






Python爬虫是一种使用Python编程语言开发的自动化网页抓取工具。它们主要用于从互联网上获取数据,通常用于收集公开信息,如新闻文章、社交媒体帖子、价格信息等。
一、爬虫的基本原理
- 爬虫本质上就是HTTP请求,使用一些请求库模拟,比如requests,httpx让服务器响应内容。
- 服务器响应之后,使用HTML解析库页面,或者使用JSON解析JSON格式数据。bs4、xpath、正则。
- 解析数据之后需要把内容存储入库,比如本地文件,或者数据库。mysql、redis。
爬虫流程图 :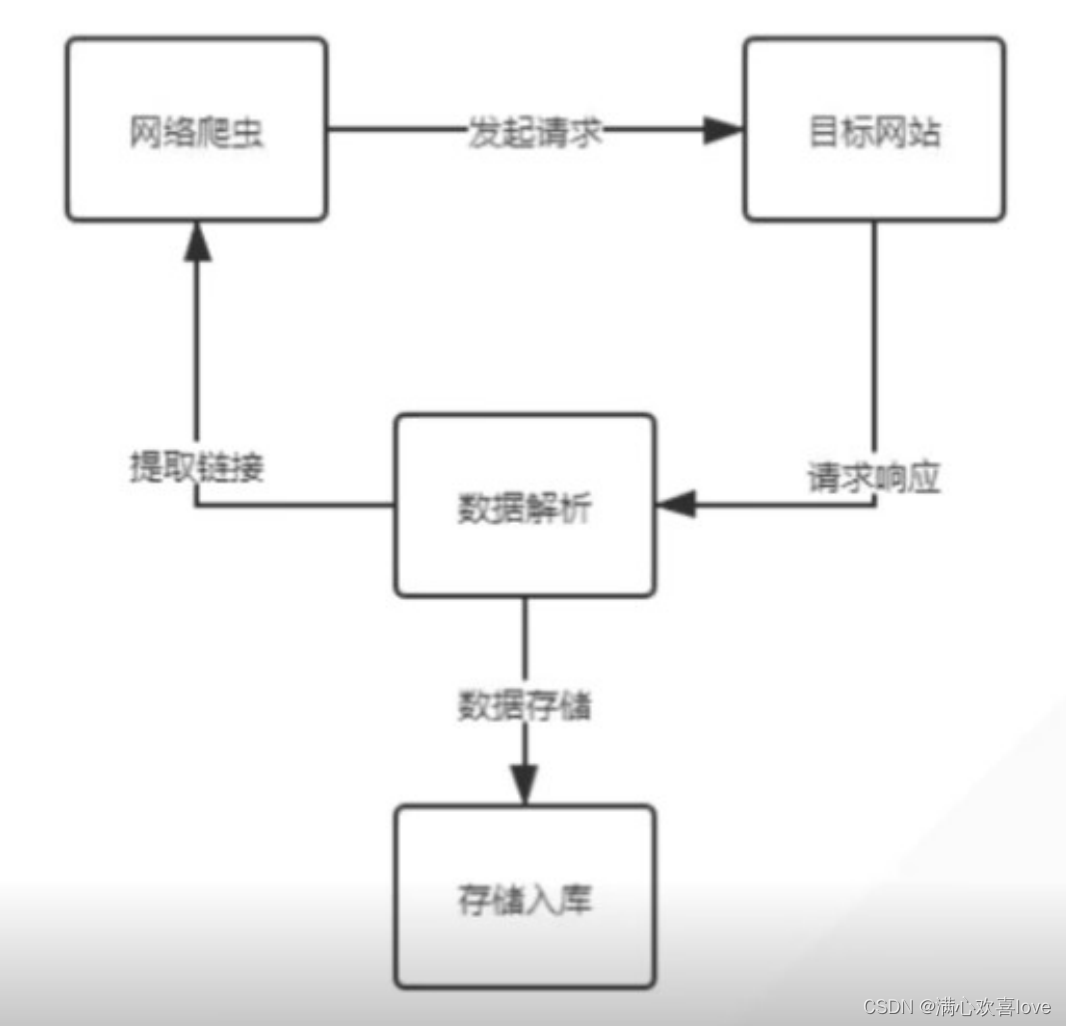
二、HTTP基础
- HTTP,全称为超文本传输协议(Hypertext Transfer Protocol),是一种用于互联网上数据传输的基本协议。它被广泛应用于网页浏览、文件传输、电子邮件等各种网络应用中。
- HTTP是一种无状态的协议,意味着服务器并不保持与客户端的连接状态。每个请求都是独立的,并且不依赖于之前或之后的请求。这使得HTTP协议具有很好的可伸缩性,并且能够高效地处理大量并发的请求。
- HTTP请求由一个请求行、一个或多个头部和可选的消息体组成。请求行包括请求方法(如GET、POST等)、请求的资源路径以及HTTP协议的版本。头部则包含关于请求或响应的各种信息,例如内容类型(Content-Type)、响应状态码(Status Code)等。
- HTTP使用端口80进行通信,这也是为什么当你在浏览器中输入一个URL并按下回车键时,浏览器会自动通过端口80进行连接。然而,HTTPS协议则使用端口443,以提供更安全的通信,例如在传输敏感信息如信用卡信息时。
- HTTP协议的发展已经经历了多个版本,从最初的HTTP/1.0到目前广泛使用的HTTP/1.1和HTTP/2。HTTP/1.1引入了许多重要的特性,例如持久连接、缓存和分块传输编码等,以提高效率和性能。而HTTP/2则引入了二进制帧、头压缩等特性,进一步优化了协议的性能和安全性。
- 总的来说,HTTP作为互联网上最核心的协议之一,为我们的在线生活提供了基础支持。它的持续发展和改进确保了网络应用的快速、安全和高效的数据传输。
http请求报文:

1、http请求方法:
HTTP请求方法是指客户端与服务器之间进行交互的不同方式。
八种常见请求方法:

其中第三种head方法一般用于网站测试与第七种trace方法可以相互替代。
2、http标头
HTTP标头是HTTP协议中用于描述请求或响应属性的一种元数据格式。HTTP标头包含一个键值对,其中键和值都是字符串,由冒号分隔。标头在HTTP请求和响应的消息体之前传输,用于传递关于请求或响应的附加信息。
标头参数含义:

3、http状态码:
HTTP状态码是指由服务器返回给客户端的数字代码,用于表示HTTP请求的处理结果。状态码是一种标准的协议机制,用于向客户端传达特定请求的处理状态。
五类状态码响应类别:

三、python-requests库基础方法
- 如果你是在Windows系统下,可以在命令行输入
pip install requests进行安装。- 如果你是在Linux系统下,可以输入
sudo pip install requests进行安装。
借鉴文档地址:Requests: 让 HTTP 服务人类 — Requests 2.18.1 文档
1、简单发送请求:
我这里就医借鉴文档地址为例,来爬取内容

首先导入requests库,使用get方法向网页发送一个get请求。但是这里可以看到值返回了一个状态码200.
加一个.text就爬取到了网页源代码。
2、传递URL参数
什么是url参数?简单来说域名后如果带一个?问号,那么问号后就是url参数


在浏览器开发者模式中我们也可以在载荷中查询url参数
https://www.baidu.com/s?ie=UTF-8&wd=%E7%99%BE%E5%BA%A6
实验网址
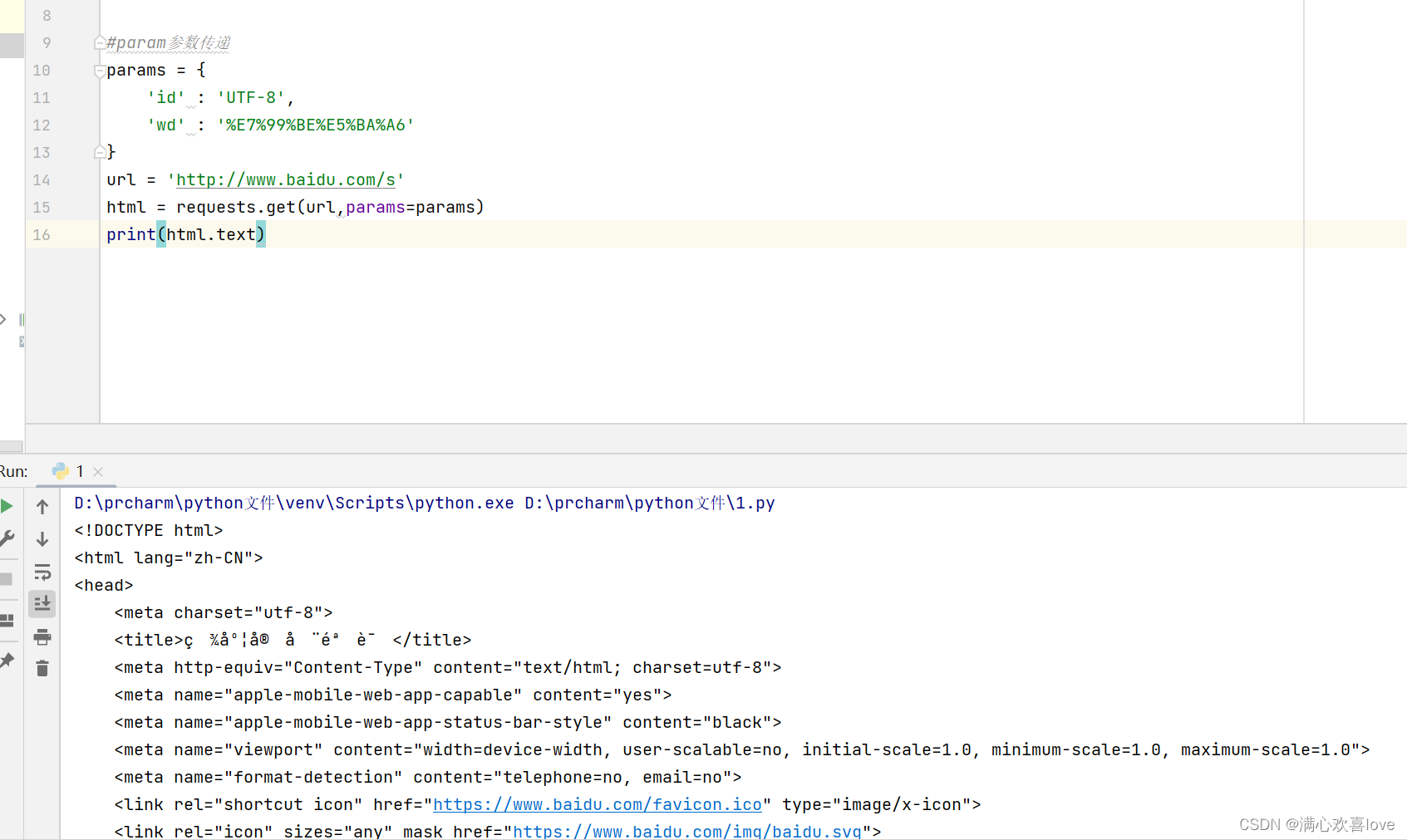
可以看到虽然爬取到了内容。但是有乱码
当返回页面有乱码时,一定要记住用encoding
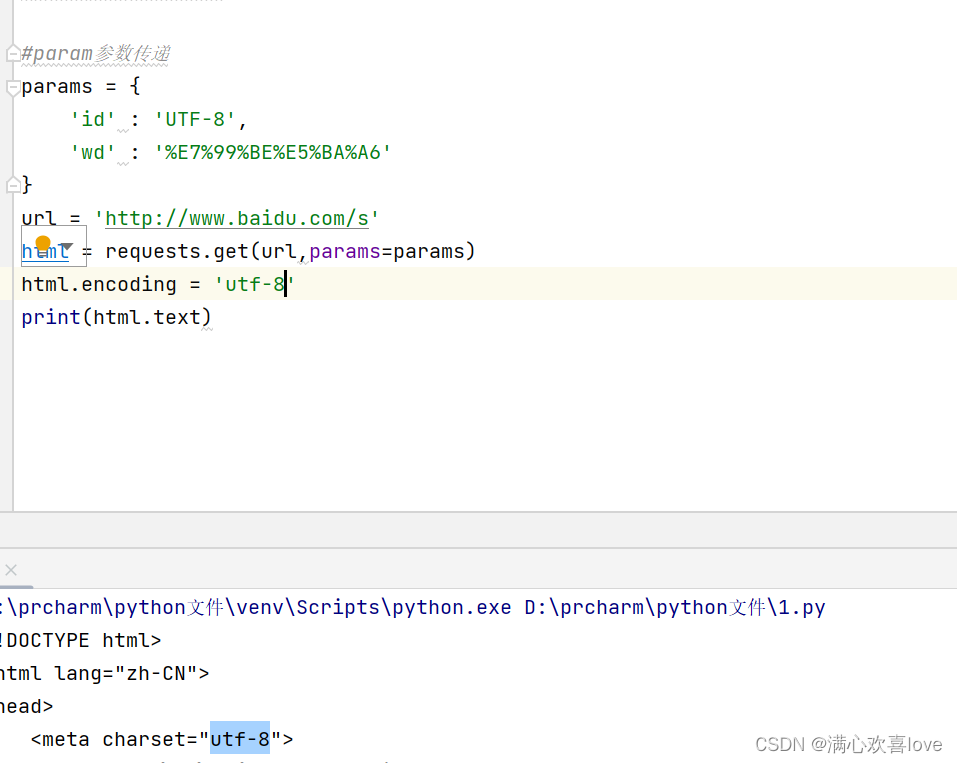
网页返回的时什么编码encoding后就写什么编码。

没有乱码了。但是出现了百度安全验证,这就是反爬虫。
我们可以在headers里加入网页请求头

记得要以键值对的形式。

爬取到的内容又乱码了,怎么回事?
请求头部加的太多了,将浏览器可以处理但编译器不能处理的也加了进去比如说压缩方式,所以我们现在要删除。

成功。
3、二进制响应内容
之前我们.text返回的是文本内容,那么想要返回二进制内容怎么办?

实验图片
这次的请求头不用全部加,可以一个一个加着试试,但是User-Agent是必须要加的
成功爬到这张图片的二进制数据。

这张图片就被我下载下来了。
4、JSON响应内容
百度图片就是json数据
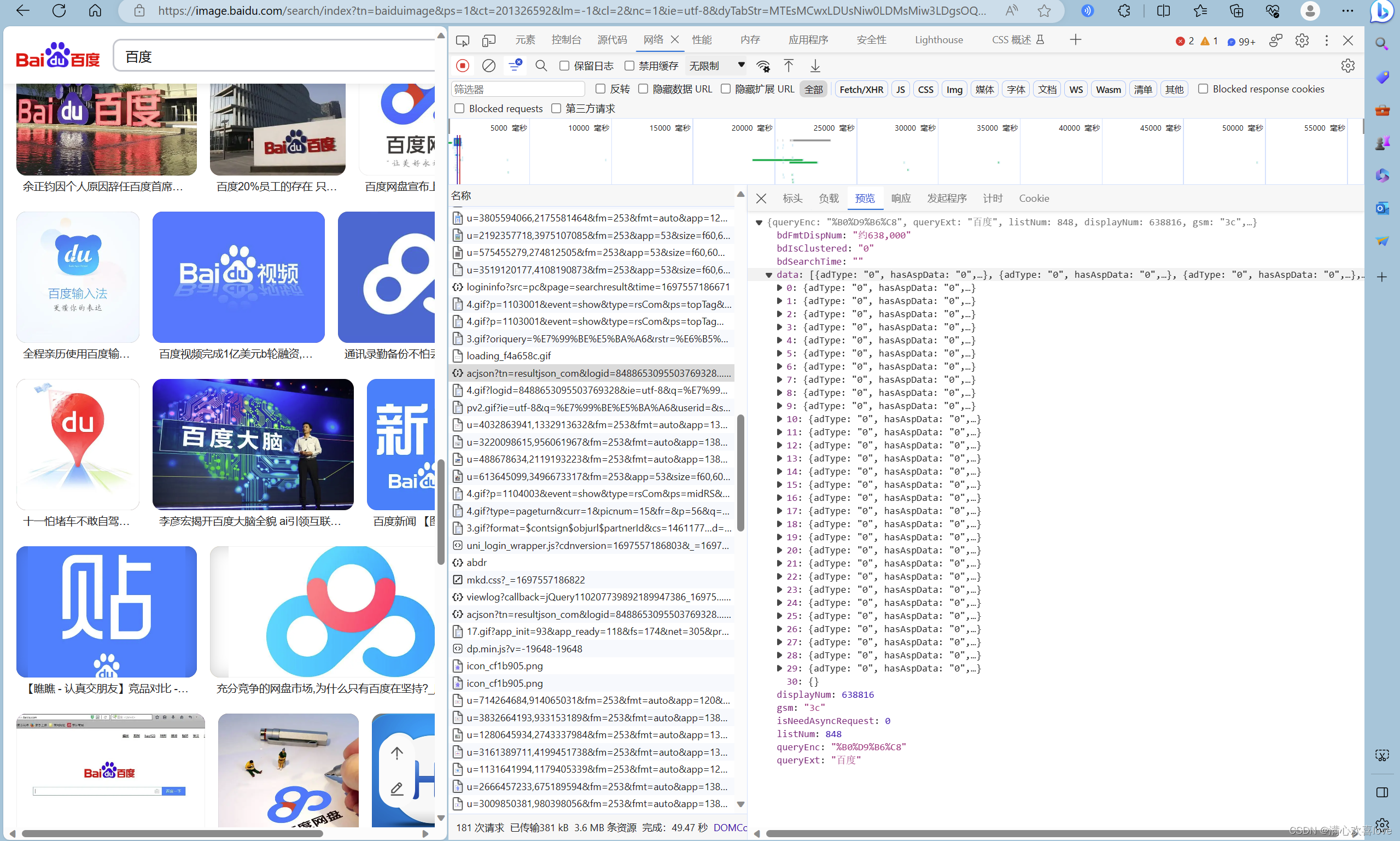
这种花括号标注的数据就是json格式。

可以获取文本形式但是不方便看

.jison()

虽然图片数据爬到了但是报了错
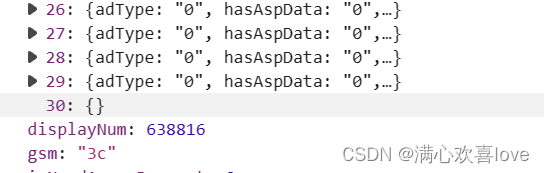
因为第三十条为空,取字典取不出来就会报错。
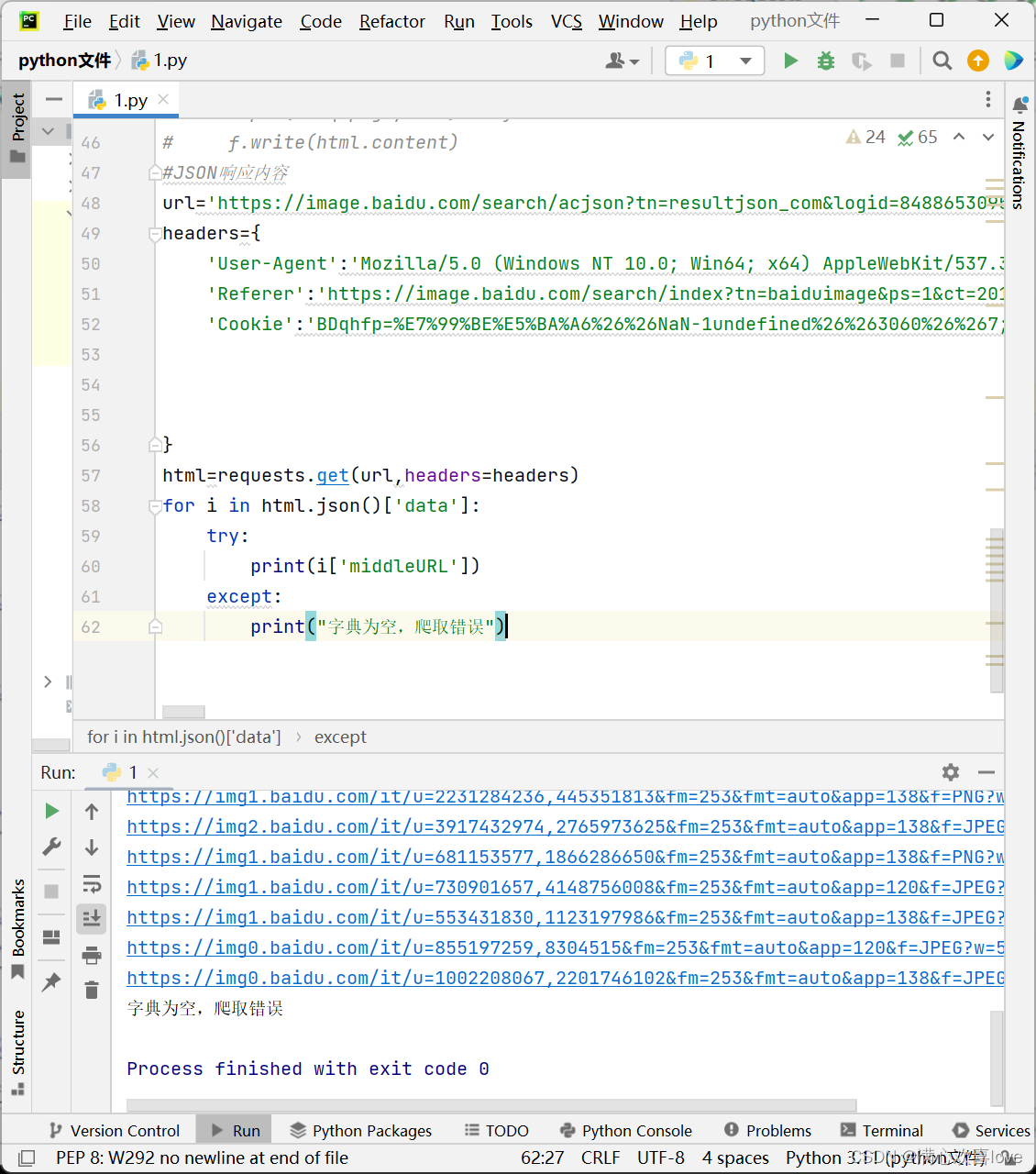
这样就不报错了。
5、更加复杂的post请求
http://httpbin.org/post测试网站

注意post是data ,get是params
6、响应状态码
还是上面的例子
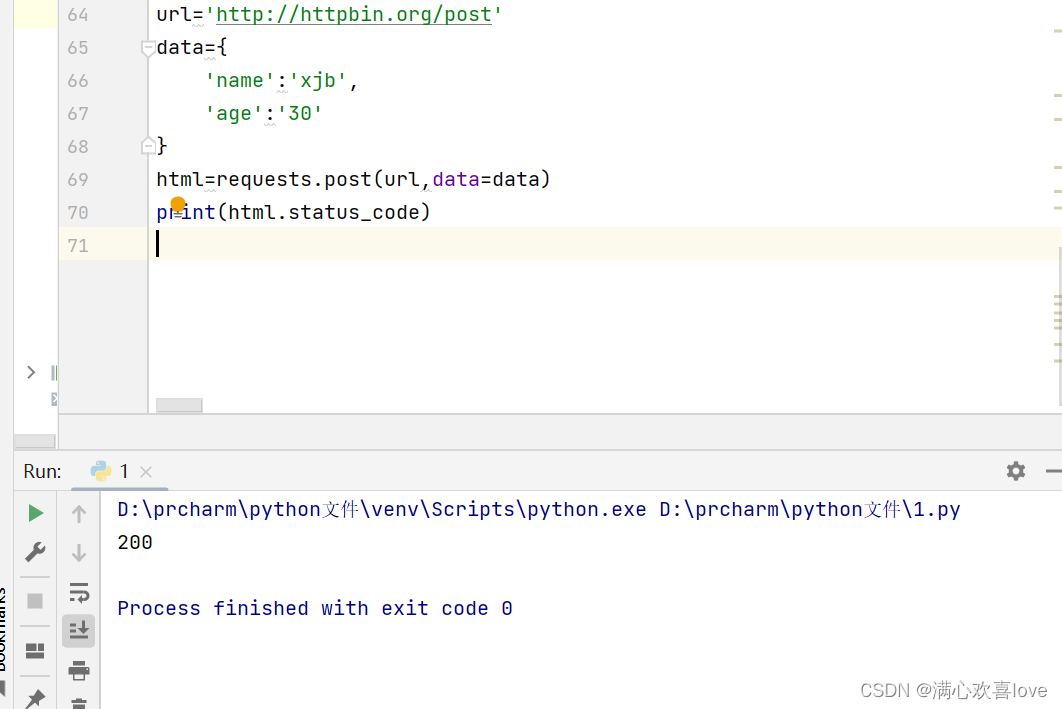
status_code
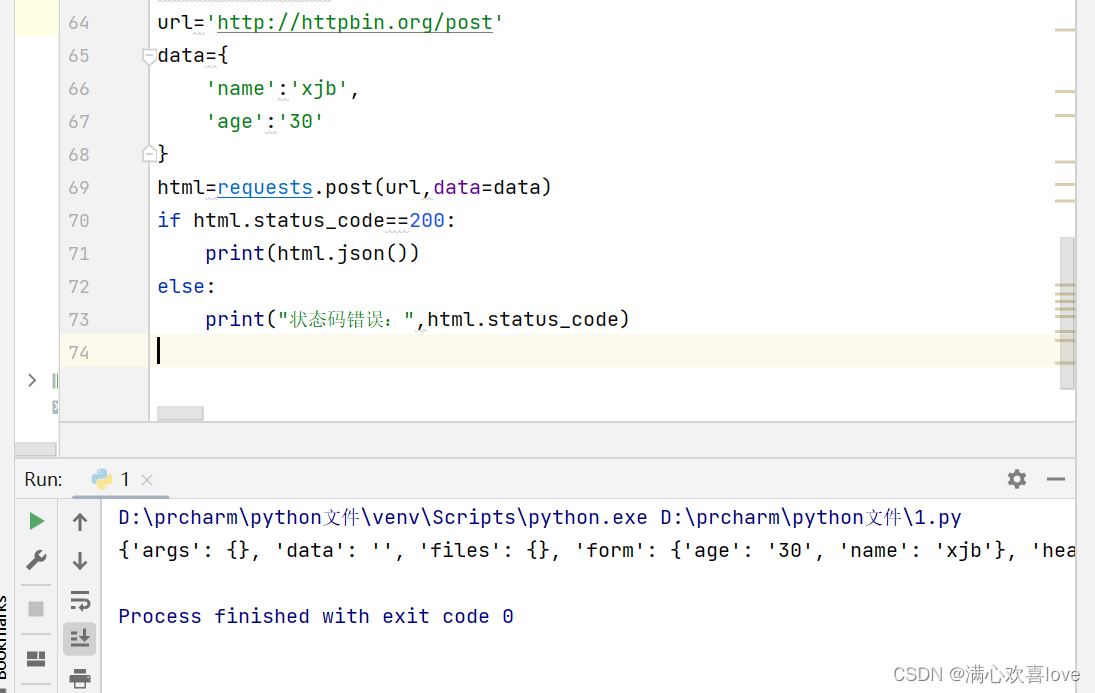
还可以利用状态码写一个条件判断
7、响应头
.headers

8、超时
timeout

如果在参数时间之前没返回就报错。
四、requests高级用法
1、会话对象
会话对象让你能够跨请求保持某些参数。
.Session()

就用这个例子

先把下面两行代码注释,运行返回cookies
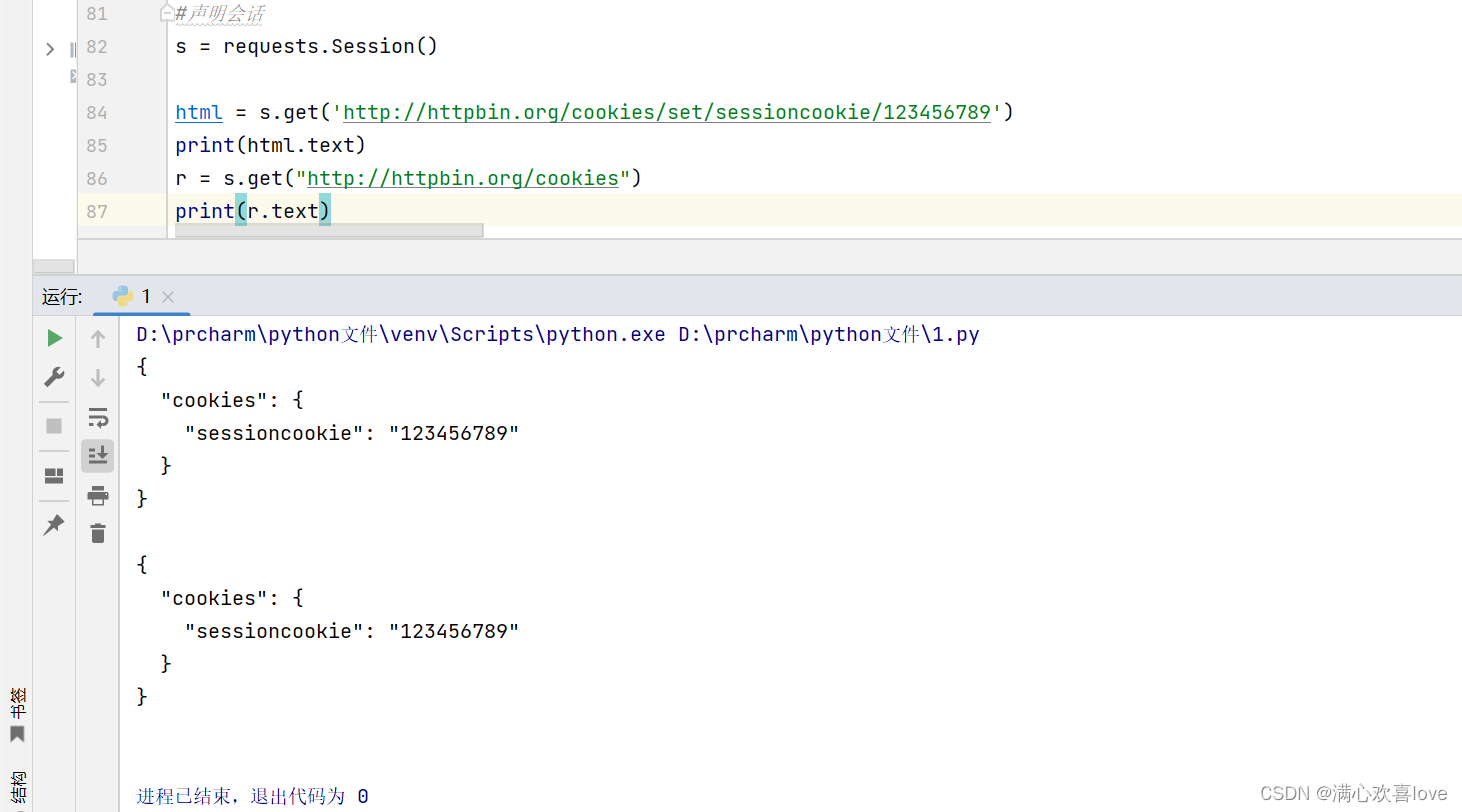
取消注释可以看到,cookies被传递下来了

点进Session查看源代码,可以看到里面可以传递很多参数
2、SSL证书验证
Requests 可以为 HTTPS 请求验证 SSL 证书,就像 web 浏览器一样。SSL 验证默认是开启的,如果证书验证失败,Requests 会抛出 SSLError:

还是文档中的例子
运行之后会返回报错信息
requests.exceptions.SSLError: hostname 'requestb.in' doesn't match either of '*.herokuapp.com', 'herokuapp.com'
这时候就要加上verify参数

爬取到了数据但是提示访问危险,但我们获取数据就行了不用管危不危险。
以后只要看见SSLError错误就用verify
3、代理
如果需要使用代理,你可以通过为任意请求方法提供
proxies参数来配置单个请求

使用代理要先创建一个字典形式的proxies参数
注意,快代理里的代理一般用不了因为全国人民都在用,全凭运气
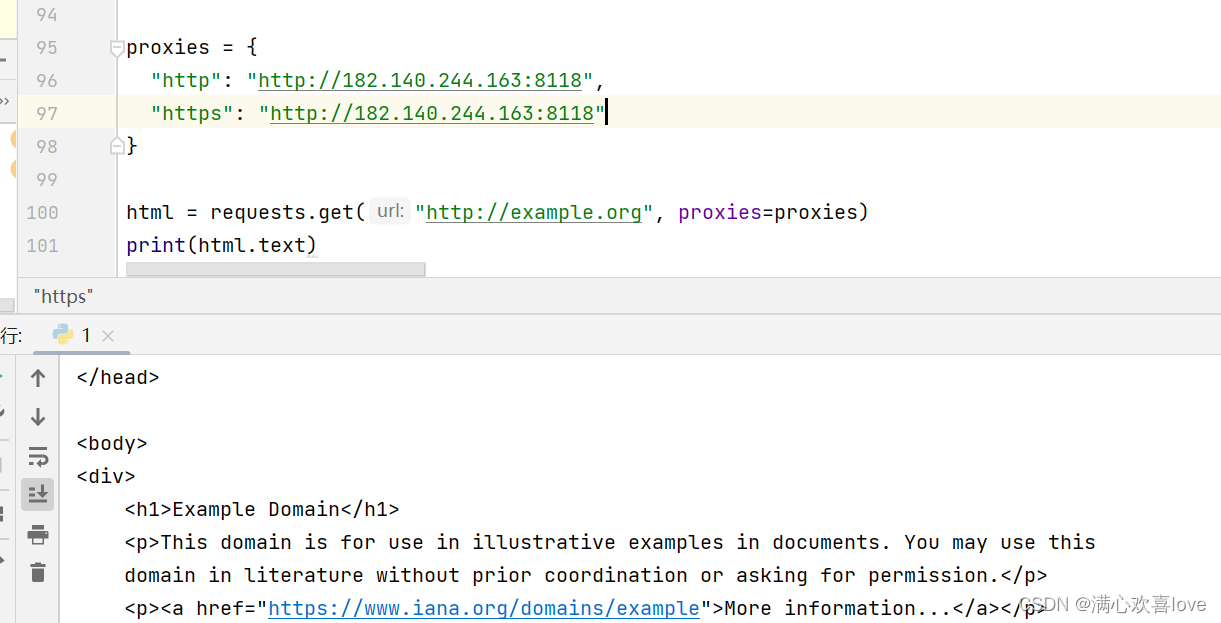
我运气不错
五、实战-无广告百度搜索(bs4)
pip install bs4 lxml 安装bs4和lxml两个库
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple如果下不成功也可以使用国内镜像源。
css选择器
根据HTML的结点的class和id定位元素
查看网页源代码

可以发现大多数结点都是存在class和id的
标签定位原则:从外到内,层层深入

在检查页面按ctrl+f可以调出查找框,可以在里面写css或者xpath
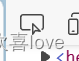 点击这个按钮定位到整个页面
点击这个按钮定位到整个页面
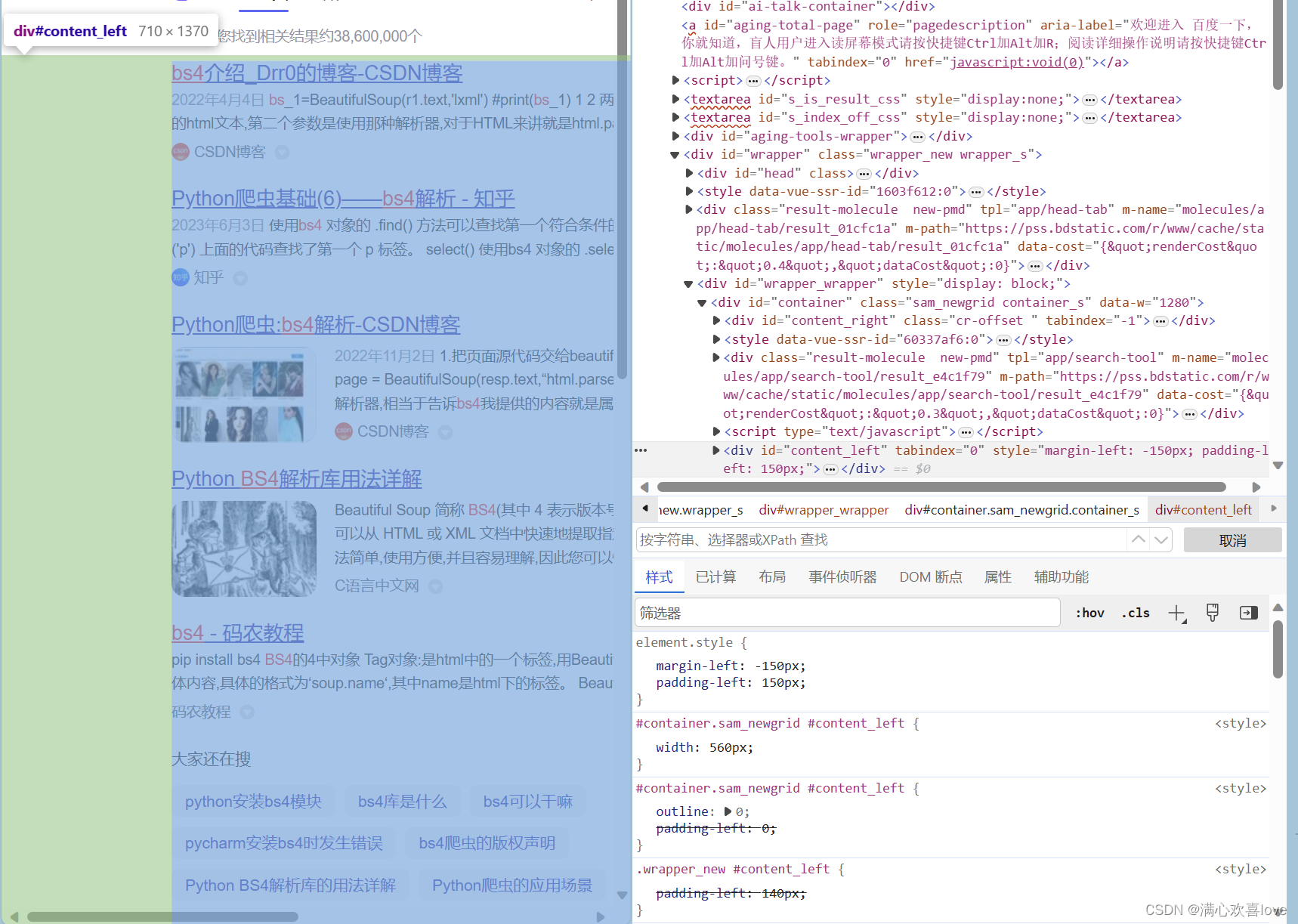
是div id=content_left
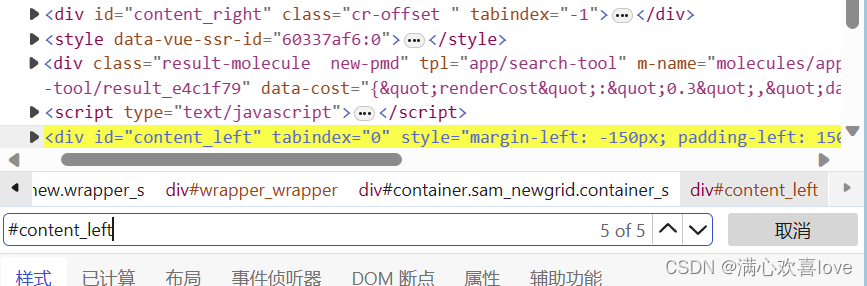
在查找框通过#+id查找,发现查找到了五个 ,除了刚刚的div之外别的东西也有这个id,这个时候就需要我们层层深入
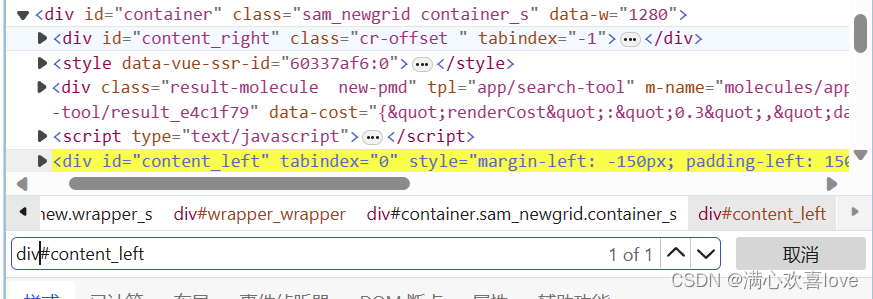
在前面加个div,定位到了只有一个

再往里深入

发现广告的class是空的

我们就可以只选出class是这样款式的将class为空的过滤掉

通过这种语法就能过滤掉广告,但是定位到了一整个答案,而我们需要的是标题和跳转链接。所以我们还得深入

发现标题在这个h3里面,但里面没有class也没有id直接用标签名就好

里面有href跳转链接有文本,已经定位到最终的东西了
以上就是一个css选择器使用过程
开始写代码

先测试以下,成功
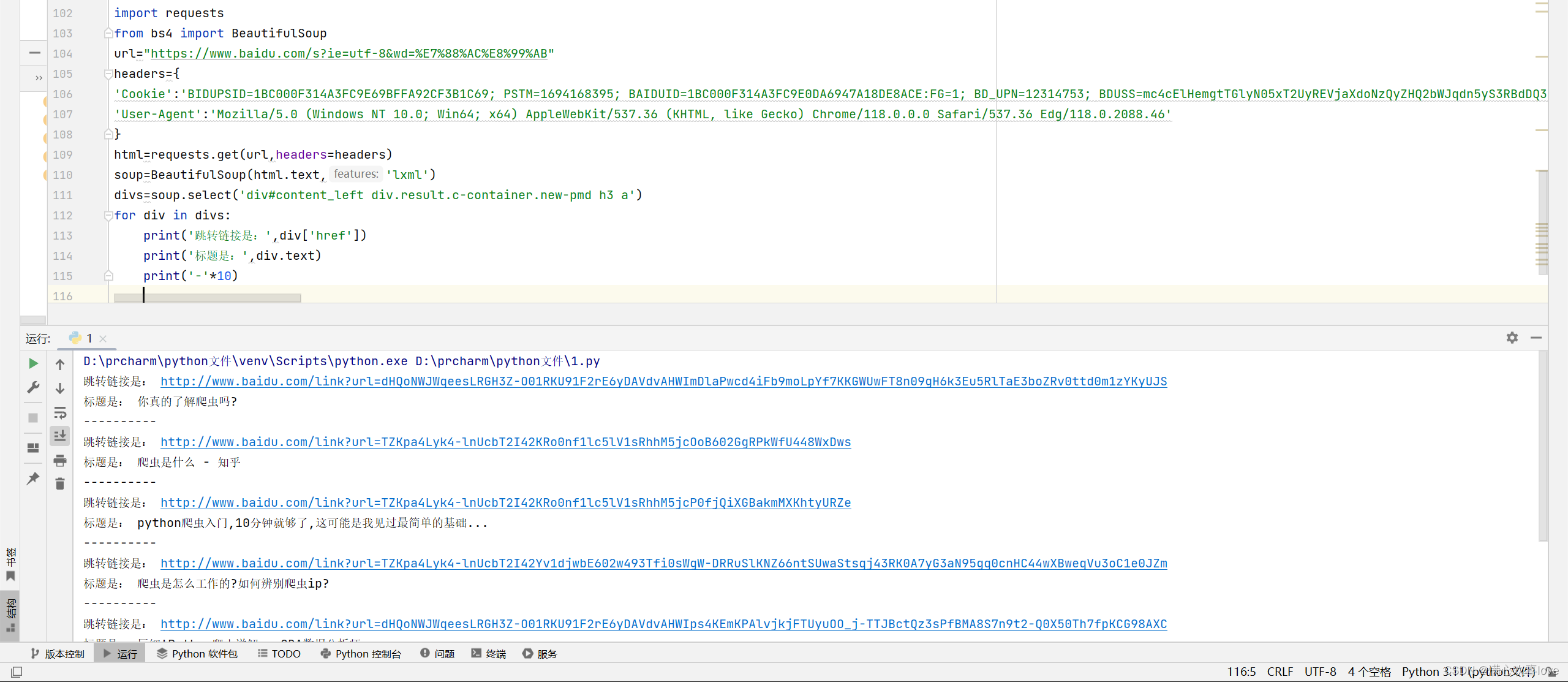
成功实现百度爬虫
接下来实现用户自定义输入搜索

再来实现翻页功能

观察百度翻页的url发现,关键的就是pn参数

写上for循环总共可以爬取十页
翻页一般都是参数变化 pn page number
六、xpath改写第五节代码

定位到页面所有
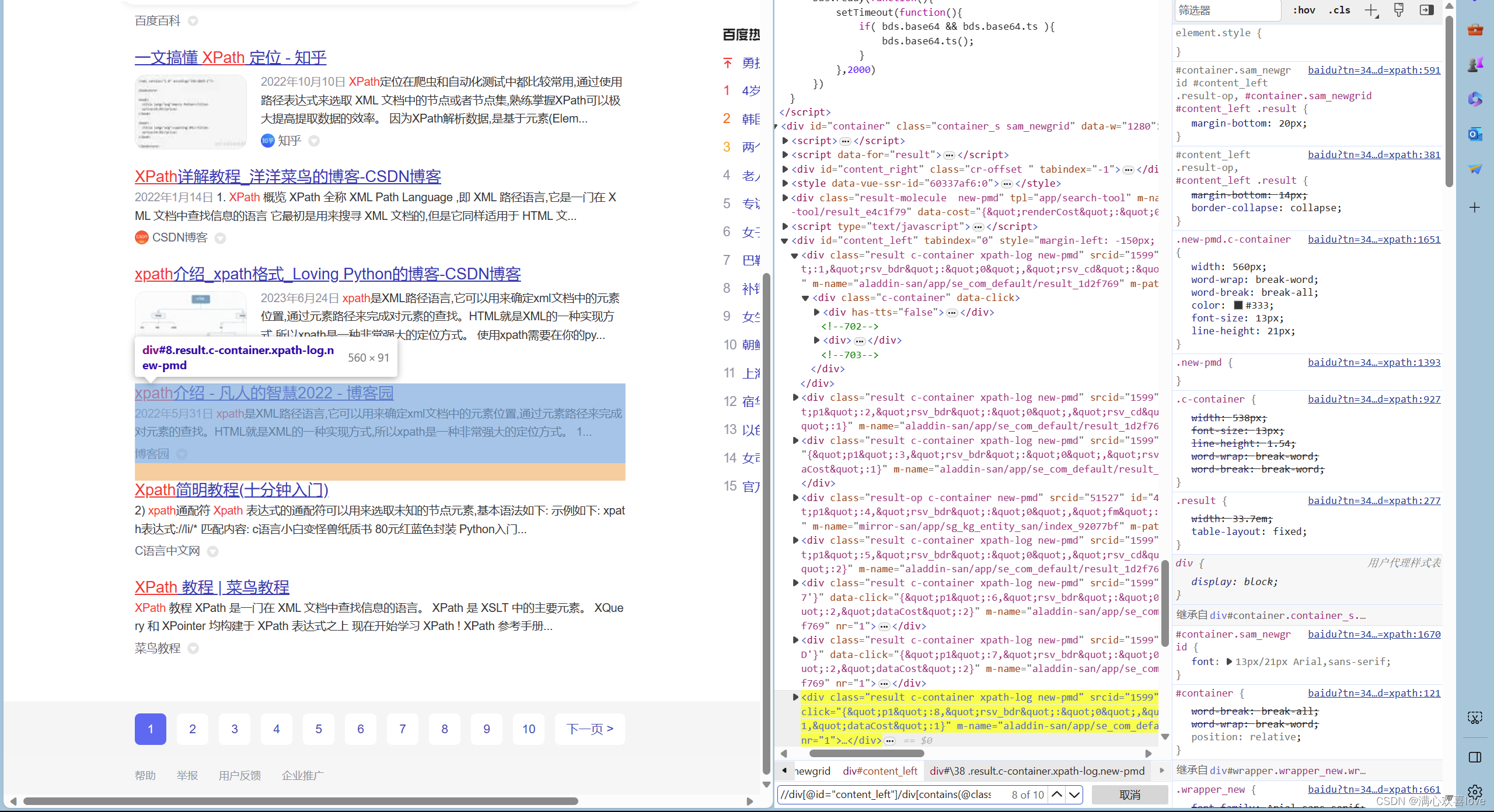
层层深入
//div[@id="content_left"]/div[contains(@class,"result")]/div[contains(@class,"c-container")]/div[contains(@has-tts,"true")]/h3/a/@href
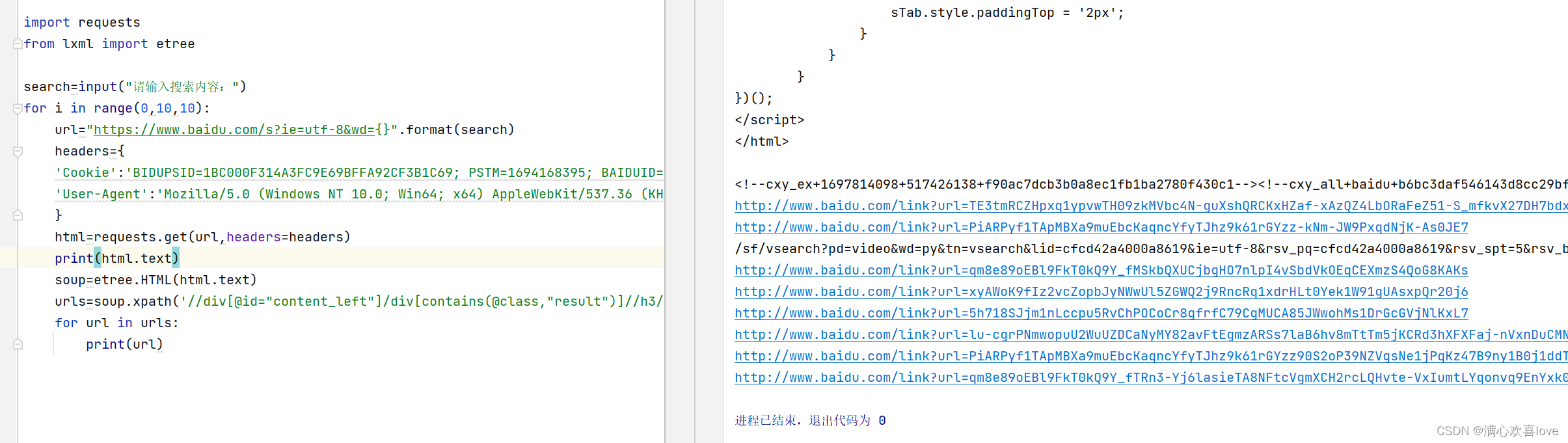
链接爬取到了

将href改为text()文本也爬取到了
xpath比css快很多但我个人感觉还是css好用
七、正则表达式
拿知乎热榜这个网址为例‘

查看网页源代码

div里有简介有热度有图片
但是没有简介和里面的内容跳转链接啥的

都在下面的json文件中
这个时候就不得不用到正则了,xpath和beautifulsoup的短板就体现出来了
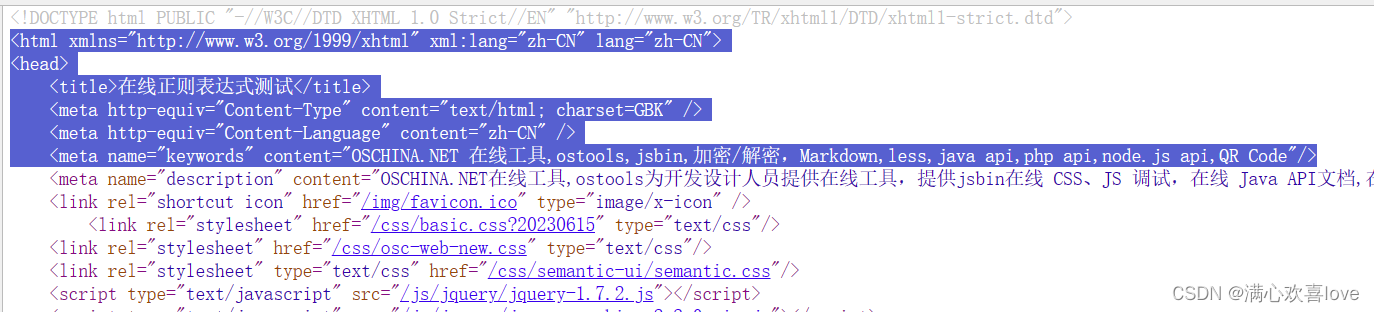
就以正则表达式在线测试网站的源代码为例
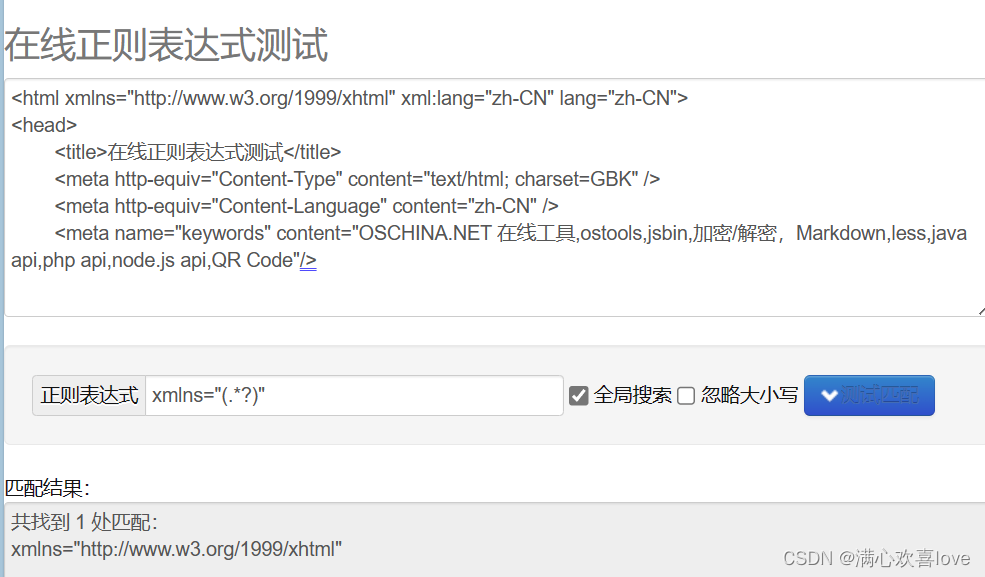
(.*?) 惰性匹配
将符合语法的东西全部弄出来
注意:括号要是英文括号


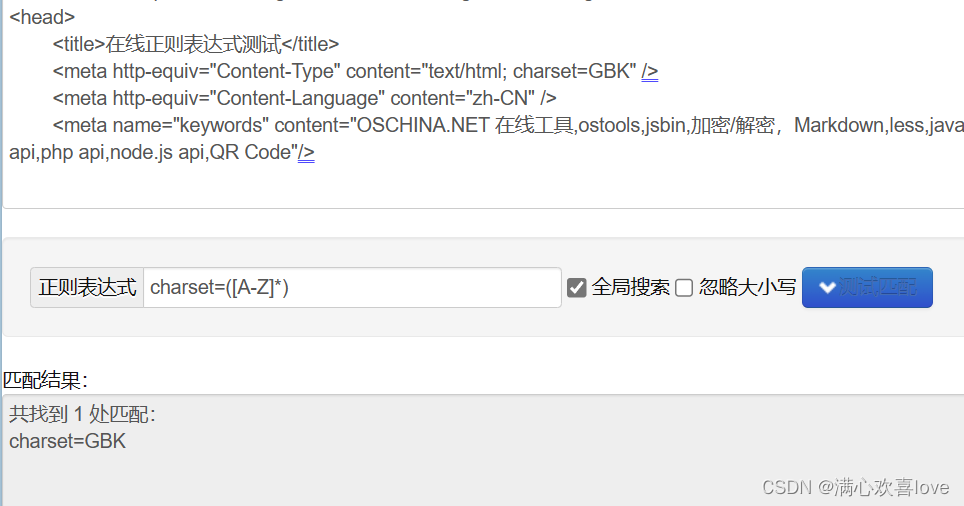
匹配字母可以直接写匹配的次数也可以写*号
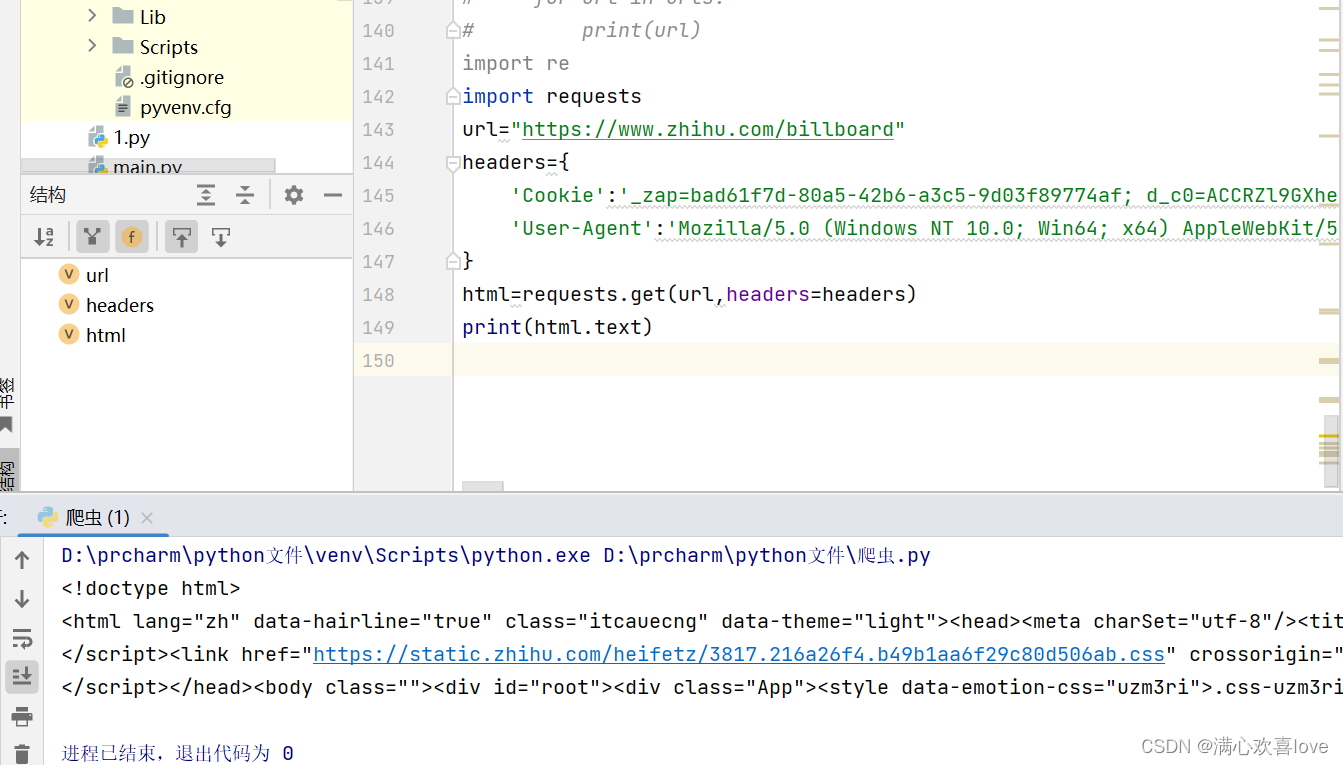
这里是运用到内置库re
先测试一下爬取成不成功

复制网页源代码的时候最好像这样复制吧,把附加的一些东西一起复制,最好是独一无二的特征。

将里面的内容换成惰性匹配

现在里面的内容都爬下来了
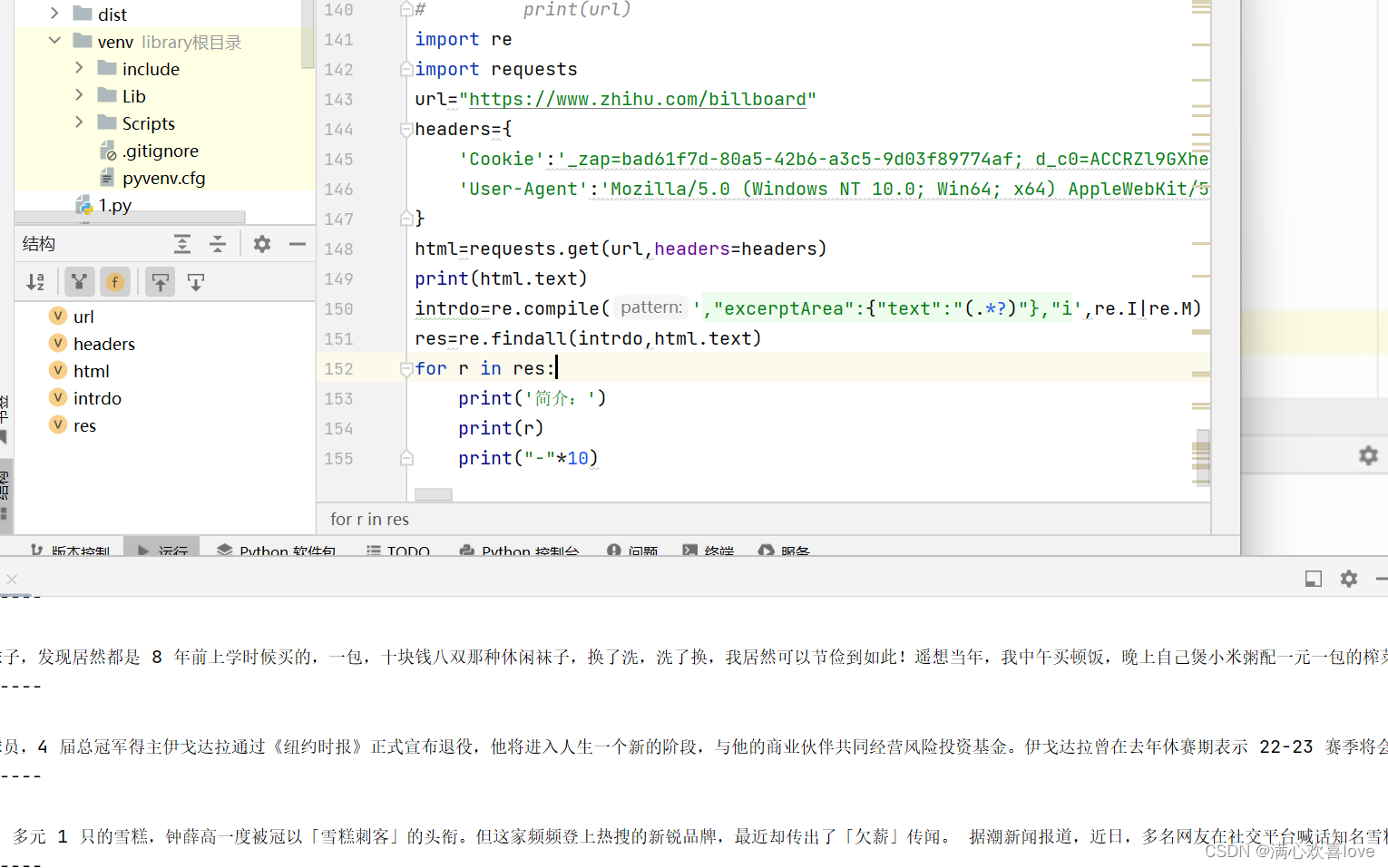
再加个文字提示就更好看了
现在再弄他的跳转链接

还是一样多复制一点

跳转链接也爬取下来了
八、urlencode补充知识
urlencode是一个函数,可将字符串以URL编码,用于编码处理。
之前复制百度的url时,https://www.baidu.com/s?ie=UTF-8&wd=百度变成了https://www.baidu.com/s?ie=UTF-8&wd=%E7%99%BE%E5%BA%A6
百度被自动编码了,这个就是urlencode
python中有内置库urllib可以解决这个问题
from urllib.parse import unquote,quote
quote编码
unquote解码

使用方法大致就是这样
九、腾讯视频下载

今天来试试腾讯的免费电影下载
腾讯视频加载是以m3u8的形式
- M3U8是一种常见的流媒体格式,主要用于在流媒体传输中实现动态适应性。它由多行组成,每行以特定的标签和内容组成,用于描述媒体片段的URL、时长、编码信息、分辨率等相关信息。M3U8文件可以包含多个媒体流,每个流都由一个或多个媒体片段组成。
- M3U8的主要用途是在流媒体传输中实现动态适应性,根据网络条件和设备能力调整视频的质量和传输速度。通过M3U8文件中的描述,客户端可以根据当前的带宽和设备性能选择最合适的媒体片段进行下载和播放。M3U8文件通常由流媒体服务器生成和维护。服务器根据不同码率或分辨率生成不同质量的媒体片段,并将它们的URL和相关信息写入M3U8文件中。客户端通过解析M3U8文件来获取媒体片段的位置和属性,并根据需要下载和播放这些片段。客户端还会周期性地请求新的M3U8文件,以获取最新的媒体片段列表,并根据网络条件和设备性能选择适合的片段进行播放。
- 总的来说,M3U8是一种用于描述多个媒体片段的视频播放列表文件格式,既支持直播又支持点播,尤其在Android、iOS等平台最为常用。
现在的腾讯视频不像以前,直接搜m3u8是搜不到的,现在的视频文件直接搜 gzc就有了。

复制这个url就是直接下载一段十几秒的视频
(目前博主的水平只能到这个地步,道心破损)
十、腾讯新闻
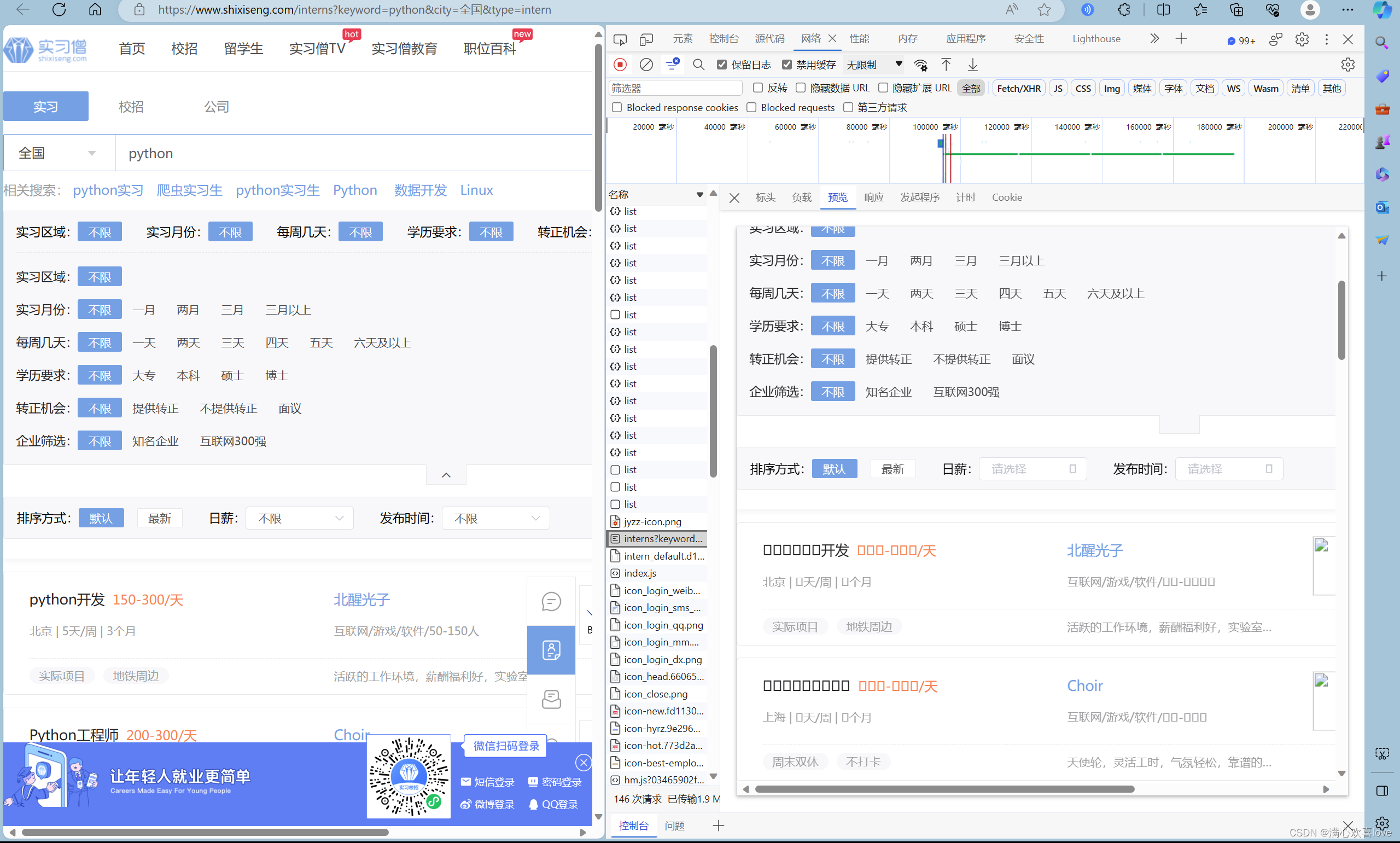
a.jax动态请求,json
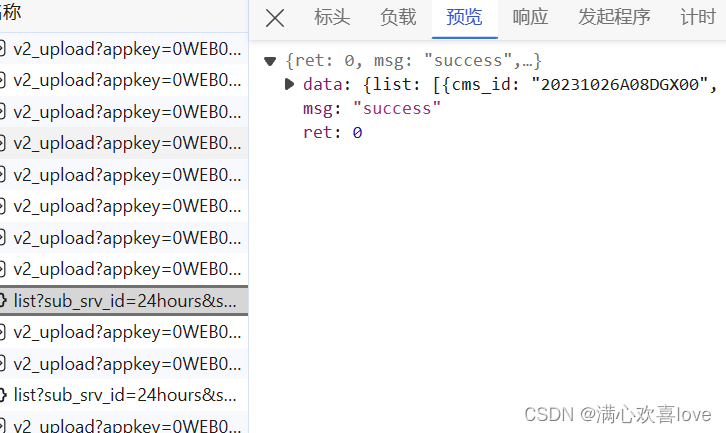
抓包查看Fetch/XHR,一般a.jax请求都是通过XHR发起的
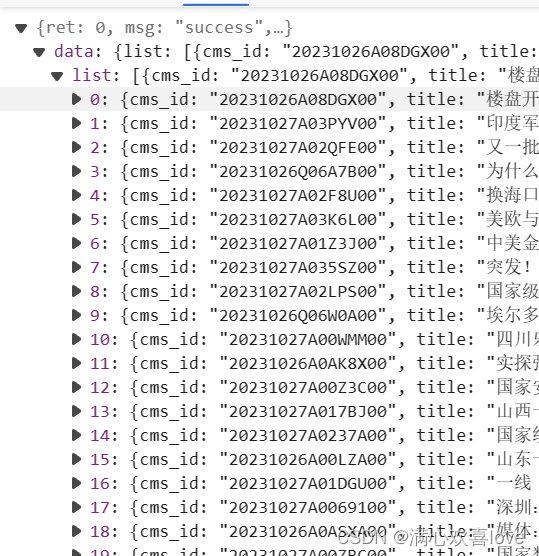
json类型的文件
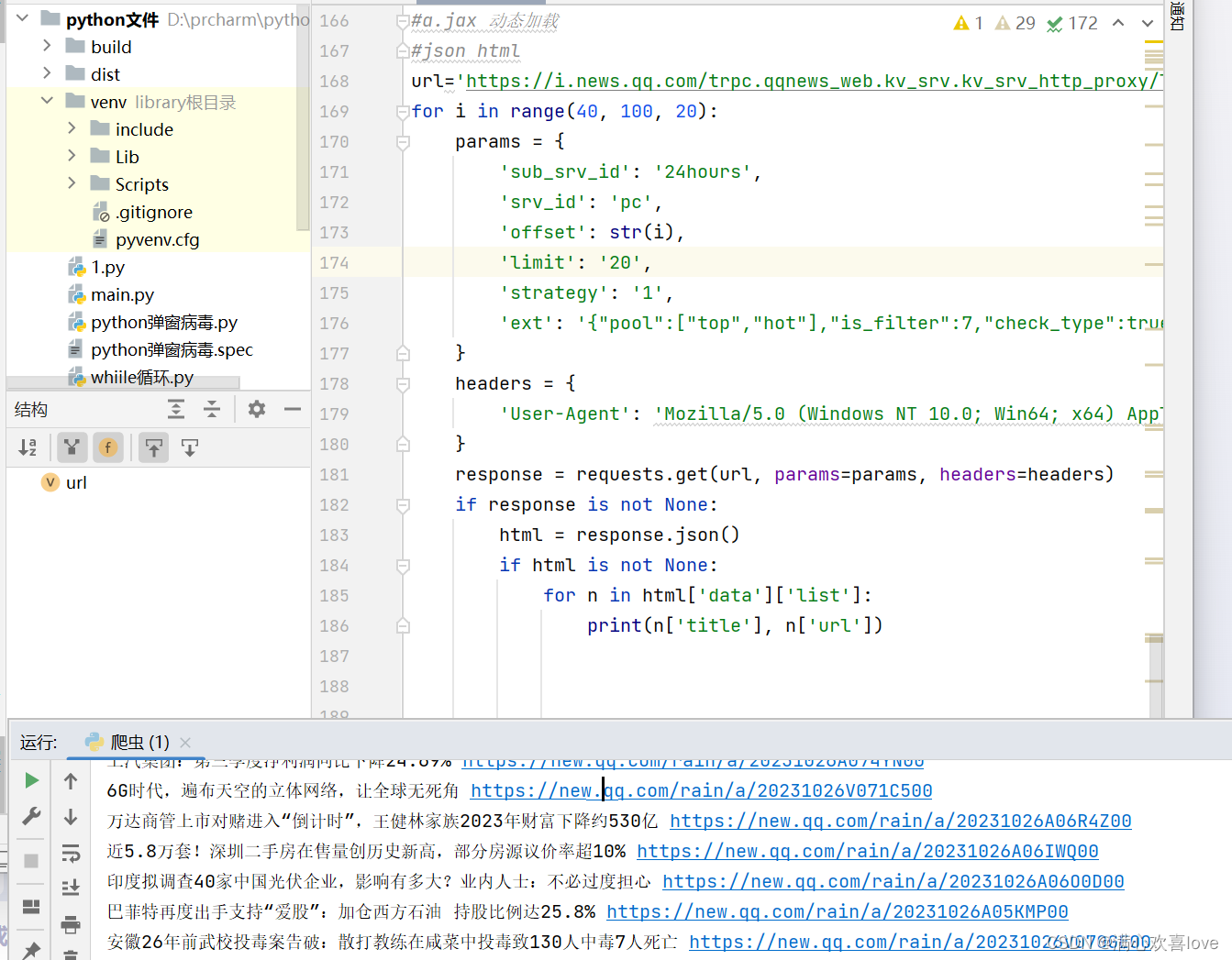
爬取成功
十一、图怪兽图片爬取

首先查看网页源代码,如果图片文件跳转链接就在前端那我们就不需要抓包了
具体方法就是用左上角的检查按钮检查一个图片,将url复制到网页源代码看看有没有


这里是有的,那咱们就不需要抓包了
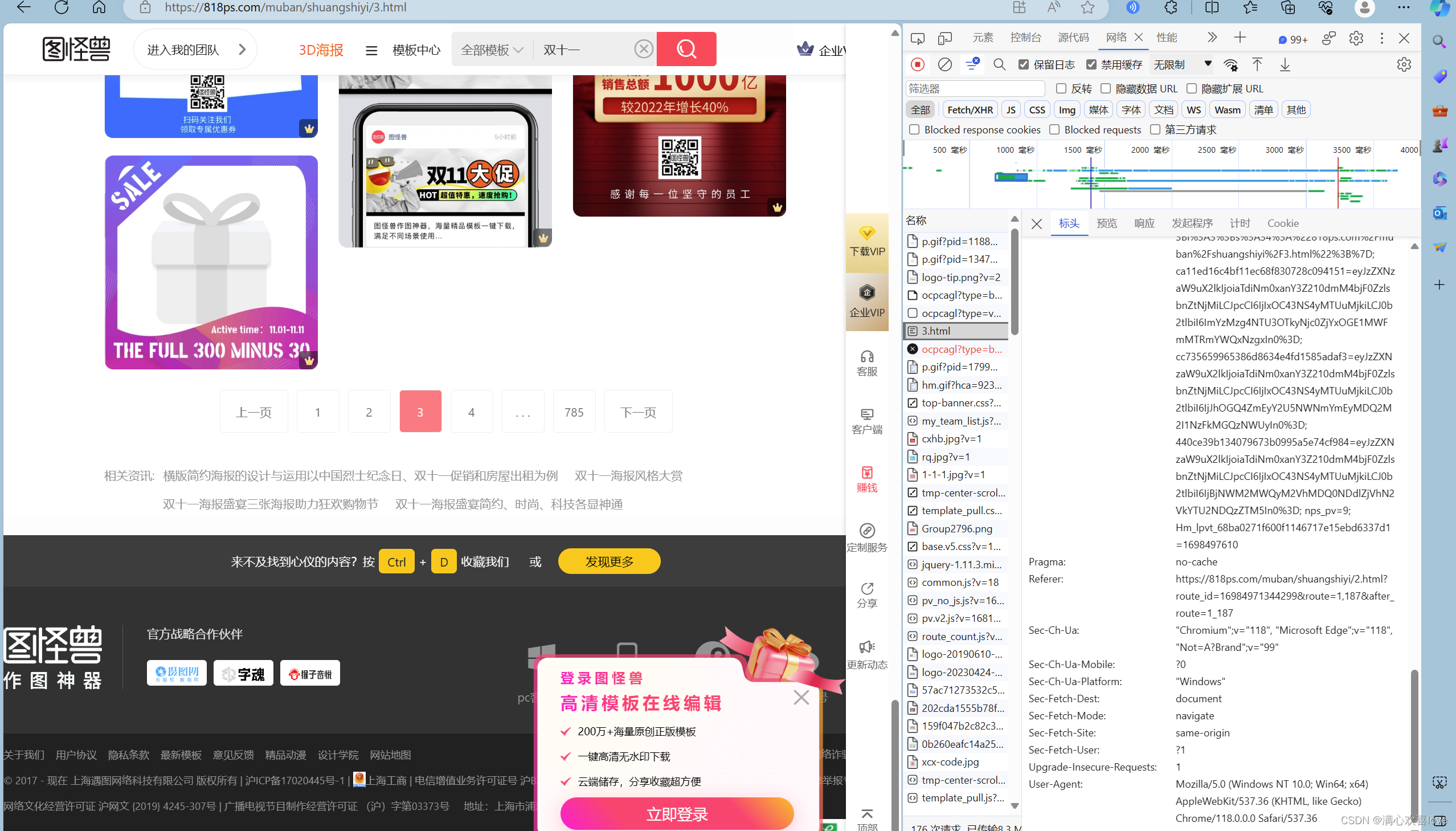
我们要找到正确的网络包,这样才能找到正确的标头,不然请求会不成功

文本成功爬取
接下来配合使用之前的css语法
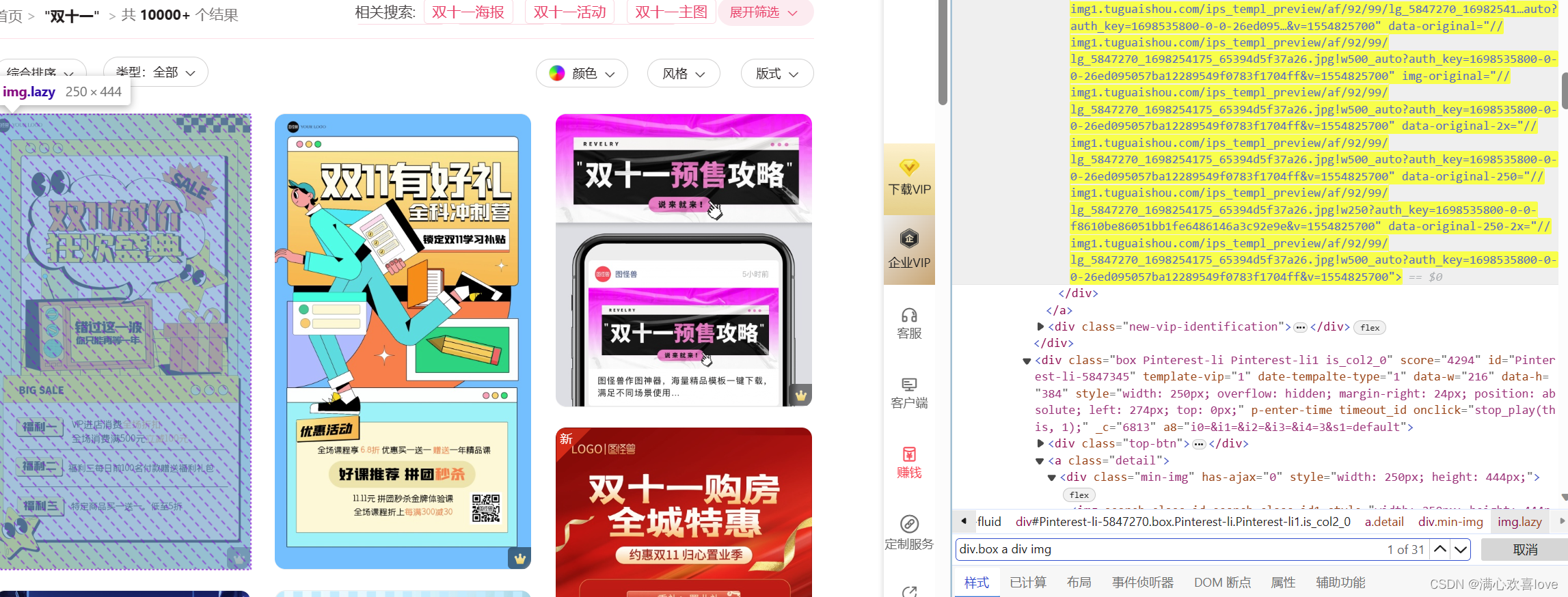
这里试了很久css语法,发现src返回不了正确的url,返回的是https://js.tuguaishou.com/img/i.png,换了一个参数才返回出来


但我这个是不正确的

这样才是正确的
os库批量下载图片
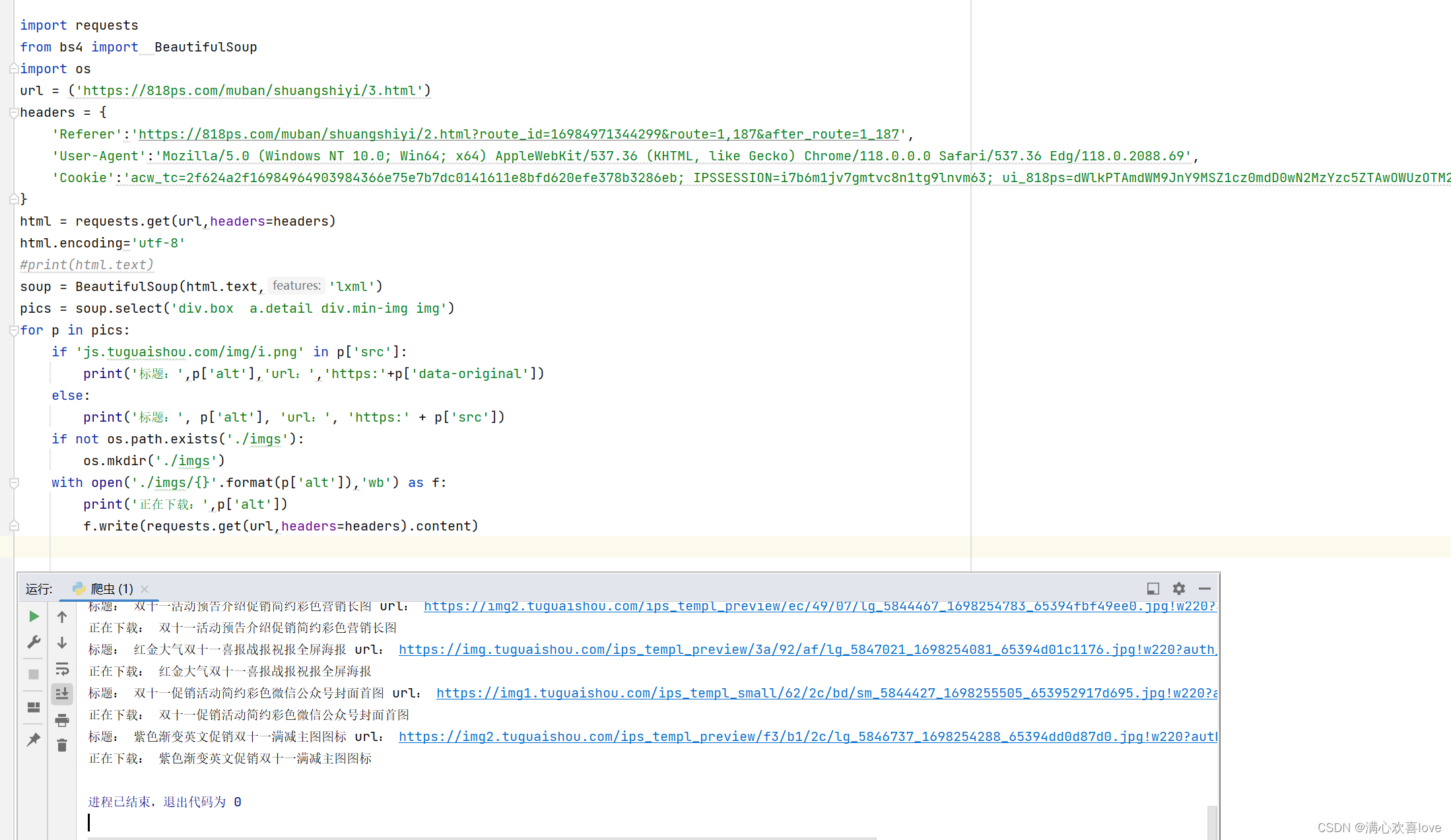
但是下完之后发现无法识别


在这里加个后缀即可

import requests
from bs4 import BeautifulSoup
import os
url = ('https://818ps.com/muban/shuangshiyi/3.html')
headers = {
'Referer':'https://818ps.com/muban/shuangshiyi/2.html?route_id=16984971344299&route=1,187&after_route=1_187',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.69',
'Cookie':'acw_tc=2f624a2f16984964903984366e75e7b7dc0141611e8bfd620efe378b3286eb; IPSSESSION=i7b6m1jv7gmtvc8n1tg9lnvm63; ui_818ps=dWlkPTAmdWM9JnY9MSZ1cz0mdD0wN2MzYzc5ZTAwOWUzOTM2OWVjMzgxNmY3OTJmYWEwMTE2OTg0OTY0OTAuNDU2NTc2MjQ2JmdyPUdSQVlfUkVMRUFTRSZ1cnM9; track_id=dae31d13b466e7402cde2870659e04a02bba61b84a6ad7daf423674f46f15d66a%3A2%3A%7Bi%3A0%3Bs%3A8%3A%22track_id%22%3Bi%3A1%3Bs%3A52%3A%2207c3c79e009e39369ec3816f792faa011698496490.456576246%22%3B%7D; _csrf=2fb21c14b1ea353a05badc9c2acff9ab338d85f3e4892b4da1839d83c6b25a1ca%3A2%3A%7Bi%3A0%3Bs%3A5%3A%22_csrf%22%3Bi%3A1%3Bs%3A32%3A%22%3A%26xn%C3%8Bz%D2%C9%CDm%C7%E0jnNj3q%A8%DA%D6Q%14%3Cf%E53%B6%2B%C2Q%22%3B%7D; AGL_USER_ID=d5806d65-a2f7-467c-9156-6173e99ea0d2; FIRSTVISITED=1698496493.057; Hm_lvt_68ba0271f600f1146717e15ebd6337d1=1698496493; 1152_cookie=a%3A4%3A%7Bi%3A0%3Bs%3A10%3A%22818ps.com%2F%22%3Bi%3A1%3Bs%3A32%3A%22818ps.com%2Fmuban%2Fshuangshiyi.html%22%3Bi%3A2%3Bs%3A34%3A%22818ps.com%2Fmuban%2Fshuangshiyi%2F2.html%22%3Bi%3A3%3Bs%3A34%3A%22818ps.com%2Fmuban%2Fshuangshiyi%2F3.html%22%3B%7D; ca11ed16c4bf11ec68f830728c094151=eyJzZXNzaW9uX2lkIjoiaTdiNm0xanY3Z210dmM4bjF0ZzlsbnZtNjMiLCJpcCI6IjIxOC43NS4yMTUuMjkiLCJ0b2tlbiI6ImYzMzg4NTU3OTkyNjc0ZjYxOGE1MWFmMTRmYWQxNzgxIn0%3D; cc735659965386d8634e4fd1585adaf3=eyJzZXNzaW9uX2lkIjoiaTdiNm0xanY3Z210dmM4bjF0ZzlsbnZtNjMiLCJpcCI6IjIxOC43NS4yMTUuMjkiLCJ0b2tlbiI6IjJhOGQ4ZmEyY2U5NWNmYmEyMDQ2M2I1NzFkMGQzNWUyIn0%3D; 440ce39b134079673b0995a5e74cf984=eyJzZXNzaW9uX2lkIjoiaTdiNm0xanY3Z210dmM4bjF0ZzlsbnZtNjMiLCJpcCI6IjIxOC43NS4yMTUuMjkiLCJ0b2tlbiI6IjBjNWM2MWQyM2VhMDQ0NDdlZjVhN2VkYTU2NDQzZTM5In0%3D; nps_pv=9; Hm_lpvt_68ba0271f600f1146717e15ebd6337d1=1698497610'
}
html = requests.get(url,headers=headers)
html.encoding='utf-8'
#print(html.text)
soup = BeautifulSoup(html.text,'lxml')
pics = soup.select('div.box a.detail div.min-img img')
for p in pics:
if 'js.tuguaishou.com/img/i.png' in p['src']:
print('标题:',p['alt'],'url:','https:'+p['data-original'])
else:
print('标题:', p['alt'], 'url:', 'https:' + p['src'])
if not os.path.exists('./imgs'):
os.mkdir('./imgs')
with open('./imgs/{}.jpg'.format(p['alt']),'wb') as f:
print('正在下载:',p['alt'])
f.write(requests.get(url,headers=headers).content)
十二、字体反爬硬解

实例网站

还是先用css语法找到字体所在位置
抓一下包,发现页面就在包里面

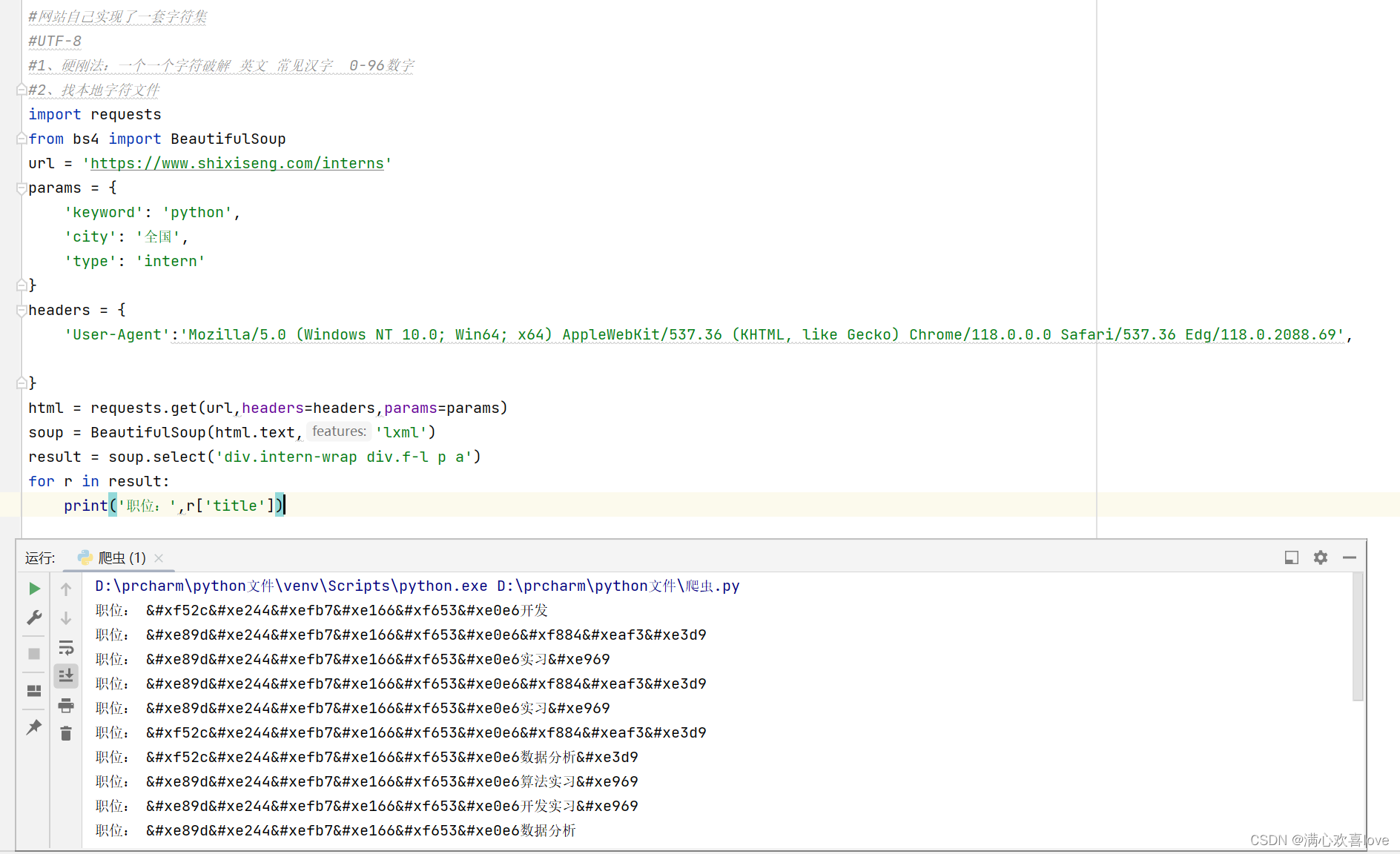
直接爬取,发现全是乱码

我们换一种,取title不取文本
每一个连接符&和#后就是一个字符
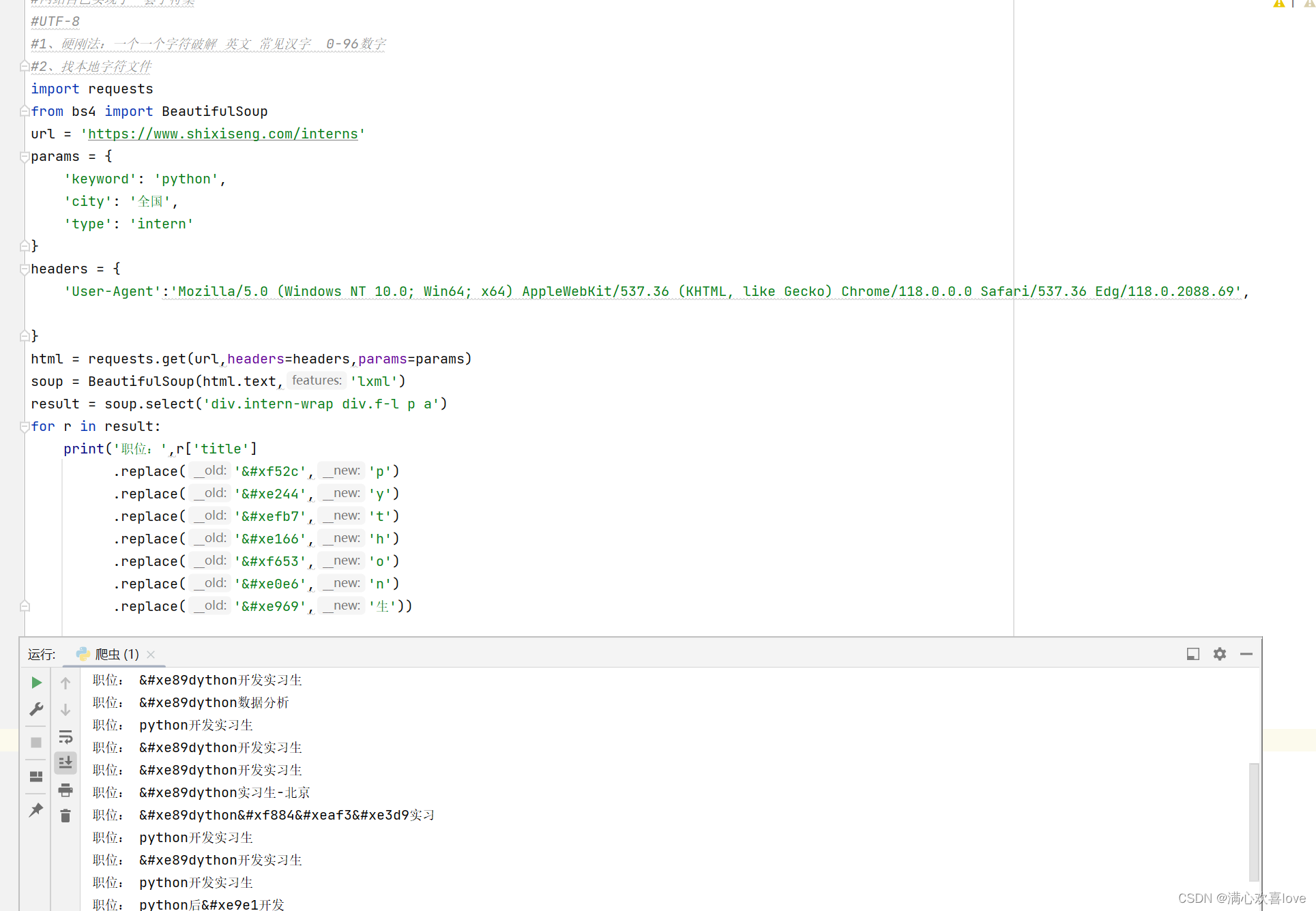
硬刚法大致就是这样,太多了我就不弄完了
十三、字体反爬找文件
上一节的硬解法,太麻烦要一个一个解,效率不高

检查,样式中font就是字体的意思
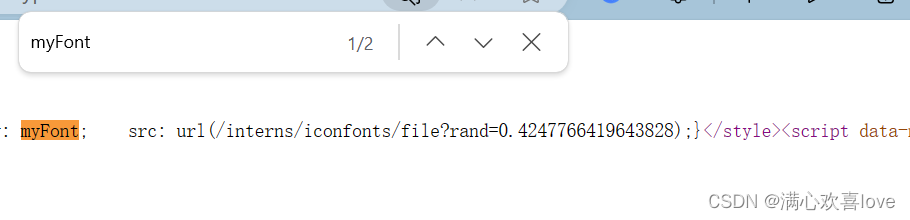
搜一下,直接有个src url

主站域名加上这个url直接就下载下来这个字体文件了,但是这个字体文件还是看不了的,是乱码,需要特殊的软件查看比如说fontcreator


这里面的东西也不算多
这里需要下载一个fontTools库,如果下载太慢也可以用国内源
pip install fontTools -i https://pypi.tuna.tsinghua.edu.cn/simple
import requests
from bs4 import BeautifulSoup
import re
# 下载字体
myFont = requests.get('https://www.shixiseng.com/interns/iconfonts/file?rand=0.4247766419643828')
with open('file.ttf', 'wb') as f:
f.write(myFont.content)
from fontTools.ttLib import TTFont
font = TTFont('./file.ttf')
font.saveXML('font.xml')
# 获取对应关系
bestcmap = font['cmap'].getBestCmap()
print(bestcmap)
newDict = {}
for k, v in bestcmap.items():
print(hex(k), v)
newDict[hex(k)] = v
# 获取所有字体头
fontNames = font.getGlyphOrder()
print(fontNames)
fontNameDict = {
'uni70': 'p',
'uni50': 'P',
'uni30': '1',
'uni70':'y'
}
# 绕过反爬虫限制,使用正则表达式替换特殊字符
def replace_special_chars(text):
special_chars = ['\u4e00', '\u3002', '\u3001', '\u301c', '\uff5e'] # 特殊字符列表,根据需要自行添加
for char in special_chars:
text = text.replace(char, '') # 删除特殊字符
return text
# 爬取网页内容并替换特殊字符
url = 'https://www.shixiseng.com/interns'
params = {
'keyword': 'python',
'city': '全国',
'type': 'intern'
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.69',
}
html = requests.get(url, headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
result = soup.select('div.intern-wrap div.f-l p a')
for r in result:
title_text = r['title'].replace('&#', '0') # 获取标题文本并删除HTML实体编码
title_text = replace_special_chars(title_text) # 替换特殊字符为正常文本
print(title_text) # 输出处理后的标题文本
这个大工程太累了
十四、酷狗音乐下载

首先看看mp3在不在源代码里面,但是很显然这种大型音乐网站肯定是不在前端的。
直接加入音乐页面,自动播放,说明这个mp3肯定在这个页面里面
抓包
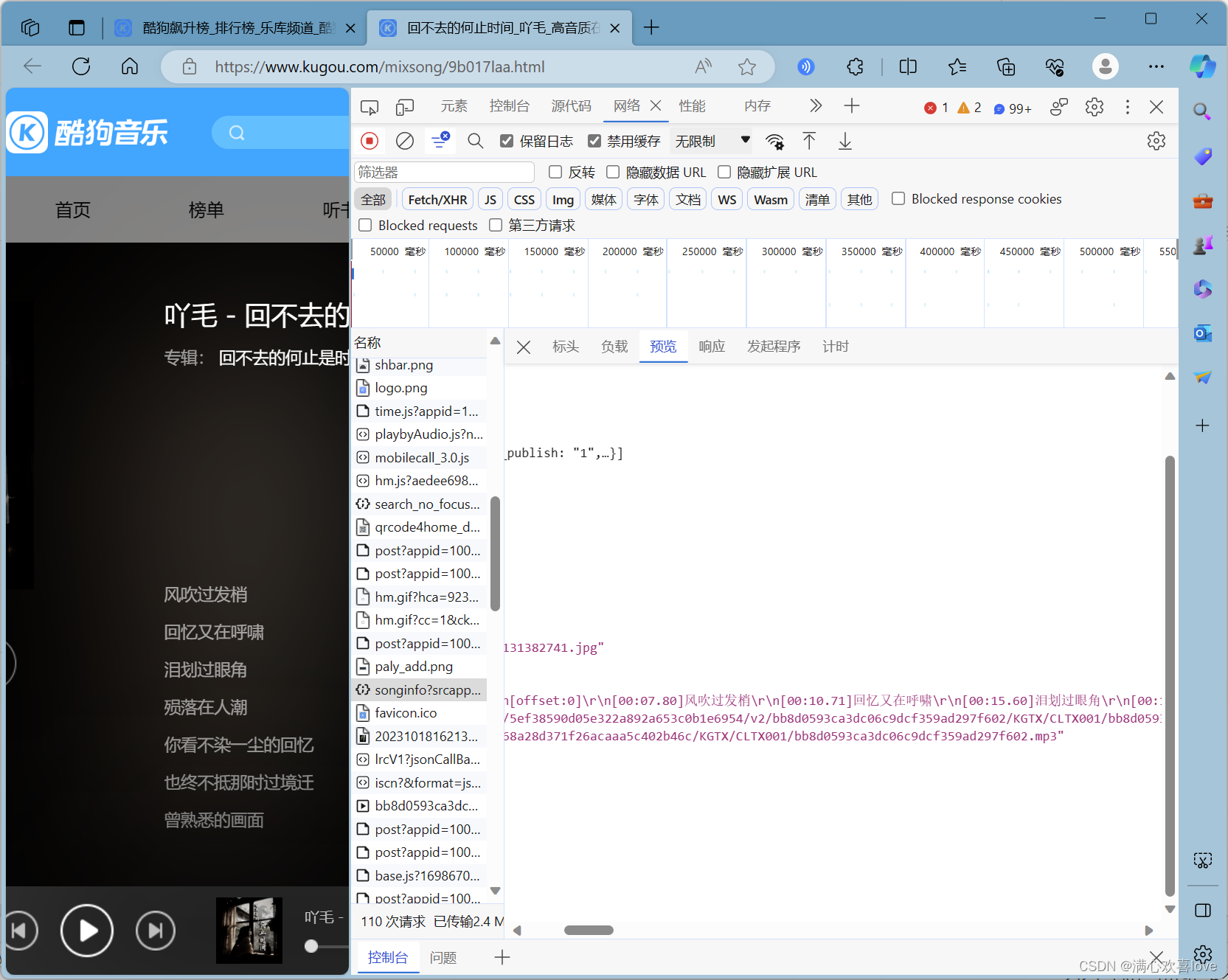
从后往前看包,发现mp3

就是这个play_url
打开这个url

可播放可下载
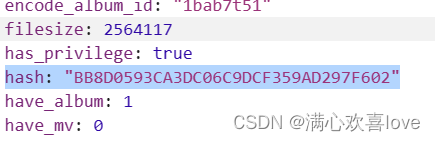
这里有一个很重要的东西,hash哈希值在预览里不在负载参数里

全局搜索一下hash
一个一个看

这个hash在这个windos.location里面

在控制台中输入window,这是个浏览器自带的一个属性

在控制台输入window.location,是些url的相关部分


在榜单页面查看源代码搜索hash
接下来只需要用正则将hash弄出来就好了,因为数据在json中

这个hash已经成功弄出来了,一首音乐一个hash
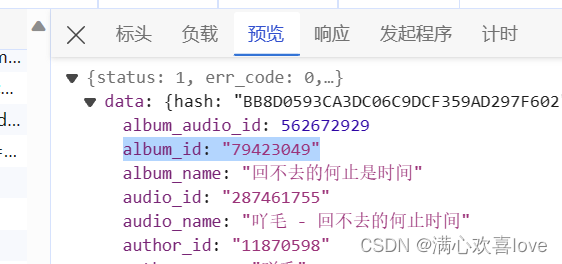
这个album_id跟hash一样也很重要
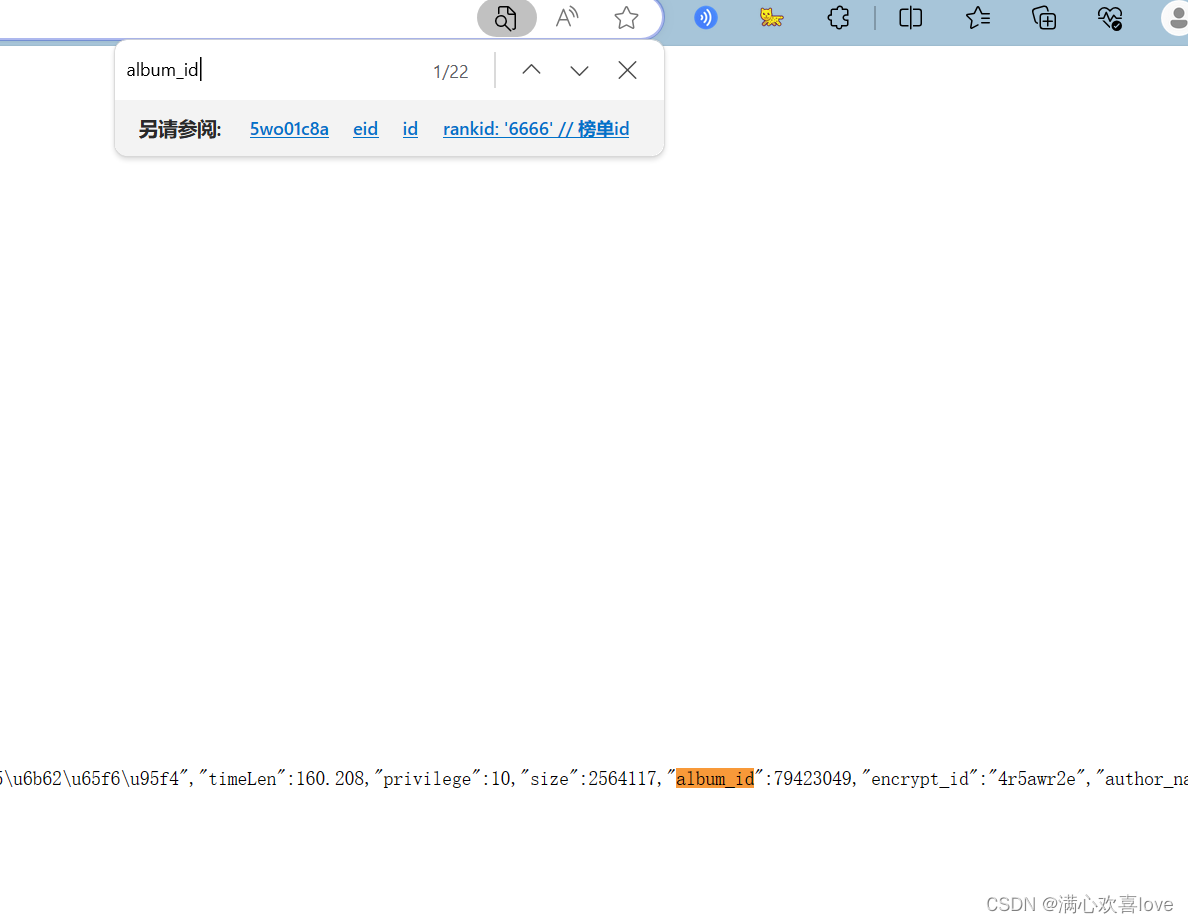
跟hashi一样在json中


代码中的r:play/getdata 是调用后端接口
一番苦战终于搞定了。

















 1920
1920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}