 去重 uniq
uniq命令从输入中删除前后相接的重复的行
常见选项:-c: 显示每行重复出现的次数
-d: 仅显示重复过的行
-u: 仅显示不曾重复的行
uniq常和sort 命令一起配合使用:
范例:
sort userlist.txt | uniq -c
范例:并发连接最多的远程主机IP
[root@centos8 ~]#ss -nt|tail -n+2 |tr -s ' ' : |cut -d: -f6|sort|uniq -c|sort -
nr |head -n2
7 10.0.0.1
2 10.0.0.7
范例:取两个文件的相同和不同的行
[root@centos8 data]#cat test1.txt
a
b
1
c
[root@centos8 data]#cat test2.txt
b
e
f
c
1
2
#取文件的共同行
[root@centos8 data]#cat test1.txt test2.txt | sort |uniq -d
1
b
c
#取文件的不同行
[root@centos8 data]#cat test1.txt test2.txt | sort |uniq -u
2
a
e
f
2.6.4 diff patch
diff 命令比较两个文件之间的区别
-u 选项来输出“统一的(unified)”diff格式文件,最适用于补丁文件
patch 复制在其它文件中进行的改变(要谨慎使用)
-b 选项来自动备份改变了的文件
范例:
[root@centos8 ~]#cat f1.txt
mage
zhang
wang
xu
[root@centos8 ~]#cat f2.txt
magedu
zhang sir
wang
xu
shi
[root@centos8 ~]#diff f1.txt f2.txt
1,2c1,2
< mage
< zhang
---
> magedu
> zhang sir
4a5
> shi
[root@centos8 ~]#diff -u f1.txt f2.txt
--- f1.txt 2019-12-13 21:31:30.892775671 +0800
+++ f2.txt 2019-12-13 22:00:14.373677728 +0800
@@ -1,4 +1,5 @@
-mage
-zhang
+magedu
+zhang sir
wang
xu
+shi
[root@centos8 ~]#diff -u f1.txt f2.txt > f.patch
[root@centos8 ~]#rm -f f2.txt
[root@centos8 ~]#patch -b f1.txt f.patch
patching file f1.txt
[root@centos8 ~]#cat f1.txt
magedu
zhang sir
wang
xu
shi
[root@centos8 ~]#cat f1.txt.orig
mage
zhang
wang
xu
2.6.5 vimdif
相当于 vim -d
[root@centos8 ~]#cat f1.txt
mage
zhangsir
wang
lilaoshi
zhao
[root@centos8 ~]#cat f2.txt
mage
zhang
wang
li
zhao
[root@centos8 ~]#which vimdiff
/usr/bin/vimdiff
[root@centos8 ~]#ll /usr/bin/vimdiff
lrwxrwxrwx. 1 root root 3 Nov 12 2019 /usr/bin/vimdiff -> vim
[root@centos8 ~]#vimdiff f1.txt f2.txt

2.6.6 cmp
范例:查看二进制文件的不同
[root@centos8 data]#ll /usr/bin/dir /usr/bin/ls
-rwxr-xr-x. 1 root root 166448 May 12 2019 /usr/bin/dir
-rwxr-xr-x. 1 root root 166448 May 12 2019 /usr/bin/ls
[root@centos8 data]#ll /usr/bin/dir /usr/bin/ls -i
201839444 -rwxr-xr-x. 1 root root 166448 May 12 2019 /usr/bin/dir
201839465 -rwxr-xr-x. 1 root root 166448 May 12 2019 /usr/bin/ls
[root@centos8 data]#diff /usr/bin/dir /usr/bin/ls
Binary files /usr/bin/dir and /usr/bin/ls differ
[root@centos8 ~]#cmp /bin/dir /bin/ls
/bin/dir /bin/ls differ: byte 737, line 2
#跳过前735个字节,观察后面30个字节
[root@centos8 ~]#hexdump -s 735 -Cn 30 /bin/ls
000002df 00 05 6d da 3f 1b 77 91 91 63 a7 de 55 63 a2 b9 |..m.?.w..c..Uc..|
000002ef d9 d2 45 55 4c 00 00 00 00 03 00 00 00 7d |..EUL........}|
000002fd
[root@centos8 ~]#hexdump -s 735 -Cn 30 /bin/dir
000002df 00 f1 21 4e f2 19 7e ef 38 0d 9b 3e d7 54 08 39 |..!N..~.8..>.T.9|
000002ef e4 74 4d 69 25 00 00 00 00 03 00 00 00 7d |.tMi%........}|
000002fd
3.文本处理三剑客
文本三剑客之awk
awk 工作原理和基本用法说
gawk:模式扫描和处理语言,可以实现下面功能
文本处理
输出格式化的文本报表
执行算数运算
执行字符串操作
格式:
awk [options] 'program' var=value file…
awk [options] -f programfile var=value file…
Program格式:
pattern{action statements;..}
pattern:决定动作语句何时触发及触发事件,比如:BEGIN,END,正则表达式等
action statements:对数据进行处理,放在{}内指明,常见:print, printf
取利用率
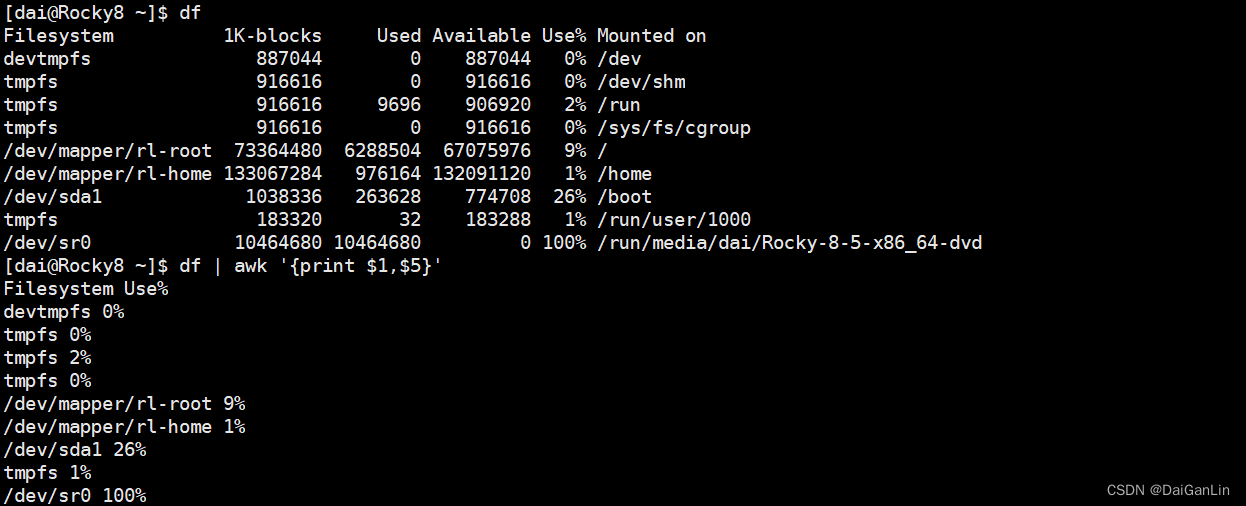
常见选项:
F “分隔符” 指明输入时用到的字段分隔符,默认的分隔符是若干个连续空白符
-v var=value 变量赋值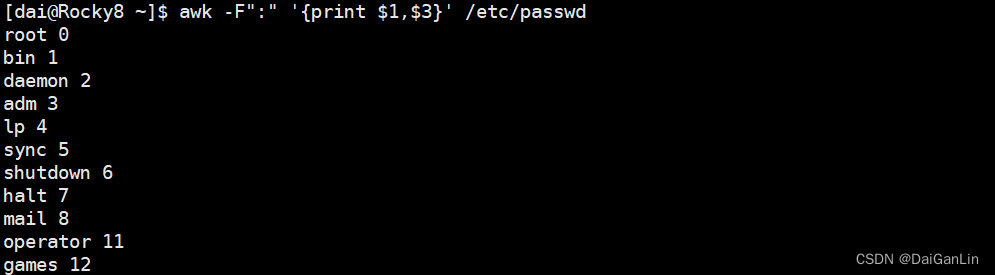

面题:取出网站访问量最大的前3个IP
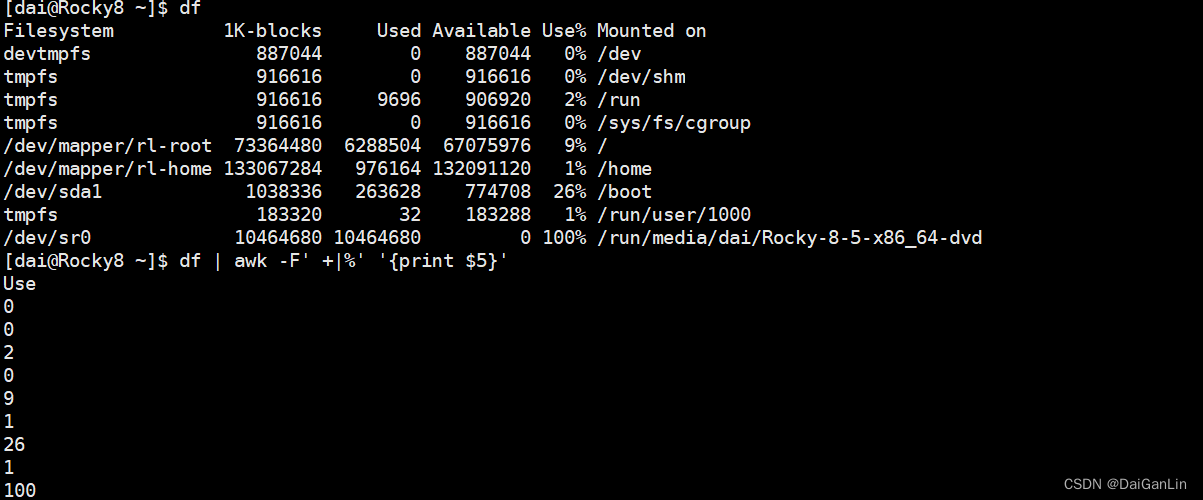
[root@VM_0_10_centos logs]# awk '{print $1}' nginx.access.log-20200428|sort |
uniq -c |sort -nr|head -3
5498 122.51.38.20
2161 117.157.173.214
953 211.159.177.120

面试题:取 ifconfig 输出结果中的IP地址

面试题:文件host_list.log 如下格式,请提取”.magedu.com”前面的主机名部分并写入到回到该文件中
![]()
awk 变量
awk中的变量分为:内置和自定义变量
常见的内置变量
FS:输入字段分隔符,默认为空白字符,功能相当于 -F
OFS:输出字段分隔符,默认为空白字符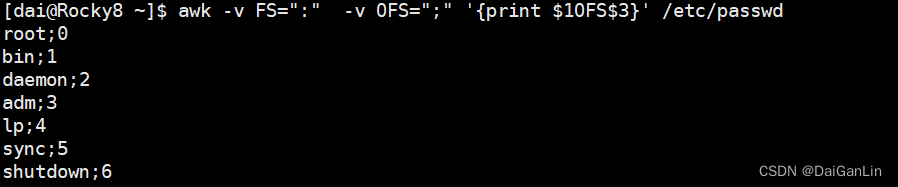
RS:输入记录record分隔符,指定输入时的换行符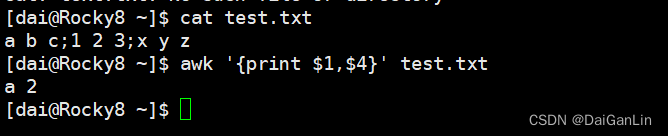



NF:字段数量 域 字段 列
NR:记录的编号
FILENAME:当前文件名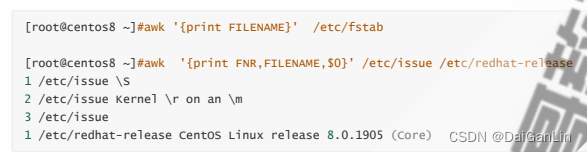
ARGC:命令行参数的个数
ARGV:数组,保存的是命令行所给定的各参数,每一个参数:ARGV[0],......
自定义变量
自定义变量是区分字符大小写的,使用下面方式进行赋值
-v var=value
在program中直接定义

动作 printf
printf 可以实现格式化输出
格式:
printf “FORMAT”, item1, item2, ...
说明:
必须指定FORMAT
不会自动换行,需要显式给出换行控制符 \n
FORMAT中需要分别为后面每个item指定格式符
格式符:与item一一对应
%s:显示字符串
%d, %i:显示十进制整数
%f:显示为浮点数
%e, %E:显示科学计数法数值
%c:显示字符的ASCII码
%g, %G:以科学计数法或浮点形式显示数值
%u:无符号整数
%%:显示%自身
修饰符
#[.#] 第一个数字控制显示的宽度;第二个#表示小数点后精度,如:%3.1f
- 左对齐(默认右对齐) 如:%-15s
+ 显示数值的正负符号 如:%+d

操作符
算术操作符:
x+y, x-y, x*y, x/y, x^y, x%y
-x:转换为负数
+x:将字符串转换为数值
字符串操作符:没有符号的操作符,字符串连接
赋值操作符:
=, +=, -=, *=, /=, %=, ^=,++, --
逻辑操作符:
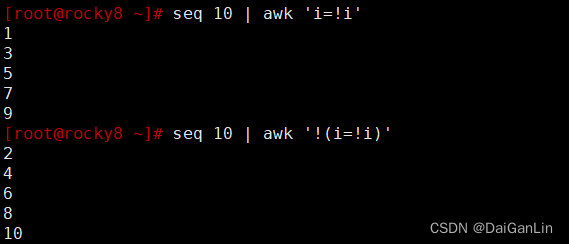
与:&&,并且关系
或:||,或者关系
非:!,取反
模式PATTERN
PATTERN:根据pattern条件,过滤匹配的行,再做处理
如果未指定:空模式,匹配每一行
BEGIN/END模式
BEGIN{}:仅在开始处理文件中的文本之前执行一次
END{}:仅在文本处理完成之后执行一次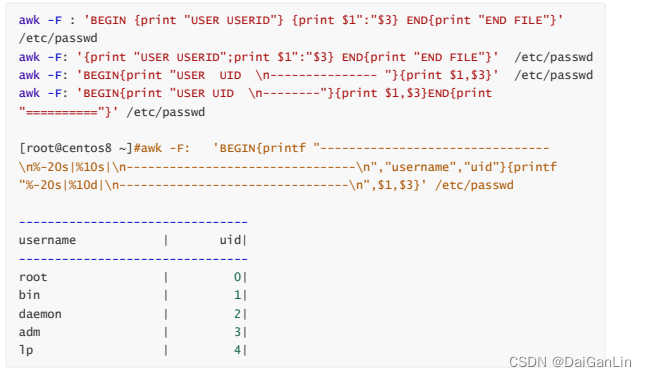
/regular expression/:仅处理能够模式匹配到的行,需要用/ /括起来


relational expression: 关系表达式,结果为“真”才会被处理
真:结果为非0值,非空字符串
假:结果为空字符串或0值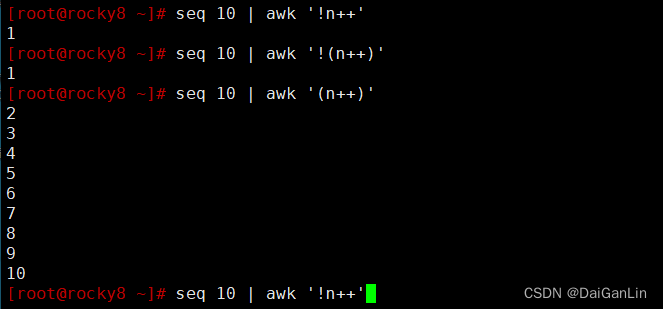
条件表达式(三目表达式)
selector?if-true-expression:if-false-expression
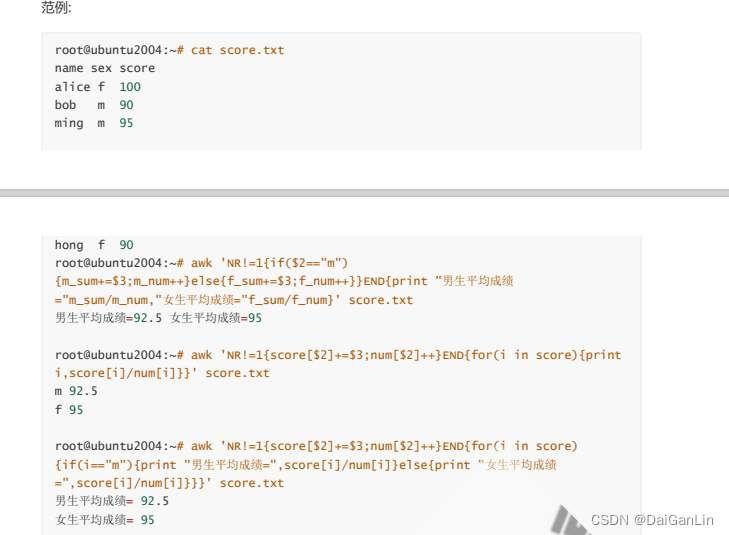
awk -F: '{$3>=1000?usertype="Common User":usertype="SysUser";printf
"%-20s:%12s\n",$1,usertype}' /etc/passwd
[root@centos8 ~]#df | awk -F"[ %]+" '/^\/dev\/sd/{$(NF-1)>10?
disk="full":disk="OK";print $(NF-1),disk}'
3 OK
1 OK
13 full
line ranges:行范围
不支持直接用行号,但可以使用变量NR间接指定行号
/pat1/,/pat2/ 不支持直接给出数字格式
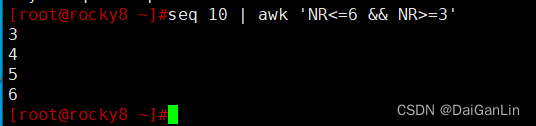
[root@centos8 ~]#awk '/^bin/,/^adm/' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
[root@centos8 ~]#sed -n '/^bin/,/^adm/p' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
条件判断 if-else
语法:
if(condition){statement;…}[else statement]
if(condition1){statement1}else if(condition2){statement2}else if(condition3)
{statement3}...... else {statementN}
使用场景:对awk取得的整行或某个字段做条件判断
范例:
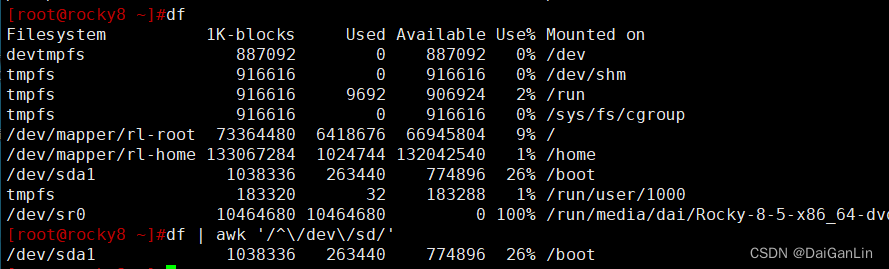
[root@centos8 ~]#df | awk -F' +|%' '/^\/dev\/sd/{if($5>=10)print $1,$5}'
/dev/sda1 15
awk 'BEGIN{ test=100;if(test>90){print "very good"}
else if(test>60){ print "good"}else{print "no pass"}}'
条件判断 switch
语法:
switch(expression) {case VALUE1 or /REGEXP/: statement1; case VALUE2 or
/REGEXP2/: statement2; ...; default: statementn}
循环 while
语法:
while (condition) {statement;…}
条件“真”,进入循环;条件“假”,退出循环
使用场景:
对一行内的多个字段逐一类似处理时使用
对数组中的各元素逐一处理时使用
循环 do-while
语法:
do {statement;…}while(condition)
意义:无论真假,至少执行一次循环体
do-while循环
语法:do {statement;…}while(condition)
意义:无论真假,至少执行一次循环体
循环 for
语法:
for(expr1;expr2;expr3) {statement;…}
常见用法:
for(variable assignment;condition;iteration process) {for-body}
特殊用法:能够遍历数组中的元素
for(var in array) {for-body}
root@ubuntu2004:~# awk 'BEGIN{sum=0;for(i=1;i<=100;i++){sum+=i};print sum}'
5050
root@ubuntu2004:~# for((i=1,sum=0;i<=100;i++));do let sum+=i;done;echo $sum
5050

continue 和 break
continue 中断本次循环
break 中断整个循环
格式:
continue [n]
break [n]
[root@centos8 ~]#awk 'BEGIN{for(i=1;i<=100;i++){if(i==50)continue;sum+=i};print
sum}'
5000
[root@centos8 ~]#awk 'BEGIN{for(i=1;i<=100;i++){if(i==50)break;sum+=i};print
sum}'
1225
next
next 可以提前结束对本行处理而直接进入下一行处理(awk自身循环)
[root@centos8 ~]#awk -F: '{if($3%2!=0) next; print $1,$3}' /etc/passwd
root 0
daemon 2
lp 4
shutdown 6
mail 8
games 12
ftp 14
nobody 65534
polkitd 998
gluster 996
rtkit 172
rpc 32
chrony 994
数组
awk的数组为关联数组
格式
array_name[index-expression]
若要遍历数组中的每个元素,要使用 for 循环
for(var in array) {for-body}
注意:var 会遍历array的每个索引
[root@centos8 ~]#awk
'BEGIN{weekdays["mon"]="Monday";weekdays["tue"]="Tuesday";for(i in weekdays)
{print i,weekdays[i]}}'
tue Tuesday
mon Monday

去重


取访问ip地址前3位
awk 函数
常见内置函数
数值处理:
rand():返回0和1之间一个随机数
srand():配合rand() 函数,生成随机数的种子
int():返回整数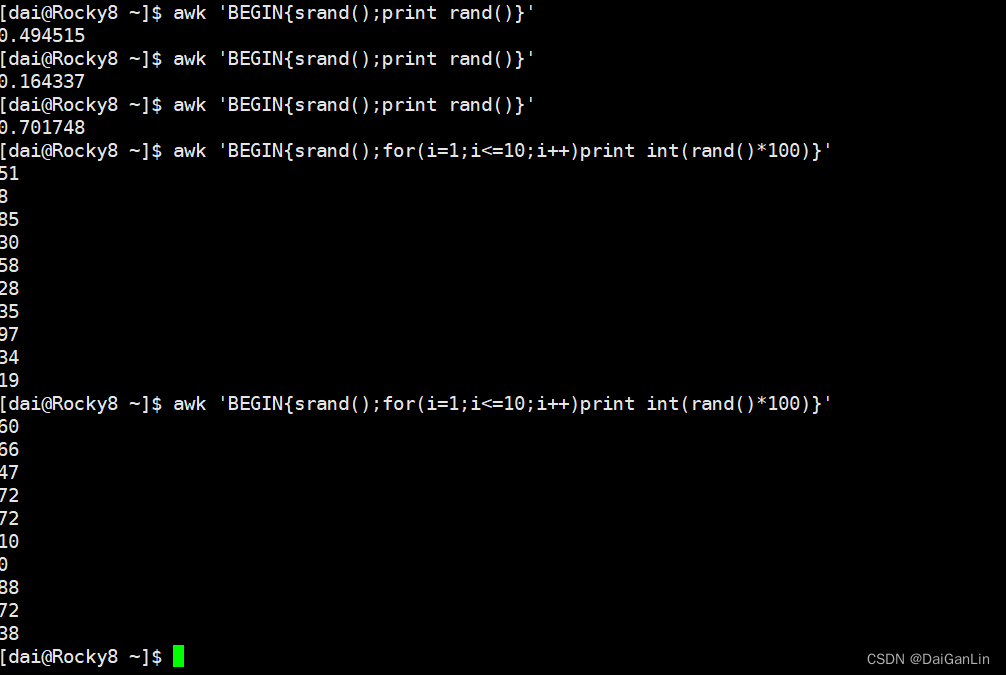
字符串处理:
length([s]):返回指定字符串的长度
sub(r,s,[t]):对t字符串搜索r表示模式匹配的内容,并将第一个匹配内容替换为s
gsub(r,s,[t]):对t字符串进行搜索r表示的模式匹配的内容,并全部替换为s所表示的内容
split(s,array,[r]):以r为分隔符,切割字符串s,并将切割后的结果保存至array所表示的数组中,第
一个索引值为1,第二个索引值为2,…
自定义函数
自定义函数格式:
function name ( parameter, parameter, ... ) {
statements
return expression
}
[root@centos8 ~]#cat func.awk
function max(x,y) {
x>y?var=x:var=y
return var
}
BEGIN{print max(a,b)}
[root@centos8 ~]#awk -v a=30 -v b=20 -f func.awk
30
awk 脚本
范例:
[root@centos8 ~]#cat test.awk
#!/bin/awk -f
#this is a awk script
{if($3>=1000)print $1,$3}
[root@centos8 ~]#chmod +x test.awk
[root@centos8 ~]#./test.awk -F: /etc/passwd
nobody 65534
wang 1000
mage 1001
上面格式变量在BEGIN过程中不可用。直到首行输入完成以后,变量才可用
可以通过-v 参数,让awk在执行BEGIN之前得到变量的值
命令行中每一个指定的变量都需要一个-v参数
[root@rocky8 ~]#awk -v x=100 'BEGIN{print x}{print x+100}' /etc/hosts
100
200
200
[root@rocky8 ~]#awk 'BEGIN{print x}{print x+100}' x=200 /etc/hosts
300
300
检查出最近一小时内访问nginx服务次数超过3次的客户端IP
[root@VM_0_10_centos ~]# cat check_nginx_log.awk
#!/usr/bin/awk -f
BEGIN {
beg=strftime("%Y-%m-%dT%H:%M",systime()-3600) ;
#定义一个小时前的时间,并格式化日期格式
end=strftime( "%Y-%m-%dT%H:%M",systime()-60) ;
#定义结束时间
#print beg;
#print end;
}
$4 > beg && $4 < end {#定义取这个时间段内的日志
count[$12]+=1;#利用ip当做数组下标,次数当做数组内容
}
END {
for(i in count){#结束从数组取数据代表数组的下标,也就是ip
if(count[i]>3) { #如果次数大于3次,做操作
print count [i]" "i;
#system("iptables -I INPUT -S”i”j DROP" )
}
}
}
#awk -F'"' -f check_nginx_log.awk /apps/nginx/logs/access.log















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









