






前言
本章包含了有关接入和使用大型语言模型(LLM)及构建相关应用的指南,详细如下:
-
LLM 接入 LangChain:
- 介绍了如何使用LangChain快速接入并使用大型语言模型(LLM),包括ChatGPT和其他模型。
- LangChain提供了一个开发框架,帮助开发者利用LLM的强大功能快速搭建应用。
- 文档详细说明了如何配置和调用ChatGPT,包括API密钥的设置和使用方法。
- 也探讨了使用提示模板(PromptTemplates)来精确控制模型输出的技术。
-
构建检索问答链:
- 讨论了如何使用向量知识库增强问答系统的效果。
- 介绍了加载和利用向量数据库进行查询召回的过程。
- 文档中涉及如何将检索到的信息整合并输入到LLM中以改进回答质量。
- 解释了构建有效的提示(Prompt)的重要性以及如何设计这些提示来优化LLM的性能。
-
部署知识库助手:
- 介绍了如何使用Streamlit创建和部署一个用户界面(UI),使LLM应用对用户友好且易于交互。
- 文档涵盖了从基础的Streamlit使用到高级功能,如如何通过用户界面(UI)进行动态交互和提供连续的对话历史。
- 探讨了如何将检索问答系统与历史对话功能结合,通过Streamlit部署在云端,使其可以全球访问。
此章为开发者提供了一系列工具和方法,用以构建、优化和部署基于大型语言模型的应用,特别是在处理和增强语言理解及生成任务方面。
关于“将LLM 接入 LangChain”与前面两部分的关联:
-
使用 LLM API 开发应用主要涵盖了使用不同的 LLM API(如OpenAI, Baidu Wenxin等)进行应用开发的基本方法。这部分内容为开发者提供了如何直接与LLM进行交互的基础知识和技能。
-
搭建知识库则着重于如何建立和管理一个知识库,以支持LLM的查询和数据检索需求,这为LLM提供了数据支持和背景信息,使得LLM可以提供更加精准和丰富的回答。
-
构建 RAG 应用则是结合前两个部分的内容,进一步将LLM的功能和知识库结合,通过构建基于检索的生成模型(RAG),提升模型在具体问题上的表现。这一部分中的“将LLM 接入 LangChain”侧重于如何在LangChain的框架下,集成和使用LLM,实现定制化的应用开发。
在VSCode里基于LangChain调用ChatGPT的步骤:
-
环境配置:确保VSCode安装了Python插件,并配置好Python环境。
-
安装LangChain:

-
设置环境变量:需要在
.env文件中配置OPENAI_API_KEY以存储ChatGPT的API密钥。 -
编写代码:创建一个Python文件,在其中编写以下代码用于调用ChatGPT:
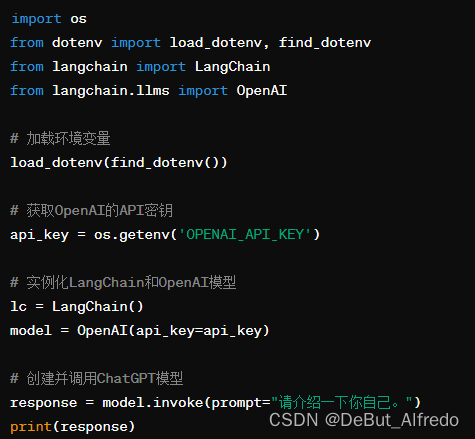
-
运行代码:在VSCode的终端中运行这个Python文件,查看ChatGPT的回答。
一些问题以及解决措施:
问题:Traceback (most recent call last): File "/workspaces/test_codespace/llm-universe/scripts/rag_tryone.py", line 3, in <module> from langchain import LangChain ImportError: cannot import name 'LangChain' from 'langchain' (/usr/local/python/3.10.13/lib/python3.10/site-packages/langchain/__init__.py)
解决:LangChain 类无法从 langchain 包中导入。这通常意味着我们可能使用了一个不正确的导入语句或者 langchain 包的版本不包含我们试图使用的类或功能。
问题一的解决步骤
-
确认
langchain包版本:首先确认安装的langchain包是最新的或者是支持需要的功能的版本。可以通过运行以下命令来查看当前安装的版本: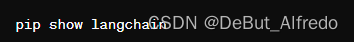
-
更新或安装正确的
langchain版本:如果发现版本不是最新的,可以尝试更新它:
-
检查文档:查看最新的
langchain文档,确认LangChain类的正确导入方式。可能的情况是,类的名字或模块结构发生了变化。 -
修改导入语句:如果发现文档中提供了不同的导入方式,按照文档更新代码。比如,如果文档中提到应该这样导入:
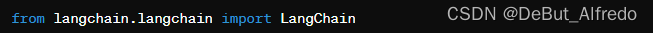
那么请更新代码以匹配这个导入路径。
-
测试代码:更新导入语句后,重新运行你的脚本以确认问题是否解决。
问题:Traceback (most recent call last): File "/workspaces/test_codespace/llm-universe/scripts/rag_tryone.py", line 14, in <module> openai_api_key = os.environ['OPENAI_API_KEY'] File "/usr/local/python/3.10.13/lib/python3.10/os.py", line 680, in __getitem__ raise KeyError(key) from None KeyError: 'OPENAI_API_KEY'
解决:这个错误发生的原因是代码试图从环境变量中获取名为 OPENAI_API_KEY 的值,但是在当前的环境变量中找不到这个键值。KeyError: 'OPENAI_API_KEY' 指出 OPENAI_API_KEY 这个环境变量不存在。
问题二的解决步骤
-
检查环境变量文件:确保项目目录中有
.env文件,并且其中包含了OPENAI_API_KEY=你的密钥这样的行。密钥应该是从 OpenAI 获取的API密钥。 -
确保加载
.env文件:代码中已经包含了load_dotenv(find_dotenv())的调用,这应该可以加载.env文件。确保.env文件位于项目根目录或者其他find_dotenv()能够找到的位置。 -
手动检查和加载:
在终端运行printenv | grep OPENAI_API_KEY查看是否正确设置了环境变量。如果上面的命令没有输出,我们可能需要手动设置环境变量。在 Linux 或 macOS 终端,可以运行export OPENAI_API_KEY='你的密钥'来设置环境变量,然后再运行脚本。 -
运行代码之前加载环境变量:
确保load_dotenv()在尝试访问OPENAI_API_KEY环境变量之前被调用。代码应该像这样:
这段代码中加入了错误处理,如果环境变量未设置,会抛出一个更明确的错误消息。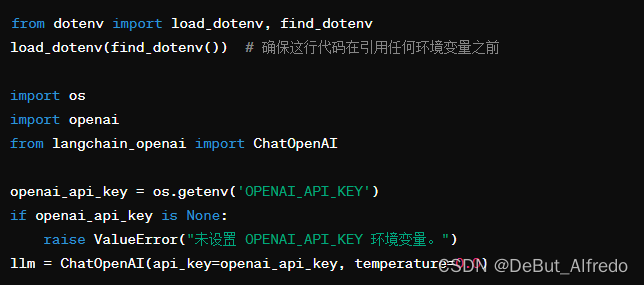
通过以上步骤,应该能够解决 KeyError 的问题。确保 .env 文件存在并正确配置,且 load_dotenv() 在使用环境变量之前被调用。
最终代码运行如下:
from dotenv import load_dotenv, find_dotenv
import os
from langchain_openai import OpenAI
from langchain.prompts.chat import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 环境变量加载
load_dotenv(find_dotenv())
# 获取OpenAI的API密钥
api_key = os.getenv("OPENAI_API_KEY")
if api_key is None:
raise ValueError("API密钥未设置。请在环境变量中设置OPENAI_API_KEY。")
# 实例化ChatOpenAI模型
llm = OpenAI(api_key=api_key, temperature=0.0)
# 创建提示模板
template = "你是一个翻译助手,可以帮助我将 {input_language} 翻译成 {output_language}."
human_template = "{text}"
prompt_template = ChatPromptTemplate.from_messages([
("system", template),
("human", human_template)
])
# 输出解析器
output_parser = StrOutputParser()
# 构造完整的链
def translate(text, input_language, output_language):
messages = prompt_template.format_messages(input_language=input_language, output_language=output_language, text=text)
response = llm.invoke(messages)
return output_parser.invoke(response)
# 使用链
text = "我带着比身体重的行李,游入尼罗河底,经过几道闪电看到一堆光圈,不确定是不是这里。"
result = translate(text, "中文", "英文")
print(result)
运行结果:System: I carried luggage heavier than my body and swam to the bottom of the Nile, passing through several flashes of light to see a pile of apertures, not sure if this is the place.
![]()















 366
366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









