







二叉树的线索化
以二叉链表作为存储结构时,只能找到结点的左、右孩子信息,而不能直 接得到结点在任一序列(先序、中序或后序序列)中的前
驱
和后继信息,这
种信息只有在遍历的动态过程中才能得到。为了保存这种在遍历过程中得到的信息,我们利用二叉树表中的空树
域
(
由于结点没有左子树或右子树),
来存放结点的前驱和后继信息。
通俗一点来说,就是为了方便遍历而形成的,其实我们更多的是学习线索化的构建思想,看似简单的将空树域的的左孩子指针和右
孩
子指针改成指向该
种遍历方式中的该节点的前驱结点和后驱结点,其实实际实现的时候可能就会出现各种各样的问题,
我随便画
一个树。
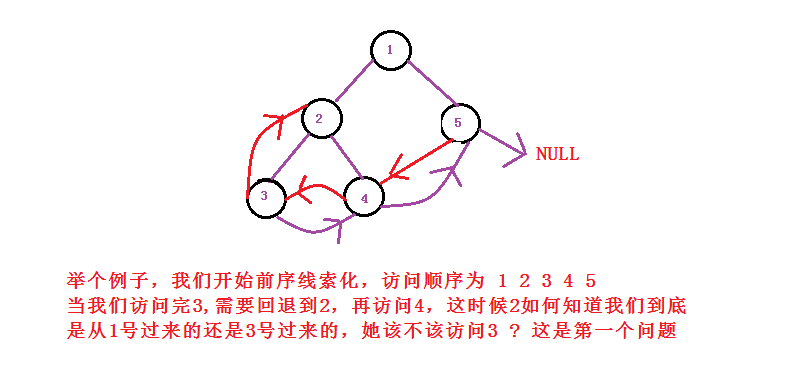
这个问题我们可以通过,在结点里面添加成员,用来判断和记录该结点是否被线索化过。
enum PointerType //枚举类型
{
THREAD, //已线索化的
LINK //连接节点,未线索化.
};
template<class T>
struct BinaryTreeNodeThd
{
BinaryTreeNodeThd<T>* _letf;
BinaryTreeNodeThd<T>* _right;
T _data;
PointerType _leftType;
PointerType _rightType;
BinaryTreeNodeThd(const T& x)
:_data(x)
, _letf(NULL)
, _right(NULL)
, _leftType(LINK)
, _rightType(LINK)
{}
};
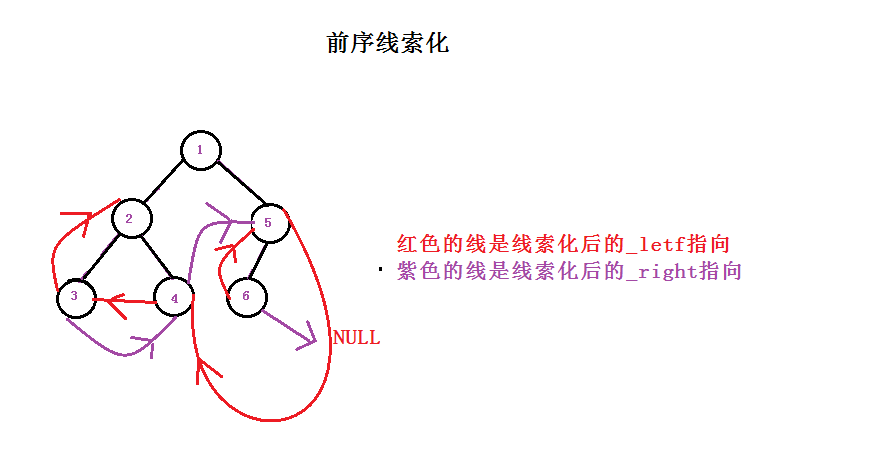
前序线索化
好的我们开始思考,前序线索化有一个小问题,就是当你访问到一个需要线索化的结点,你怎么知道它将要指向哪里? 它的下一个结点是谁?
我现在怎
么会知道下一刻我发生什么?这个问题该如何解决呢? 来集中精力! 开始穿越剧.
我们唯一的办法就是带你去未来,让你知道你下一步应该做什么,所以这里我们不得不创建一个参数,用来传递上一个结点,我把上一个结点带到我这
里来,然后我让他需要线索化的地方指向我,而且我需要线索化的地方正好可以指向它(寻找
前驱结点)。 这样就完美的解决掉这个问题.
所以我们添加一个_prev参数用来记录上一个节点的地址,让我们可以访问并操作它。(注意,这里必须_prev的引用,要不然在函数
里面操作无效)
具体的代码:
//重要的事情说3遍,这里的Node* & 必须加上引用,要不然上层对prev的修改就是没有意义的.
//重要的事情说3遍,这里的Node* & 必须加上引用,要不然上层对prev的修改就是没有意义的.
//重要的事情说3遍,这里的Node* & 必须加上引用,要不然上层对prev的修改就是没有意义的.
//MD害老子调半天
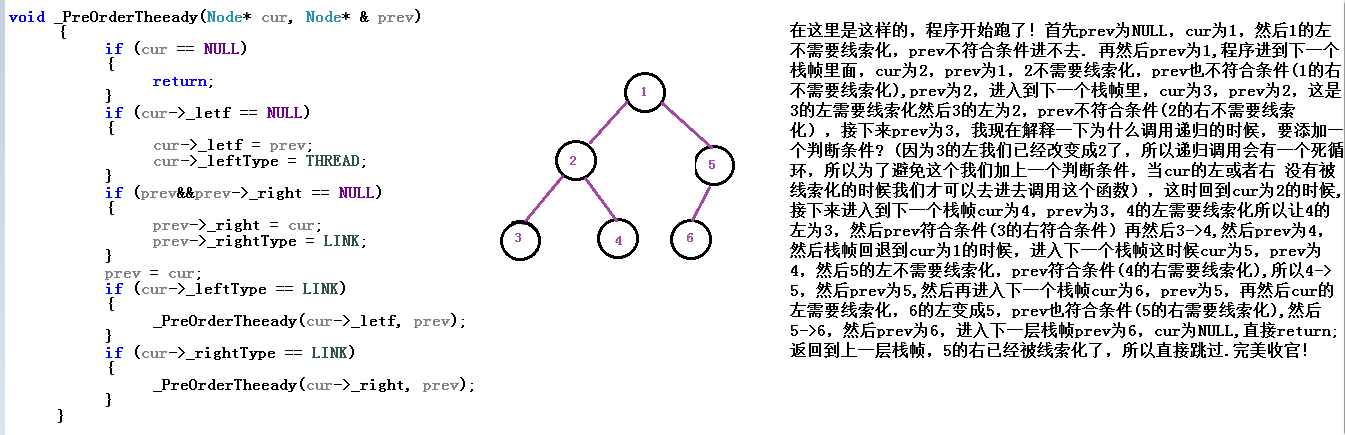
void _PreOrderTheeady(Node* cur, Node* & prev)
{
if (cur == NULL)
{
return;
}
//如果是空树链,它的线索化_left指向上一个结点,并标记。
if (cur->_letf == NULL)
{
cur->_letf = prev;
cur->_leftType = THREAD;
}
//如果是空树链,上一个结点的线索化_right指向我,并标记。
if (prev&&prev->_right == NULL)
{
prev->_right = cur;
prev->_rightType = THREAD;
}
prev = cur;
//if里的条件 防止重复访问结点
if (cur->_leftType == LINK)
{
_PreOrderTheeady(cur->_letf, prev);
}
//if里的条件 防止重复访问结点
if (cur->_rightType == LINK)
{
_PreOrderTheeady(cur->_right, prev);
}
}
这个过程画图不好描述,大家只能参照一棵树自己走一走,体会一下为什么里面会有这多的判断条件。
线索化后的结果:
中序线索化
其实意思跟前序线索化很相似,只是有的地方顺序换了一下而已。
我们来看具体的代码实现:
//中序线索化
void _InOrderThreading(Node* cur,Node* & prev)
{
if (cur)
{
_InOrderThreading(cur->_letf, prev);
//如果是空树链,它的线索化_left指向上一个结点,并标记。
if (cur->_letf == NULL)
{
cur->_letf = prev;
cur->_leftType = THREAD;
}
//如果是空树链,上一个结点的线索化_right指向我,并标记。
if (prev&&prev->_right == NULL)
{
prev->_right = cur;
prev->_rightType = THREAD;
}
prev = cur;
_InOrderThreading(cur->_right, prev);
}
}
如果你看懂了前序线索化,那么中序我相信你都可以直接写出来了.

我们来看看效果:

后序线索化
这里是有难度的以后补充吧...
线索化的遍历:
现在线索化的实现我们已经完成了,接下来我们遍历出结果看一看,那么我们就需要实现前序遍历的函数,和中序遍历的函数,记
好的我们从前序开始:如果你认为跟数组遍历一样,那就翻车了,因为这里的指向有点混乱如果单纯地_right的往后走很容易出错
前序遍历的实现代码:
//前序线索化遍历
void prevOrder()
{
Node* cur = _root;
while (cur)
{
//找到最左结点
while (cur->_leftType == LINK)
{
cout << cur->_data << " ";
cur = cur->_letf;
}
cout << cur->_data << " ";
cur = cur->_right;
}
}再来看看中序遍历的实现代码:
//针对中序线索化以后的遍历
void inorderThd()
{
Node* cur = _root;
while (cur)
{
//找到最左结点,开始遍历.
while (cur->_leftType == LINK)
{
cur = cur->_letf;
}
cout << cur->_data << " ";
//原始版本,放在这里有助于理解
/*if (cur->_rightType == LINK)
{
cur = cur->_right;
}
else
{
while (cur->_rightType == THREAD)
{
cur = cur->_right;
cout << cur->_data << " ";
}
cur = cur->_right;
}*/
//****优化后****
while (cur->_rightType == THREAD)
{
cur = cur->_right;
cout << cur->_data << " ";
}
cur = cur->_right;
}
}为什么中序遍历为什么会多几句判断条件,大家自己走一遍过程,就会理解到了呢。
具体这里最后为什么是while(cur->_rightType == THREAD)而不是if()呢?
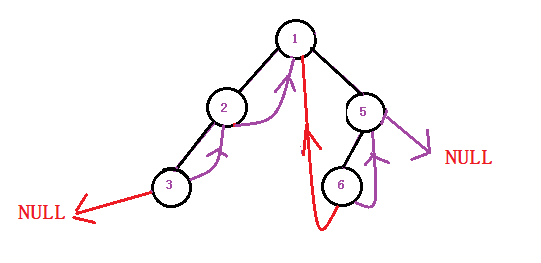
当二叉树为这样的时候,你觉得使用if()合适吗?
这里如果用if()会造成数据遍历缺失.
线索化全部代码实现与测试:
#include<iostream>
#include<Windows.h>
using namespace std;
enum PointerType //枚举类型
{
THREAD, //已线索化的
LINK //连接节点,未线索化.
};
template<class T>
struct BinaryTreeNodeThd
{
BinaryTreeNodeThd<T>* _letf;
BinaryTreeNodeThd<T>* _right;
T _data;
PointerType _leftType;
PointerType _rightType;
BinaryTreeNodeThd(const T& x)
:_data(x)
, _letf(NULL)
, _right(NULL)
, _leftType(LINK)
, _rightType(LINK)
{}
};
template<class T>
class BinaryTreeThd
{
typedef BinaryTreeNodeThd<T> Node;
public:
BinaryTreeThd(T* a, size_t n, const T& invalid)
{
size_t index = 0;
_root = CreateTree(a, n, invalid, index);
}
void InOrderThreading()
{
Node* prev = NULL;
_InOrderThreading(_root, prev);
}
void PreOrderTheeady()
{
Node* prev = NULL;
_PreOrderTheeady(_root, prev);
}
//前序线索化遍历
void prevOrder()
{
Node* cur = _root;
while (cur)
{
//找到最左结点
while (cur->_leftType == LINK)
{
cout << cur->_data << " ";
cur = cur->_letf;
}
cout << cur->_data << " ";
cur = cur->_right;
}
}
/*if (cur->_leftType == THREAD || cur->_rightType == THREAD)
{
cout << cur->_data << " ";
cur = cur->_right;
}*/
//针对中序线索化以后的遍历
void inorderThd()
{
Node* cur = _root;
while (cur)
{
//找到最左结点,开始遍历.
while (cur->_leftType == LINK)
{
cur = cur->_letf;
}
cout << cur->_data << " ";
//原始版本,放在这里有助于理解
/*if (cur->_rightType == LINK)
{
cur = cur->_right;
}
else
{
while (cur->_rightType == THREAD)
{
cur = cur->_right;
cout << cur->_data << " ";
}
cur = cur->_right;
}*/
//****优化后****
while (cur->_rightType == THREAD)
{
cur = cur->_right;
cout << cur->_data << " ";
}
cur = cur->_right;
}
}
protected:
//中序线索化
void _InOrderThreading(Node* cur,Node* & prev)
{
if (cur)
{
_InOrderThreading(cur->_letf, prev);
//如果是空树链,它的线索化_left指向上一个结点,并标记。
if (cur->_letf == NULL)
{
cur->_letf = prev;
cur->_leftType = THREAD;
}
//如果是空树链,上一个结点的线索化_right指向我,并标记。
if (prev&&prev->_right == NULL)
{
prev->_right = cur;
prev->_rightType = THREAD;
}
prev = cur;
_InOrderThreading(cur->_right, prev);
}
}
//重要的事情说3遍,这里的Node* & 必须加上引用,要不然上层对prev的修改就是没有意义的.
//重要的事情说3遍,这里的Node* & 必须加上引用,要不然上层对prev的修改就是没有意义的.
//重要的事情说3遍,这里的Node* & 必须加上引用,要不然上层对prev的修改就是没有意义的.
//MD害老子调半天
void _PreOrderTheeady(Node* cur, Node* & prev)
{
if (cur == NULL)
{
return;
}
//如果是空树链,它的线索化_left指向上一个结点,并标记。
if (cur->_letf == NULL)
{
cur->_letf = prev;
cur->_leftType = THREAD;
}
//如果是空树链,上一个结点的线索化_right指向我,并标记。
if (prev&&prev->_right == NULL)
{
prev->_right = cur;
prev->_rightType = THREAD;
}
prev = cur;
//if里的条件 防止重复访问结点
if (cur->_leftType == LINK)
{
_PreOrderTheeady(cur->_letf, prev);
}
//if里的条件 防止重复访问结点
if (cur->_rightType == LINK)
{
_PreOrderTheeady(cur->_right, prev);
}
}
//注意这里的index 要使用引用, 若是没有使用 上一层递归里面的++index 对上一层没有任何影响.
//构建二叉树表
Node* CreateTree(T* a, size_t n, const T& invalid, size_t& index)
{
Node* root = NULL;
if (index < n && a[index] != invalid)
{
root = new Node(a[index]);
root->_letf = CreateTree(a, n, invalid, ++index);
root->_right = CreateTree(a, n, invalid, ++index);
}
return root;
}
protected:
Node* _root;
Node* _left;
Node* _right;
};
void Test()
{
int array[10] = { 1, 2, 3, '#', '#', 4, '#', '#', 5, 6 };
BinaryTreeThd<int> t1(array, sizeof(array) / sizeof(array[0]), '#');
/*t1.InOrderThreading();
t1.inorderThd();*/
t1.PreOrderTheeady();
t1.prevOrder();
}














 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









