







深度卷积对抗神经网络 基础 第五部分 Inception-v3 architecture GANs
对抗神经网络能够产生不存在的图片,换脸或者生成一些艺术品,这些有趣和强大的对抗神经网络的能力不仅能够创造价值,还能够用来犯罪。With Great Power , Comes With Responsibility. 请使用者可以 Handle it responsibly。
Inception-v3 architecture 是一种图像识别模型,已证明在 ImageNet 数据集上的准确率超过 78.1%。该模型是多位研究人员多年来开发的许多想法的结晶。它基于原始论文: Szegedy 等人的“重新思考计算机视觉的初始架构” ,其主要用于进行图像中的物体识别,具体叫特性识别。
该模型本身由对称和非对称构建块组成,包括卷积、平均池化、最大池化、连接、dropout 和全连接层。批量归一化在整个模型中广泛使用,并应用于激活输入,使用 Softmax 计算损失。下面进行一个简单的介绍,具体请看论文。
1. 模型的评估 Evaluation
为什么评估模型非常的难? why is evaluating GANs hard?
- 判别器容易出现过拟合的状况,不存,在一个通用的可以适合所有模型的判别器。 Discriminator overfitting non gold universal discriminator
- 两个重要的模型特性需要考虑和平衡 Two important properties needed to consider and trade off:
- 保真性:指的是生成的图片以假乱真的能力 Fidelity
- 多样性:指的是生成的图片类别类型多样的能力 Diversity
比较生成图像的差别 Comparing images:
- 像素距离 pixel distances : 这种方式比较简单,但是在很多情况并不适用 not realistic in some situations
- 特征距离 feature distances : 这种方式可以比较特征之间的距离,比如说
1.1 特征提取 Feature extraction
使用一个提前训练好的特征提取器来进行初始的特征提取,并输出特征信息 Using Feature extraction using pre-trained classifiers (Extensively pre-trained classifiers available to use)
- 通过将分类器的神经网络切断,取其中的一部分来提取特征。Classifiers can be used as feature extractors by cutting the network at earlier layers
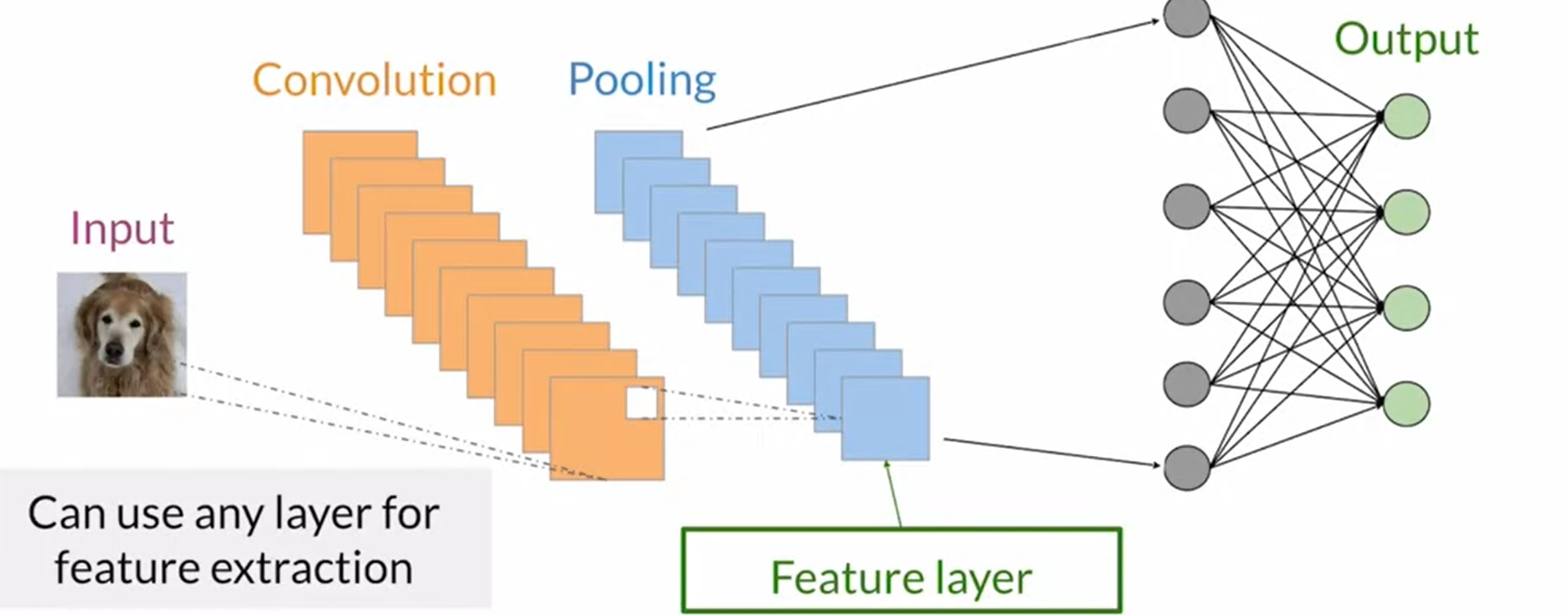
- 一般截取到池化层,因为池化层通常用来进行特征提取。The last pooling layer is most commonly used for features extraction
1.2 Inception-v3 architecture
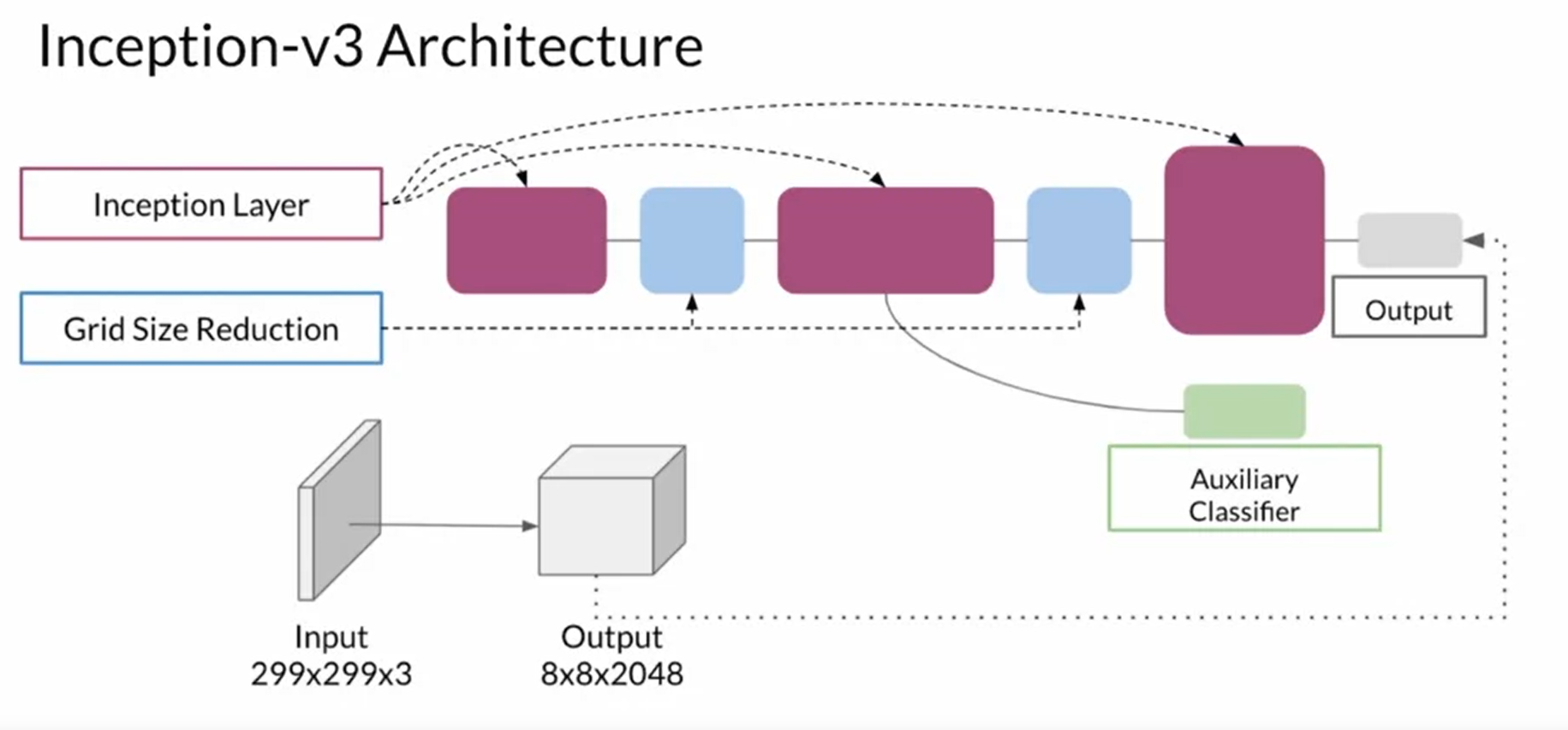
通过这个imagenet的神经网络可以将像素空间投影到feature空间,实现比较feature而不是比较像素。这样就可以识别出鼻子,耳朵,头发颜色等等图像的具体特征,并实现一些具体的操作,比如说对图像的特征距离进行计算等等。这些特性被叫做 embeddings, 我们可以通过比较 embeddings来得到 特性距离,也就是feature distance。
1.3 方法一 Frechet distance (Maurice frechet)
在数学中,Fréchet 距离是曲线之间相似性的度量,它考虑了沿曲线的点的位置和顺序。它以Maurice Fréchet的名字命名。用于计算两个曲线的距离的一种metric(度量方式)想象一个人在用皮带遛狗时穿过一条有限的弯曲路径,而狗则穿过一条单独的有限弯曲路径。每个人都可以改变他们的速度以保持皮带松弛,但都不能向后移动。两条曲线之间的 Fréchet 距离是足以让两条曲线从头到尾穿过各自路径的最短皮带的长度。请注意,该定义关于两条曲线是对称的——如果狗在遛它的主人,Fréchet 距离将是相同的。其称之为 Frechet Inception Distance (FID)。这个距离通常用来比较两个随机变量分布之间的距离。
- Univariate Normal Frechet Distance
( μ X − μ Y ) 2 + ( σ X 2 + σ Y 2 − 2 σ X σ Y ) (\mu_X - \mu_Y)^2 + (\sigma^2_X + \sigma^2_Y - 2 \sigma_X \sigma_Y) (μX−μY)2+(σX2+σY2−2σXσY)
- Multivariate Normal Frechet Distance (FID)
∣ ∣ μ X − μ Y ∣ ∣ 2 + T r ( Σ X + Σ Y − 2 Σ X Σ y ) ||\mu_X - \mu_Y ||^2 + Tr (\Sigma_X + \Sigma_Y - 2 \sqrt{\Sigma_X \Sigma_y}) ∣∣μX−μY∣∣2+Tr(ΣX+ΣY−2ΣXΣy)
FID的缺点: Shortcomings of FID:
- 需要一个提前训练好的模型来进行特征提取 Need pre-trained Inception model, which may not capture all features
- 需要大尺度的数据量 Needs a large sample size
- 模型训练非常慢 Slow to run
- 仅仅只有有限的统计量被使用 Limited statistics used: only mean and covariance
1.4 方法二 Inception Score: (IS)
这是一种同时评估了多样性和真实性的一种度量方式。
-
保持classifier的完整,直接提取他的输出
-
在某些class上的高分布,以及在其他类上的低分布来评价一个class的entropy P(y|x)
-
Fidelity means low entropy
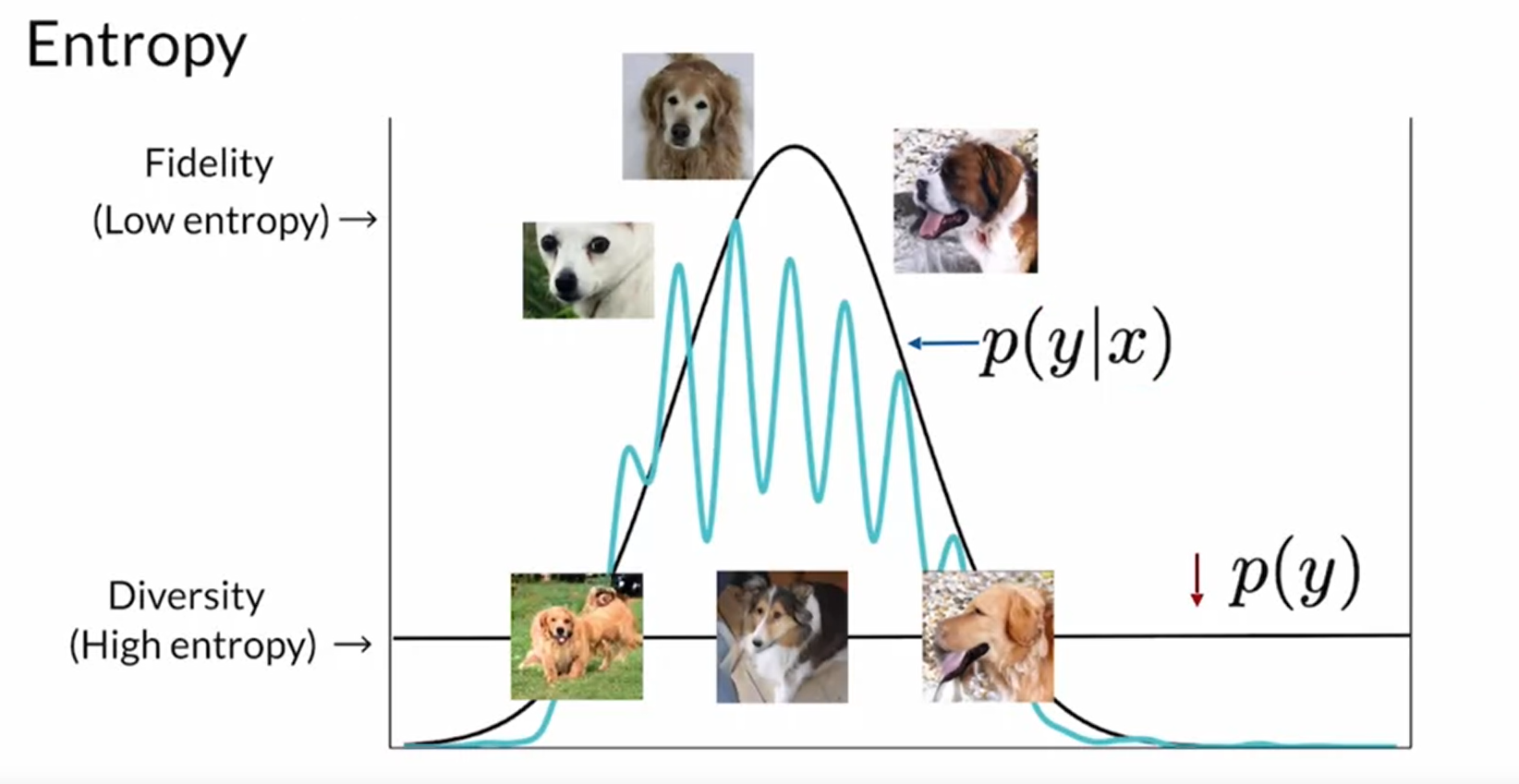
1.5 IS(Inception Score) definition
1. KL Divergence:
-
其主要描述了你通过边缘分布(样本的分布)可以得到多少条件分布(conditional distribution)的信息。当KL Divergence 越大,也就意味着你的总体样本包含的信息越多,entropy就越小,其就越准确。KL散度是两个几率分布P和Q差别的非对称性的度量。 KL散度是用来度量使用基于Q的分布来编码服从P的分布的样本所需的额外的平均比特数。
-
当 p(y) 与 p(y|x) 越相近,那么divergence越小,那么也就意味着我可以从p(y) 中得到更多的信息
-
KL散度通过条件分布和边缘分布的乘积来综合评估模型的有效性。其最初的作用是为了评估当知道先验分布后,评估其对后验推断的有效性,也就是其提供的信息的多少。而在这里,通过条件概率分布 p(y|x) 来表达,随机变量x条件下,随机变量y分布的概率,当这个值越大,也就意味着两个分布越相似。
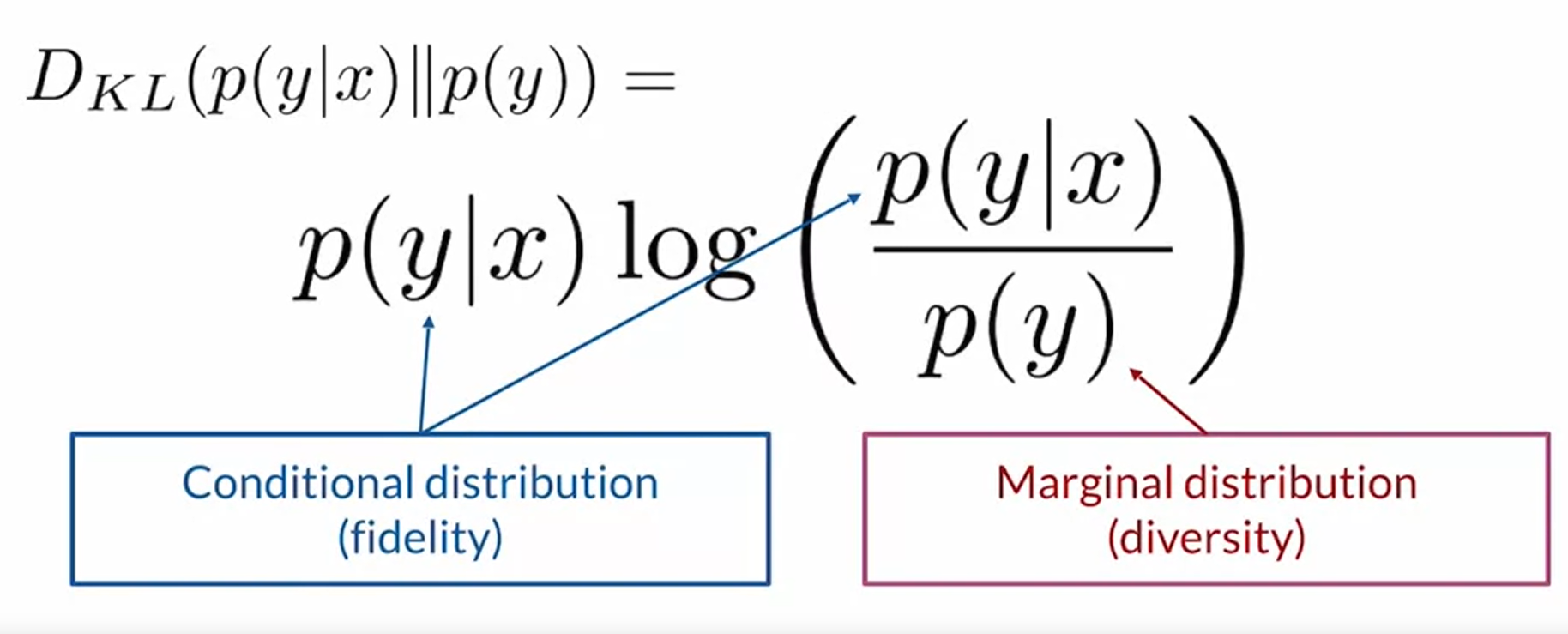
IS(Inception Score) definition
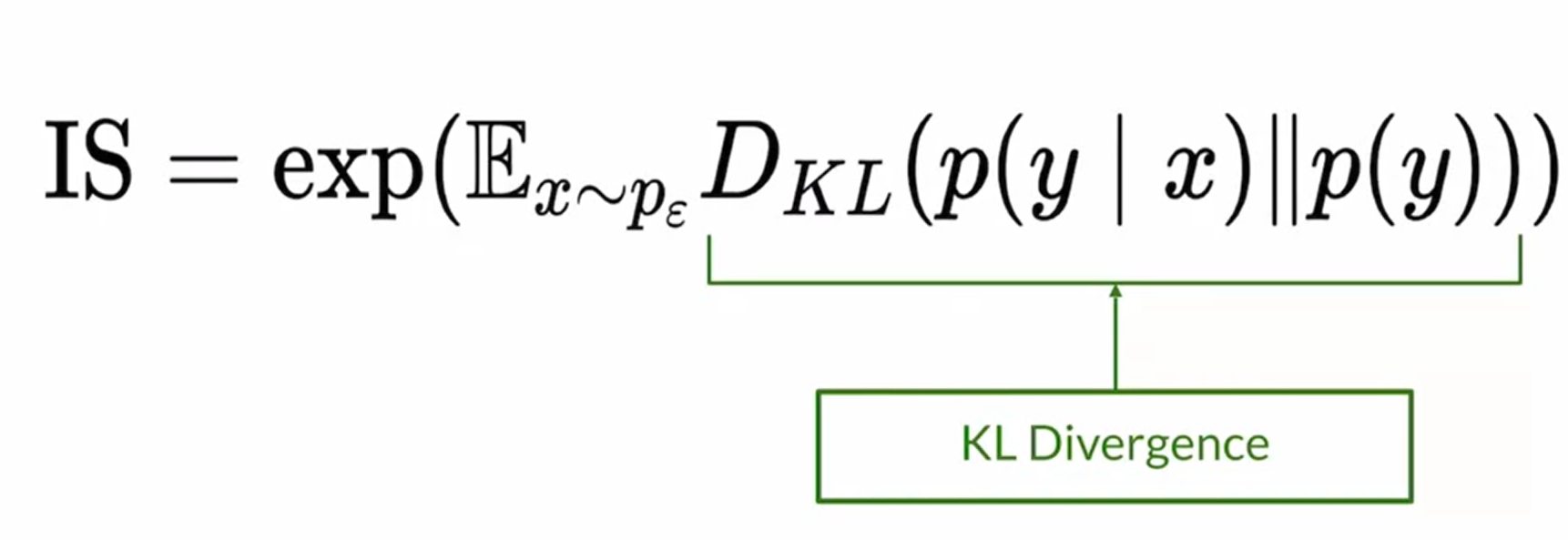
这个分布通过评估两个分布的信息增量的期望,旨在评估多样性和真实性。 Fidelity & Diversity
IS的缺点:Shortcomings of IS
- 每个class只生成一个,也就是局部最优
- 只看假的照片,对真的照片没有比对。
- 可能会错过有用的feature
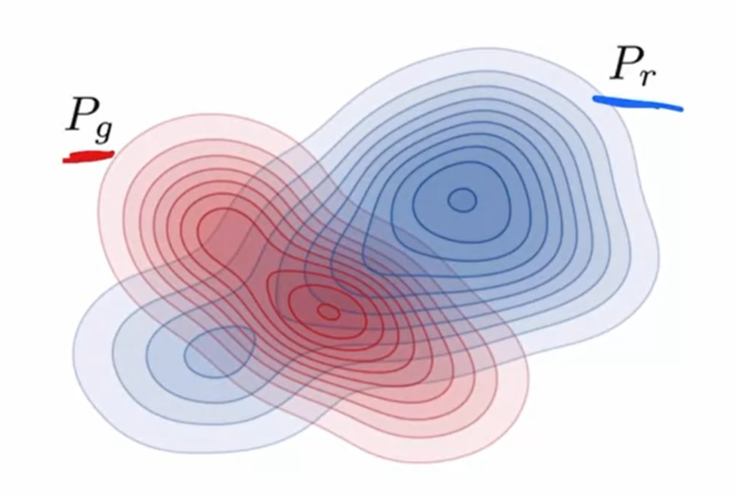
1.6 GANs 评估标准
GANs的目标就是上Pg 和Pr完全重合,以达到以假乱真的效果。
-
精确率和召回率 precision and recall
-
precision 指的是精确性,指的是其产生的随机分布样本中属于实际分布的样本在生成样本中的概率,也就是fidelity,指的是生成器生成真实样本的效率,也就是精确性。

-
recall 指的是多样性,也就是diversity,指的是真实的样本分布在产生的随机样本中的概率,也就是recall,也就是真实样本空间与生成样本空间的交集。简而言之,就是真实样本中有多少样本被生成样本所覆盖,也就直接表达了生成器生成样本的多样性覆盖率。

-
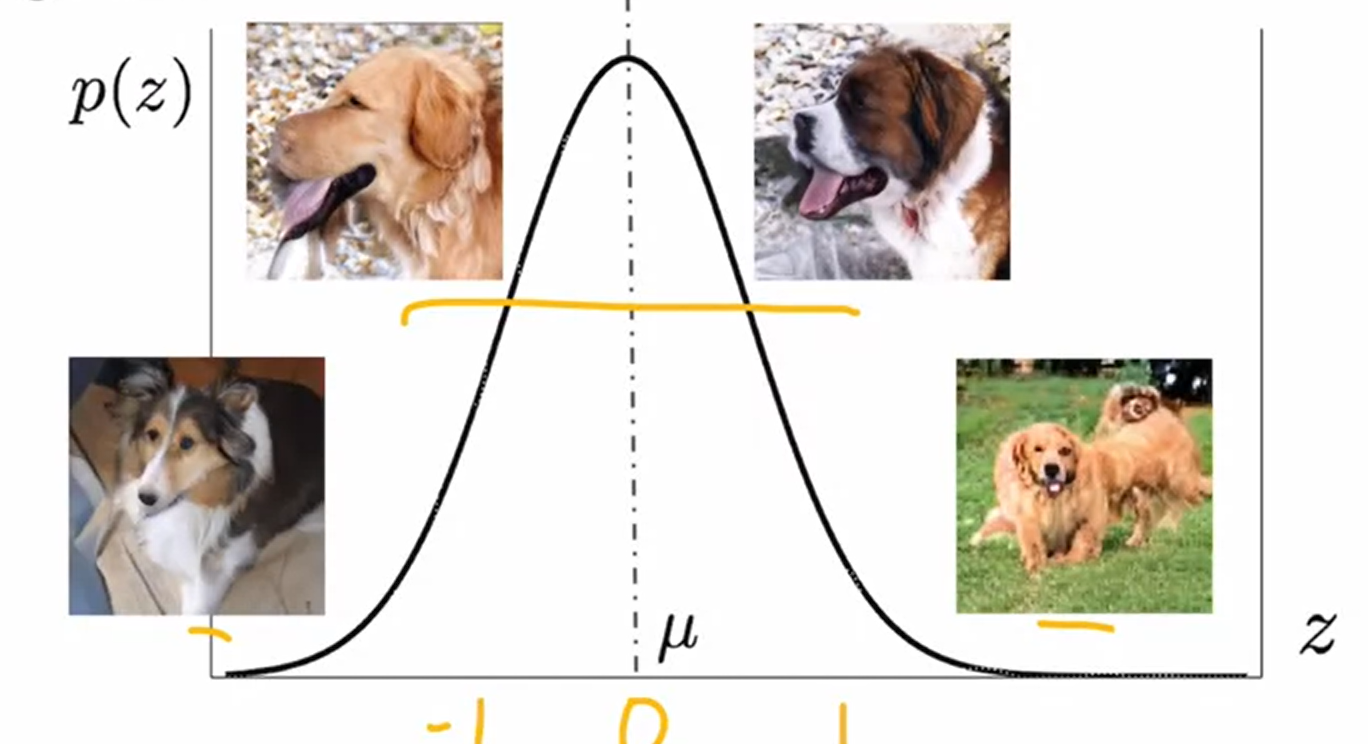
大多数情况下,GANs都是recall的性能更好一些,也就是覆盖率高但是可靠性差,也就是genereator可以包含和生成所有的feature,但是其却并不能够保证一定的精确性。于是根据此就用到了sampling fakes(Truncation Trick as a method),用于排除高diversity的样本。如下图的例子。
-
2. 参考文献 Reference
Need a summary of FID and IS? Here are two great articles that recap both metrics!
Fréchet Inception Distance (Jean, 2018): https://nealjean.com/ml/frechet-inception-distance/
GAN — How to measure GAN performance? (Hui, 2018): https://medium.com/@jonathan_hui/gan-how-to-measure-gan-performance-64b988c47732
Works Cited
All of the resources cited in Course 2 Week 1, in one place. You are encouraged to explore these papers/sites if they interest you! They are listed in the order they appear in the lessons.
From the videos:
- StyleGAN - Official TensorFlow Implementation: https://github.com/NVlabs/stylegan
- Stanford Vision Lab: http://vision.stanford.edu/
- Review: Inception-v3 — 1st Runner Up (Image Classification) in ILSVRC 2015 (Tsang, 2018): https://medium.com/@sh.tsang/review-inception-v3-1st-runner-up-image-classification-in-ilsvrc-2015-17915421f77c
- HYPE: A Benchmark for Human eYe Perceptual Evaluation of Generative Models (Zhou et al., 2019): https://arxiv.org/abs/1904.01121
- Improved Precision and Recall Metric for Assessing Generative Models (Kynkäänniemi, Karras, Laine, Lehtinen, and Aila, 2019): https://arxiv.org/abs/1904.06991
- Large Scale GAN Training for High Fidelity Natural Image Synthesis (Brock, Donahue, and Simonyan, 2019): https://arxiv.org/abs/1809.11096
From the notebook:
- CelebFaces Attributes Dataset (CelebA): http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
- ImageNet: http://www.image-net.org/
- The Fréchet Distance between Multivariate Normal Distributions (Dowson and Landau, 1982): https://core.ac.uk/reader/82269844




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











