







WAV2VEC: UNSUPERVISED PRE-TRAINING FOR SPEECH RECOGNITION
概要
本文使用大量的无标签数据集去预训练wav2vec模型,从而提升声学模型效果。本文训练的模型在性能上超越了Deep Speech 2,在nov92测试集上,WER达到了2.43%。
1 简介
预训练在深度学习算法中是一个很常用的方法,主要作用是能提升模型性能,即使是在当前带标签数据集的很少的情况下。主要方法是通过大量的无标签数据或者有标签的其他数据集对模型进行训练,可以使模型学习到通用的特征,然后再使用目标数据集对预训练后的模型进行训练,就可以再有限数据集的情况下,达到很好的效果。
这种方法在CV和NLP领域已经被大量的使用,在语音领域中,在情感识别,说话人识别和音素区分场景下用的比较多,但还没有用来提升语音识别的性能。
本文采用无监督的预训练方法来提升asr识别的性能,采用的是wav2vec模型,该模型是卷积神经网络模型,输入数据是音频的原始数据,然后计算出一系列特征,再使用该特征进行语音识别,使用contrastive loss作为损失函数。相较于序列模型,使用卷积模型好处是可以很容易的实现并行处理。
实验结果证明了在WSJ benchmark中,在使用1000小时的无标签数据集训练后,提高了asr系统的性能,相较于之前最好的Deep Speech 2,WER从3.1%下降到了2.43%。在TIMIT数据集上,仅仅使用8小时带标签的训练集,相对于基线模型,wav2vec将WER降低了36%。
2 预训练的方法
2.1 模型

作者共使用了两种网络接口,一个是encoder network,一个是context network。encoder network用来把音频信号转换到特征空间,context network将不同时间步的特征结合在一起,形成拥有上下文的特征。
Encoder network共有五层,每层的kernel size是(10,8,4,4,4),步长为(5,4,2,2,2),encoder对30ms的16k音频进行编码,输出结果为低频的特征,步长大约为10ms。
context network将不同时间步的encoder特征放到一个tensor中计算,共有九层,kernel size为3,步长为1,感受野总共大概210ms。
针对较大的数据集,作者还使用了一个wav2vec large的模型,在encoder network添加了两次线性变换,在context network添加了12层,并且扩大了kernel size。
2.2 目标函数
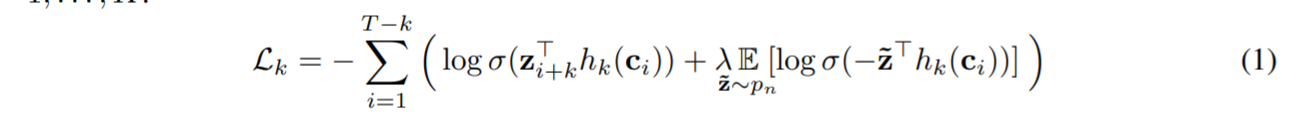
作者使用的损失函数如图, σ \sigma σ是sigmoid函数, σ ( z i + k T h k ( c i )
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2684
2684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









