







机器学习之逻辑回归中的数学之美
这几天准备开一个新的专栏,记录一下自己学习的过程总结一些心得,希望和大家一起进步。虽然现在python的组件都是开盒即用,所有算法和api全部封装好,但是对于我来说,原理不明白是难以接受的。所以我学习的路线可能会从最基础的算法开始,希望能给你一些帮助
1.机器学习基本的几种算法
学习人工智能之前,我们需要了解算法的发展史和基本的机器学习算法,只有理论基础牢固了,建筑才会牢固。所以一起来看看最基本的几种算法吧
-
KNN算法(K-近邻算法):
- 简单来说就是通过和目标样本距离最近的样本类型来给目标样本分类
- 用来解决大容量类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
- 但是效率较低,计算量大
-
线性回归算法(Linear Regression):
- 线性回归是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式。
- 通常线性回归可以用来做预测,但分类效果不好
- 关于线性回归和逻辑回归的介绍我们会放在下面
-
逻辑回归算法(Logistic Regression):
- 线性回归不能用来做分类问题,逻辑回归在线性回归的基础上改进,可以用来分类
-
决策树算法
- 一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果,本质是一颗由多个判断节点组成的树。
- 决策树算法一个重要的思想就是根据信息熵进行信息分割,提取对象特征,找到最契合结果的特征分割推导路径。
例如:分析哪类人物最可能在末日中活下来,训练数据中,能存活下来的人特征都有身体强壮,没有疾病,跑的快等特征,那么决策树就会将这几类特征优先作为判断依据,有此类特征的人可能会活下来
-
集成学习
- 有的时候对于特征分散的分类问题,用单一模型可能效果不好
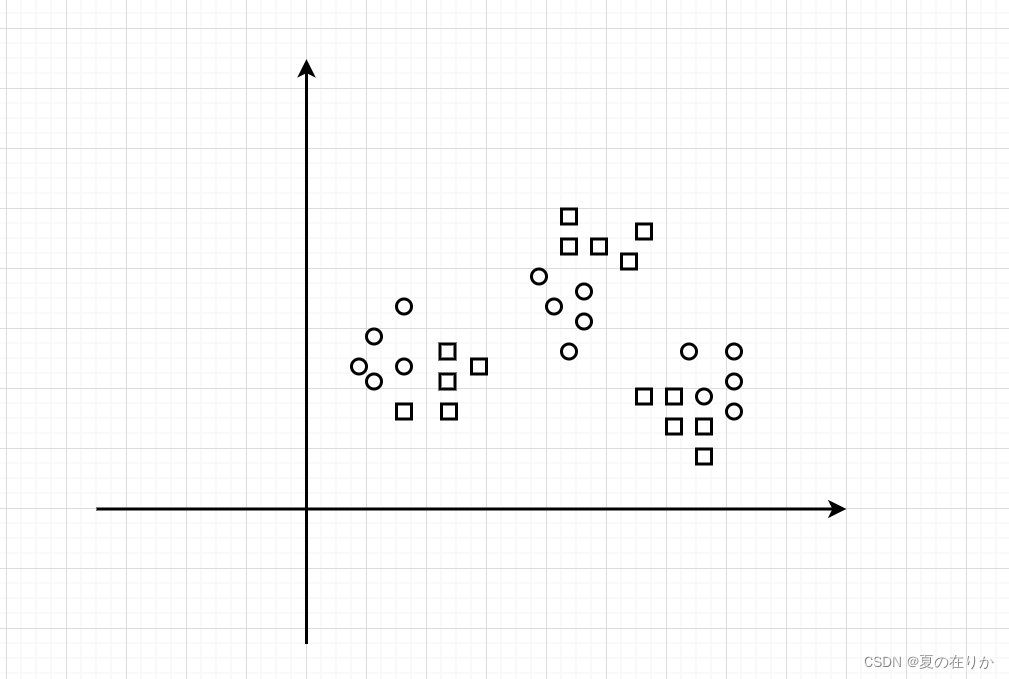
例如这种,如果用单一模型效果不好,可能会出现过拟合的情况,也就是模型可复用程度不高,换一组数据此模型就无法准确分类了。
这时不如将数据集拆分,每个数据集只用建立一个简单模型
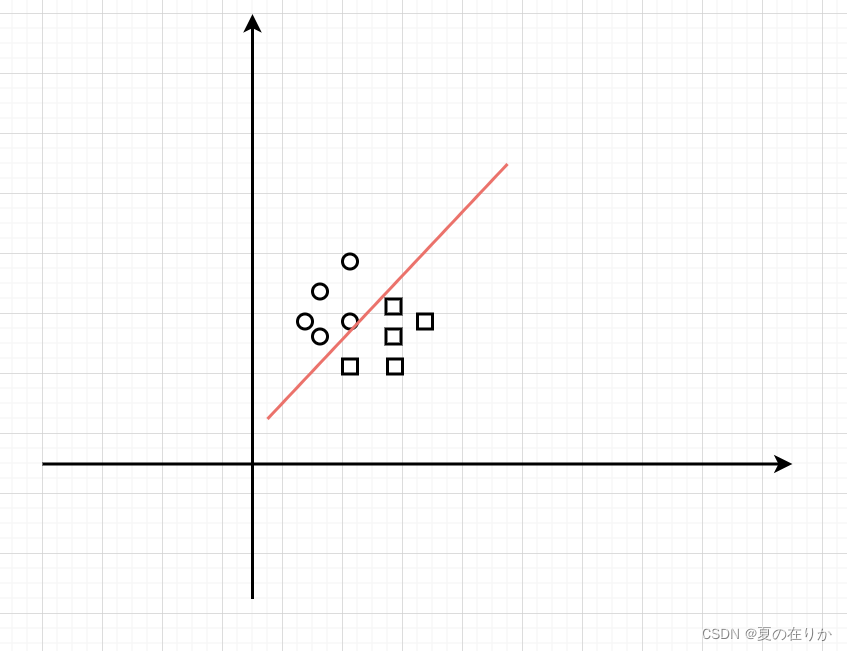
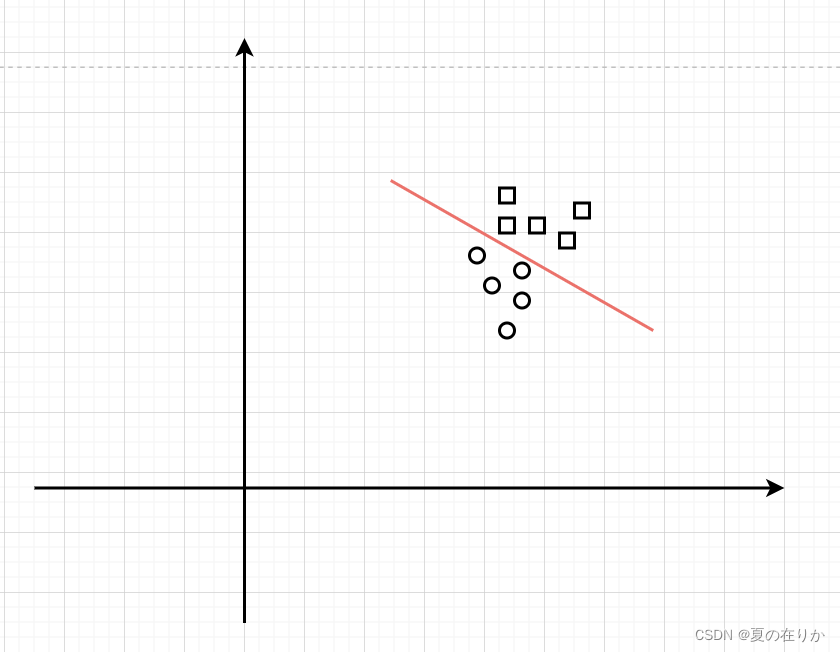
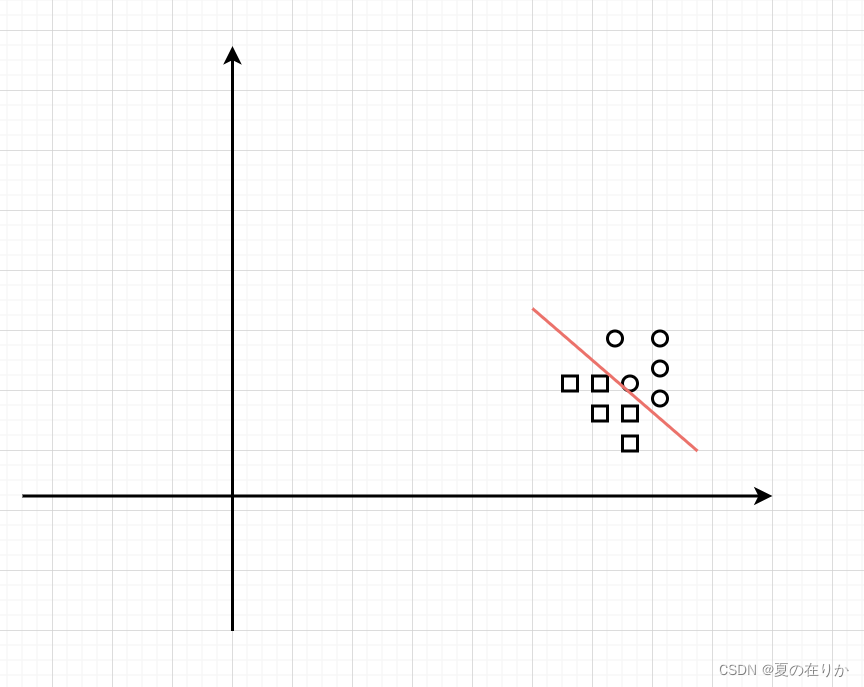
判断某些样本特征是否符合分类标准时,让多个模型平权评估, 如果多数模型给出True的结果,即判断该样本符合分类特征
- 有的时候对于特征分散的分类问题,用单一模型可能效果不好
-
聚类(K-means)算法
- 和之前的算法不同,分类算法都是有监督的学习算法,而它是一种典型的无监督学习算法,主要用于将相似的样本自动归到一个类别中
- K-means会先随机假定多个中心点K,没有标定的点选择最近的K点,并假定改点的类型为最近K点的类型
- 然后对每个K中心集团的点距离重新计算出每个聚类的中心点,如果计算的新中心点与原中心点一样,那么结束,否则重新开始锚定K点,计算距离,直到得出的中心点不再移动
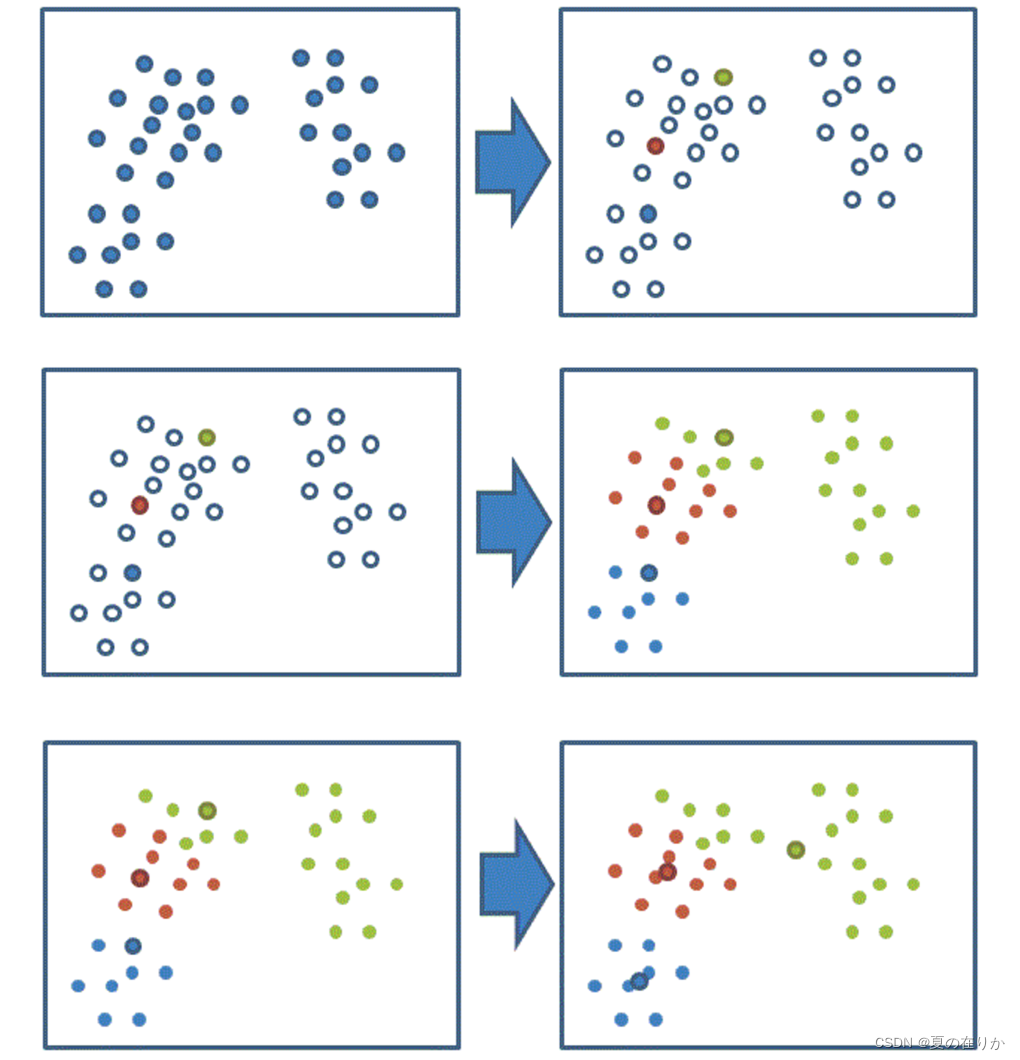
- K-means的缺点也比较明显,计算量大,效率低,收敛速度慢
-
朴素贝叶斯
-
支持向量机
- 找到一个超平面使样本分成两类,并且间隔最大。
2.什么是线性回归
2.1 什么是线性回归
- 在计算机的世界中,一切都被抽象成数字,对于某些情况,总能找到误差最小的线性方程 y=ax+b,使得给定一个随意x的值,可预测误差较小的y值。
- 而在计算机中,数据往往不是单一维度,例如一张图片,有RGB三个通道,如果你的像素大小的5像素, 那么就是三个5x5的矩阵。

我们把这些数据提取出来,放入特征向量中,作为 x x x, x x x的总维度就是 5 × 5 × 3 5\times5\times 3 5×5×3。
再比如预测房价,我们将地段,时间,人口组成一个 3 × 1 3\times1 3×1的向量 x x x,找出对应的方程,预测出对应的房价 y y y。
2.2 线性回归的公式
对于机器学习来说,线性回归的公式往往是以矩阵计算的:
通用公式:
y
=
w
1
×
x
1
+
w
2
×
x
2
+
w
3
×
x
3
+
.
.
.
+
b
y= w_1\times x_1+w_2\times x_2+w_3\times x_3+...+b
y=w1×x1+w2×x2+w3×x3+...+b
这里的
y
,
w
,
x
,
b
y,w,x,b
y,w,x,b都是特征矩阵,为了理解方便,就把矩阵抽象成单个参数,看起来更直观
y
=
w
T
x
+
b
y=w^Tx+b
y=wTx+b
(
w
w
w转置后对于计算机来说计算更加方便)
3.逻辑回归公式及设计原理
上面我们介绍了线性方程,但是线性方程只能用于预测,不支持用于分类。,为了解决这个问题,将会对上面的回归方程进行改进,也就是接下来要介绍的逻辑回归。
3.1 公式介绍
y
^
=
σ
(
w
T
×
x
+
b
)
\hat{y}=\sigma(w^T\times x+b)
y^=σ(wT×x+b)
y
^
\hat{y}
y^是
y
y
y的预测值,
σ
\sigma
σ是sigmod函数
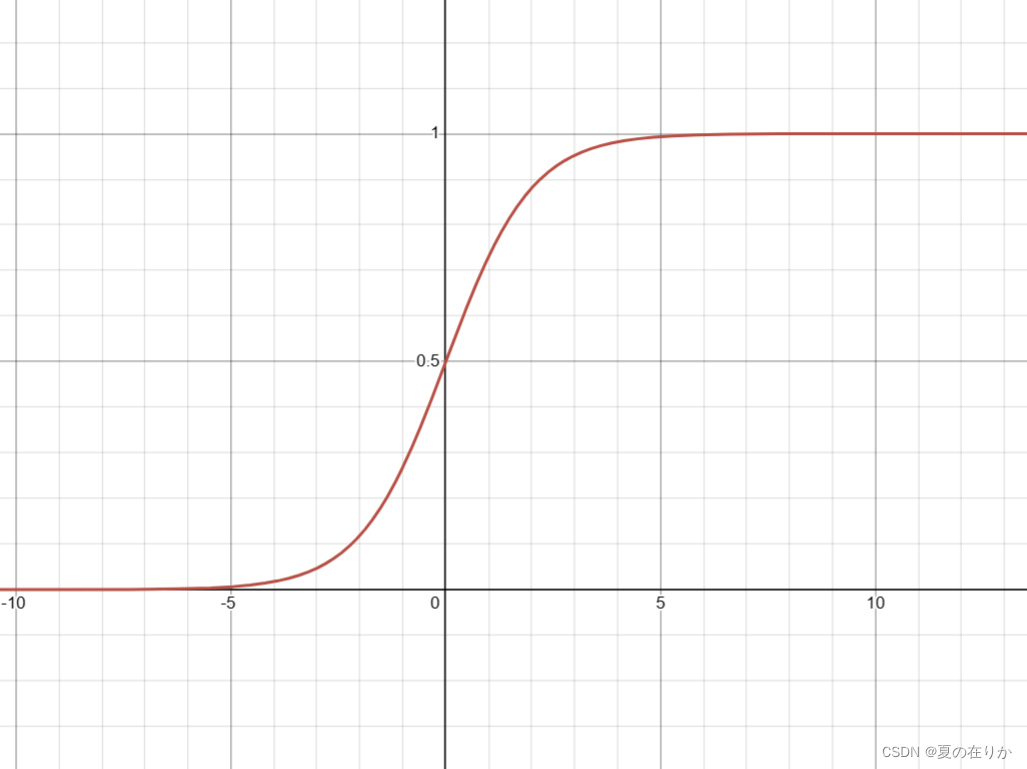
Sigmod函数是什么:
σ
(
z
)
=
1
1
+
e
−
z
\sigma \left( z \right)=\frac{1}{1+{{e}^{-z}}}
σ(z)=1+e−z1
3.2 为什么要使用激活函数
- 首先明确一个前提:在二分类问题中,目标值y只能为0或1,而我们希望输出一个分类概率,概率值在0-1之间。
- 但是线性函数最后得出的结果并不介于0和1之间,非常分散,无法进行很好的进行分类训练。那么如何让线性回归的值能控制在0和1之间且单调递增就成为了一个值得思考的问题。
- 我们不希望破坏线性回归的基础算法,因为线性回归表示了目标 x x x和 y y y之间的推导逻辑,需要保留,那么为何不在线性方程外面套一个函数,让线性方程的输出 y y y作为该函数的输入值,由该函数重新计算 y y y值对应的输出。
- 恰好sigmod函数符合要求,
y
y
y越小,sigmod输出的值越趋近于0,
y
y
y越大,sigmod越趋近于1,使用激活函数让输出的值更适应二分类模型的训练
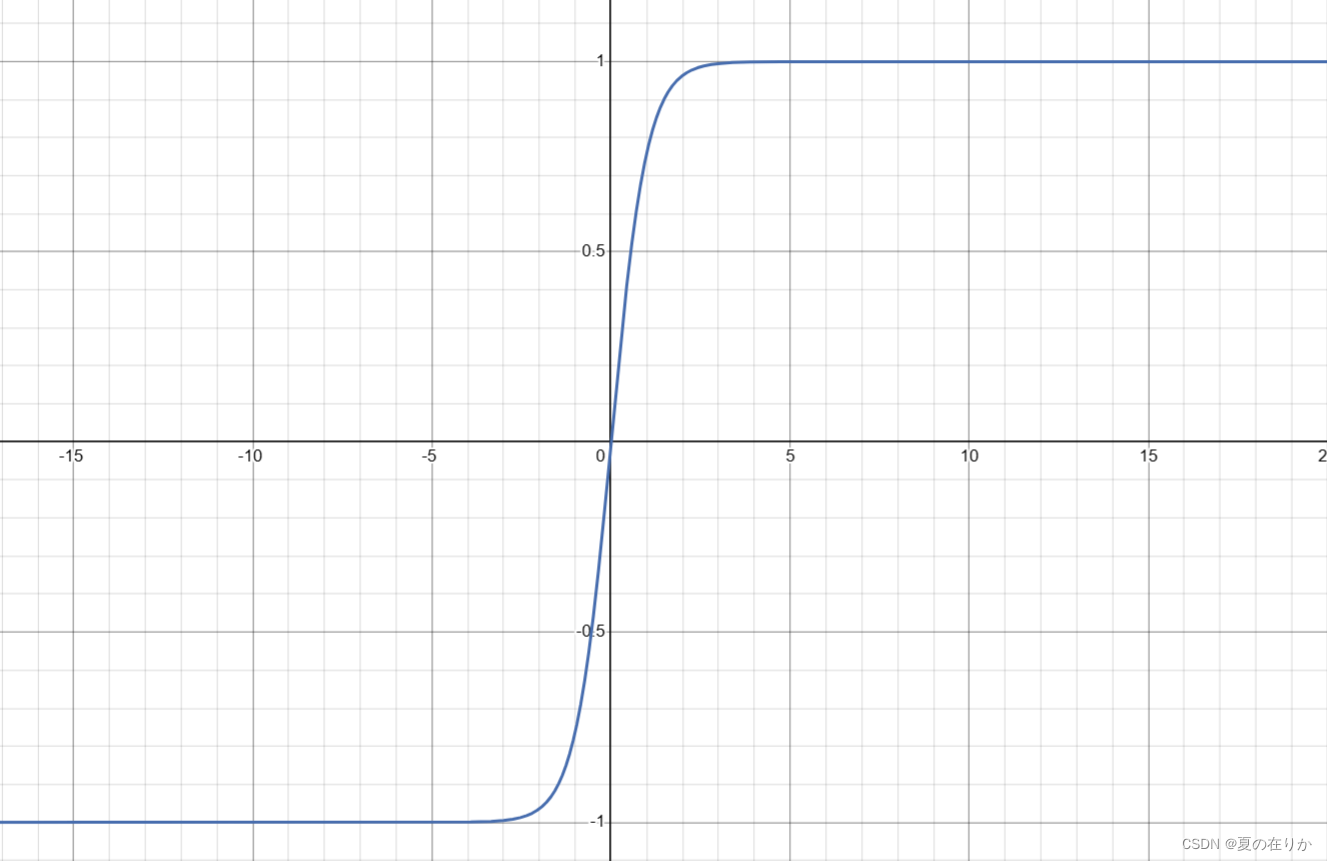
- 值得注意的是,线性回归是神经网络的算法基础。但是在神经网络的隐藏层的激活函数的选择上,我们往往不会选择sigmod函数,因为神经网络隐藏层的计算结果需要层层传递,均值是0.5对于数据逐层传递来说非常不适合计算,我们希望将输出的均值保持在0,
- 所以通常会将sigmod函数向下平移并经过原点,形成一个新的函数:
tanh函数:
g ( x ) = e z − e − z e z + e − z g(x)=\frac{{e}^{z}-e^{-z}}{{e}^{z}+{{e}^{-z}}} g(x)=ez+e−zez−e−z
- 而对于tanh函数和sigmod函数极值训练效果差的问题,也有人选择使用ReLU或LeakyReLU,这里就不重点介绍了
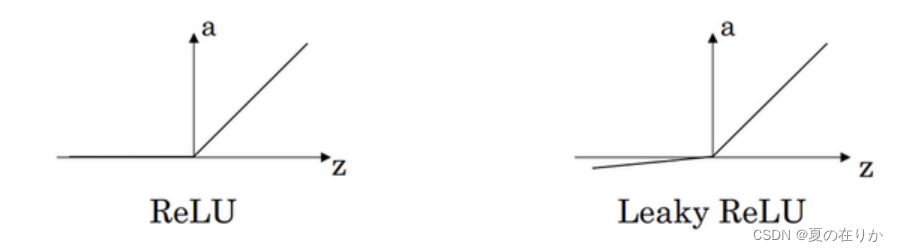
3.3 损失函数是什么,为什么这么设计
3.3.1 简介
- 定义
损失函数又叫做误差函数,用来衡量算法的运行情况。
我们通常用 L ( y ^ , y ) L(\hat{y}, y) L(y^,y)来表示损失函数。 y ^ \hat{y} y^:预测值, y y y:真实值。
损失函数用来衡量预测输出值和实际值有多接近。 - 公式
L ( y ^ , y ) = − y l o g ( y ^ ) − ( 1 − y ) l o g ( 1 − y ^ ) L(\hat{y},y) = -ylog(\hat{y})-(1-y)log(1-\hat{y}) L(y^,y)=−ylog(y^)−(1−y)log(1−y^)
3.3.2 为什么要用这个函数作为损失函数
- 在数学问题中,我们常常用方差或标准差来表示预测值和真实值的差异,但是在逻辑回归中并不合适。因为损失函的结果是为了更好的迭代,评估,找出模型最优参数。方差和标准差输出结果无固定区间,量化标准差,所以我们需要另外使用一个损失函数。
- 损失函数的设计之美:
- 当 y y y=1时,损失函数 L = − l o g ( y ^ ) L=-log(\hat{y}) L=−log(y^),而如果想要损失尽可能的小, y ^ \hat{y} y^就要尽可能的大,而由于sigmod函数的约束, y ^ \hat{y} y^在0到1之间,所以 y ^ \hat{y} y^就会无限接近于1。
- 当 y y y=0时,损失函数 L = − l o g ( 1 − y ^ ) L=-log(1-\hat{y}) L=−log(1−y^),而如果想要损失尽可能的大, y ^ \hat{y} y^就要尽可能的大,而由于sigmod函数的约束, y ^ \hat{y} y^在0到1之间,所以 y ^ \hat{y} y^就会无限接近于0。
- 总结: L ( y ^ , y ) L(\hat{y},y) L(y^,y) 函数在 y y y和 y ^ \hat{y} y^越接近的时候,值越小。也就是真实值和预测值越接近,损失函数值越小。
3.3.3 为什么这么设计损失函数
-
在逻辑回归中,我们用sigmod函数处理需要预测的结果 y ^ \hat{y} y^。
-
约定 y ^ = p ( y = 1 ∣ x ) \hat{y}=p(y=1|x) y^=p(y=1∣x):
y ^ \hat{y} y^表示,在给定的训练样本 x x x下, y = 1 y=1 y=1的概率。
回顾一下上面我们说到的,二分类问题的 y y y取值只能为0或1,所以我们来讨论一下这两种情况:-
y
=
1
y=1
y=1时,根据上面的约定,概率就是
y
^
\hat{y}
y^,即:
y = 1 y=1 y=1时: p ( y ∣ x ) = y ^ p(y|x)=\hat{y} p(y∣x)=y^ - 反过来
y
=
0
y=0
y=0时,概率就是
1
−
y
^
1-\hat{y}
1−y^,即:
y = 0 y=0 y=0时: p ( y ∣ x ) = 1 − y ^ p(y|x)=1-\hat{y} p(y∣x)=1−y^
这两个概率公式定义了 y = 1 y=1 y=1和 y = 0 y=0 y=0时的两种情况。我们将这两个公式合并成如下公式:
p ( y ∣ x ) = y ^ y ( 1 − y ^ ) 1 − y p(y|x)=\hat{y}^y(1-\hat{y})^{1-y} p(y∣x)=y^y(1−y^)1−y -
y
=
1
y=1
y=1时,根据上面的约定,概率就是
y
^
\hat{y}
y^,即:
-
为什么如此合并
上面的公式我们在合并的同时要保持他们的特性,即 y = 1 y=1 y=1时 p ( y ∣ x ) = y ^ p(y|x)=\hat{y} p(y∣x)=y^, y = 0 y=0 y=0时 p ( y ∣ x ) = 1 − y ^ p(y|x)=1-\hat{y} p(y∣x)=1−y^。- 当 y = 1 y=1 y=1时,我们想让 p ( y ∣ x ) = y ^ p(y|x)=\hat{y} p(y∣x)=y^,意味着合并 p ( y ∣ x ) = ( 1 − y ^ ) p(y|x)=(1-\hat{y}) p(y∣x)=(1−y^)这个公式时要使其等于1,因为 x 0 x^0 x0永远等于1,所以合并 ( 1 − y ^ ) (1-\hat{y}) (1−y^)时让其的指数位为0即可,并且在 y = 1 y=1 y=1时不能影响该公式,也就是指数位腰围1,所以合并 1 − y ^ 1-\hat{y} 1−y^的指数位为 1 − y 1-y 1−y,即第二个公式为 ( 1 − y ^ ) 1 − y (1-\hat{y})^{1-y} (1−y^)1−y
- 同理,当 y = 0 y=0 y=0时, p ( y ∣ x ) = 1 − y ^ p(y|x)=1-\hat{y} p(y∣x)=1−y^,所以第一个公式 p ( y ∣ x ) = y ^ p(y|x)=\hat{y} p(y∣x)=y^要变换使其等于1,且 y = 1 y=1 y=1时, y ^ \hat{y} y^要保持不变。所以 y ^ \hat{y} y^的指数位设置为 y y y,即第一个公式为 y ^ \hat{y} y^
- 合并得 p ( x ∣ y ) = y ^ y ( 1 − y ^ ) 1 − y p(x|y)=\hat{y}^y(1-\hat{y})^{1-y} p(x∣y)=y^y(1−y^)1−y
-
损失函数的优化
上面我们推导出损失函数的公式,但实际上往往不这么使用,我们将函数进行简化。两边同时取对数,对数函数单调递增,所以对于趋势没有影响,得到以下公式:
h ( x ) = l o g ( y ^ y ( 1 − y ^ ) 1 − y ) h ( x ) = y l o g y ^ + ( 1 − y ) l o g ( 1 − y ^ ) h(x)=log(\hat{y}^{y}(1-\hat{y})^{1-y}) \\ h(x)=ylog\hat{y}+(1-y)log(1-\hat{y}) h(x)=log(y^y(1−y^)1−y)h(x)=ylogy^+(1−y)log(1−y^)
还有一个问题,当我们将公式应用于训练学习时,期望算法输出的概率值越大越好,然而逻辑回归我们希望损失越小越好,也就是概率越大损失应当越小,两者负相关,所以损失函数要取负值。
L ( y ^ , y ) = − y l o g y ^ − ( 1 − y ) l o g ( 1 − y ^ ) L(\hat{y},y) = -ylog\hat{y}-(1-y)log(1-\hat{y}) L(y^,y)=−ylogy^−(1−y)log(1−y^)
而对于多个训练样本的损失函数,我们希望尽可能的让数值小一点好计算一点,所以对于有m个训练数据的样本,我们会加一个常数因子: 1 m \frac{1}{m} m1
最终得出多样本的损失函数:
J ( w , b ) = 1 m ∑ i = 1 m L ( y ^ ( i ) , y ( i ) ) = 1 m ∑ i = 1 m ( − y ( i ) log y ^ ( i ) − ( 1 − y ( i ) ) log ( 1 − y ^ ( i ) ) ) J\left( w,b \right)=\frac{1}{m}\sum\limits_{i=1}^{m}{L\left( {{{\hat{y}}}^{(i)}},{{y}^{(i)}} \right)}=\frac{1}{m}\sum\limits_{i=1}^{m}{\left( -{{y}^{(i)}}\log {{{\hat{y}}}^{(i)}}-(1-{{y}^{(i)}})\log (1-{{{\hat{y}}}^{(i)}}) \right)} J(w,b)=m1i=1∑mL(y^(i),y(i))=m1i=1∑m(−y(i)logy^(i)−(1−y(i))log(1−y^(i)))
w w w: 线性函数 w T + b w^T+b wT+b的w参数
b b b: 线性函数的b参数
i i i:当前的训练对象
m m m:训练样本数量
以上就是逻辑回归函数中的一些数学设计,此栏目会一直更新。觉得有用就点赞收藏吧














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









