






前言:在日常运维工作中,告警风暴总是作为一个不可忽视但又无法避免的问题摆在我们面前。为了尽可能缩短 MTTI 和 MTTR,我们不得不提升异常检测的灵敏度、压缩阈值的波动空间;而造成的后果就是大量的告警被触发,形成告警风暴。
告警风暴产生的原因
常见的有以下几种情况:
1、阈值设置不合理
往往表现在指标阈值设置缺乏个性化,对不同资源、服务设置同一套阈值;而不同服务和主机的运行情况、对资源的利用率要求常常是不一样的。例如:有些主机上跑着核心业务应用,内存使用率就普遍较高;而有些主机上运行的业务应用的访问量就很少,或者只有在特定时间段才有大量访问(如定时跑批的服务)。
2、异常瞬时值过多
当异常的瞬时值过多时,每一次检测到异常都会形成一条报警,这样告警的数量自然就变得很多。
3、比值(率)型指标分母过小
以请求失败率为例,当计算失败率的分母值也就是请求量过小时,每发生一次异常都会极大地改变失败率的数值。比如某 Web 接口 5 分钟内被请求了 1 次,失败 1 次,该接口 5 分钟的请求失败率就是 100%;在这种情况下,根据比值(率)型指标设置阈值就会变得很不合理,同时报警量激增。
4、点问题影响到面甚至波及多层级
主要有两类表现:
-
资源层面,如磁盘、内存出现破坏性异常导致上层应用服务出现大面积不可用报警;
-
调用链层面,当链路中的底层服务出现异常导致上层应用服务出现大面积指标报警。

Databuff如何抑制告警风暴
阈值设置不合理
1、动态基线
动态基线会根据指标历史数据的特性计算出一个合理的阈值:它能够依据正常情况下数据的变化走势自适应生成基线,作为异常检测的阈值;同时,Databuff的低成本存储能力和优秀的算法能力,能够放大动态基线的效果,支持为每一个指标的不同监控对象独立计算动态基线。动态基线检测配置页面如下所示:
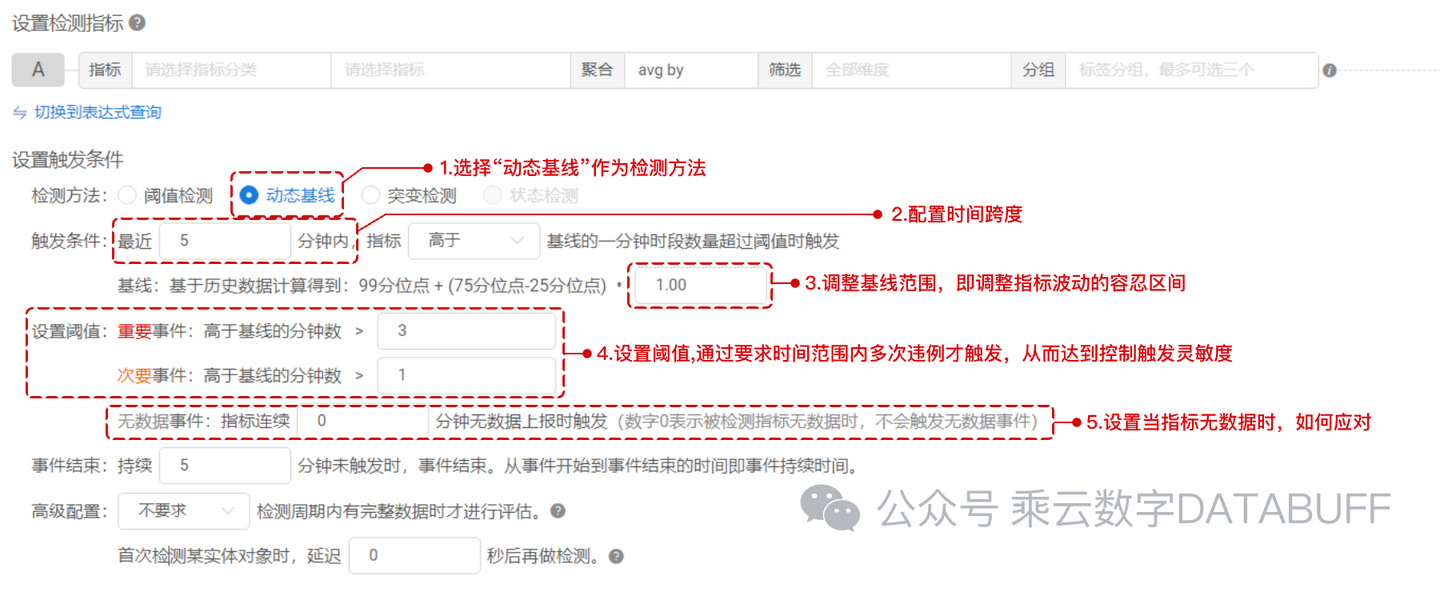
2、多指标综合判断
Databuff 支持同时对多个指标进行综合检测,使得异常的判断不再是对单一指标值的判断,而是将其场景化。这样能够根据不同场景的需求配置相对应的合适阈值、使用合适的检测方法。多指标检测的配置界面如下所示:
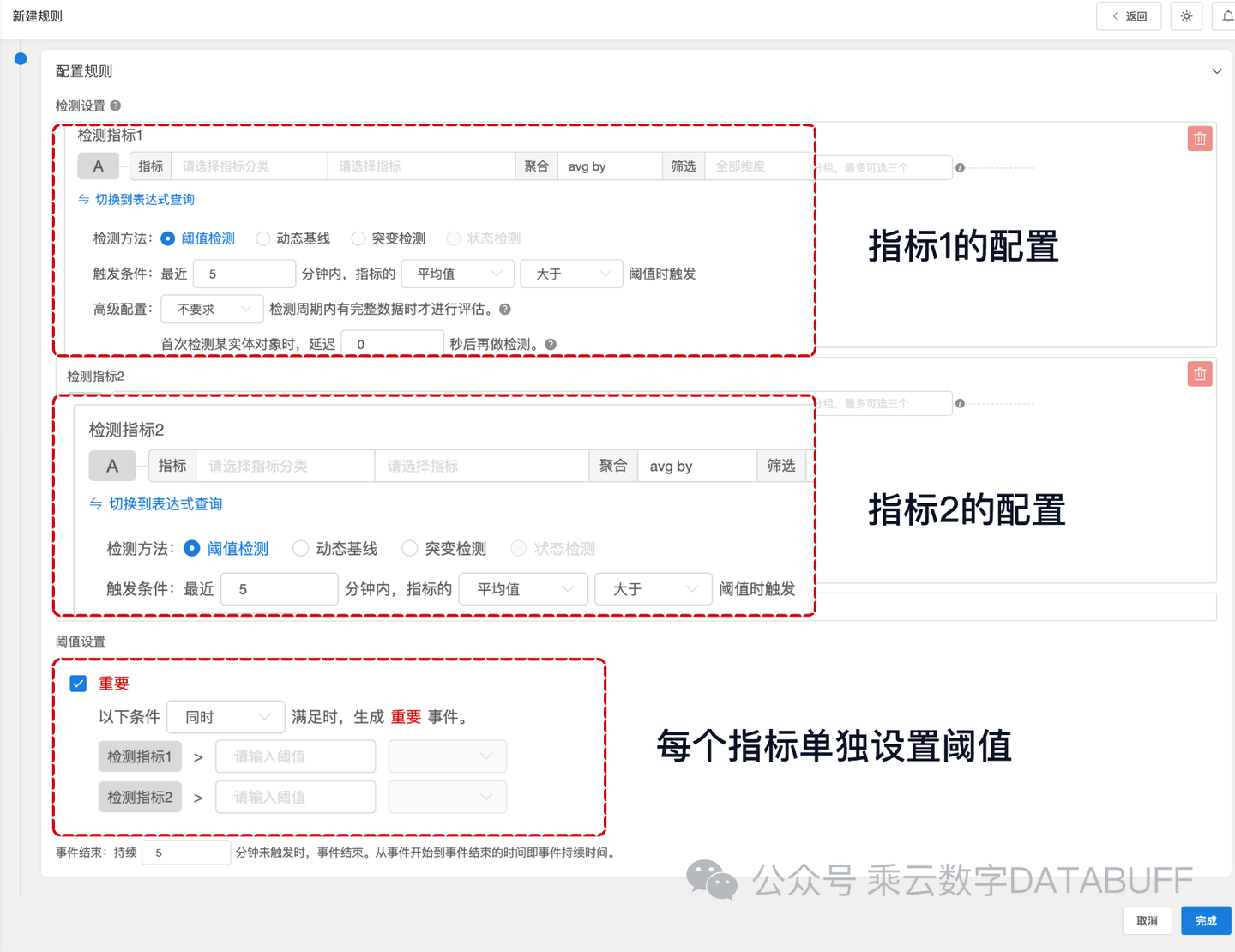
3、异常瞬时值过多
Databuff在进行单次异常检测时就考虑了异常瞬时值的问题,您可以通过配置限定范围内的异常值需达到一定频率/次数才会判断异常存在,从而可以有效忽略异常值波动带来的告警量激增问题。常常被用在CPU使用率异常检测这样易出现瞬时异常但可忽略的场景中。具体配置如下图所示:

您可以根据自身需求,对异常值出现的频率、连续性等做出要求,以减少非必要的报警。
4、比值(率)型指标分母过小
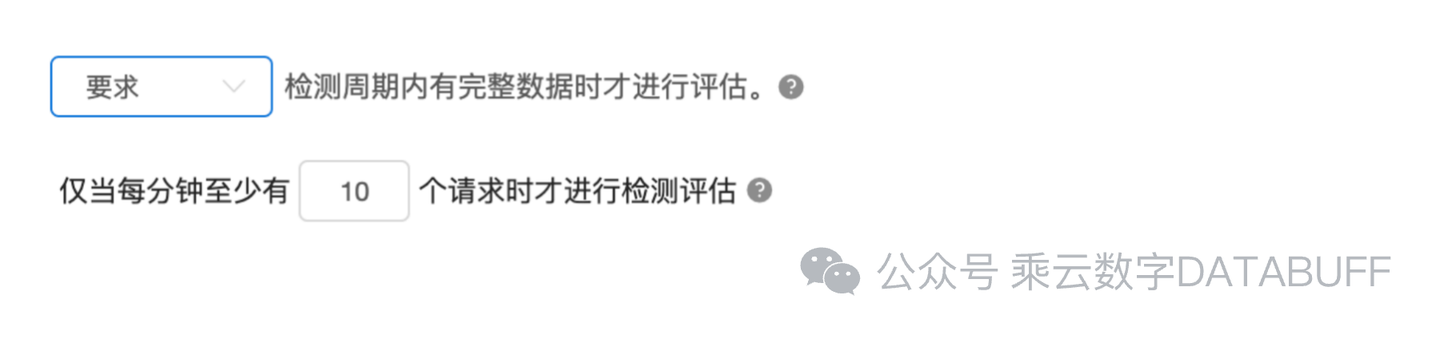
为有效排除此因素对报警的影响,Databuff支持在异常检测规则中配置如下几项:
-
是否要求检测周期内有完整数据
-
对于应用性能指标,设置每分钟的最少请求量来限制检测动作
配置界面如下图所示:
5、点问题影响到面甚至波及多层级
目前市面上很多传统做告警的厂家都考虑到了这一点,但效果都很有限。造成这种现状的关键在于,传统做告警的厂家的指标与实体之间、实体与实体之间的关系是割裂的,缺乏关联。只能通过数学模拟、以相似性作为因果关系、强制合并等方式来抑制报警。表现出来的方法有指标波动耦合、告警描述相似度计算、同时间段相同实体对象上发生的报警强制聚合等。
区别于上述方案,Databuff的策略是结合自身数据关联性强、拥有横向/纵向(从应用层到基础设施层)完整的访问依赖关系拓扑等特点和优势,结合AI算法,自动分析和推断异常发生的根因,找出问题发生的起始点。将根因报警以及受此根因影响引发的报警全部收敛在一起,大大提高了收敛的合理性、有效性、可解释性。
















 7782
7782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









