






对于学生成绩的影响因素分析是一项复杂而多样的研究。学生成绩的影响因素包括家庭环境、学习动机、学习方式、课外活动、学校教育资源等多个方面。在进行这项研究时,我们通常采用因素分析的方法。因素分析是一种用于识别和解释多个变量之间关系的统计方法,可帮助我们了解学生成绩各方面的影响因素并进行量化分析。
第一部分:引言
1. 研究背景
在这部分,我们将简要介绍学生成绩的重要性以及研究该主题的动机和意义。学生成绩不仅影响个人未来的发展,也反映了教育体系的效果和社会整体素质的水平。因此,对学生成绩的影响因素进行深入研究具有重要的现实意义。
2. 研究目的
这一部分将阐明我们的研究目的,明确我们希望揭示学生成绩的影响因素,为学生学习和发展提供科学依据,以及推动教育改革的迫切需求。
第二部分:文献综述
1. 家庭环境对学生成绩的影响
我们将阐述家庭背景、父母文化素养、经济状况等因素对学生成绩的影响,并总结前人的研究成果以及不同观点之间的争议。
2. 学习动机和学习方式
这一部分将对学习动机、学习方法对学生成绩的影响进行深入分析,如内在动机和外在动机的作用,不同学习方式对学生成绩的影响程度等。
3. 课外活动与学生成绩
我们将探讨学生参与课外活动对学习的促进效果,以及不同类型课外活动对学生成绩的差异影响。
4. 学校教育资源对学生成绩的影响
在这一部分,我们将详细阐述不同学校教育资源对学生成绩的影响,如师资力量、教材资源、校园环境等。
第三部分:研究设计
1. 研究方法
我们将介绍采用的研究方法,如问卷调查、访谈、实地观察等,以及对样本的选择和研究工具的设计。
2. 数据分析
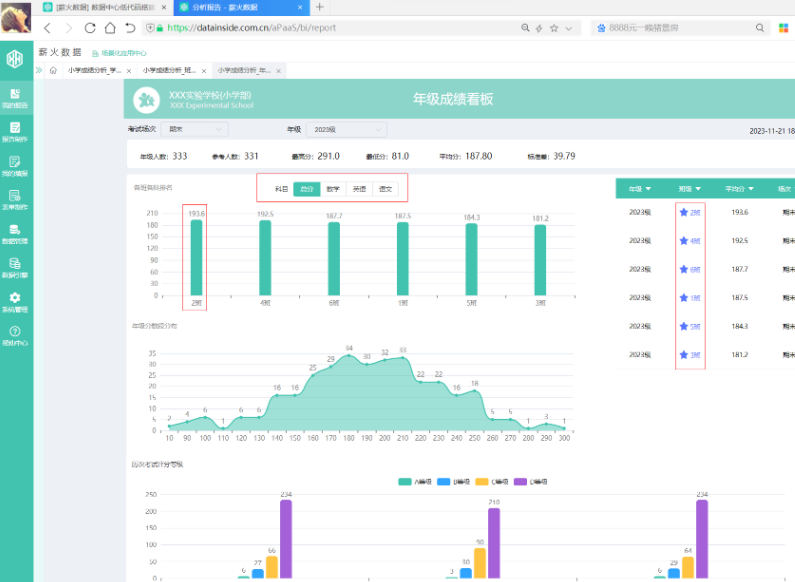
我们将详细描述采用的数据分析方法,包括统计软件的选择、变量分析、因素分析等。分析我们一般采用表格或者软件,我们学校采用的是薪火数据学生成绩分析系统,效果比较好用。分析也到位。
第四部分:实证分析
1. 数据收集与处理
我们将描述数据的收集过程,数据的详细情况以及数据的处理方法。
2. 因素分析结果
在这一部分,我们将详细呈现因素分析的结果,包括各因素的权重和对学生成绩的影响程度。
3. 深入讨论
我们将对分析结果进行深入讨论,并探讨不同因素之间的相互关系、内在机制等。
第五部分:结论与展望
1. 结论总结
在这一部分,我们将总结研究的主要发现,并得出对学生成绩影响因素的结论。
2. 对教育实践的启示
我们将探讨研究结果对教育实践的启示和指导意义,以及可能的政策建议。
结尾
在结尾部分,我们将对整个研究进行总结,并提出未来研究的展望。
通过这篇论文,我们将深入探讨学生成绩的多方面影响因素,并为教育实践提供科学依据,以促进学生成长与发展。

















 2263
2263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









