






 AniPortrait通过Audio2Lmk提取音频特征并生成3D人脸网格和姿态序列,Lmk2Video利用扩散模型结合参考图像生成逼真动画。研究强调了重新设计的姿态引导模块和对嘴部运动的增强。尽管有进展,但模型仍受限于中间三维表示和可能存在的时序一致性问题。
AniPortrait通过Audio2Lmk提取音频特征并生成3D人脸网格和姿态序列,Lmk2Video利用扩散模型结合参考图像生成逼真动画。研究强调了重新设计的姿态引导模块和对嘴部运动的增强。尽管有进展,但模型仍受限于中间三维表示和可能存在的时序一致性问题。
代码地址:https://github.com/Zejun-Yang/AniPortrait
论文地址:https://arxiv.org/abs/2403.17694
摘要
提供一段音频和参考图像,AniPortrait可以生成一段高质量的人物说话视频。
AniPortrait分为两个不同的阶段:
- Audio2Lmk:使用基于transformer的模型,从输入音频来提取一段3D脸部网格和头部姿态的序列,然后将这一序列投影成一串2D脸部landmark点序列。这一阶段可以捕获精细的表情和嘴部运动,以及与音频节奏同步的头部动作。
- Lmk2Video:使用了一个包含运动模块的扩散模型,将脸部landmark点序列转换为一个时序一致且逼真的动画肖像。(在网络结构上借鉴了AnimateAnyone)。
特别指出的,是该工作在网络中重新设计了姿态引导模块,这一设计既保持了轻量化的设计,而且在产生唇部运动时也展示出更高的精度。
方法
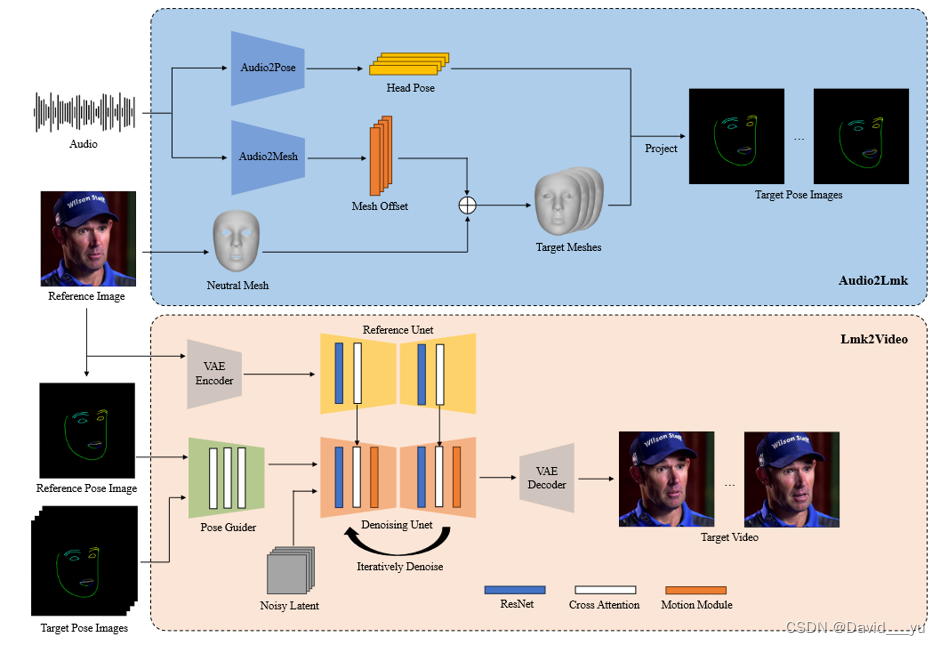
该框架包含两个阶段:Audio2Lmk和Lmk2Video,第一阶段从给定的音频输入提取得到一系列表征人脸表情和嘴部运动的landmark序列,第二阶段使用这一landmark序列来生成高质量、时序稳定的人物视频。
- Audio2Lmk:输入一段音频片段,该模块会预测相应的3D人脸网格序列和姿态序列,其中姿态序列是6维度的向量表征旋转与偏移。
- 使用预训练的Wav2vec 2.0模型来提取音频特征,之所以使用该模型是因为Wav2vec可以准确识别语音和语调,这对于生成逼真的面部运动至关重要。由于使用了改种高效的提取方式,后面作者只设计了一个包含两层全连接网络的简单结构,来将这些特征转换为对应的3D人脸网格。(作者认为这一设计不仅保证了准确性同时提高了推理时的效率)。
- 将语音转换成头部姿态的任务也同样使用wav2vec作为主干网络,但是却没有和前面的语音到人脸网格的网络共享权重,这是基于一个事实,即头部运动与音频的节奏和语调联系更紧密。为考虑先前状态的影响,作者使用了transformer解码器来生成动作序列,将音频特征通过交叉注意力机制集成到解码器中。
- 这个阶段中的两个部分都是用了L1 loss进行监督训练。
- Lmk2Video:给定一张参考人脸,以及一系列的人脸landmark点,该模块会生成一个时序一致的人脸动画。该动画在运动上与landmark序列对齐,在外观上与参考人脸保持一致。
- 该模块的网络设计参考了阿里的工作AnimateAnyone,使用SD1.5作为主干,插入时序模块来讲多帧噪声转换为一系列的视频帧。同时使用一个RenferenceNet(结构上和SD1.5的Unet主干相同),用来提取参考图像的外观信息,并将其集成进主干中。这一结构保证了输出视频中的脸部ID信息保持一致。
- 与AnimateAnyone不同的是,作者重新设计了一个更加复杂的PoseGuider,原始的设计中只插入了一些简单的卷积层,在经过这些层之后landmark信息与lantents在主干网络输入层的位置相融合。作者发现这一设计在捕捉嘴唇部分的复杂运动时是不够的,因此作者采用了ControlNet中的多尺度策略,将相应尺度的landmark特征整合到主干中的不同块中。尽管做了这些增强,但还是整体上保持了相对较低的参数设计。
- 作者还引入了一个额外的提升,将参考图的landmark作为额外的输入。PoseGuider中的交叉注意力模块促进了参考帧landmark和每一目标帧landmark之间的交互,这一过程为网络提供了额外的线索来理解面部标志与外观之间的相关性,从而帮助生成更精确运动的脸部动画。
实验
在Audio2Lmk阶段,使用Wav2Vec2.0作为backbone。使用MediaPipe来提取3D网格和6D姿态用于信息标注。
- Audio2Mesh的训练数据来自于作者团队的内部数据集,包含单个演讲者一个小时的高质量语音数据。为了保证MediaPipe提取的3D网格的稳定性,作者在采集数据时指导表演者在整个录制过程中保持稳定的头部位置,面对摄像机;
- Audio2Pose采用了HDTF数据集;
所有的训练过程都在单张A100上进行,采用1e-5的学习率,采用Adam优化器。
在Lmk2Video阶段,采用了两步训练策略。
- 在初始训练阶段只训练不包含时序模块的部分;
- 在后续阶段固定初始阶段训练的模块只训练运动模块。
训练中使用了两个大规模高质量的脸部视频数据集VFHQ和CelebV-HQ,所有的数据都是用MediaPipe来提取2D脸部landmark点。
为了增强网络对于嘴部运动的敏感性,在绘制2D landmark姿态图时,用不同的颜色区分上下唇。
所有的图片都被resize到512x512的大小,采用4张A100 GPU用于模型训练,两步训练都分别用了两天,训练中使用AdamW优化器,以及一个恒定的学习率,1e-5。
结论
该研究提出了一种基于扩散模型的人脸动画生成框架。通过简单的输入音频片段和参考图像,该框架能够生成具有平滑嘴部运动和自然头部运动的人脸视频。利用扩散模型的强大泛化能力,该框架创建的动画显示出令人印象深刻的逼真图像质量和运动。然而,这种方法需要使用中间的三维表示,并且获得大规模、高质量三维数据的成本相当高,因此生成的人像视频中面部表情和头部姿态都无法避免恐怖谷效应。作者后续打算遵循阿里EMO的工作,抛弃中间表征形式,直接从音频预测人脸视频,以获得更好的效果。
点评
作者在结论中还是很诚恳的指出了该框架的缺点,引入landmark作为中间表征增强了对于扩散模型生成的引导控制能力,但其表达的能力能被限制在中间表征形式的能力上,有利有弊吧。
查看开源的代码部分,其借鉴了Moore开源的AnimateAnyone实现,放出的结果基本上符合预期,尽管人物的运动、表情看起来是连续的,但是生成的视频上可以看到存在一种噪声,在一些纯色的背景上尤为明显,似乎该框架在时序一致性上还存在问题?究竟是数据的问题,还是方法的问题,这还有待进一步探究。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









