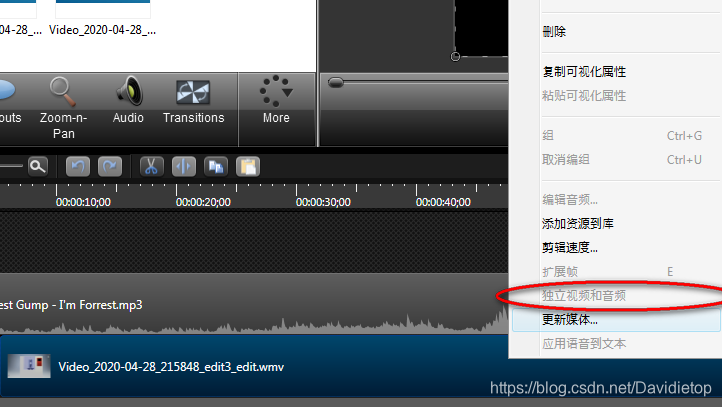
网上已经很多这种教程了,这里小虎分享自己做项目展示剪辑视频的一些使用过程,以备自己以后再用。 步骤过程 导入素材删除原视频音频音频长度控制音视频结合导出保存 导入素材 删除原视频音频 独立后再删除。 音频长度控制 控制时间轴到需要剪接部分,右键编辑音频,然后分割,不需要的部分就可以独立删除啦。 音视频结合 一般比较简单两个轨道就可以了,一条音频、一条视频,长度的话小虎是根据视频长度剪切音频长度的。 导出保存










 本文分享了项目展示剪辑视频的实用技巧,包括素材导入、音频处理、音视频结合及导出保存等关键步骤,适合初学者快速掌握视频剪辑流程。
本文分享了项目展示剪辑视频的实用技巧,包括素材导入、音频处理、音视频结合及导出保存等关键步骤,适合初学者快速掌握视频剪辑流程。





















 658
658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






