







Scrapy介绍
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。
Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
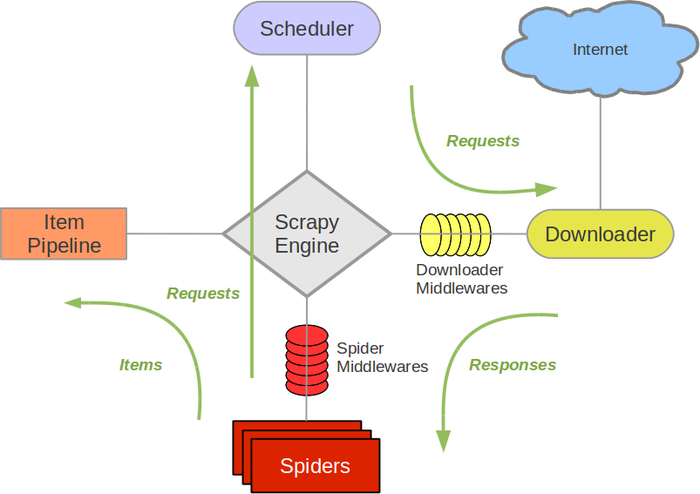
- Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scrapy的运作流程
-
Engine 首先打开一个网站,找到处理该网站的 Spider 并向该 Spider 请求第一个要爬取的 URL。
-
Engine 从 Spider 中获取到第一个要爬取的 URL 并通过 Scheduler 以 Request 的形式调度。
-
Engine 向 Scheduler 请求下一个要爬取的 URL。
-
Scheduler 返回下一个要爬取的 URL 给 Engine,Engine 将 URL 通过 Downloader Middlewares 转发给 Downloader 下载。
-
一旦页面下载完毕, Downloader 生成一个该页面的 Response,并将其通过 Downloader Middlewares 发送给 Engine。
-
Engine 从下载器中接收到 Response 并通过 Spider Middlewares 发送给 Spider 处理。
-
Spider 处理 Response 并返回爬取到的 Item 及新的 Request 给 Engine。
-
Engine 将 Spider 返回的 Item 给 Item Pipeline,将新的 Request 给 Scheduler。
重复第二步到最后一步,直到 Scheduler 中没有更多的 Request,Engine 关闭该网站,爬取结束。
通过多个组件的相互协作、不同组件完成工作的不同、组件对异步处理的支持,Scrapy 最大限度地利用了网络带宽,大大提高了数据爬取和处理的效率。
制作Scrapy步骤
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
微博数据获取
在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
scrapy startproject weibo
其中, weibo 为项目名称,可以看到将会创建一个 weibo文件夹,目录结构大致如下:
下面来简单介绍一下各个主要文件的作用:
weibo/
scrapy.cfg
weibo/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
- scrapy.cfg: 项目的配置文件。
- weibo/: 项目的Python模块,将会从这里引用代码。
- weibo/items.py: 项目的目标文件。
- weibo/pipelines.py: 项目的管道文件。
- weibo/settings.py: 项目的设置文件。
- weibo/spiders/: 存储爬虫代码目录。
我们打算抓取 微博搜索 (weibo.com) 网站里的发布相关的文章信息
- 打开 mySpider 目录下的 items.py。
- Item 定义结构化数据字段,用来保存爬取到的数据,有点像 Python 中的 dict,但是提供了一些额外的保护减少错误。
- 可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field 的类属性来定义一个 Item(可以理解成类似于 ORM 的映射关系)。
接下来,创建一个 ItcastItem 类,和构建 item 模型(model)。
import scrapy
class WeiboItem(scrapy.Item):
author=scrapy.Field() # 作者
content=scrapy.Field() # 内容
time=scrapy.Field() # 时间
comment_num=scrapy.Field() # 评论数
like_num=scrapy.Field() # 点赞数
transfer_num=scrapy.Field() # 转发数
在当前目录下输入命令,将在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
scrapy genspider startweibo "weibo.com"
在Settings.py文件下进行设置
ROBOTSTXT_OBEY = False表示不遵守 robots.txt 规则。这样,爬虫可以抓取网站上所有的内容,即使网站的 robots.txt 文件明确指出不允许抓取某些页面。
COOKIES_ENABLED = False表示禁用 Cookies。Cookies 是网站存储在用户浏览器中的信息,用于跟踪用户会话状态。禁用 Cookies 后,爬虫每次发送请求时不会携带 Cookies,这可能导致无法模拟登录或保持会话状态。
TELNETCONSOLE_ENABLED = False表示禁用 Telnet 控制台。禁用此功能可以减少爬虫运行时的安全风险,因为 Telnet 控制台可能允许未经授权的用户访问爬虫的内部状态。
DEFAULT_REQUEST_HEADERS定义了爬虫在发送 HTTP 请求时使用的默认请求头。请求头是发送给服务器的附加信息,用于告诉服务器请求的具体细节,比如客户端的类型、支持的内容格式等。
LOG_LEVEL = "WARNING"表示只记录警告级别及以上的日志(即警告、错误和关键错误)。这样可以减少日志的冗余信息,只关注爬虫运行中的潜在问题。
ROBOTSTXT_OBEY = False
COOKIES_ENABLED = False
TELNETCONSOLE_ENABLED = False
DEFAULT_REQUEST_HEADERS = {
# ":authority:":"s.weibo.com",
# ":method:":"GET",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Cookie":"PC_TOKEN=2350ead6e7; SCF=ArqZ1DQL1HunpdT3ZtRq2g2Epwt60MMtvuz0A4nyYbylR9q7IbFqBd6lFikO9FrjAtfE39YYKvCkvRwdcUY45fQ.; _s_tentry=passport.weibo.com; Apache=5895479271617.783.1723172196026; SINAGLOBAL=5895479271617.783.1723172196026; ULV=1723172196034:1:1:1:5895479271617.783.1723172196026:; SUB=_2A25LsfsjDeRhGeFJ7VAZ-SrMzD6IHXVoz3LrrDV8PUNbmtANLWPZkW9Nf2-TIxbmT3ceouPvtHVYTTVe5eG9HUcE; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5yePZkAF3_AJczE0Q9Cmh.5NHD95QNS0qE1h.XehMEWs4DqcjGgHv2dc4rw5tt; ALF=02_1725765747",
}
LOG_LEVEL = "WARNING"
打开 mySpider/spider目录里的 itcast.py,默认增加了下列代码:
import scrapy
from ..items import WeiboItem
count_page=0
class StartweiboSpider(scrapy.Spider):
name = "startweibo"
allowed_domains = ["weibo.com"]
start_urls = ["https://s.weibo.com/weibo?q=%E8%94%A1%E5%BE%90%E5%9D%A4&page=1"]
def parse(self, response):
其实也可以由我们自行创建startweibo.py并编写上面的代码,只不过使用命令可以免去编写固定代码的麻烦
要建立一个Spider, 你必须用scrapy.Spider类创建一个子类,并确定了三个强制的属性 和 一个方法。
name = “” :这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。
allow_domains = [] 是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。
start_urls = [] :爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
parse(self, response) :解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item)
生成需要下一页的URL请求。
将start_urls的值修改为需要爬取的第一个url
start_urls = ("https://s.weibo.com/weibo?q=蔡徐坤&page=1",)
修改parse()方法
div=response.xpath(): 使用 xpath 从 response 中提取所有具有 card 类的 <div> 元素。
'//div[@class="card"]': 是一个 XPath 表达式,选择页面中所有类名为 card 的 <div> 元素,这些通常代表每个微博内容的容器。
for i in range(len(div)):: 遍历所有提取到的 div 元素。div 是一个包含多个微博卡片的列表。
'./div[1]/div[2]/div[1]/div[2]/a/text()': 定位作者名称的 XPath 路径,提取 <a> 标签中的文本内容。
extract_first(): 提取第一个匹配的文本内容,如果不存在则返回 None。
itme=WeiboItem(): 创建一个 WeiboItem 实例,将提取到的数据传递给它的字段。
yield itme: 返回这个数据项给 Scrapy 框架,进行进一步处理(如存储或传递给下一个管道)。
yield scrapy.Request(next_url, callback=self.parse): 如果存在下一页,发起一个新的请求,继续抓取下一页内容,并指定 parse 函数作为回调函数处理新的响应。
def parse(self, response):
div=response.xpath('//div[@class="card"]')
for i in range(len(div)):
author=div[i].xpath('./div[1]/div[2]/div[1]/div[2]/a/text()').extract_first()
time=div[i].xpath('./div[@class="card-feed"]/div[@class="content"]/div[@class="from"]/a[1]/text()').extract_first()
content=div[i].xpath('./div[@class="card-feed"]/div[@class="content"]/p/text()').extract()
transfer_num=div[i].xpath('./div[@class="card-act"]/ul[1]/li[1]/a/text()').extract()
comment_num=div[i].xpath('./div[@class="card-act"]/ul[1]/li[2]/a/text()').extract()
like_num=div[i].xpath('./div[@class="card-act"]/ul[1]/li[3]/a/button/span[2]/text()').extract()
itme=WeiboItem(author=author,time=time,content=content,transfer_num=transfer_num,comment_num=comment_num,like_num=like_num)
yield itme
global count_page
count_page+=1
print("已获取第"+str(count_page)+"页数据")
next_url="https://s.weibo.com"+response.xpath('//a[@class="next"]/@href').extract_first()
if next_url:
yield scrapy.Request(next_url,callback=self.parse)
然后运行一下看看,在mySpider目录下执行:
scrapy crawl startweibo
编写pipelines文件,同时进行清晰
from itemadapter import ItemAdapter
import csv
import os
class WeiboPipeline:
def __init__(self) -> None:
self.file_path="weibo.csv"
self.f=open(self.file_path,'w',encoding='utf-8',newline='')
self.file_name=["author","time","content","transfer_num","comment_num","like_num"]
self.writer=csv.DictWriter(self.f,self.file_name)
self.writer.writeheader()
def process_item(self, item, spider):
item["time"]=item["time"].replace('\n','').replace('\r','').replace('\t','').replace(' ','')
item["content"]=''.join(item["content"]).replace('\n','').replace('\r','').replace('\t','').replace(' ','')
item["transfer_num"]=''.join(item["transfer_num"]).replace('\n','').replace('\r','').replace('\t','').replace(' ','')
item["comment_num"]=''.join(item["comment_num"]).replace('\n','').replace('\r','').replace('\t','').replace(' ','')
item["like_num"]=''.join(item["like_num"]).replace('\n','').replace('\r','').replace('\t','').replace(' ','')
if item["transfer_num"]=="转发":
item["transfer_num"]="0"
if item["comment_num"]=="评论":
item["comment_num"]="0"
if item["like_num"]=="赞":
item["like_num"]="0"
self.writer.writerow(item)
return item
def close_spider(self,spider):
self.f.close()
settings启动pipelines
ITEM_PIPELINES = {
"weibo.pipelines.WeiboPipeline": 300,
}
执行爬虫
scrapy crawl startweibo

绘制词云
导入要用的库
import pandas as pd
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import PIL.Image as image
import numpy as np
import jieba
import re
from wordcloud import ImageColorGenerator
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
读取数据
data=pd.read_csv("weibo/weibo.csv")
data["content"]
自定义停用词表
# 自定义停用词列表
stopwords = set([
"的", "是", "在", "和", "了", "我", "有", "这", "一个", "也", "很", "人", "都", "等", "我们", "你","他"
# 添加更多的停用词...
])
绘制词云并显示
text = ' '.join(list(data["content"]))
# 使用正则表达式去除非法字符,只保留中文字符、字母和数字
text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9\s]', '', text)
words = jieba.cut(text)
filtered_words = [word for word in words if word not in stopwords]
segmented_text = ' '.join(filtered_words)
bg_pic=image.open("mask.png")
bg_pic=np.array(bg_pic)
wordcloud = WordCloud(background_color="white",font_path='c:\windows\Fonts\simhei.ttf',mask=bg_pic,scale=15)
wordcloud.generate(segmented_text)
image_color = ImageColorGenerator(bg_pic)# 提取图片的色彩分布
a = wordcloud.recolor(color_func = image_color)
plt.figure(figsize=(10, 5))
plt.imshow(a, interpolation='bilinear')
plt.axis('off')
plt.show()

创作不易,关注GZH【阿欣Python与机器学习】,发送【爬虫】获得数据及代码,欢迎关注,共同讨论,共同进步。















 3183
3183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









