







本人初学Python,经推荐看到一个很简单快捷的pdf转docx方法,仅仅需要几行代码即可完成,于是想抄来用,但是因为我安装的Python是3.10.0版,运行的时候老是报错:ImportError:cannot import name 'Iterable' from 'collections',在“老表Max”的指导下,解决了此问题,感谢!
pdf2docx代码介绍:
Convert PDF — pdf2docx 0.5.2 documentation
运行报错状态:
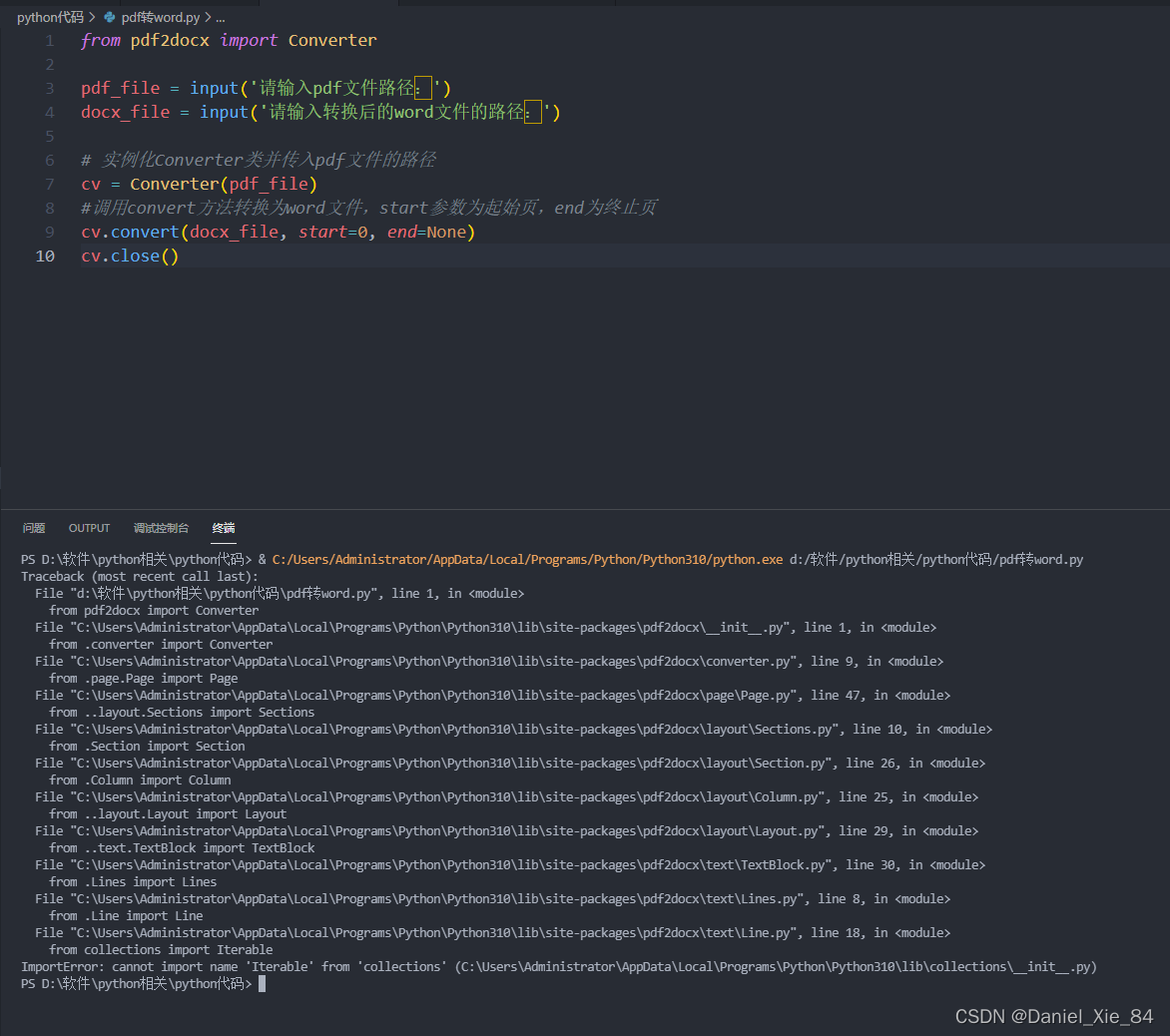
原因查找:
经网上搜索,感谢几位网友的经验,应该是版本导致的问题
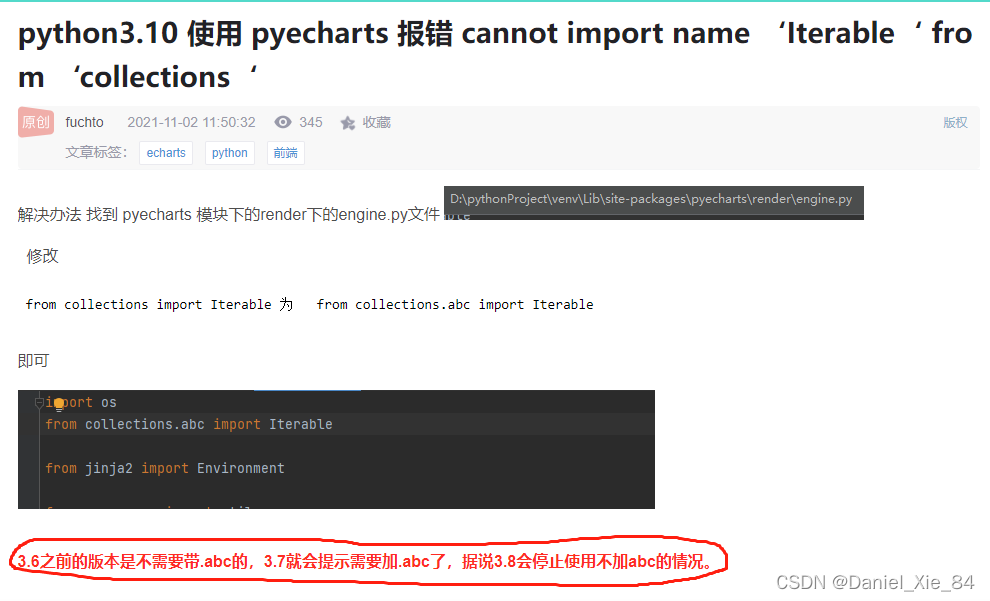
解决方法:
我尝试直接在代码前面加上‘from collections.abc import Iterable’, 测试结果是True,但是还是不能运行。经‘老表Max’指点,看最后一次报
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4098
4098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









