







摘要 : 以“为什么需要聚类分析这一问题”作为引入,逐步阐述聚类分析领域是如何发展的。这篇文章主要阐述聚类分析的四类方法:划分方法、层次方法、基于密度的方法和基于网格的方法的基本原理以及它们中的代表算法和实现方式。将聚类算法的设计总结为两大核心:划分过程和相似度量的设计。
1 引言
聚类分析技术已经发展了近60年,至今该领域依旧非常活跃 [ 1 ] ^{[1]} [1]。聚类分析的地位与其他的机器学习理论,如分类,SVM等,有所不同。首先,聚类分析是一个多学科交织的研究领域,大部分的聚类算法都需要跨域知识(领域知识)的参与,不同角度会产生不一样的聚类结果,因此聚类结果没有统一的衡量标准;其次,聚类分析领域中的算法多如牛毛,但很难对这些算法提出一个总的划分(概念的划分),算法之间存在着重叠概念。以上原因导致了聚类分析理论难以形成系统化的理论体系,以至于有些教科书只会轻描淡写的阐述聚类分析的一些理论。但是不可否认的一点是,聚类分析在现实任务中占据着非常重要的地位。
本文从聚类分析本质的角度阐述聚类分析的来龙去脉,让读者们能够简单明了的掌握聚类分析的基本概念。在第二部分将会围绕着4个聚类分析的本质问题,即:
- 为什么需要聚类分析?
- 什么是聚类分析?
- 如何进行聚类分析?
- 如何评估聚类分析结果?
展开详细的论述;第三部分阐述聚类分析中一些具有代表性算法以及常用的聚类结果评估标准;希望通过本文能让读者对聚类分析有一个全方位的理解。
2 聚类分析的因与果
不同的研究者对聚类分析这个领域的观察角度是不同的,例如周志华教授的《机器学习》 [ 2 ] ^{[2]} [2]就会从性能度量和距离度量着手,而韩家炜教授 [ 3 ] ^{[3]} [3]则会以数据挖掘的一个工具的角度讲聚类定义和要求。尽管不论从何种角度看待聚类最终我们学到的东西都是一致的,但对于入门者来说这些就有点摸不着头脑了。就比如我当初学习聚类时我更希望教科书能告诉我为什么需要聚类技术?,而后才是如何定义聚类这个概念等等。因此本节从聚类最本质的问题着手,回答聚类分析的因与果。
2.1 聚类分析的因
问题一:为什么需要聚类分析?
在我们接触到的许多常见的机器学习任务(算法)大部分都是带有标记的(有监督的),如分类与回归。分类与回归问题恐怕是绝大部分学习机器学习理论的人最开始接触到的内容。有监督学习(或者称有先验结果的学习)自然是从业者最愿意看到的一种学习任务,然而在真实的世界中,有人工标记的数据仅仅占很少的一部分,对于大数据时代而言甚至可以忽略不计(可以说无监督(不带标记)的学习才是机器学习的终极目标)。但我们仍然希望探究那些无法或者还未标记的数据的内在数据结构或规律。 聚类分析就此诞生。
问题二:什么是聚类分析?
从问题一中我们知道了聚类分析的目的,就是要寻找非预先得知的数据分类信息,其中分类信息值得就是我们现在所称呼的“簇”的概念,物以类聚。韩家炜教授 [ 2 ] ^{[2]} [2]用了更为精炼的语言阐述这一概念,即:
Cluster analysis or simply clustering is the process of partitioning a set of data objects (or observations) into subsets. Each subset is a cluster, such that objects in a cluster are similar to one another, yet dissimilar to objects in other clusters. The set of clusters resulting from a cluster analysis can be referred to as a clustering.
聚类分析,是一个把数据对象(或观测)划分成子集的过程。每个子集是一个簇,使得簇中的对象彼此相似,但与其他簇中的对象不相似。由这个过程产生的一系列簇成为一个聚类。
2.1 聚类分析的果
问题三:如何进行聚类分析?
从问题二聚类分析的定义定义中我们可以提取两个关键的信息点,划分过程与(对象之间)相似与否。实际上聚类分析所有的工作都关注在这两者上,划分过程一般的有:
- 依距离划分
- 依层次划分
- 依密度估计划分
- 依概率估计划分
- 依网格划分
不同的划分方式有不同的优缺点(如簇的形状,数据集的大小等),没有包打一切的算法 [ 2 ] ^{[2]} [2]。而对于相似度(一般是特征空间上的相似度,因此也称距离度量),一般有:
- 有序属性的相似度,常用的欧氏距离(Euclidean distance),闵氏距离(Minkovski distance)等。
- 无序属性的相似度,如VDM(Value Difference Metric)。
具体可查阅周志华教授的机器学习 [ 2 ] ^{[2]} [2],这里就不再赘述。
问题四:如何评估聚类分析结果?
在问题三我们知道聚类分析主要关注划分方式与相似度量,自然地评价一个聚类结果的好与坏也主要关注在这两者上,即评估划分结果与聚类的质量。对于估算簇的个数,一般地常用以下两种:
- 经验法,簇数取 n 2 \sqrt{\frac{n}{2}} 2n,其中 n n n为样本数。
- 肘方法(elbow method),其中常用的为Gap Statistic [ 4 ] ^{[4]} [4]的方法,在第三部分将会详细讲解。
对于评估聚类质量,一般地也有两种方法:
- 有监督方法(外在方法),即我们有对聚类结果的期望结果(真实的聚类结果),然后对比期望结果与聚类器的结果的差异,例如BCubed [ 5 ] ^{[5]} [5]算法,该算法在scikit-learn库中有相应的实现。
- 无监督方法(内在方法),此时我们并没有对聚类结果的期望结果,因此我们仅能从聚类的本质出发评估聚类结果,即簇内距离是否足够近且簇间距离是否足够远,其中轮廓系数(silhouette coefficient)较为常用,同样在被实现于scikit-learn中。
但从上文中我们了解一个事实,即使聚类技术发展到如今也没有产生一个绝对统一的衡量标准,因此所有的评估方式都只能充当一种参考,一种从数据角度(统计理论)出发的参考。
至此,我们已经理解了聚类分析的由来以及功用。接下来我们将对问题三与问题四展开详细的讨论,但由于聚类分析这棵大树的果实非常多,因此我们仅能阐述有代表性的部分,关于它们的变种或改进我们也会稍微提及。
3 聚类算法与评估方法
至今为止,都没有一个很准确的方法去归类聚类算法,有的研究者将聚类算法大致归并为两类 [ 1 ] ^{[1]} [1]:划分方法(Partition methods)和层次方法(Hierarchical methods),有的会归并为四类 [ 3 ] ^{[3]} [3]:划分方法、层次方法、基于密度的方法(Density-based methods)和基于网格的方法(Grid-based methods),而在最近出现了一种更为细致的 [ 6 ] ^{[6]} [6]划分方式,如图3.1所示:
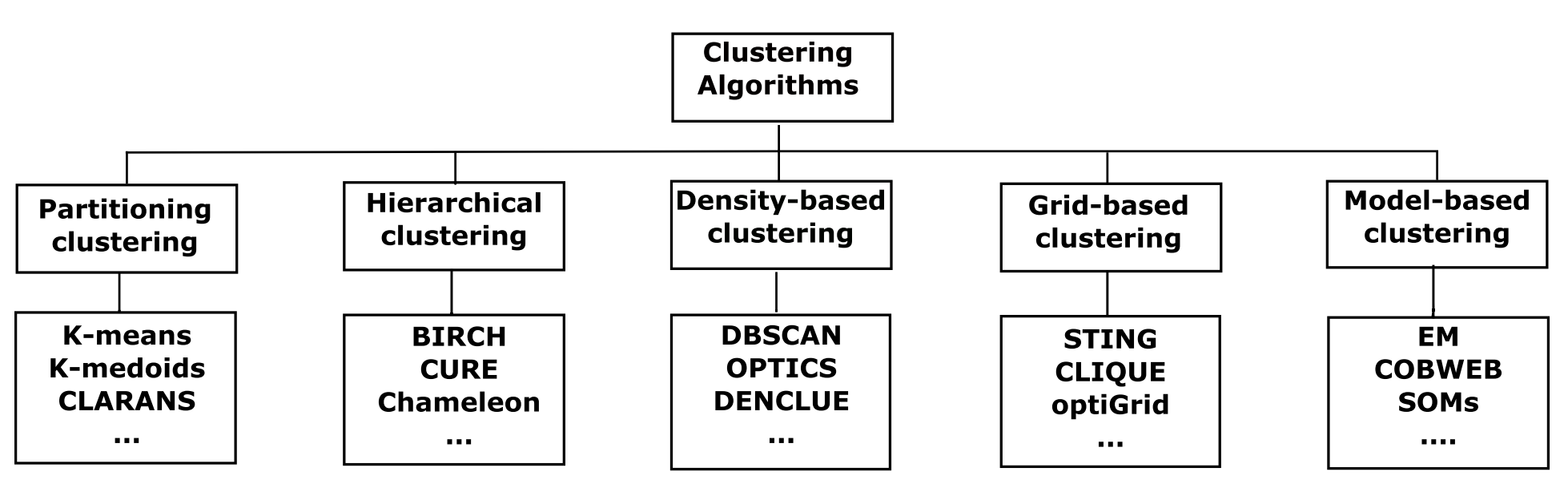
新增了基于模型的方法(Model-based methods/clustering)的划分方式,但纵使有这些总结性的划分方式,也不见得所代表的算法就是“纯”的(即特性完全属于该分类),例如CLIQUE(CLustering In QUEst) [ 21 ] ^{[21]} [21]就是同时基于网格和密度的算法,而且算法间也经常互相借鉴思想。本文将会以图1中的归并方式为下文组织结构阐述若干个有代表性的算法(其中基于模型的方法属于高级内容,不在本文的进行阐述),本文所有的代码均可以在附录中找到。
3.1 划分方法
划分方法,是聚类分析中两大经典的划分过程之一。根据距离度量将 n n n个观测对象划分成 k k k个簇(分区),其中 k ≤ n k \leq n k≤n。显然当 k = n k=n k=n时是划分方法的一种极端情况,此时代价函数最小(为0)。其中以KMeans为代表的算法最为常用,由于划分方法基于距离度量,因此非常擅长发现球状的互斥簇,并且能发现每个簇的代表对象,也常用于压缩。但由于划分方法在计算时通常需要计算每一对对象之间的距离,因此通常在小数据集上表现得很好,但近几年不断有研究者创造出了高伸缩的适合大规模数据集的划分方法,如KMeans的变种MiniBatchKMeans [ 7 ] ^{[7]} [7]。本节主要介绍KMeans以及另一种围绕中心点划分算法PAM(Partitioning Around Medoids)。
3.1.1 形心划分方法KMeans
KMeans以簇内变差度量为划分依据,即:
E = ∑ i = 1 k ∑ p ∈ C i d i s t ( p , c i ) 2 (3.1) E = \sum^{k}_{i=1} \sum_{p \in C_i} dist(p, c_i)^2 \tag*{(3.1)} E=i=1∑kp∈Ci∑dist(p,ci)2(3.1)
将 n n n个观测对象划分成以 k k k个中心点(均值点)为代表的簇 C 1 , C 2 , ⋯ , C k C_1, C_2 , \cdots , C_k C1,C2,⋯,Ck,其中 k ≥ 2 k \geq 2 k≥2。KMeans算法通常有两个步骤组成:分配(Assigment)和更新(Update),一开始 (1) 算法会随机在数据集 D D D中选择 k k k个中心点,然后 (2) 将 n n n个观测对象依据距离(一般为欧氏距离)最近原则分配给 k k k个簇,最后 (3) 以启发式的方式迭代计算(式3.1)得到新的 k k k个中心点,重复步骤(2)(3)直到中心点不再发生改变或者已达到设定的迭代次数,关于KMeans的详细内容可以查阅《KMeans原理、实现及分析》。
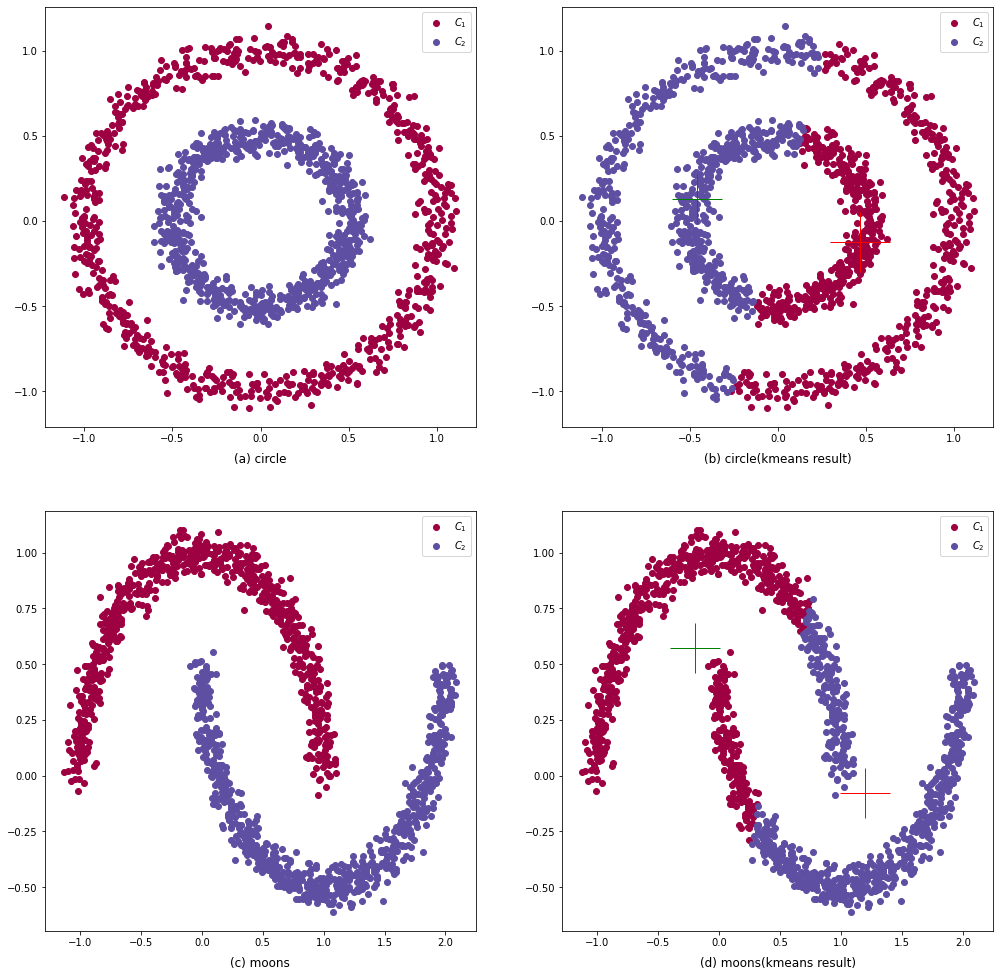
KMeans因此简便易操作的特性,使其逐渐成为了聚类分析任务中的首选聚类器。但KMeans也存在许多缺陷,如无法发现任意形状的簇,在图3.2中,由于KMeans基于欧氏距离导致其不能发现类似同心圆簇或是U型簇。不仅如此,KMeans使用了 平均值(Mean) 这种较为脆弱的统计量还导致了其对离群点(噪点)敏感。而且由于在步骤(1)使用了随机初始化中心点的策略,无法保证KMeans算法能够收敛到全局最优解,因此需要多次运行KMeans,才能的到一个较为满意的聚类结果。
到目前为止,已有许多KMeans的变种算法被开发出来,用于处理不同需求的聚类任务。当要处理的数据是类别属性(标称属性)时,使用平均值可能是无意义的,这时就可以使用众数(mode)来代替均值,即K-mode算法 [ 8 ] ^{[8]} [8],在Python上可以使用实现了K-mode的第三方库;当需要处理较大规模的数据集时,KMeans就显得抓襟见肘,因此一种行之有效的方法就是选取适当规模的数据集进行多次训练,如MiniBatchKMeans,该算法被scikit-learn作为标准工具实现了;当数据存在噪声或离群数据时,KMeans算法产生的聚类结果与真实结果存在较大的偏差,一种抗噪方案是使用中心划分的技术,使用真实观测点代替均值点,如3.1.2节提到的K-medoids算法。
即使KMeans本身已经非常成熟,但仍然有许多新的变种相继被开发出来,甚至可以KMeans的历史是聚类分析发展史的缩影。更多的KMeans相关信息可以查阅Jain [ 1 ] ^{[1]} [1]的文章。
3.1.2 中心划分方法PAM
为了减少离群点对聚类结果的影响,Kaufman和Rousseeuw [ 9 ] ^{[9]} [9]于1987年提出了围绕中心划分的方法,一种流行的实现是K-medoids,如图3.3。K-medoids算法与KMeans一样可以分为两大步骤:分配与更新,在开始时 (1) 会随机地在数据集 D D D中选择 k k k个中心点 o o o,然后 (2) 将剩余的所有观测对象依据最近原则分配给每个中心点,形成 k k k个簇,最后 (3) 随机地选取 k k k个非中心对象 o r a n d o m o_{random} orandom尝试代替最原来的中心对象 o o o,计算 o r a n d o m o_{random} orandom的平均距离代价差 S S S,若 S < 0 S<0 S<0,则用 o r a n d o m o_{random} orandom替换原中心对象 o o o,否则继续寻找,直到遍历完所有对象为止。算法迭代地执行步骤(2)(3)直到中心对象 o o o不再发生改变。该算法的代码实现可在附录文件中找到。

显然,步骤(3)的计算是非常消耗时间的,当 n , k n,k n,k都比较大时,其时间计算开销远大于KMeans,虽然K-medoids算法能够有较好的抗噪能力,但很难在大型数据集上有较好的表现。因此Kaufman和Rousseeuw于1990年又提出一种基于抽样的中心划分方法CLARA(Clustering LARge Applications) [ 10 ] ^{[10]} [10]拟补K-medoids算法处理大型数据的不足,理论上只要抽样数据分布与原数据分布足够接近,是可以找到最佳中心点的,但这就会导致CLARA的聚类结果的好坏依赖抽样的好坏。于是乎Raymond和Jiawei Han提出了更为高效的CLARANS(Clustering Large Applications based on RANdomized Search) [ 11 ] ^{[11]} [11]算法,基于随机搜索查找全局最优解,该算法在Python上被pyclustering库实现。此外Schubert和Rousseeuw [ 22 ] {^{[22]}} [22]在2019年提出了更快速的K-Medoids算法,有兴趣的读者可以自行查阅!
3.1.3 小结
划分方法的算法步骤大多都是相似的:随机的选择初始点,然后划分簇,不断尝试将一个簇中对象放至另一个簇中来降低代价函数。划分方法通常的划分依据是距离,常用的欧氏距离、马氏距离和闵氏距离等,通过更换距离度量有可能会提高聚类质量。划分方法通常在高斯簇上表现得很好,但不能发现任意形状的簇。
3.2 层次方法
与划分方法要求聚类结果为互斥簇不同,层次方法更加强调对象间层次关系。如在一个公司的管理体系内,可以分成董事局-总经理-部门经理-业务员,利用“树状”的图形表示这些层次关系,是层次聚类可视化的常用方法。一般地,使用两种划分策略来完成层次聚类:凝聚(Agglomerative) 和 分裂(Divisive),用数据结构的语言来描述,即自底向上和自顶向下。这两者不仅含义相仿,甚至层次聚类里面的许多算法都与数据结构中的构建各种“树”的算法相似。而层次聚类常用的距离度量是有:
最 小 距 离 : d i s t m i n ( C i , C j ) = min p ∈ C i , p ′ ∈ C j { ∣ p − p ′ ∣ } ( 3.2 ) 最 大 距 离 : d i s t m a x ( C i , C j ) = max p ∈ C i , p ′ ∈ C j { ∣ p − p ′ ∣ } ( 3.3 ) 均 值 距 离 : d i s t m e a n ( C i , C j ) = ∣ m i − m j ∣ ( 3.4 ) 平 均 距 离 : d
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1912
1912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









