







在使用Lire实现图片检索功能比较简单,主要分为两步,第一步创建索引,第二步索引检索
一、创建索引
创建索引主要是使用DocumentBuilderFactory 创建 DocumentBuilder,例如DocumentBuilderFactory.getCEDDDocumentBuilder().
将图片加入索引index 需要以下2步:
使用 DocumentBuilder 创建Document:builder.createDocument(FileInputStream, String).(第一个参数是图片文件)
将document 加入 index.
Document就是lucene中的文档,它建立的文档包含了图像的某个特征和图像的标识字符串两个Field。通过调用createDocument就能返回每个图像对应特征和标识的文档,用lucene的IndexWriter就能将它写入索引文件。
LIRE支持很多种的特征值。具体可以看 DocumentBuilderFactory 类的源代码。也可以使用 ChainedDocumentBuilder 同时使用多种特征值。
创建索引的方法如下代码所示
/**
* Simple index creation with Lire
*
* @author Mathias Lux, mathias@juggle.at
*/
public class Indexer {
public static void main(String[] args) throws IOException {
// Checking if arg[0] is there and if it is a directory.
boolean passed = false;
if (args.length > 0) {
File f = new File(args[0]);
System.out.println("Indexing images in " + args[0]);
if (f.exists() && f.isDirectory()) passed = true;
}
if (!passed) {
System.out.println("No directory given as first argument.");
System.out.println("Run \"Indexer <directory>\" to index files of a directory.");
System.exit(1);
}
// Getting all images from a directory and its sub directories.
ArrayList<String> images = FileUtils.getAllImages(new File(args[0]), true);
// Creating a CEDD document builder and indexing al files.
DocumentBuilder builder = DocumentBuilderFactory.getCEDDDocumentBuilder();
// Creating an Lucene IndexWriter
IndexWriterConfig conf = new IndexWriterConfig(LuceneUtils.LUCENE_VERSION,
new WhitespaceAnalyzer(LuceneUtils.LUCENE_VERSION));
IndexWriter iw = new IndexWriter(FSDirectory.open(new File("index")), conf);
// Iterating through images building the low level features
for (Iterator<String> it = images.iterator(); it.hasNext(); ) {
String imageFilePath = it.next();
System.out.println("Indexing " + imageFilePath);
try {
BufferedImage img = ImageIO.read(new FileInputStream(imageFilePath));
Document document = builder.createDocument(img, imageFilePath);
iw.addDocument(document);
} catch (Exception e) {
System.err.println("Error reading image or indexing it.");
e.printStackTrace();
}
}
// closing the IndexWriter
iw.close();
System.out.println("Finished indexing.");
}
}二、索引检索
检索用的接口类ImageSearcherFactory实现检索功能,提供了很多的检索方式,其中常用的createDefaultSearcher。Searcher搜索结果返回的是ImageSearchHits,它就是ArrayList results结果集,根据图片的相似度由高到低的一个集合。
/**
* Simple image retrieval with Lire
* @author Mathias Lux, mathias <at> juggle <dot> at
*/
public class Searcher {
public static void main(String[] args) throws IOException {
// Checking if arg[0] is there and if it is an image.
BufferedImage img = null;
boolean passed = false;
if (args.length > 0) {
File f = new File(args[0]);
if (f.exists()) {
try {
img = ImageIO.read(f);
passed = true;
} catch (IOException e) {
e.printStackTrace();
}
}
}
if (!passed) {
System.out.println("No image given as first argument.");
System.out.println("Run \"Searcher <query image>\" to search for <query image>.");
System.exit(1);
}
IndexReader ir = DirectoryReader.open(FSDirectory.open(new File("index")));
ImageSearcher searcher = ImageSearcherFactory.createCEDDImageSearcher(10);
ImageSearchHits hits = searcher.search(img, ir);
for (int i = 0; i < hits.length(); i++) {
String fileName = hits.doc(i).getValues(DocumentBuilder.FIELD_NAME_IDENTIFIER)[0];
System.out.println(hits.score(i) + ": \t" + fileName);
}
}
} 新建一个web project,工程名为LireDemo,项目结构如图所示;
TestImageSearch.java
package com.lire.demo;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.FileInputStream;
import javax.imageio.ImageIO;
import net.semanticmetadata.lire.DocumentBuilder;
import net.semanticmetadata.lire.DocumentBuilderFactory;
import net.semanticmetadata.lire.ImageDuplicates;
import net.semanticmetadata.lire.ImageSearchHits;
import net.semanticmetadata.lire.ImageSearcher;
import net.semanticmetadata.lire.ImageSearcherFactory;
import org.apache.lucene.analysis.SimpleAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class TestImageSearch {
private static String INDEX_PATH = "F:\\LireImageSearch\\index";// 索引文件存放路径
private static String INDEX_FILE_PATH = "F:\\LireImageSearch\\images"; //要索引的图片文件目录
private static String SEARCH_FILE = "F:\\LireImageSearch\\testImg\\1000.jpg";//用于搜索的图片
public void createIndex() throws Exception {
//创建一个合适的文件生成器,Lire针对图像的多种属性有不同的生成器
DocumentBuilder db = DocumentBuilderFactory.getCEDDDocumentBuilder();
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_33, new SimpleAnalyzer(Version.LUCENE_33));
IndexWriter iw = new IndexWriter(FSDirectory.open(new File(INDEX_PATH)), iwc);
File parent = new File(INDEX_FILE_PATH);
for (File f : parent.listFiles()) {
// 创建Lucene索引
Document doc = db.createDocument(new FileInputStream(f), f.getName());
// 将文件加入索引
iw.addDocument(doc);
}
iw.optimize();
iw.close();
}
public void searchSimilar() throws Exception {
IndexReader ir = IndexReader.open(FSDirectory.open(new File(INDEX_PATH)));//打开索引
ImageSearcher is = ImageSearcherFactory.createDefaultSearcher();//创建一个图片搜索器
FileInputStream fis = new FileInputStream(SEARCH_FILE);//搜索图片源
BufferedImage bi = ImageIO.read(fis);
ImageSearchHits ish = is.search(bi, ir);//根据上面提供的图片搜索相似的图片
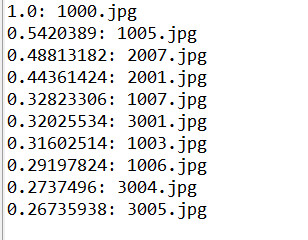
for (int i = 0; i < 10; i++) {//显示前10条记录(根据匹配度排序)
System.out.println(ish.score(i) + ": " + ish.doc(i).getFieldable(DocumentBuilder.FIELD_NAME_IDENTIFIER).stringValue());
}
}
//测试前先将包含重复图片的文件进行索引
public void searchDuplicates() throws Exception {
IndexReader ir = IndexReader.open(FSDirectory.open(new File(INDEX_PATH)));
ImageSearcher is = ImageSearcherFactory.createDefaultSearcher();
ImageDuplicates id = is.findDuplicates(ir);//查找重复的图片,如果没有,则返回null
for (int i = 0; id != null && i < id.length(); i++) {
System.out.println(id.getDuplicate(i).toString());
}
}
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
TestImageSearch ts = new TestImageSearch();
try {
ts.createIndex();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
ts.searchSimilar();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











