







OutOfMemoryError GC问题排查方法总结
导语
在项目运行当中,最怕出现OutOfMemoryError。但是作为程序猿,这种问题肯定会遇到,如果分析的方法错误了,一定会耗费相当长的时间,还不一定能从根本解决问题。
而要解决好GC问题首先要看懂JVM到底告诉了你啥问题
-
从错误信息初定位问题
-
GC 问题分类
-
Java heap space
Exception in thread “main” java.lang.OutOfMemoryError: Java heap space.
这是比较常见的内存问题,意思是超出最大堆内存大小,这时候最好先检查一下设置的 Xmx值,如果设置的确实过小,将参数调大,观察是否有问题,如果仍然出现问题,按照下文的排查方式继续排查 -
Meta space
Caused by: java.lang.OutOfMemoryError: Meta space.
这个报错很明显了,永久代(元空间)内存溢出了。这个问题一般在jdk1.8之前出现,1.8之后基本没有了。这个问题我曾经遇到过一次,其他项目组的一个老项目启动不久总是挂,查看了他的系统日志,就是报出这个问题。我问了一下这个项目使用的jdk版本,确实是jdk1.6的老版本。解决方法也简单,调整 -XX:MaxPermSize(jdk1.8之前的版本)的值。如果jdk1.8及之后的版本在启动时出现频繁full GC,调整 -XX:MetaspaceSize 和 -XX:MaxMetaspaceSize, 但是注意这个值不要调整过大,从而影响服务器上的其他程序的运行和内存申请 -
StackOverflowError
Exception in thread “main” java.lang.StackOverflowError
这个也是较为常见的错误,栈内存溢出,一般来说如果代码中调用的方法过多了,栈的容量达到了上限就会抛出这个异常。如果你的程序中有递归,检查递归方法,如果确实是因为递归调用层数过深,长时间无法释放,尝试用尾递归或者用循环代替。
但如果你的代码中没有递归,或者你的递归方法没有问题,调用链就是深,那最好不使用递归,如果不得不使用递归,那么将启动参数中的 -Xss值调大 -
GC overhead limit exceeded
java.lang.OutOfMemoryError: GC overhead limit exceeded
非常常见的GC问题,JVM短时间大量GC且每次仅能回收少量内存(2%),就会抛出这个异常。通常是因为对象持续不停增长且长时间被引用,无法被回收导致GC。这个问题比较常见,但问题定位往往却比较麻烦,因为JVM不一定在问题代码处抛出异常,导致这个问题的原因也是多种多样,需要一步一步来分析
-
-
可能导致GC的几种原因
- 年轻代大小设置不合理:
这里需要提一下对象进入老年代的情况- 年轻代分为Eden区和两个survivor区,默认比例8:1:1,一般对象先进入eden区,在Eden区满的时候会触发一次minorGC,此时没被回收的存活对象会被移动到其中一个空的survivor区。然而此时如果突然来了一个对象将Eden区占满了,gc开始回收进行一次minorGC,结果回收完Eden区剩下的对象大小超过了survivor区空余的内存空间大小,那么Eden区剩余的这些对象就会直接进入老年代(这里涉及到的survivor-from和survivor-to两区的腾挪就不赘述了)
- 大对象(默认1M)直接进入老年代
- JVM每次做MinorGC的时候都会为survivor区没被回收掉的对象标记次数,也就是对象的年龄,如果你minorGC频率非常高,在某个对象年龄达到一定值的时候(默认为5岁,CMS收集器默认6岁),就会将这些对象移动到老年代,这种机制称为对象动态年龄判断机制,一般发生在minorGC之后
- 年轻代每次MinorGC之前JVM都会计算老年代剩余空间大小,如果这个可用空间小于年轻代所有对象大小之和(包括垃圾对象),jdk1.8及之后的版本默认开启-XX:-HandlePromotionFailure,会检查剩余空间是否大于之前minorGC后进入老年代的对象的平均大小,如果剩余空间不够,或者minorGC后要挪动到老年代的对象大小大于老年代剩余空间,就会触发一次full GC,年轻代和老年代一起回收,如果回收完,剩余的空间还是不够存放新对象,就会触发OOM,这个机制就是jvm的老年代空间担保机制
- 所以如果你的年轻代设置过小,对象新增的大小远超gc回收的大小,那么老年代将很快被占满,从而频繁fullGC
- 永久代过小
如果你的永久代设置过小,jdk1.8之前会直接内存溢出,1.8之后程序启动就开始多次fullGC且启动非常缓慢 - 滥用hashmap或者ThreadLoacl类
很多开发者在使用map或者threadlocal类作为缓存的时候,不断地往里面添加数据,没有做好过期数据的淘汰,导致对象越来越大,gc难以回收,从而导致内存泄漏,频繁发生fullgc - 线程池设置不合理
线程是非常宝贵的资源,过多的线程或者频繁创建和销毁线程都是非常耗费资源的操作,尽量使用线程池,并且根据系统的情况设置合理的线程数 - 代码逻辑不合理
某些代码判断不完整,导致数据库查询一个非常大的对象,或者循环创建对象时停止条件有bug导致程序一直死循环创建对象,很快就会将内存全部占满 - 死锁
线程中出现死锁,出现死锁的线程资源一直不释放,夯死的线程过多,系统也会夯死 - 某些框架的不合理运用
比如fastjson转换超大对象, log4j的版本漏洞, forest的版本漏洞,spring注解的滥用等 - 过多调用System类下的方法
System下的很多方法调用底层都是加了同步锁的,如最常见的System.out.println,如果程序过多调用这些方法,系统将会非常卡顿
并且如果拿捏不准的话,不要手动调用System.gc - 其余因素
还有其余一些特殊因素无法一一例举
- 年轻代大小设置不合理:
-
GC排查过程
- 程序GC情况查看
-
查找程序进程号
jps -l
-
查看当前存活的最大的对象
重点查看自己代码包下的对象
jmap -histo $pid|head -numjmap -histo 22698|head -20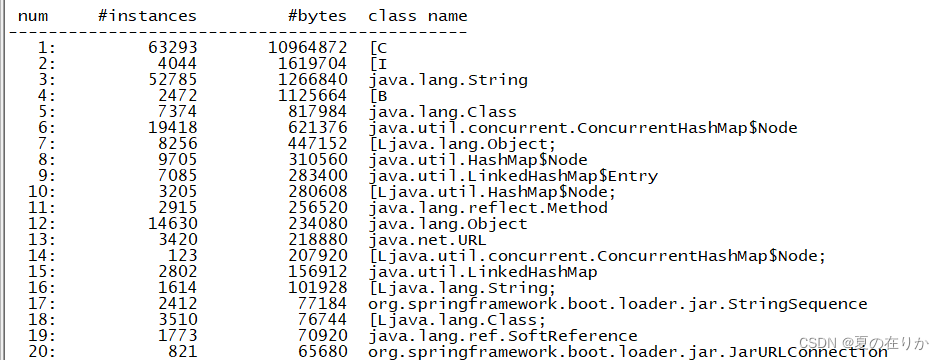
这里展示的一般都是框架或者jvm的类,最好先查看自己写的类
- num: 编号
- instances: 实例数
- bytes: 当前类所有对象总大小(单位:字节)
- class name: 类名
jmap -histo 23273|grep com.jvm|head -50
这里可以看到我们自己的类中占用最大的的是com.jvm下的Application的某几个实例和IndexController, 由于Application 只是一个启动类,基本可以排除Application的问题,排查对象重点为indexController -
浅看一下heap信息
jmap -heap 23273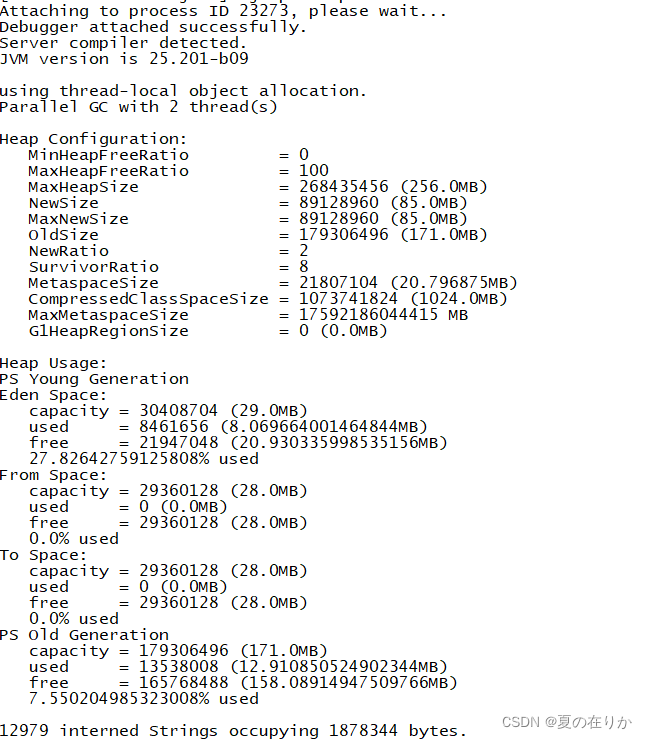
这里主要是看你程序启动的时候各个区大小到底为多少
上面可以看到我们的程序最大堆内存只设置了256m
其中:
新生代85m: eden区:29m, suvivor-from区:28m, suvivor-to区:28m
老年代171m
这时候就应该考虑增加堆内存的大小了,但是如果这里内存大小设置没问题,那么就需要进一步排查 -
检查程序中是否存在死锁
jstack $pidjstack 26872 #这里为了演示,程序重新启动,pid变了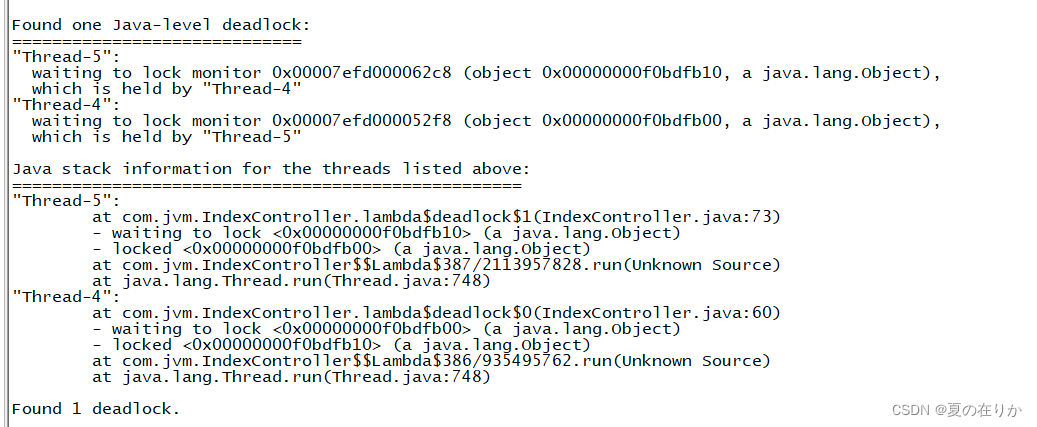
可以看到这里是存在一个死锁的,检查代码的相关行,修改引发死锁的代码
但是如果这里没有死锁,只有堆栈信息,那么就继续往下排查 -
检查每个线程的内存和cpu使用情况
top -p $pidtop -p 26872
按下H,获取进程下每个线程的线程的执行情况和线程号,如下图所示,当前线程号为26972的线程cpu占用超高
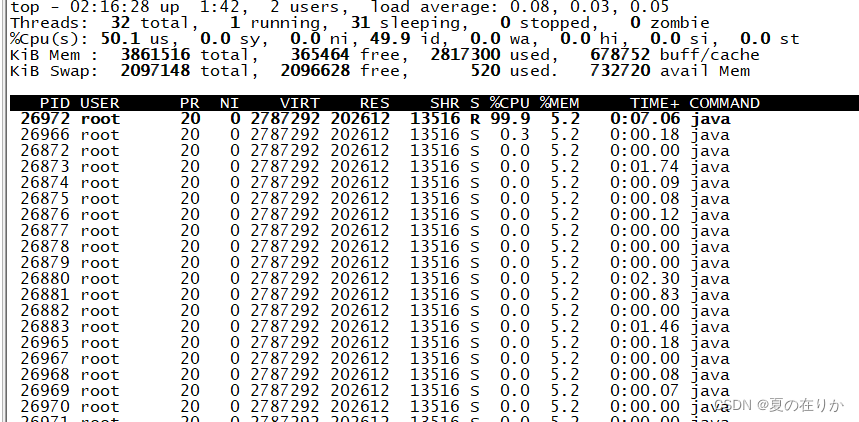
获取该线程号的16进制码
printf "%x
" $pid;printf "%x" 26972;
执行 jstack $pid|grep -A num $tid十六进制jstack 26872|grep -A 50 695c|grep $yourPackage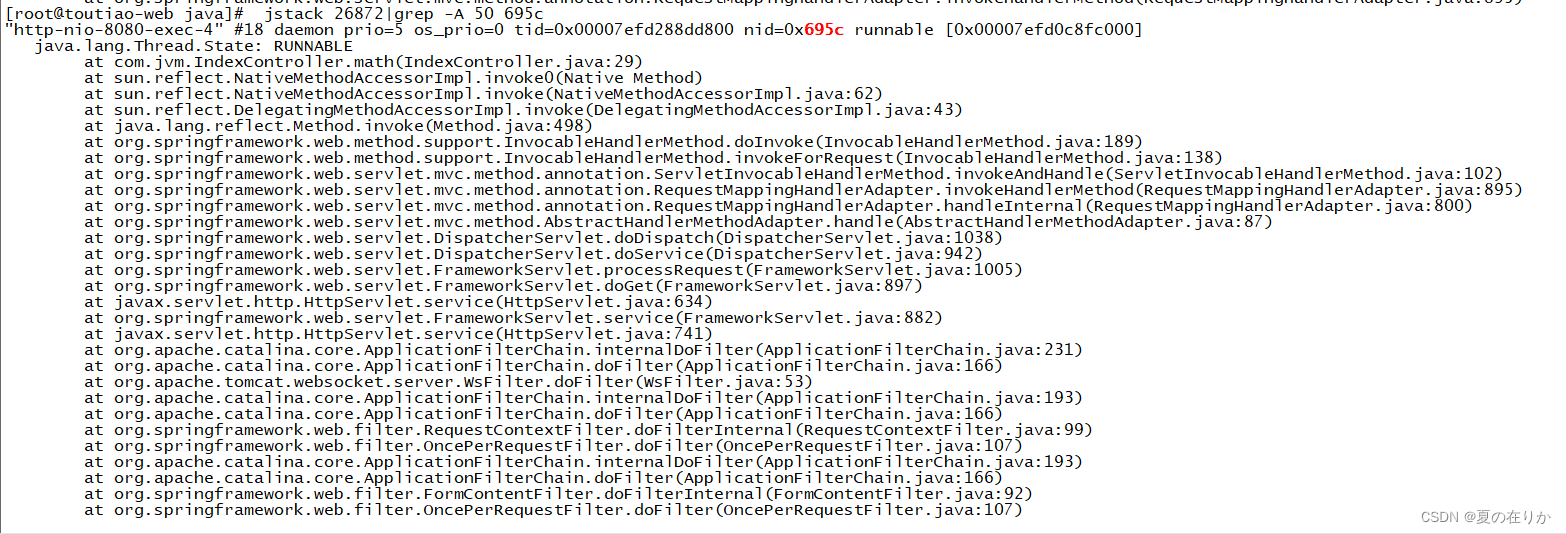
可以看到问题代码在这里了,查看对应的代码
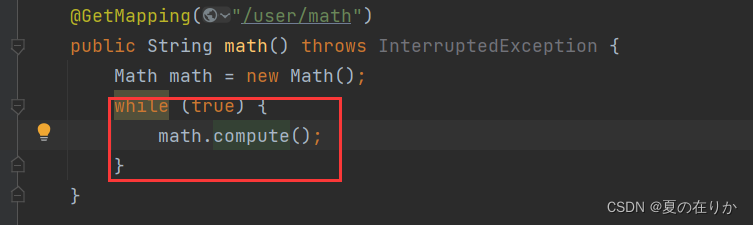
确实存在问题
但是实际生产中,问题往往没有那么明显,可能到这里还是无法发现具体的问题,别急,接着往下找 -
查看GC回收的情况
jstat -gc $pid $timeInterval $times
timeInterval:时间间隔, 单位ms(非必选)
times: 打印次数(非必选)# 这里我又重启了一次,pid变了,每隔1秒打印一次,总共打印10次 jstat -gc 38026 1000 10
S0C:第一个幸存区的大小,单位KB
S1C:第二个幸存区的大小
S0U:第一个幸存区的使用大小
S1U:第二个幸存区的使用大小
EC:伊甸园区的大小
EU:伊甸园区的使用大小
OC:老年代大小
OU:老年代使用大小
MC:方法区大小(元空间)
MU:方法区使用大小
CCSC:压缩类空间大小
CCSU:压缩类空间使用大小
YGC:年轻代垃圾回收次数
YGCT:年轻代垃圾回收消耗时间,单位s
FGC:老年代垃圾回收次数
FGCT:老年代垃圾回收消耗时间,单位s
GCT:垃圾回收消耗总时间,单位s
这里最重要的是观察各个区多长时间会被占满,多长时间触发一次young GC, 多长时间触发一次fullGC,比如下面:
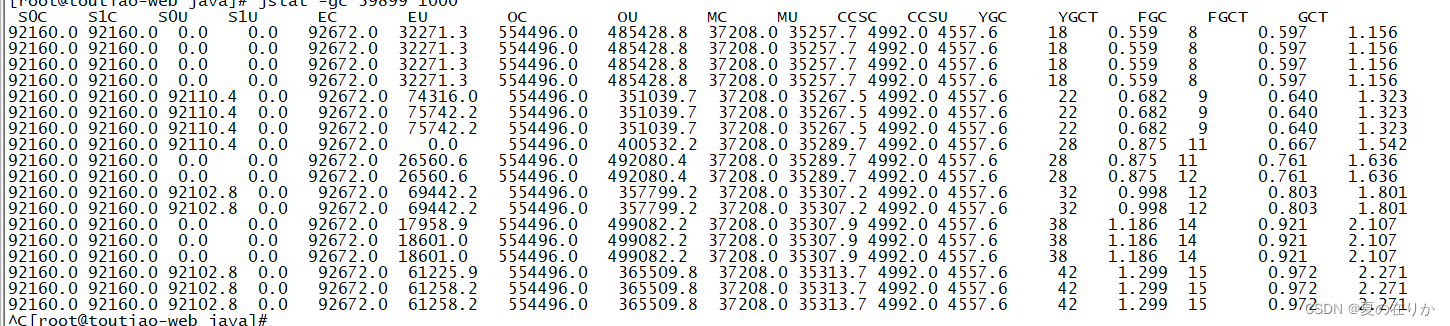
可以看到因为young GC频繁,可能是jvm的对象动态年龄判断机制使大量对象进入老年代,从而触发full gc, 需要调大年轻代大小
但是调整后继续观察
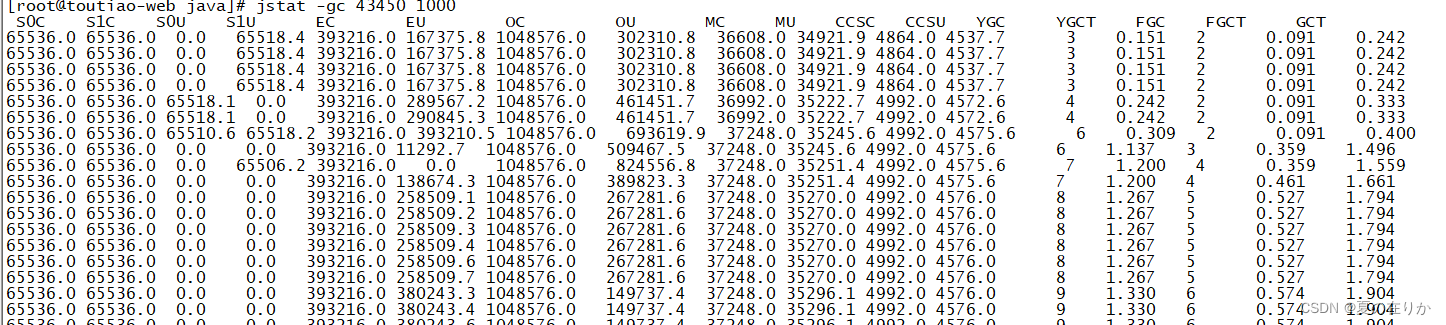
发现younggc减少了,但是full gc仍然频繁,证明程序中可能存在执行时间较长或者大量创建对象导致gc的时候只能回收少量内存,老年代空间担保机制导致full gc频繁,按照上面的方法看看是不是我们自己写的类大量新增jmap -histo 43450|grep com.jvm|head -n 50
可以看到user类大量新增,至于是哪个线程,可以使用jstack查看cpu使用率最高的,如果顺利的话是能很快定位到问题代码的
不过往往生产上的代码比较复杂,并且如果开发不规范的话,比如不适合的死循环往list里面加基本类型的数据对象,或者数据库查询到的结果集用map接收,或者jvm级缓存用了map,那么要找出新增的很快的对象是很困难的(所以程序员开发代码一定要规范)
如果以上这些都没能排查到问题那么就要分析GC dump文件和日志文件了
-
- 程序GC情况查看
-
GC排查过程
-
分析日志
- 学会分析日志是非常重要的,有的开发者还没有看过业务日志,就直接上手查看GC的dump文件,结果分析到后面发现一团雾水,抓不到重点。要知道生产的代码也业务往往非常多且复杂,如果没有一个大致的方向,直接上手分析dump文件可能会让你走很多弯路,最后也往往很难找到正确的原因
- 首先看看到底是哪里的代码抛出的gc异常,如果运气好,抛出异常的恰好是业务代码,那么根据日志里面记录的参数尽快排查当前的代码(推荐日志记录上接口或者业务代码中关键的参数,这样就能很快复现出gc场景)
- 如果运气不好,抛出异常的代码不是自己的业务代码,那么注意观察gc前后有没有明显未执行完的线程,比如数据库查询,只打印了查询的sql和参数,没有打印出返回的结果条数,那么就要注意是不是这个sql查询过大导致的oom
- 如果还是没有头绪,那么只能分析dump文件了
-
分析dump文件
-
导出dump文件
可以用命令行导出: jmap -dump:format=b,file=$filename.hprof $pid 也可以在启动参数中添加 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=path/filename.hprof -
分析软件
这里推荐两个分析软件:
- 一个是jvm自带的jvisual,在jdk的bin目录下可以找到(适用于简单的GC问题分析)
- 另一个是eclipse memory analyzer(也叫MAT)
- 还有一个在线平台 gc-easy,不用安装软件,上传dump文件能在线分析。但是不推荐这个方法,毕竟dump文件中包含一些项目的内部数据,上传到外网的服务器有风险
-
jvisual
- jvisual提供很多功能,可以离线设置可以在线监控内存,但是生产系统往往在内网,无法在线监控,这里我们只说离线功能
- 基本介绍
打开一个dump文件默认显示这个dump文件的基本情况,上面是内存的基本信息,下面是被阻塞的线程情况,参考意义不大
我们点击第二个标签页-类
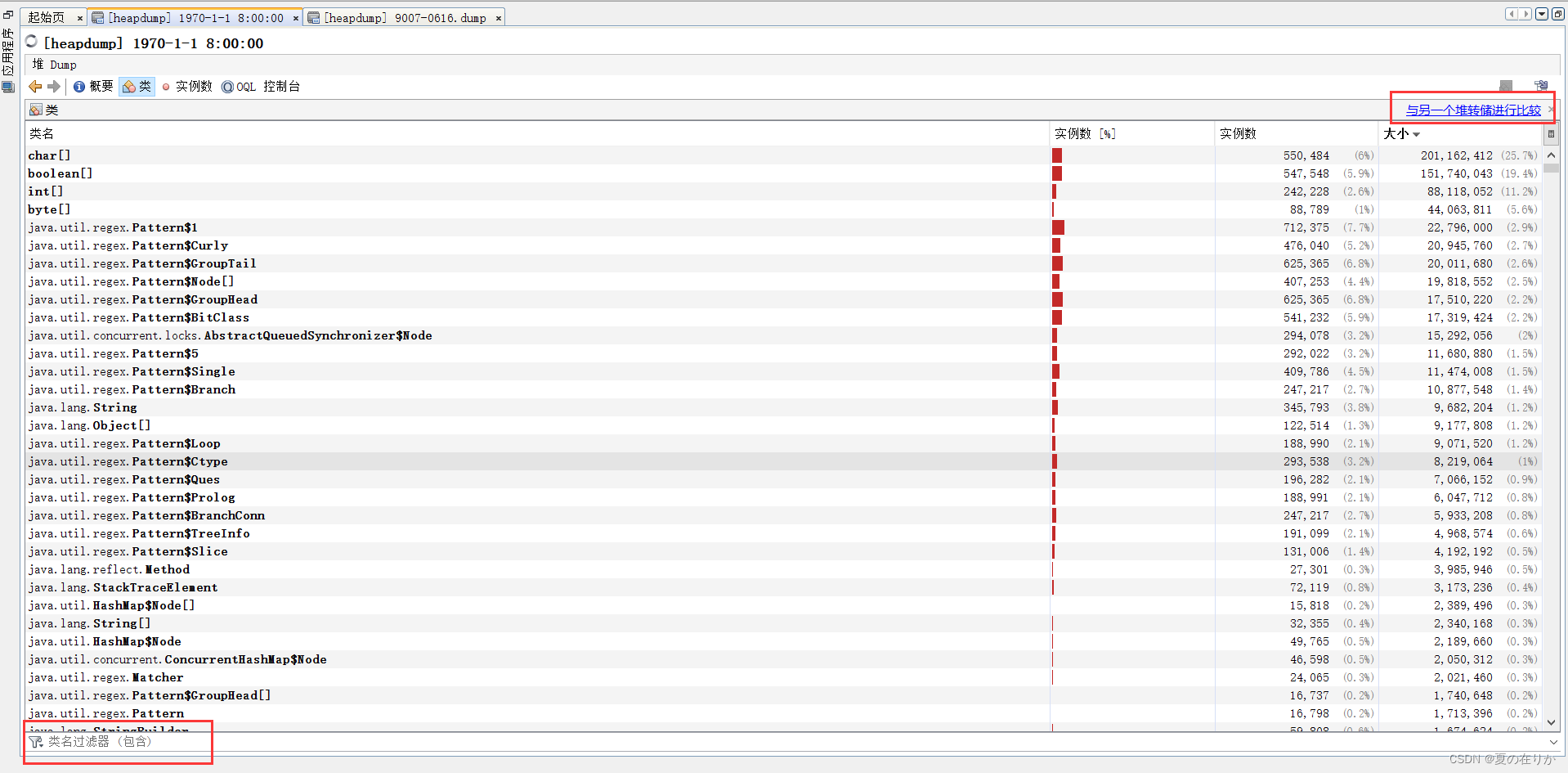
这里展示的信息比较多,类名,实例数,大小,支持按照大小或者实例数等排序,左下角可以查询类名或者包名。右上角是这个工具比较重要的一个功能,与另一个堆存储进行比较。
一般为了定位到底是哪个类增长导致的oom,我们用定时任务每隔一段时间导出一份dump文件,然后比较发生gc时的dump文件和正常的GC文件比较,定位问题,下面就是一个生产上的例子,这是两个堆文件的比较信息,我们按照大小排序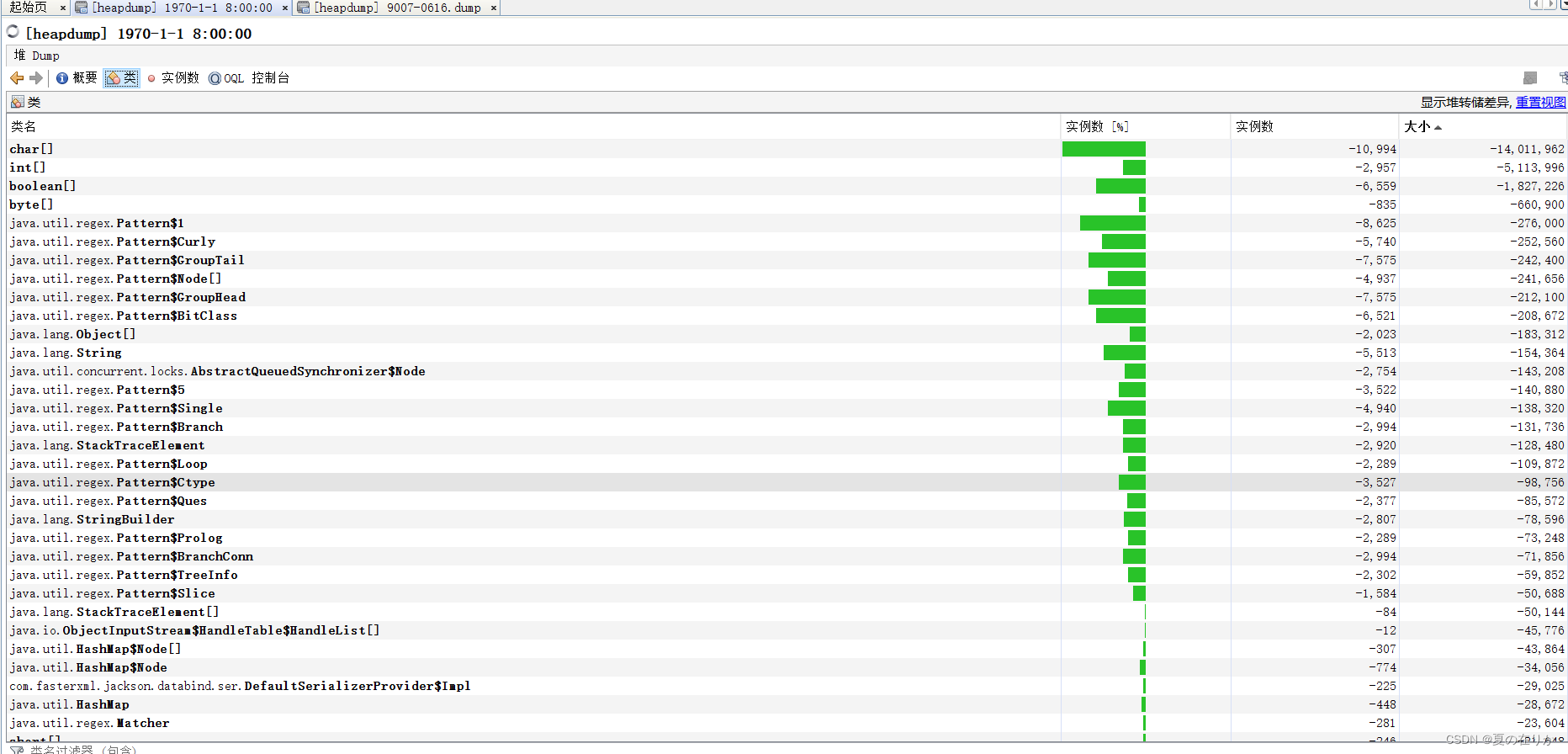
排在前面的都是各种基本类型的数组和java基础类等,这个基本可以忽略不看,因为几乎所有的对象都要用到这些类,如果从这些类开始排查会浪费很多时间,我们稍微往下拉,看看有没有我们熟悉的类(定位GC问题的时候一定要有熟悉代码的开发在旁边!!)
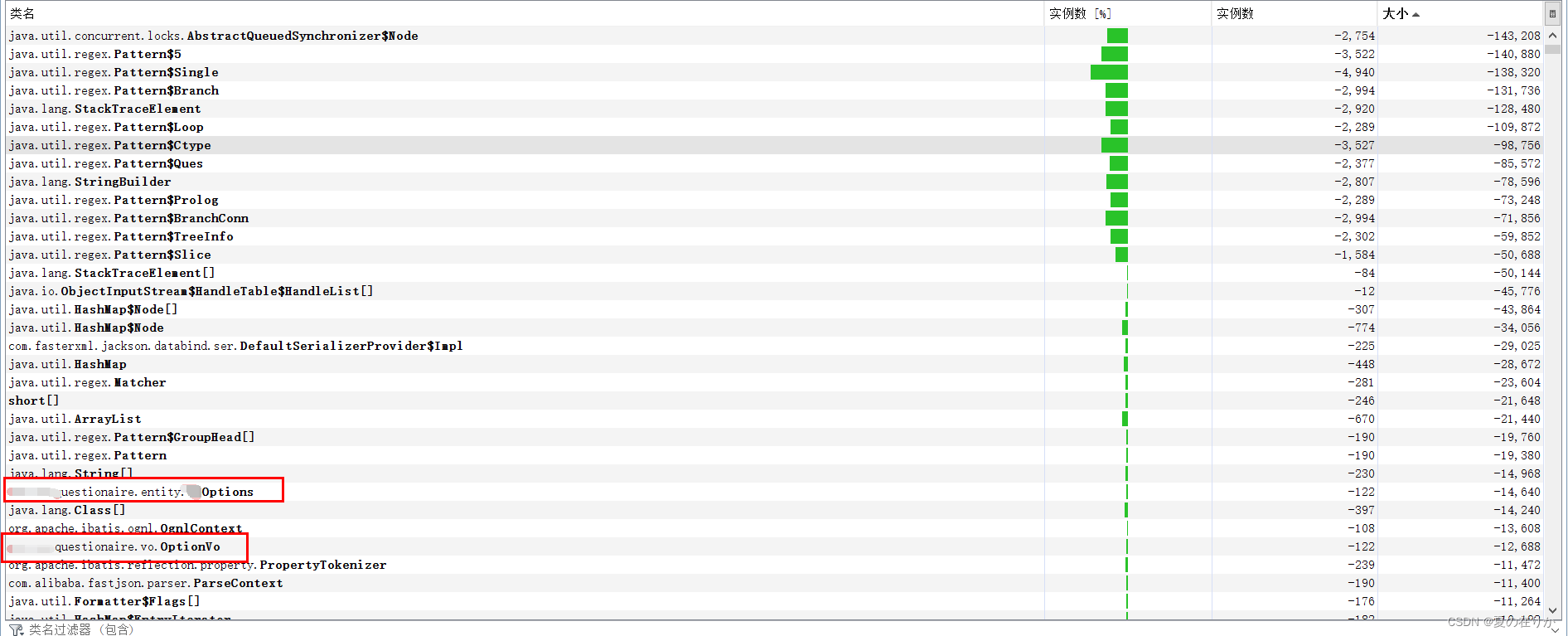
这下我们看到了一个熟悉的类,options和optionVo。查看代码,optionVo是options中引用的一个类,加载在list中,这时候我们心里有一个猜测了,会不会是因为这个list过大导致,上面的ArrayList确实增加的较大。
我们回过头来查看系统的日志文件,查看日志轨迹,确实包含这个类的某个接口没有完成完整的日志记录,从日志里面取出来请求的参数去数据库查询这个对象,发现客户将数字增长的步长设置成了复数,导致代码生成选项的时候一直不停循环,达不到停止的条件,从而引发了GC。
修改异常的设置和代码控制,GC问题没有再出现过
-
eclipse memory analyzer
- 这个分析工具比jvm自带的jvisual更加强大,可以帮你初步分析内存泄漏的原因,现在我们打开一个dump文件看看
- 基本介绍
打开时会让你选择默认打开的页,一般我们会选择Leak Suspect Report
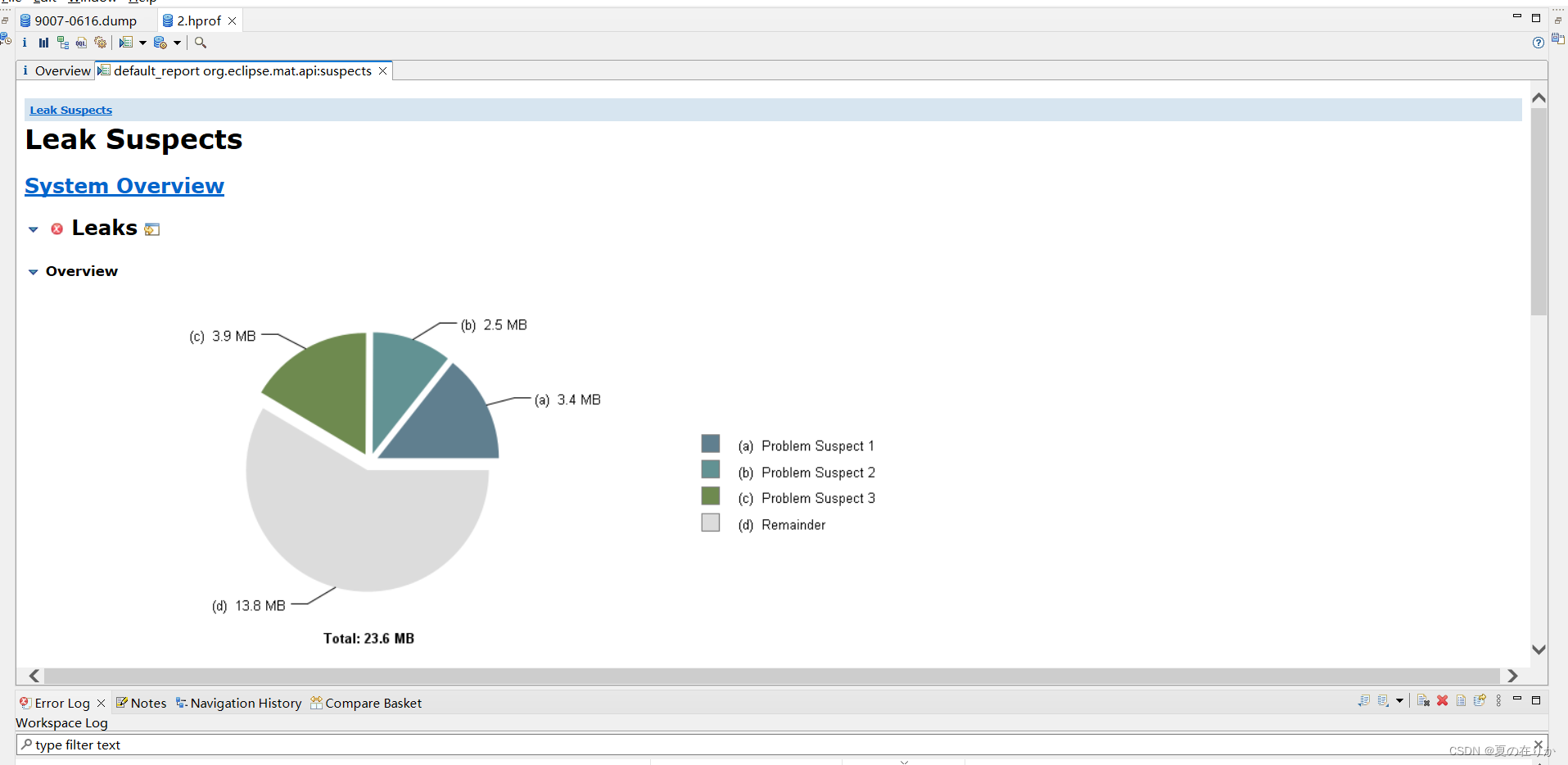
上面就是它帮我们找出来的可能存在内存泄漏的地方,我们先不看这里,看看这个工具还提供了什么功能。标签页旁边有个overview,我们点击看看有什么
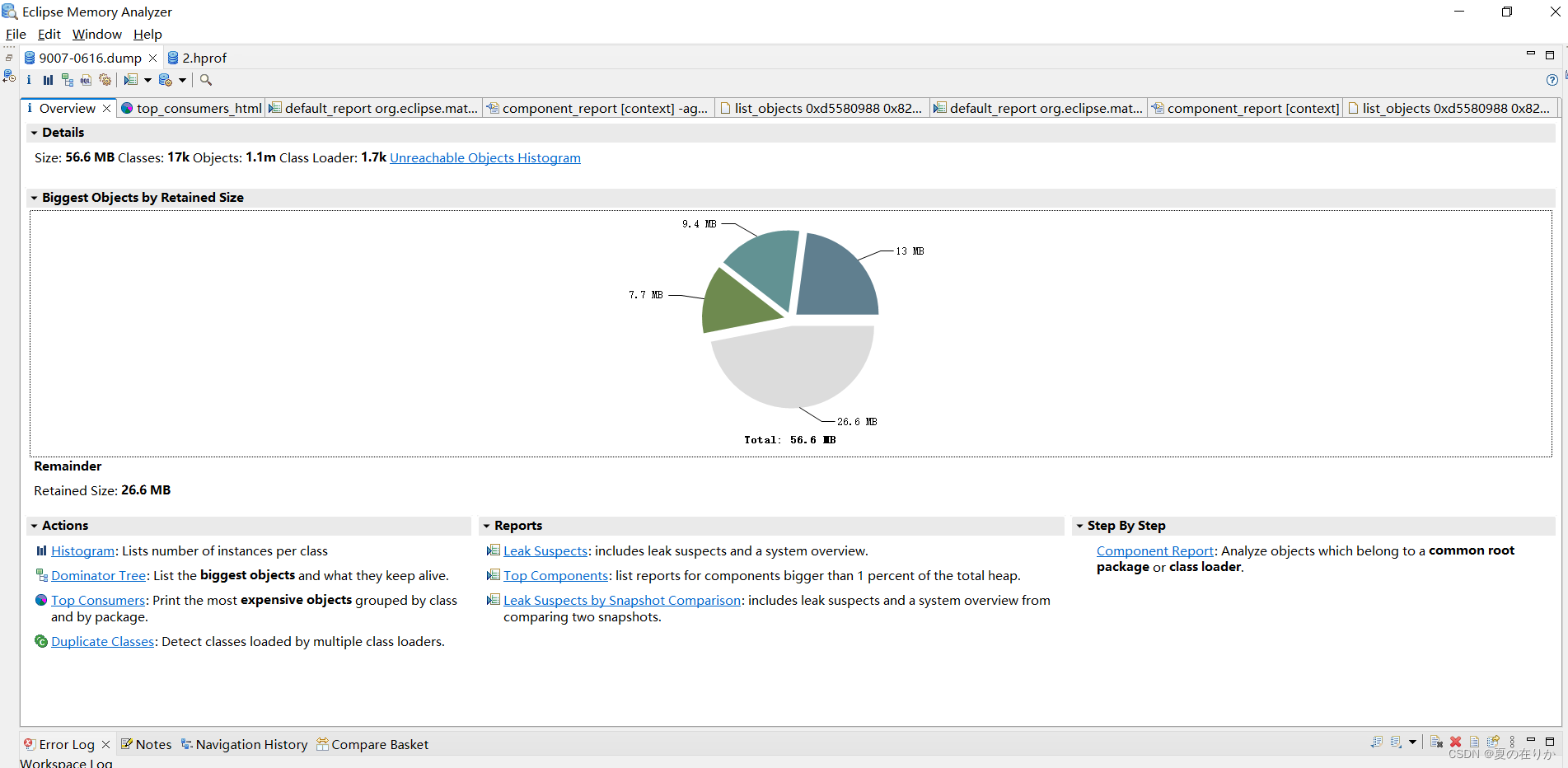
-
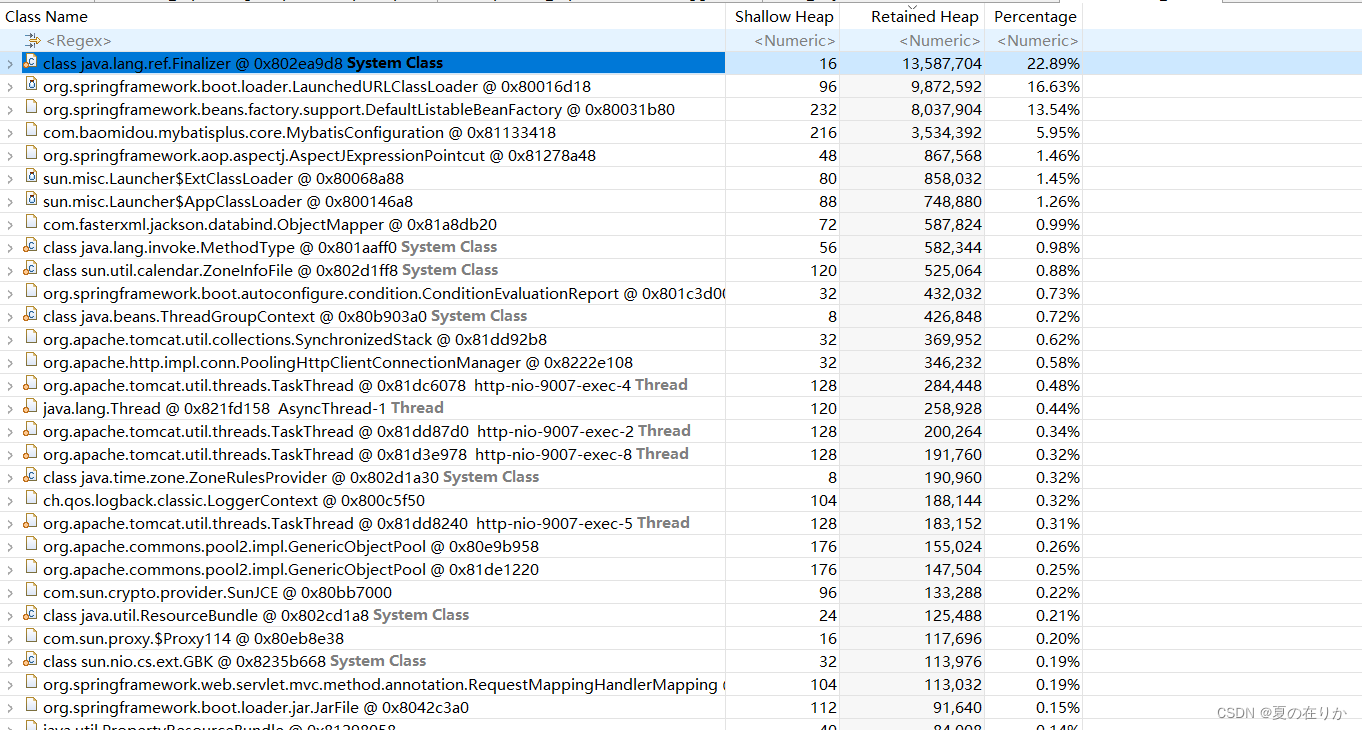
Unreachable Objects Histogram
最上面:Unreachable Objects Histogram。这里都是仍然在内存中,没有被GC回收的对象。点击这里
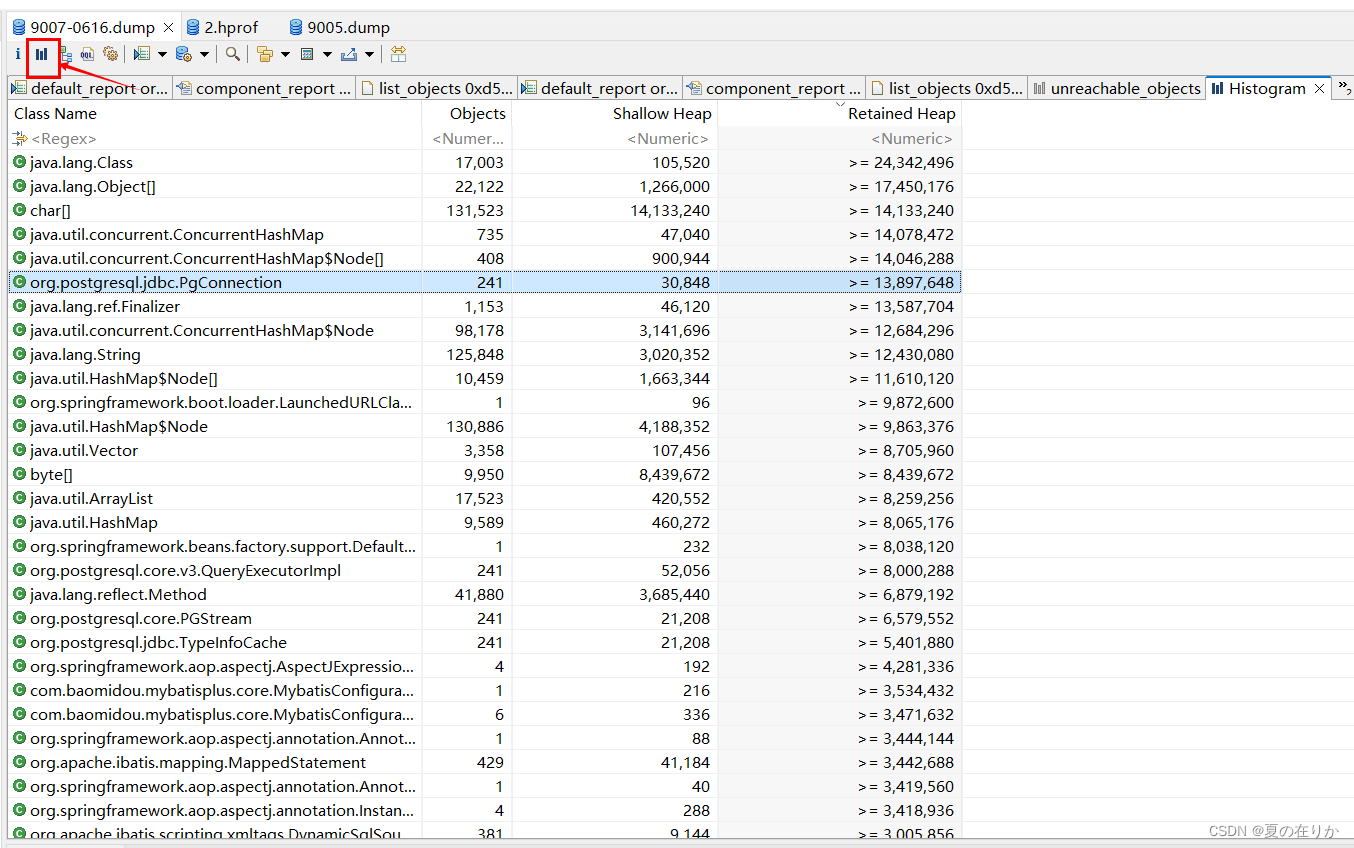
出现这个页面后点击左上角上面的图标,获取完整的内存分析图表。
objects: 对象数量
Shallow Heap: 浅对象堆大小(对象本身的大小,包括成员变量,对象头信息等,不包括它引用的对象)
Retain heap: GC回收时能被回收的该对象的引用对象的总大小,这个更能反应对象的真实大小。
我们按照retain heap排序,大致看一眼发现pgConnection占比非常大,猜测是否时因为数据库查询大数据导致某个connection很大,并且一直未释放
我们先把定位到的问题放一放,介绍完这个工具再来分析 -
Histogram
和上面的功能一样 -
Dominator Tree
和histogram类似,不过histogram是按照类进行统计,Dominator Tree是根据对象来统计的
-
Top Consumers
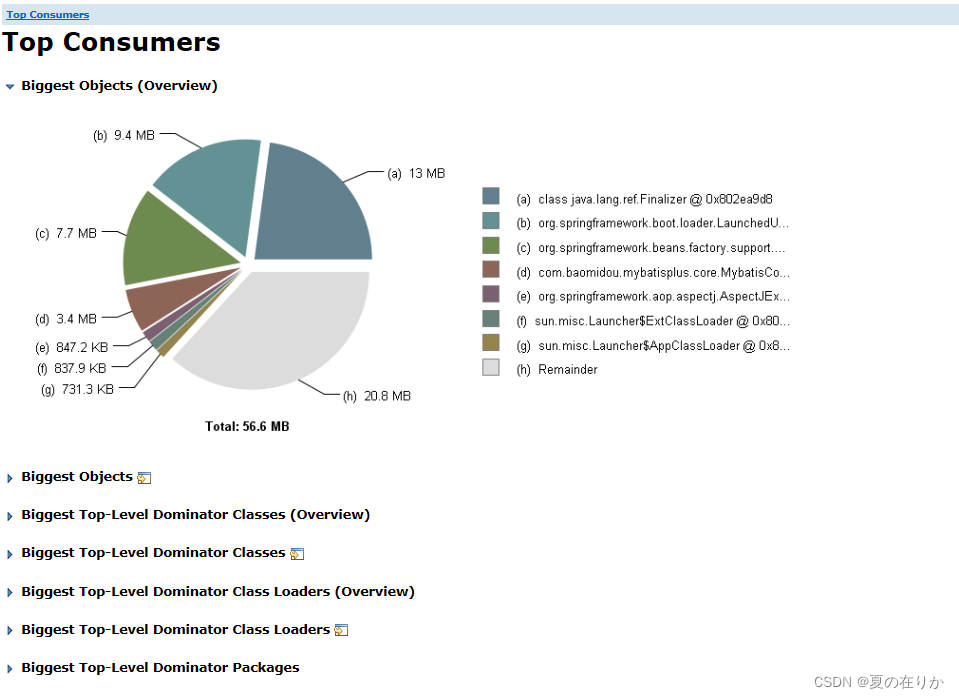
通过图形的形式列出来比较占用内存的对象 -
Duplicate classes
不常用 -
Leak Suspects
内存泄漏分析,我们点开看看分析了什么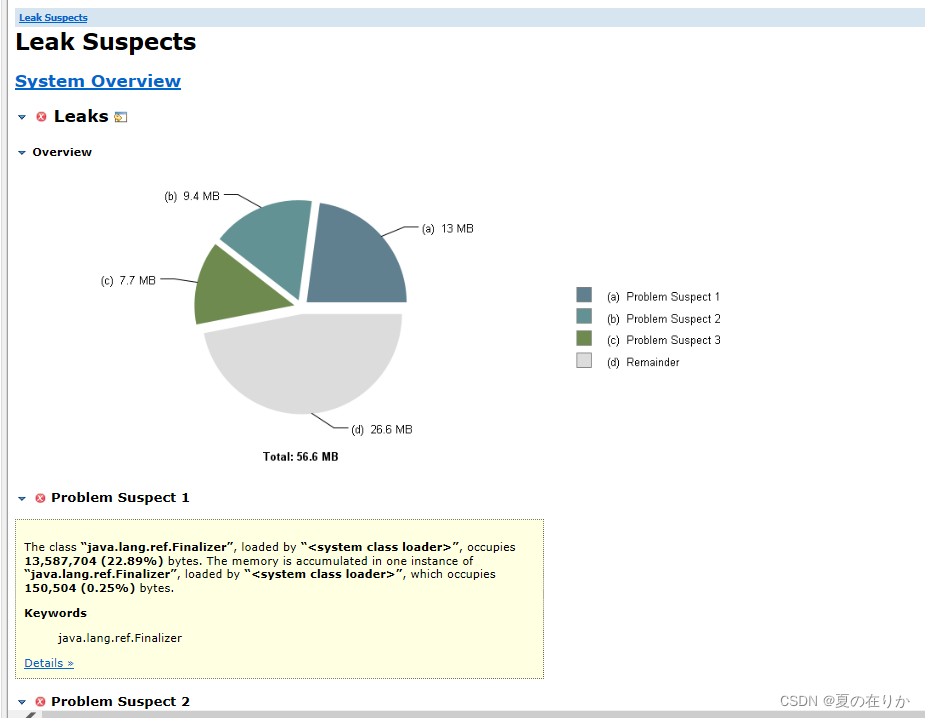
上面是一个图表,总共可能存在3个问题。图表下面是可能存在的问题, 我们点开Problem Suspect1下面的details
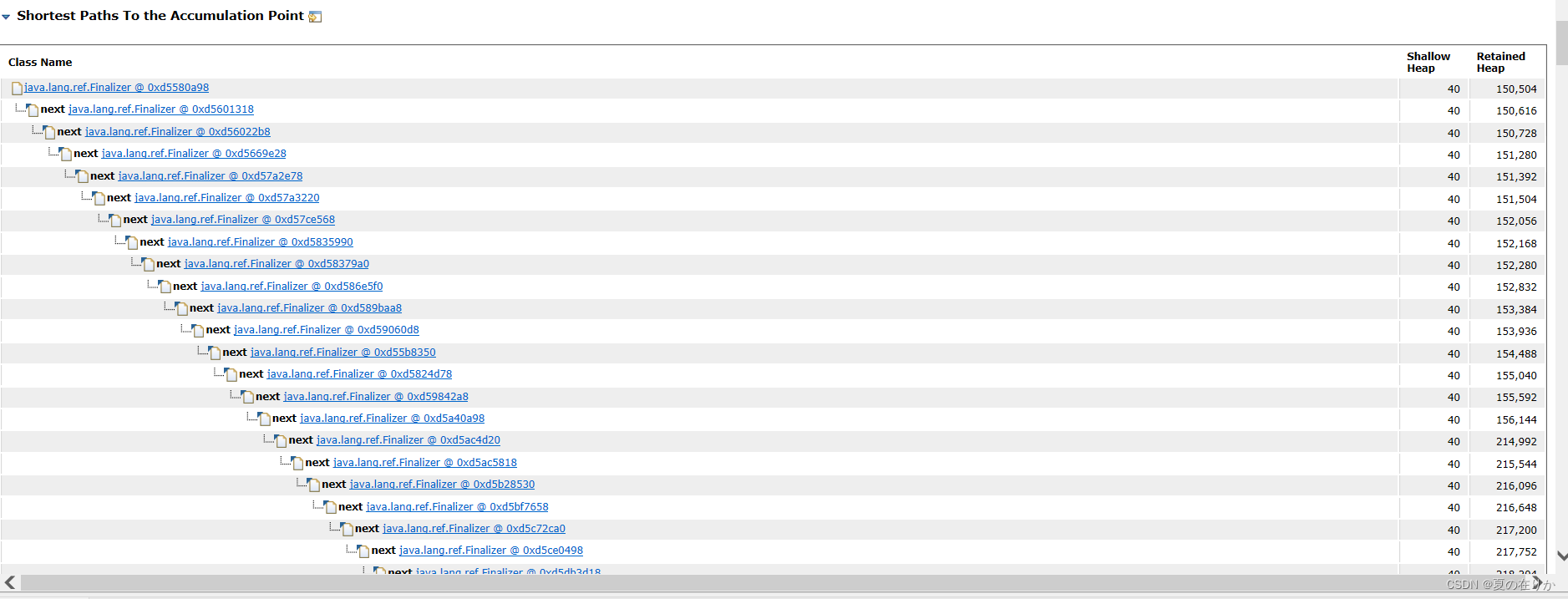
它给我们列出了可能导致内存泄漏的类和引用。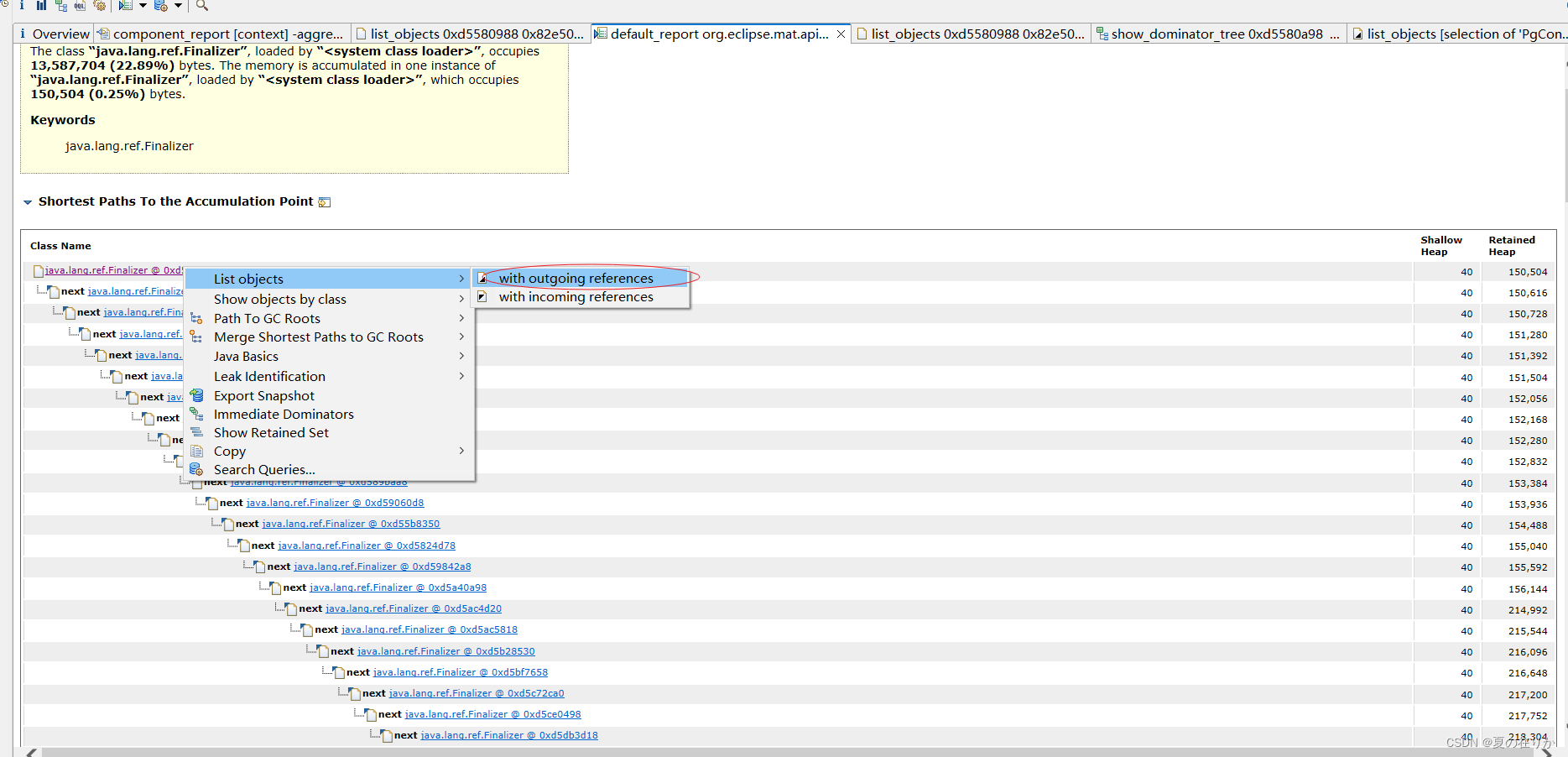
我们点击顶部对象,选择list object。有两个选项:
with outgoing references:当前对象和其引用的对象
with incoming references:当前对象和引用它的对象
我们这里先看看这个对象基本情况,选择outgoing
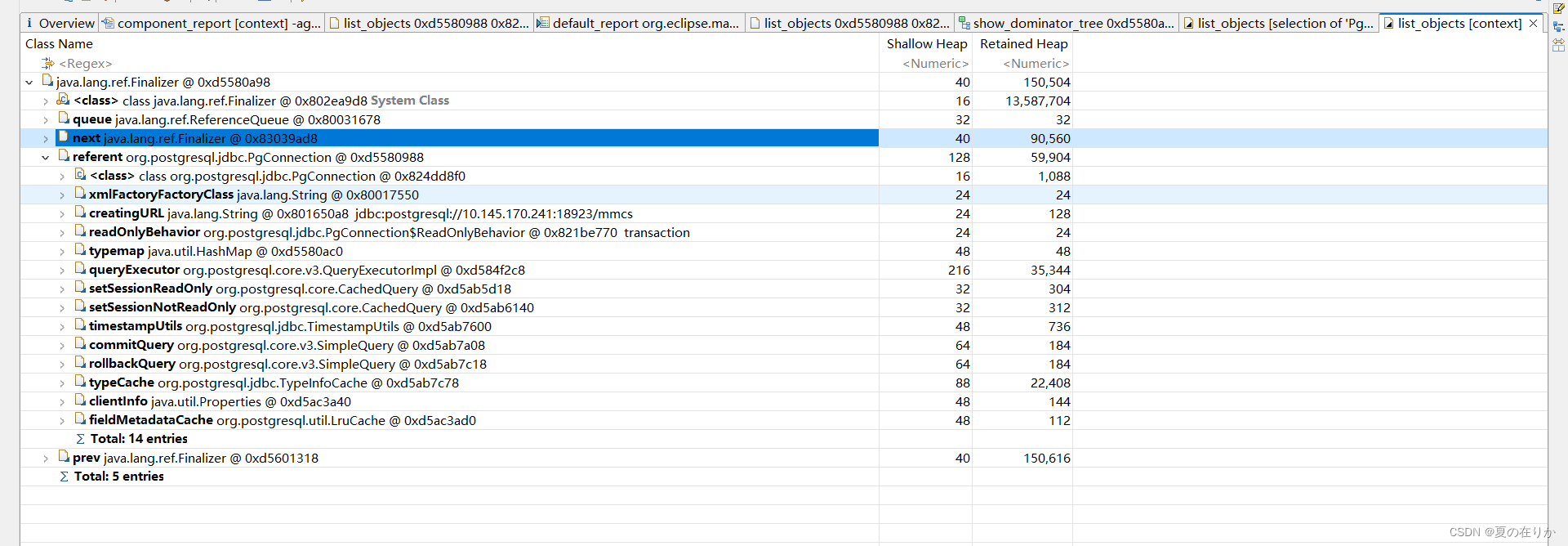
我们看到这里referent,关联的对象是pg的连接。再多点开几个next(下一个引用链),查看他们的reference都和pg有关,我们返回上面的report页,MAT总结的大对象确实包括pg连接
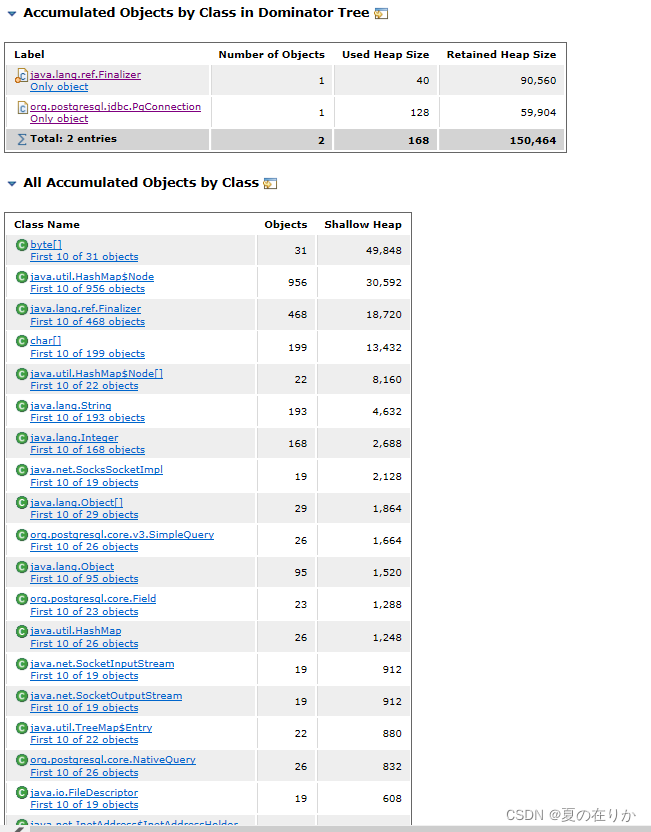
我们点击它推荐查看的pgConnection,还是with outgoing references
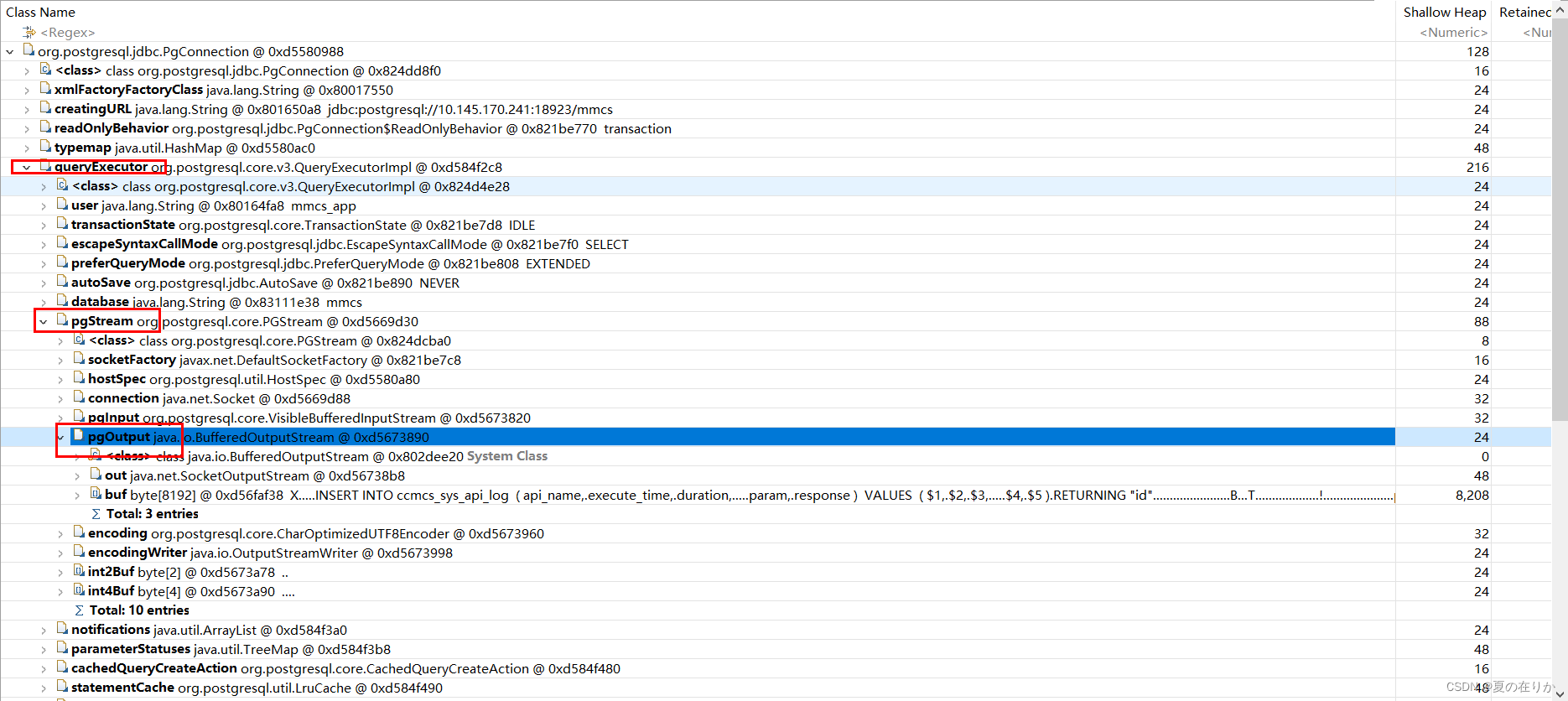
这里能看到pg执行的sql语句。这里是系统执行记录api请求记录的sql,这个sql可能因为返回体或者请求体较大导致这个connection过大,查看了这个连接的参数,并不是导致GC的根本原因,可能还有另外的pg请求导致GC
没办法,它推荐的不对我们只能自己定位 -
Top Components
上面MAT没找到根本原因,我们只能自己分析。这个功能能够分析占比最大的模块在哪。我们点开看看
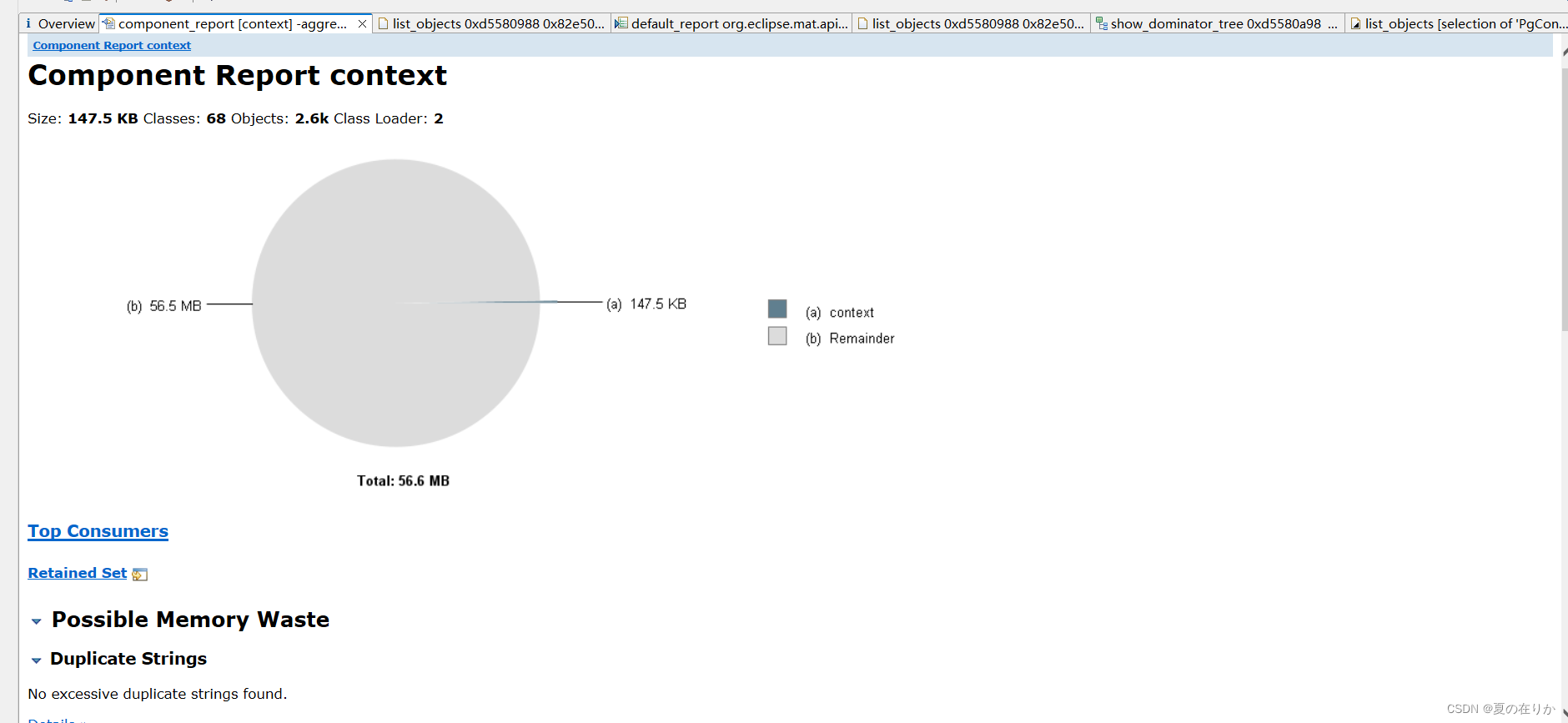
往下看看,有没有有效信息
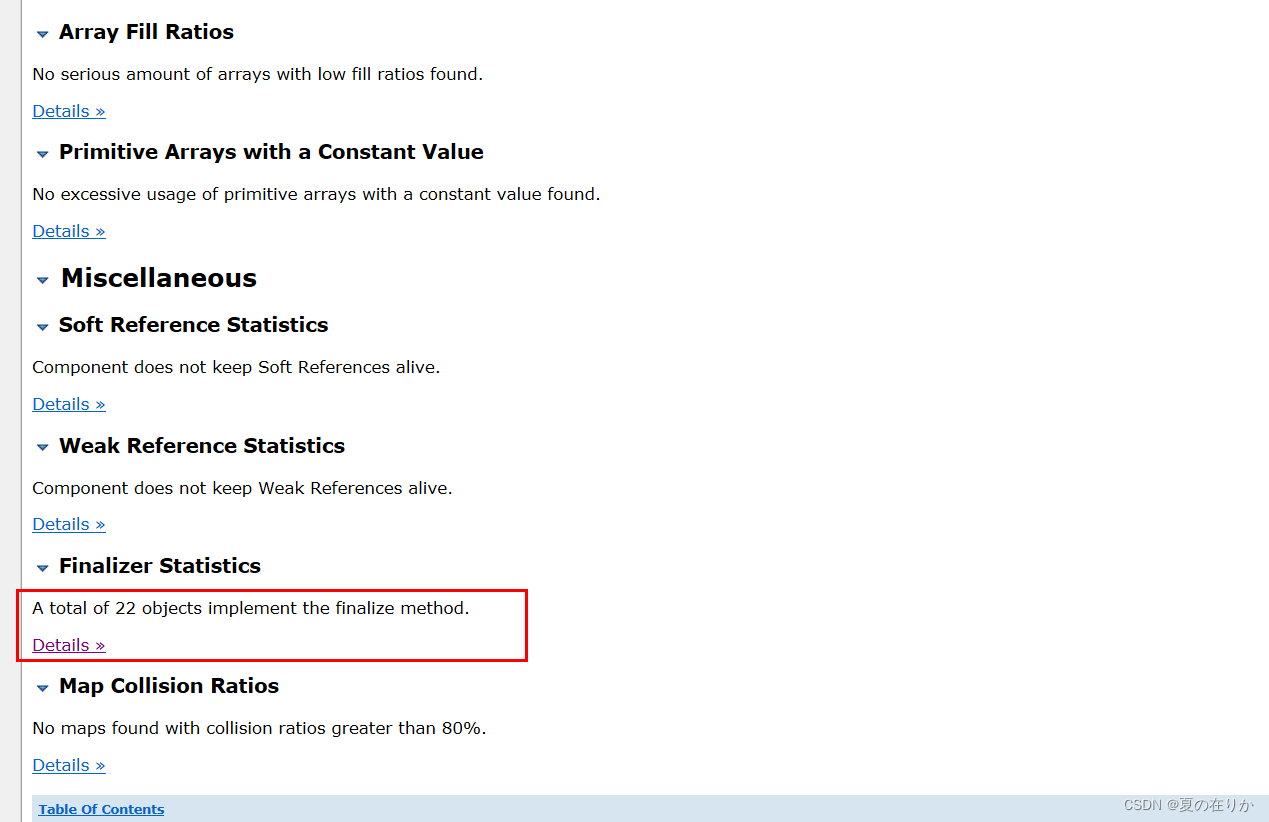
我们看到再Miscellaneous这里,看到了熟悉的Finalizer(其他选项下面的都没有给出建议,上面的两个选项GC弱引用和软引用没有太大的参考价值)。
之前内存泄漏分析的地方出现了大量未被回收的Finalizer对象,我们点开details查看
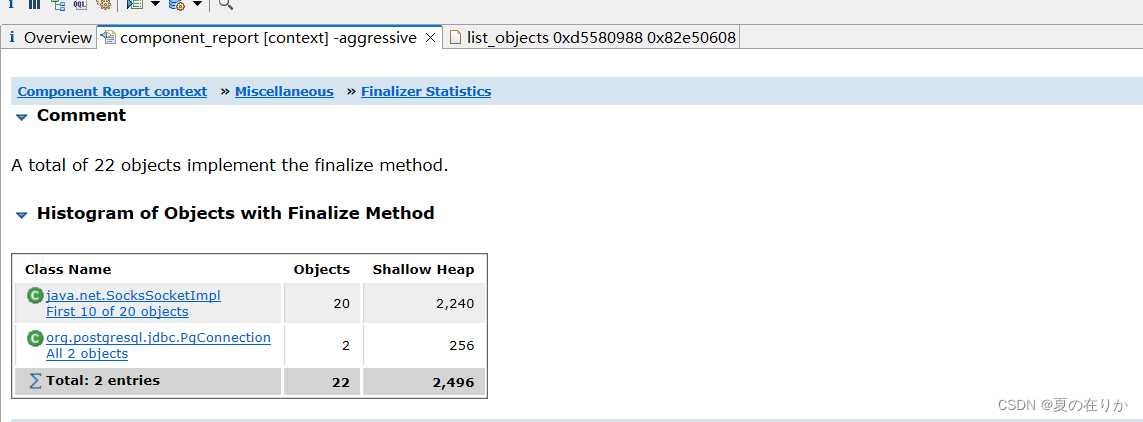
这里推荐了两个类
socket不用看,太多的类都会用到它,不好定位,直接点pg下面的All 2 objects
其中第一个就是在上面内存泄漏的地方查看过的pg连接,我们不重复看了,看看第二个是什么
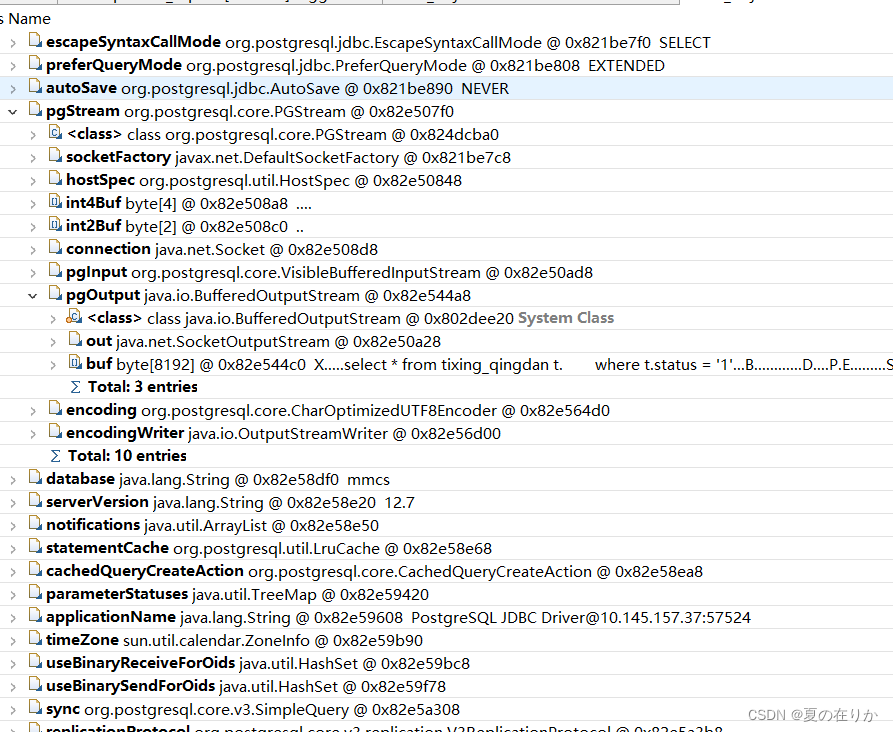
这里可以看到这个地方的sql,只有一个查询条件。找到对应的代码这里,发现确实没有对查询条件进行约束,导致查询大量数据,系统承受不住,oom了。查看系统的业务日志,这条sql确实没有输出查询的总条数。
这里说一句,一定要找对代码熟悉的开发确认,这次GC定位我是帮别的项目组定位的,一开始找的是项目的经理,询问了他这个sql是否会查询大量数据,对方表示这只是小数据表,不会存在内存被撑爆。因为我还有别的项目所以后面没有再跟踪这个事情,就交给项目组自己定位,系统半个月内优化多次,GC问题仍然存在。由于系统上线任务紧急,最后经理只能再叫上我,和项目组所有核心开发拉在一起开会,在查看业务日志的时候,开发查看日志时发现这条sql没有添加具体查询条件,查询出六百万条数据,导致了系统内存泄漏。
结果最后定位出的原因就是我第一天告诉项目经理可能存在问题的地方,经理没有足够了解系统的数据情况,导致错过了正确的问题定位,后面所有的分析都是走错了方向,导致白白浪费了半个月时间。
所以各位如果需要解决GC的问题最好和系统核心开发一起定位,尤其你怀疑可能是系统代码导致的内存泄漏时。
-
-
-
-
最后祝愿大家遇到这种问题的时候都能顺利解决!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









