






Ajax介绍
Ajax,全称为 Asynchronous JavaScript and XML,即异步的 JavaScript 和 XML。它不是一门编程语言,而是利用 JavaScript 在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。
对于传统的网页,如果想更新其内容,那么必须要刷新整个页面,但有了 Ajax,便可以在页面不被全部刷新的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行了数据交互,获取到数据之后,再利用 JavaScript 改变网页,这样网页内容就会更新了。
基础原理
初步了解了 Ajax 之后,我们再来详细了解它的基本原理。发送 Ajax 请求到网页更新的这个过程可以简单分为以下 3 步:
1、发送请求
2、解析内容
3、渲染网页
这 3 个步骤其实都是由 JavaScript 完成的,它完成了整个请求、解析和渲染的过程 。
Ajax分析
查看请求,我们使用Edge浏览器进入,搜索小猫图片的页面:https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=&st=-1&fm=result&fr=&sf=1&fmq=1722912244742_R&pv=&ic=0&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&dyTabStr=&ie=utf-8&sid=&word=%E5%B0%8F%E7%8C%AB 打开开发者工具,打开Network,勾选XHR其中Ajax请求一般的类型便是xhr,然后刷新页面,可以看到如下请求:

点击预览,可以查看到请求返回的一些参数,其中便包含图片的URL地址

到现在为止,我们已经可以分析出 Ajax 请求的一些详细信息了,接下来只需要用程序模拟这些 Ajax 请求,就可以轻松提取我们所需要的信息了。
设置请求参数
在用程序发送请求的过程中,我们尽量把程序模拟的像人在操作,这样被网站拦截的几率大大降低。
第一步设置请求头,我们所设置的参数,均来自,分析ajax请求时所发送的参数。
设置请求头

# 导入所需库
import requests
# 设置请求头
headers = {
'Connection': 'keep-alive',
'sec-ch-ua': '"Not)A;Brand";v="99", "Microsoft Edge";v="127", "Chromium";v="127"',
'Accept': 'text/plain, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua-mobile': '?0',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0',
'sec-ch-ua-platform': '"Windows"',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=&st=-1&fm=result&fr=&sf=1&fmq=1722912244742_R&pv=&ic=0&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&dyTabStr=&ie=utf-8&sid=&word=%E5%B0%8F%E7%8C%AB',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',
}
设置cookie
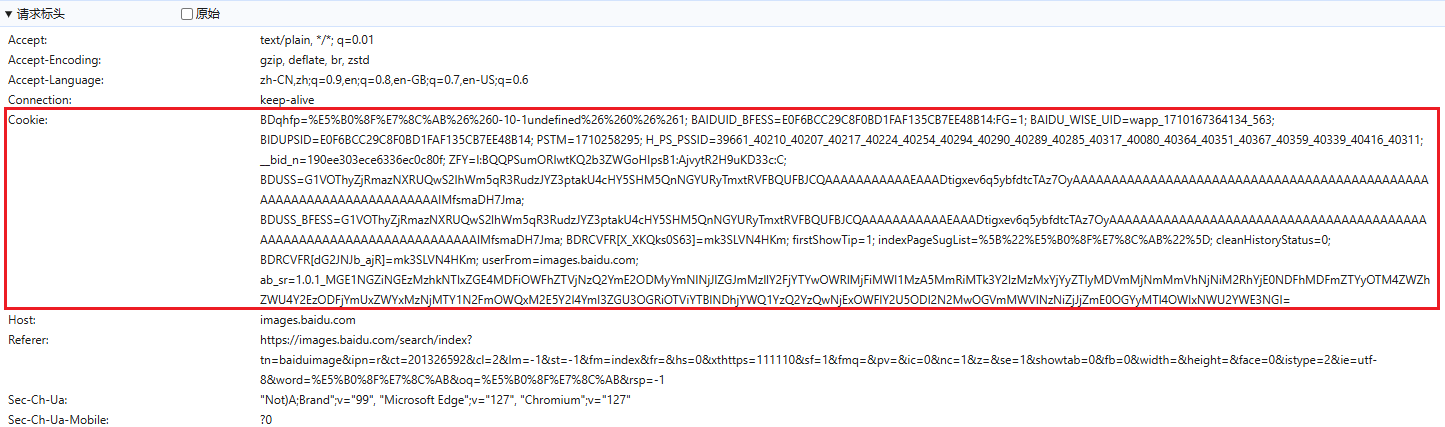
既然是给网站后端发送请求,那必然要携带一些参数。因此需要在设置一下param

设置请求参数,请发送请求
# 设置请求参数
keywords="小猫"
page=30
params=(
('tn','resultjson_com'),
('logid','11415579644838063109'),
('ipn','rj'),
('ct','201326592'),
('is',''),
('fp','result'),
('fr',''),
('word',f'{keywords}'),
('queryWord',f'{keywords}'),
('cl','2'),
('lm',''),
('ie','utf-8'),
('oe','utf-8'),
('adpicid',''),
('st','-1'),
('z',''),
('ic','0'),
('hd',''),
('latest',''),
('copyright',''),
('s',''),
('se',''),
('tab',''),
('width',''),
('height',''),
('face','0'),
('istype','2'),
('qc',''),
('nc','1'),
('expermode',''),
('nojc',''),
('isAsync',''),
('pn',f'{page}'),
('rn','30'),
('gsm','5a'),
('1722915752936',''),
)
response = requests.get('https://image.baidu.com/search/acjson', headers=headers, params=params, cookies=cookies)
if response.status_code == 200:
print(response.text)
成功获取了当前页的数据,接下来我们只需要更换page参数,便可以获得该关键词下的所有参数。

封装为函数循环爬取
函数会根据关键词进行爬取,并且设置了爬取图片个数限制。
import os
from tqdm import tqdm
import time
import warnings
warnings.filterwarnings("ignore")
def craw_single_keyword(keyword,download_num=200):
if os.path.exists("Img/"+keyword):
print("文件夹{}已存在,爬取的图片将保存在该文件夹中".format(keyword))
else:
os.mkdir("Img/{}".format(keyword))
count=1
with tqdm(total=download_num, position=0, leave=True) as pbar:
num=0
flag=True
while flag:
page=30*count
params=(
('tn','resultjson_com'),
('logid','11415579644838063109'),
('ipn','rj'),
('ct','201326592'),
('is',''),
('fp','result'),
('fr',''),
('word',f'{keyword}'),
('queryWord',f'{keyword}'),
('cl','2'),
('lm',''),
('ie','utf-8'),
('oe','utf-8'),
('adpicid',''),
('st','-1'),
('z',''),
('ic','0'),
('hd',''),
('latest',''),
('copyright',''),
('s',''),
('se',''),
('tab',''),
('width',''),
('height',''),
('face','0'),
('istype','2'),
('qc',''),
('nc','1'),
('expermode',''),
('nojc',''),
('isAsync',''),
('pn',f'{page}'),
('rn','30'),
('gsm','5a'),
('1722915752936',''),
)
response = requests.get('https://image.baidu.com/search/acjson', headers=headers, params=params, cookies=cookies)
if response.status_code == 200:
json_data = response.json().get("data")
if json_data:
for x in json_data:
type = x.get("type")
if type not in ["gif"]:
img = x.get("thumbURL")
fromPageTitleEnc = x.get("fromPageTitleEnc")
try:
resp = requests.get(url=img, verify=False)
time.sleep(1)
file_save_path = f'Img/{keyword}/{num}.{type}'
with open(file_save_path, 'wb') as f:
f.write(resp.content)
f.flush()
num += 1
pbar.update(1) # 进度条更新
if num >= download_num:
flag = False
print('{} 张图像爬取完毕'.format(num))
break
except Exception as e:
print(e)
count+=1
检查爬取结果
执行函数
craw_single_keyword('长颈鹿', download_num = 10)

创作不易,关注GZH【阿欣python与机器学习】,发送【爬虫】获取全部代码!

欢迎交流讨论,共同进步!















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









