







 ANEMONE提出了一种新的图异常检测框架,通过多尺度对比学习捕捉不同尺度的异常模式,利用GCN和MLP模型,以及统计异常估计器在Cora、CiteSeer和PubMed数据集上展现优势。
ANEMONE提出了一种新的图异常检测框架,通过多尺度对比学习捕捉不同尺度的异常模式,利用GCN和MLP模型,以及统计异常估计器在Cora、CiteSeer和PubMed数据集上展现优势。
论文简介
原文题目:ANEMONE: Graph Anomaly Detection with Multi-Scale Contrastive Learning
中文题目:基于多尺度对比学习的图异常检测
发表会议:CIKM
发表年份:2021-10-26
作者:Ming Jin
latex引用:
@inproceedings{jin2021anemone,
title={Anemone: Graph anomaly detection with multi-scale contrastive learning},
author={Jin, Ming and Liu, Yixin and Zheng, Yu and Chi, Lianhua and Li, Yuan-Fang and Pan, Shirui},
booktitle={Proceedings of the 30th ACM International Conference on Information \& Knowledge Management},
pages={3122--3126},
year={2021}
}
摘要
图上异常检测在网络安全、电子商务、金融欺诈检测等领域发挥着重要作用。然而,现有的图异常检测方法通常只考虑单个图尺度的视图,这导致它们从不同角度捕获异常模式的能力有限。为此,我们引入了一种新的图异常检测框架——ANEMONE,以同时识别多个图尺度的异常。具体而言,ANEMONE首先利用具有多尺度对比学习目标的图神经网络骨干编码器,通过在patch和上下文级别同时学习实例之间的协议来捕获图数据的模式分布。然后,我们的方法采用统计异常估计器,根据多个角度的一致程度对每个节点的异常进行评估。在三个基准数据集上的实验证明了该方法的优越性。
存在的问题
这些方法主要是从单一尺度的角度检测异常,忽略了图中节点异常经常发生在不同尺度的事实。
论文贡献
- 提出了一种多尺度对比学习框架ANEMONE,用于图异常检测,它可以捕获不同尺度的异常模式
- 设计了一种新的基于统计的算法来估计节点异常与所提出的对比模式
- 在三个基准数据集上进行了广泛的实验,以证明ANEMONE在检测图上节点级异常方面的优势
说明
- ego network:ego-net
- 随机游走:可以参考我这篇文章的笔记
- 负采样策略:负采样策略
1. ANEMONE框架
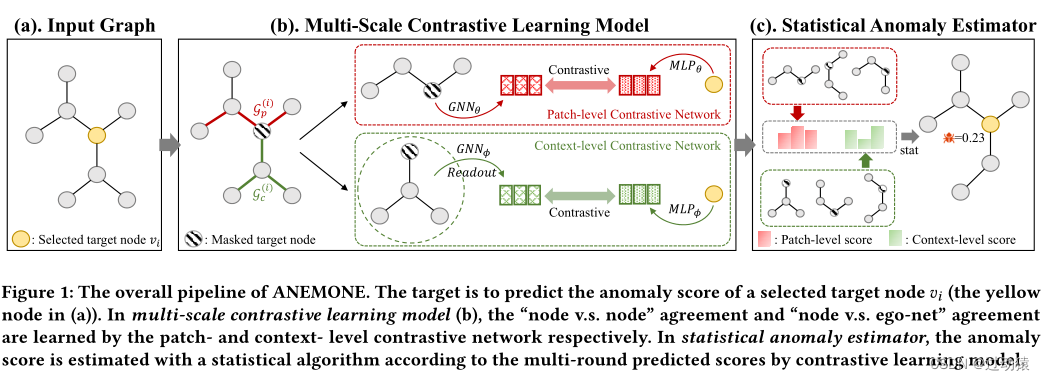
对于选定的目标节点,ANEMONE通过利用两个主要组件来计算该节点的异常评分:
- 多尺度对比学习模型:两个基于gnn的对比网络分别学习patch-level(即节点对节点)协议和context-level(即节点对自我网络)协议。
- 统计异常估计器:将多个增强自我网络获得的patch-level和context-level分数进行汇总,并通过统计估计计算出目标节点的最终异常分数。我们将在以下部分中介绍这两个组件。
-
多尺度对比学习模型
准备:
- 输入图 G G G,选择一个目标节点
- 以该目标节点为中心,使用随机游走的方法,采集两个自我网络(ego-network,简单理解就是以目标节点为中心遍历出的两个子网络),记为 G p G_p Gp 和 G c G_c Gc(p和c分别代表patch_level和context-level)
- 将 G p G_p Gp和 G c G_c Gc节点集合中的第一个节点设置为中心(目标)节点。
- 为了防止在接下来的对比学习步骤中信息泄露,在将自我网络输入到对比网络之前,应该在自我网络中进行一个名为目标节点掩蔽的预处理。具体来说,就是将目标节点的属性向量替换为零向量。
patch_level对比网络:
- 学习
G
p
G_p
Gp 嵌入和目标节点
v
i
v_i
vi嵌入的一致性。
G
p
G_p
Gp 嵌入使用GCN模型来获得,记为
H
p
H_p
Hp,目标节点
v
i
v_i
vi嵌入使用MLP模型来获得,记为
z
p
z_p
zp。
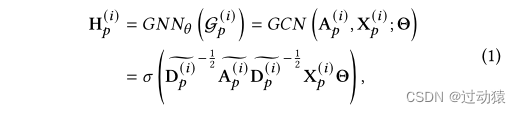
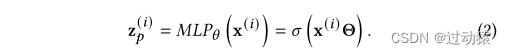
- 注意,这里共用同一个 θ \theta θ,为的是将目标节点嵌入和图嵌入映射到同一个空间中。
- 注意,在使用GCN获得图嵌入时,目标节点的属性向量要用零向量。使用MLP获得节点嵌入的时,目标节点的属性向量就用原来的即可。
- 用双线性层来计算它们的相似度得分:
s p ( i ) = B i l i n e a r ( h p ( i ) , z p ( i ) ) = σ ( h p ( i ) W p z p ( i ) T ) s_p^{(i)} = Bilinear(h_p^{(i)},z_p^{(i)}) = \sigma (h_p^{(i)}W_pz_p^{(i)T}) sp(i)=Bilinear(hp(i),zp(i))=σ(hp(i)Wpzp(i)T) - 用负采样的策略进行训练:
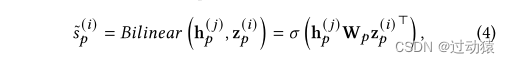
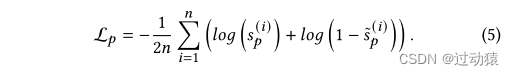
context_level对比网络:
- 学习
G
c
G_c
Gc 嵌入和目标节点
v
i
v_i
vi嵌入的一致性。
G
p
G_p
Gp 嵌入使用GCN模型+readout来获得,记为
H
c
H_c
Hc,目标节点
v
i
v_i
vi嵌入使用MLP模型来获得,记为
z
c
z_c
zc。
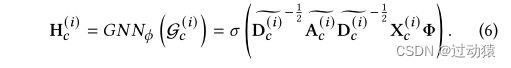
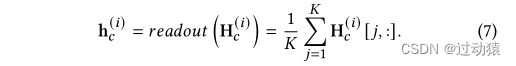
z c z_c zc的计算方法类似于patch_level对比网络。 - 相似度计算方法也与patch_level对比网络相同。
- 负采样策略训练:

联合训练,损失函数为:
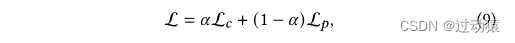
-
统计异常估计器
经过上面的计算之后,对于每个节点 i i i 而言,都有4R个分数,即
[ s p , 1 ( i ) , . . . , s p , R ( i ) , s c , 1 ( i ) , . . . , s c , R ( i ) , s p , 1 ( ˜ i ) , . . . , s p , R ( ˜ i ) , s c , 1 ( ˜ i ) , . . . , s c , R ( ˜ i ) ] [s_{p,1}^{(i)},...,s_{p,R}^{(i)},s_{c,1}^{(i)},...,s_{c,R}^{(i)},s_{p,1}^{\~(i)},...,s_{p,R}^{\~(i)},s_{c,1}^{\~(i)},...,s_{c,R}^{\~(i)}] [sp,1(i),...,sp,R(i),sc,1(i),...,sc,R(i),sp,1(˜i),...,sp,R(˜i),sc,1(˜i),...,sc,R(˜i)]假设异常节点与其相邻的结构和上下文具有较小的一致性。因此,我们将基础分数表示为正负分数之差:
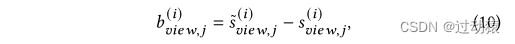
其中的view可以取p,也可以取c异常估计的统计方法:
- 异常节点具有相对较大的基础分数。这是因为异常节点嵌入通常和图嵌入有较小的一致性,就会导致 s v i e w , j ( i ) s_{view,j}^{(i)} sview,j(i)很小,而 s v i e w , j ( ˜ i ) s_{view,j}^{\~(i)} sview,j(˜i)很大,从而导致该基础分数很大。
- 异常节点在多个自网采样下的基础分数不稳定。
- 因此,我们将统计异常分数
y
p
(
i
)
y_p^{(i)}
yp(i)和
y
c
(
i
)
y_c^{(i)}
yc(i)定义为基础分数的均值和标准差之和:
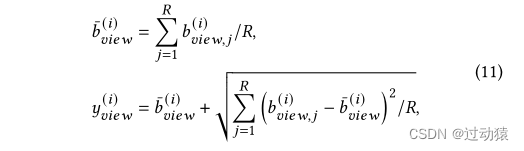
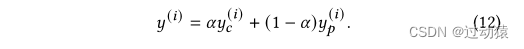
2. 实验
-
数据集
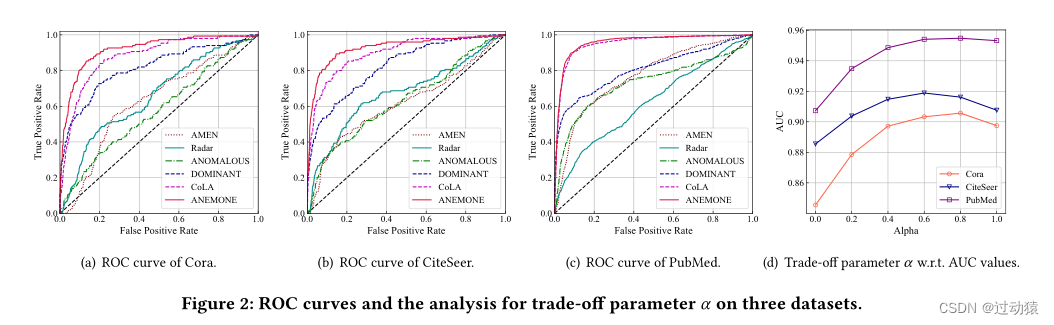
我们在三个著名的引文网络数据集,即Cora, CiteSeer和PubMed上进行了广泛的实验。
-
实验结果
总结
论文内容
-
学到的方法
写论文的方法:
- introduce -> problem statement ->…


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









