









import pandas as pd
import numpy as np
import datetime
today=str(datetime.date.today())
filepath='/Users/kangyongqing/Documents/kangyq/202311/班均及合班储备/z拆班校验/'
file1='02查询结果.csv'
file2='工具-国家对应大洲表格_副本.xlsx'
df1=pd.read_csv(filepath+file1,dtype='object')
print(df1.shape,df1.columns)
df2=pd.read_excel(filepath+file2,usecols=['国家名称', '大洲'])
print(df2.shape,df2.columns)
df3=pd.merge(df1,df2,left_on='attend_class_country',right_on='国家名称',how='left')
print(df3.info())
print(df3['大洲'].value_counts())
df3['班容']=df3.groupby('class_id')['student_user_id'].transform('count')
df3['区域数']=df3.groupby('class_id')['大洲'].transform(lambda x:len(x.unique()))
df3['区域数'].fillna(1,inplace=True)
df3['多区域']=np.where(df3['区域数']>1,'多个区域','单一区域')
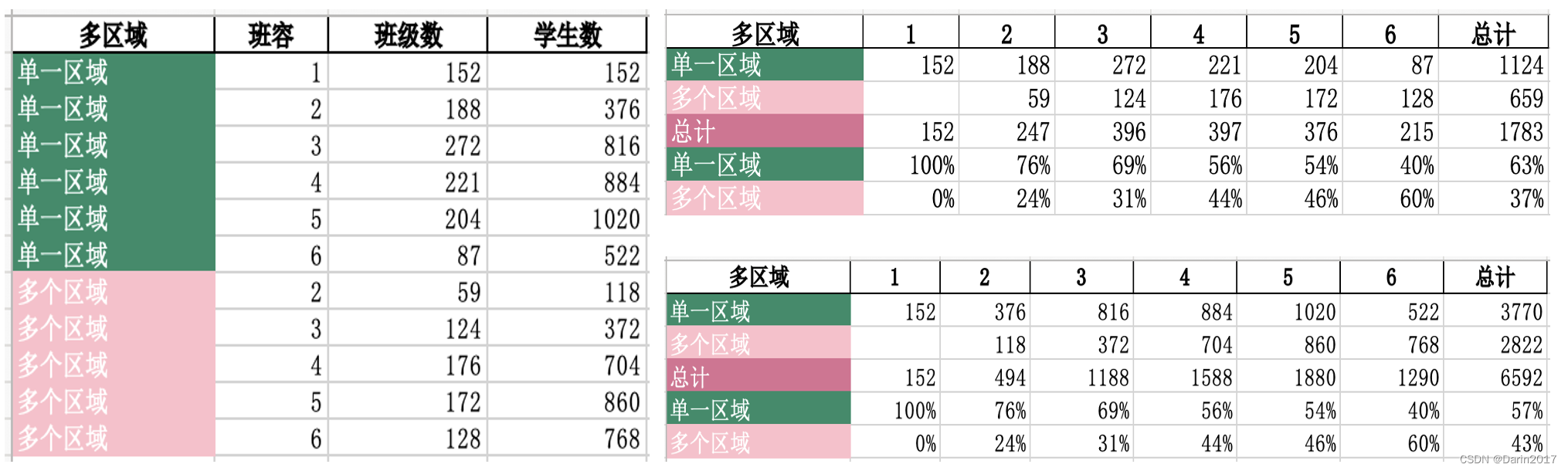
df4=df3.groupby(['多区域','班容'])['class_id'].apply(lambda x:len(x.unique())).reset_index()
df4['学生数']=df4['班容']*df4['class_id']
df4.rename(columns={'class_id':'班级数'},inplace=True)
print(df4)
df50=pd.crosstab(index=df4['多区域'],columns=df4['班容'],values=df4['班级数'],aggfunc='sum',margins=True,margins_name='总计')
df51=pd.crosstab(index=df4['多区域'],columns=df4['班容'],values=df4['班级数'],aggfunc='sum',margins=True,margins_name='总计',normalize='columns').round(2)
df5=pd.concat((df50,df51),axis=0).reset_index()
print(df5)
df60=pd.crosstab(index=df4['多区域'],columns=df4['班容'],values=df4['学生数'],aggfunc='sum',margins=True,margins_name='总计')
df61=pd.crosstab(index=df4['多区域'],columns=df4['班容'],values=df4['学生数'],aggfunc='sum',margins=True,margins_name='总计',normalize='columns').round(2)
df6=pd.concat((df60,df61),axis=0).reset_index()
print(df6)
# def color_red(val):
# color='pink' if val=='多个区域' else 'green'
# return 'background-color: %s;color:white '% color
def color_red(val):
if val=='多个区域':
color='pink'
elif val=='单一区域':
color='#238E68' #海绿色
else: color='#DB7093' #中紫红色
return 'background-color: %s;color:white '% color
writer=pd.ExcelWriter(filepath+f'03小班课多区域班容分布{today}.xlsx')
df3.sort_values(by='class_id').to_excel(writer,sheet_name='明细',index=False)
df4.style.map(color_red,subset=['多区域']).to_excel(writer,sheet_name='区域分布',index=False)
df5.style.map(color_red,subset=['多区域']).to_excel(writer,sheet_name='班级比例',index=False)
df6.style.map(color_red,subset=['多区域']).to_excel(writer,sheet_name='学生比例',index=False)
writer._save()
from reset_col import reset_col
reset_col(writer)
常用颜色代码:
1 白色 #FFFFFF 2 红色 #FF0000 3 绿色 #00FF00
4 蓝色 #0000FF 5 牡丹红 #FF00FF 6 青色 #00FFFF
7 黄色 #FFFF00 8 黑色 #000000 9 海蓝 #70DB93
10 巧克力色 #5C3317 11 蓝紫色 #9F5F9F 12 黄铜色 #B5A642
13 亮金色 #D9D919 14 棕色 #A67D3D 15 青铜色 #8C7853
16 2号青铜色 #A67D3D 17 士官服蓝色#5F9F9F 18 冷铜色 #D98719
19 铜色 #B87333 20 珊瑚红 #FF7F00 21 紫蓝色 #42426F
22 深棕 #5C4033 23 深绿 #2F4F2F 24 深铜绿色 #4A766E
25 深橄榄绿 #4F4F2F 26 深兰花色 #9932CD 27 深紫色 #871F78
28 深石板蓝 #6B238E 29 深铅灰色 #2F4F4F 30 深棕褐色 #97694F
32 深绿松石色 #7093DB 33 暗木色 #855E42 34 淡灰色 #545454
35 土灰玫瑰红色#856363 36 长石色 #D19275 37 火砖色 #8E2323
38 森林绿 #238E23 39 金色 #CD7F32 40 鲜黄色 #DBDB70
41 灰色 #C0C0C0 42 铜绿色 #527F76 43 青黄色 #93DB70
44 猎人绿 #215E21 45 印度红 #4E2F2F 46 土黄色 #9F9F5F
47 浅蓝色 #C0D9D9 48 浅灰色 #A8A8A8 49 浅钢蓝色 #8F8FBD
59 浅木色 #E9C2A6 60 石灰绿色 #32CD32 61 桔黄色 #E47833
62 褐红色 #8E236B 63 中海蓝色 #32CD99 64 中蓝色 #3232CD
65 中森林绿 #6B8E23 66 中鲜黄色 #EAEAAE 67 中兰花色 #9370DB
68 中海绿色 #426F42 69 中石板蓝色#7F00FF 70 中春绿色 #7FFF00
71 中绿松石色 #70DBDB 72 中紫红色 #DB7093 73 中木色 #A68064
74 深藏青色 #2F2F4F 75 海军蓝 #23238E 76 霓虹篮 #4D4DFF
77 霓虹粉红 #FF6EC7 78 新深藏青色#00009C 79 新棕褐色 #EBC79E
80 暗金黄色 #CFB53B 81 橙色 #FF7F00 82 橙红色 #FF2400
83 淡紫色 #DB70DB 84 浅绿色 #8FBC8F 85 粉红色 #BC8F8F
86 李子色 #EAADEA 87 石英色 #D9D9F3 88 艳蓝色 #5959AB
89 鲑鱼色 #6F4242 90 猩红色 #BC1717 91 海绿色 #238E68
92 半甜巧克力色#6B4226 93 赭色 #8E6B23 94 银色 #E6E8FA
95 天蓝 #3299CC 96 石板蓝 #007FFF 97 艳粉红色 #FF1CAE
98 春绿色 #00FF7F 99 钢蓝色 #236B8E 100亮天蓝色 #38B0DE
101棕褐色 #DB9370 102紫红色 #D8BFD8 103石板蓝色 #ADEAEA
104浓深棕色 #5C4033 105淡浅灰色 #CDCDCD 106紫罗兰色 #4F2F4F
107紫罗兰红色 #CC3299 108麦黄色 #D8D8BF 109黄绿色 #99CC32
划重点:
- 自定义分类颜色# def color_red(val):
# color='pink' if val=='多个区域' else 'green'
# return 'background-color: %s;color:white '% color - 自定义多分类颜色def color_red(val):
if val=='多个区域':
color='pink'
elif val=='单一区域':
color='#238E68' #海绿色
else: color='#DB7093' #中紫红色
return 'background-color: %s;color:white '% color - groupby+transform分类汇总
- pandas.crosstab透视表及占比处理
- style.set_properties(**{'border':'1px solid black'})添加表格框线
结果实例:
附加参考:
import pandas as pd
import seaborn as sns
import numpy as np
# filepath='/Users/kangyongqing/Documents/kangyq/202207/课消管理看板/2024课消学生类型/课消效果数据看板/'
# file1='课消效果数据看版0422.xlsx'
# df1=pd.read_excel(filepath+file1,sheet_name='完课+预排达标率',header=3)
# print(df1.info())
# print(df1.head())
# styled_df1=df1.style.background_gradient('Greens',subset=['学员量','课消标'])\
# .highlight_quantile(subset='0422完课/预排达标率',color='#ceedd0',q_left=0.75)\
# .highlight_quantile(subset='0422完课/预排达标率',color='#f6c9ce',q_right=0.25).bar(subset=['不达标学员数'])
# styled_df1=df1.style.bar(subset=['学员量'],vmin=0,vmax=50000,width=50,color='#ff5733')
#
# column_name=['语文','数学','英语']
# np.random.seed(100)
# values_1=np.random.randint(60,100,(10,3))
# index_1=range(10)
# df2=pd.DataFrame(index=index_1,columns=column_name,data=values_1)
# print(df2)
# styled_df2=df2.style.bar(subset=['语文'],color='pink',width=50).highlight_min(color='green').highlight_max(color='yellow').text_gradient(axis=0).background_gradient(cmap='viridis')
#
#
# writer=pd.ExcelWriter(filepath+'ceshi条件格式.xlsx',engine='xlsxwriter')
# styled_df1.to_excel(writer,sheet_name='mingxi',index=False)
# styled_df2.to_excel(writer,sheet_name='成绩')
# writer._save()
#
# styled_df2.to_html(filepath+'ceshi.html')
# from reset_col import reset_col
# reset_col(writer)
# df1.style.highlight_null() #高亮缺失值,默认红色
# df1.style.highlight_null(null_color='orange') #高亮缺失值,颜色可以是英文,也可以是十六进制#ff1493等
# #高亮最大值
# df1.style.highlight_max() #默认是黄色,subsety9on用于指定操作的列或行 axis用于指定行最大、列最大或全部,默认是列方向最大
# #高亮最小值
# df1.style.highlight_min(subset=['col1','col2'],color='pink')
# #高亮区间值
# df1.style.highlight_between(left=10,right=20,inclusive='both') #both,neither,left,right
# #props='color:white;background-dolor:purple;' 用于突出显示css特性,案例中将字体设置为白色,背景色为紫色
#
# #高亮分位数
# df1.style.highlight_quantile(q_left=0.5,q_right=0.85) #q_left默认为0,q_right默认为1
# #色阶
# df1.style.background_gradient(cmap='PuBu')
# cmap用于指定matplotlib色条
# low和high用于指定最小最大值颜色边界,区间[0, 1]
# axis用于指定行、列或全部,默认是列方向
# subset用于指定操作的列或行
# text_color_threshold用于指定文本颜色亮度,区间[0, 1]
# vmin和vmax用于指定与cmap最小最大值对应的单元格最小最大值
# cmap 用于指定matplotlib色条,采用seaborn美化样式
# import seaborn as sns
# cm=sns.light_palette('green',as_cmap=True)
# df1.style.background_gradient(cmap=cm)
#背景渐变色
# df1.style.background_gradient(cmap='RdY1Gn')
#文本渐变色
# df1.style.text_gradient(cmap='RdY1Gn')
#数据条
# df1.style.bar() #align='left'左对齐,'zero'中部对齐,'mid'位于(max-min)/2
#数据格式化
# formatter 显示格式
# subset用于指定操作的列或行
# na_rep用于指定缺失值的格式
# precision用于指定浮点位数
# decimal用于用作浮点数、复数和整数的十进制分隔符的字符,默认是.
# thousands用作浮点数、复数和整数的千位分隔符的字符
# escape用于特殊格式输出(如html、latex等,这里不做展开,可参考官网)
# df1.style.format('{}枚',
# na_rep='无')
# 金牌数目后边加上单位枚,缺失值显示为无
# df1.style.format(precision=0,
# na_rep='')
#设置小数点位数为0
#可分别对指定列进行单独格式化
# df1.style.format({'金牌数':'{:.2}',
# '银牌数':'{:.0f}枚'
# },
# na_rep='-')
#自定义格式函数
# def highlight_min(s):
# if s.金牌数<s.银牌数:
# return ['background-color:orange;','']
# else:
# return ['','']
# df1.style.apply(highlight_min,axis=1,subset=['金牌数','银牌数'])
#还可以定义,如果金牌数小于银牌数,这一行都高亮
# def highlight_A_lessthan_B(s):
# if s.金牌数<s.银牌数:
# return ['background-color:orange;']*len(s)
# else:
# return ['']*len(s)
# df1.style.apply(highlight_A_lessthan_B,axis=1)
#添加标题
# df1.style.set_caption('东京奥运会奖牌榜')
# #隐藏索引
# df1.style.hide_index_names()
# #隐藏指定列
# df1.style.hide_column_names(['金牌数','银牌数'])
# #设置属性(css样式)
# df1.style.set_properties(**{'background-color':'black',
# 'color':'lawngreen',
# 'border-color':'white'})
import colorsys
# from matplotlib import cm
# from matplotlib.colors import ListedColormap
# import matplotlib.pyplot as plt
#
# # 创建一个色彩表,这里以jet色彩映射为例
# cmap = cm.get_cmap('jet')
#
# # 生成色彩表的颜色
# num_colors = 256 # 色彩数量
# color_list = [cmap(i / num_colors) for i in range(num_colors)]
#
# # 打印色彩表
# for i, color in enumerate(color_list):
# print(f"{i}: RGB: ({color[0] * 255:.0f}, {color[1] * 255:.0f}, {color[2] * 255:.0f})")
#
# # 显示色彩表
# plt.figure()
# plt.axis("off")
# plt.imshow(color_list, aspect='auto', cmap=ListedColormap(color_list))
# plt.show()
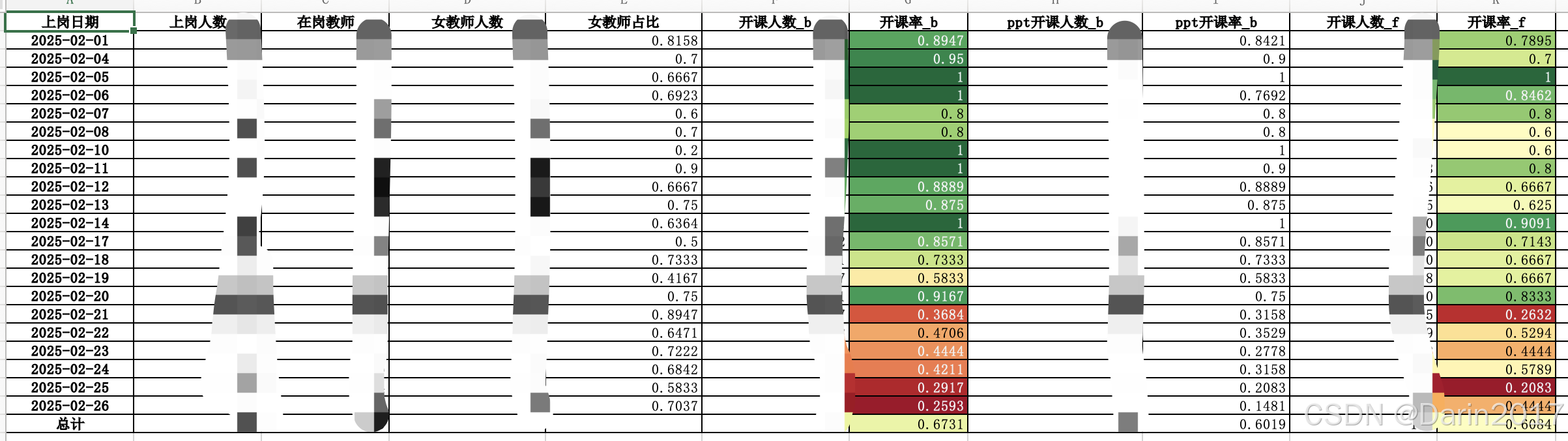
边框+背景色示例:
writer=pd.ExcelWriter(filepath+f'01上岗教师开课率{today}.xlsx',engine='openpyxl')
df.loc[:,~df.columns.isin(['实际上岗日期'])].style.set_properties(**{'border':'1px solid black'}).background_gradient(subset=['开课率_b','开课率_f'],cmap='RdYlGn').to_excel(writer,sheet_name='明细')
writer._save()
from reset_col import reset_col
reset_col(writer)
# import matplotlib
# print("-----------获取所有颜色表colormaps----------")
# print(matplotlib.colormaps) # 所有官方色带
# df=pd.DataFrame({'A':matplotlib.colormaps})
# df.to_excel(filepath+'色带.xlsx')结果展示:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









