




 本文介绍了作者利用深度学习技术,特别是LeNet和AlexNet网络,对iChallenge-PM病理性近视数据集进行图片识别的实践。通过对比,发现AlexNet在防止过拟合和提高识别准确性方面表现更优,达到了90%以上的识别率。
本文介绍了作者利用深度学习技术,特别是LeNet和AlexNet网络,对iChallenge-PM病理性近视数据集进行图片识别的实践。通过对比,发现AlexNet在防止过拟合和提高识别准确性方面表现更优,达到了90%以上的识别率。
写在前面: 我是「虐猫人薛定谔i」,一个不满足于现状,有梦想,有追求的00后
\quad
本博客主要记录和分享自己毕生所学的知识,欢迎关注,第一时间获取更新。
\quad
不忘初心,方得始终。
\quad❤❤❤❤❤❤❤❤❤❤

数据介绍
百度大脑和中山大学中山眼科中心联合举办的iChallenge比赛提供了一系列医疗类数据集, 其中有一项是关于病理性近视(Pathologic Myopia,简称:PM)疾病的,iChallenge-PM
PALM-Training400该文件夹下存放的是训练用的图片
PALM-Validation400该文件夹下存放的是验证用的图片
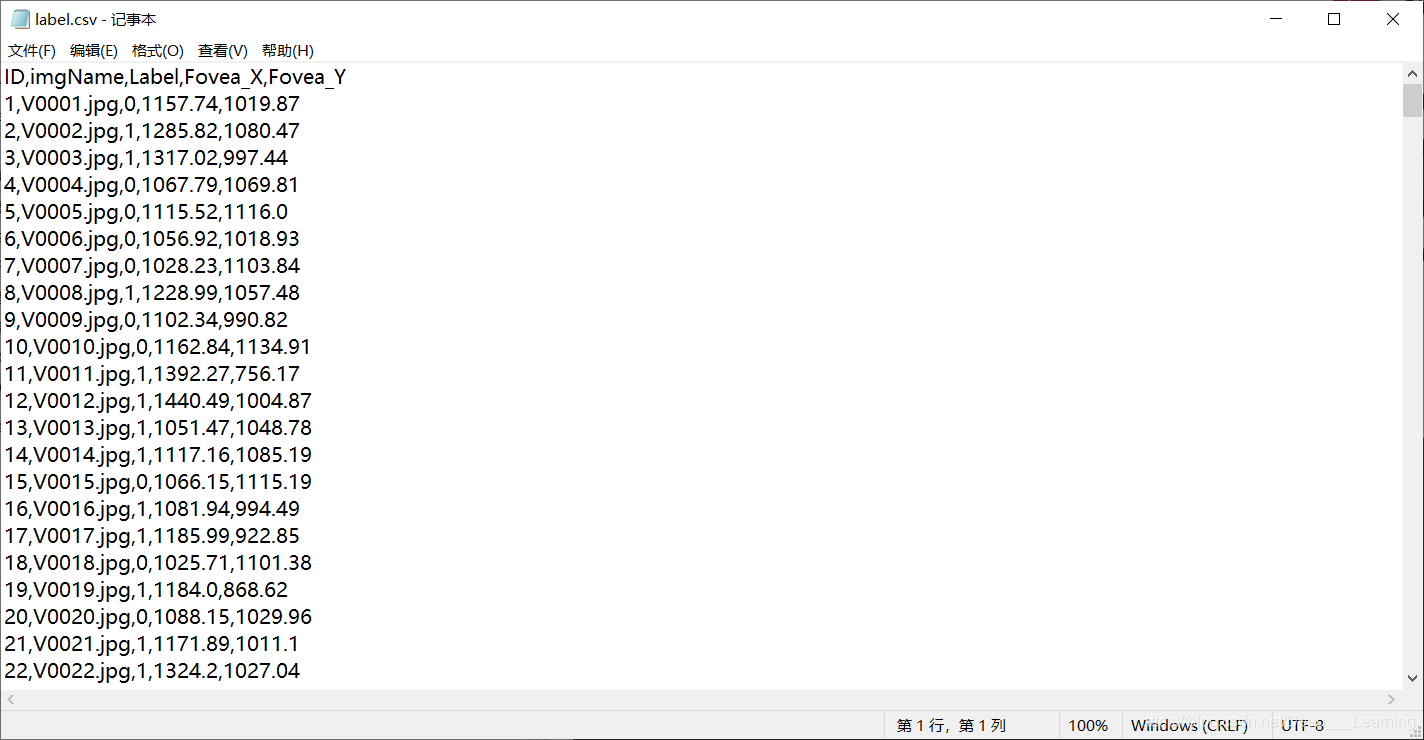
label.csv文件(处理过了,原数据集中是excel文件,我把它转成csv文件了)
代码
LeNet网络结构
# 定义LeNet的网络结构
class LeNet(fluid.dygraph.Layer):
def __init__(self, name_scope, num_classes=1):
super(LeNet, self).__init__(name_scope)
self.conv1 = Conv2D(num_channels=3,
num_filters=6,
filter_size=5,
act='sigmoid')
self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.conv2 = Conv2D(num_channels=6,
num_filters=16,
filter_size=5,
act='sigmoid')
self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.conv3 = Conv2D(num_channels=16,
num_filters=120,
filter_size=4,
act='sigmoid')
self.fc1 = Linear(input_dim=300000, output_dim=64, act='sigmoid')
self.fc2 = Linear(input_dim=64, output_dim=num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.conv3(x)
x = fluid.layers.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
x = self.fc2(x)
return x
AlexNet网络结构
# 定义AlexNet网络结构
class AlexNet(fluid.dygraph.Layer):
def __init__(self, name_scope, num_classes=1):
super(AlexNet, self).__init__(name_scope)
name_scope = self.full_name
self.conv1 = Conv2D(num_channels=3,
num_filters=96,
filter_size=11,
stride=4,
padding=5,
act='relu')
self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.conv2 = Conv2D(num_channels=96,
num_filters=256,
filter_size=5,
stride=1,
padding=2,
act='relu')
self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.conv3 = Conv2D(num_channels=256,
num_filters=384,
filter_size=3,
stride=1,
padding=1,
act='relu')
self.conv4 = Conv2D(num_channels=384,
num_filters=384,
filter_size=3,
stride=1,
padding=1,
act='relu' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 367
367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









