







一个简单的爬虫可以由一下几部分构成:
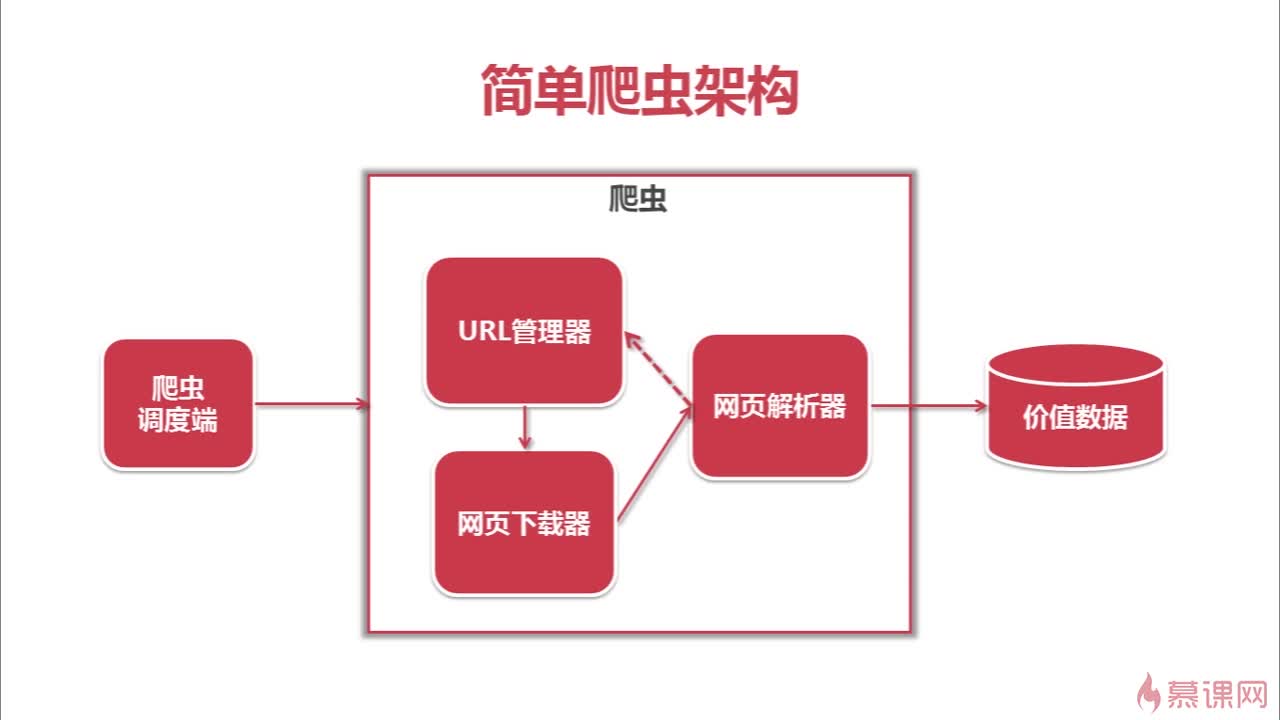
1.爬虫调度端
启动,停止,监控运行情况,也就是整个爬虫的main。
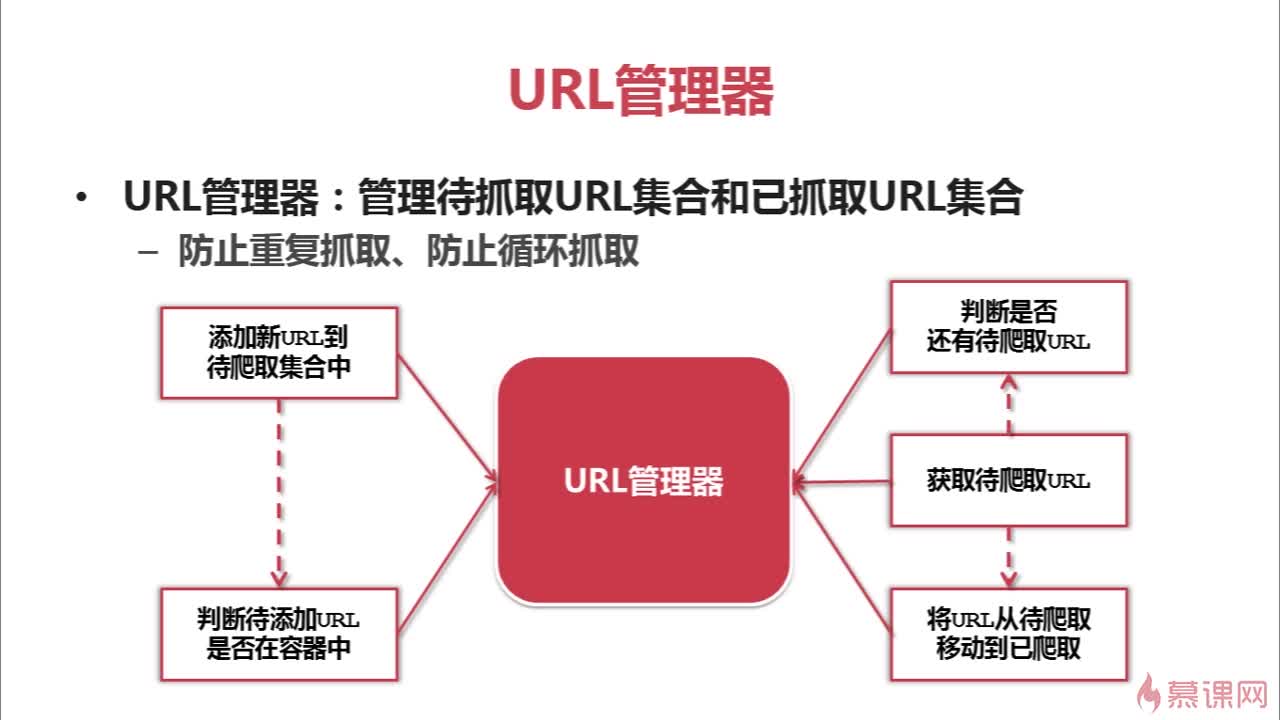
2.URL管理器
管理待爬取和已爬取的URL,可以将已经获得的url保存在内存或者关系型数据库中或者缓存数据库中。内存中储存可以用set()语句可去除重复数据;用关系型数据库存储时设计两个列,其中一列记录url(主键),另一列记录是否爬取过;大公司会采取redis这种缓存数据库进行存储,使用其中的set结构(完全不了解)。
3.网页下载器
接收待爬取URL,将网页内容下载为字符串,给解析器,可以采用urllib2模块来实现。
4.网页解析器
一方面解析出有价值的数据,一方面解析出其他关联URL,传回URL管理器进行循环,可以使用BeautifulSoup4实现。
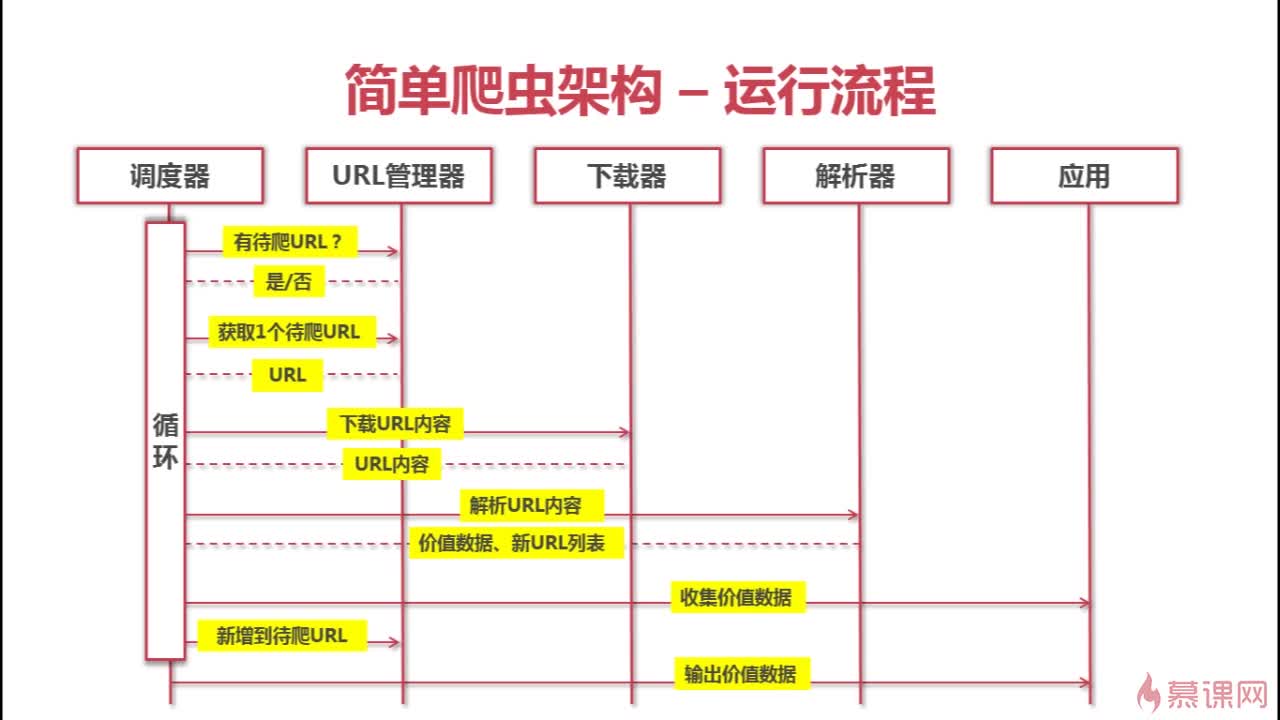
其运行流程如下所示:















 504
504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









