







深度卷积对抗神经网络 进阶 第二部分 GANs Pix2Pix PatchGAN 模型
Image to image translation 是非常普遍的GAN的应用场景,最近我们也经常看到AI会做出一些比较有趣的结果。比如说黑白视频的填色等等,这都是对信息的一种补充和添加。而近些年更加有趣的事情是可以将非常复杂的模糊视频进行一些高清还原,其运用了不仅仅是当前帧的图像,还利用了视频时序的特点将视频前后帧的图像进行了分析和信息提取,使得模型看起来添加了视频的一些信息内容;但是其其实是由于某些信息是隐藏在其他信息帧中的。

pix2pix image 模型
生成模型
传统的conditional GANs的原理是通过一个噪声矩阵以及一个类向量来告诉生成器需要生成的结果的特征。这样可以生成不同类型的结果,但是噪声向量是不可控的,也就意味着我们无法知道某个噪声向量具体会生成何种结果。

而反过来,Pix2pix 生成器通过实际的图片输入来代替噪声矩阵和类向量来生成不同类型的结果。具体的差别就是,通过像素输入,生成器会了解输入的模式,并根据他的理解生成它理解的输出。那么我们的输入就从一维的向量转变为二维的图片,输入信息变多,模型也就更加地准确地能够了解到用户的信息,生成的结果也就更加具有指向性。

在个人理解中,conditional GANs做了噪声空间到图片仿射空间到实际图片空间的映射;而pix2pix直接略过了噪声向量到潜在的图片仿射空间的映射,而直接将仿射空间的图片元素映射到实际输出空间,更加直接,增加了控制的自由度,能够精确地控制生成的结果的特性。而随机特性包含在输入的图片中,并没有因此而丢失掉随机性。
辨别器 Pix2Pix Discriminator: PatchGAN
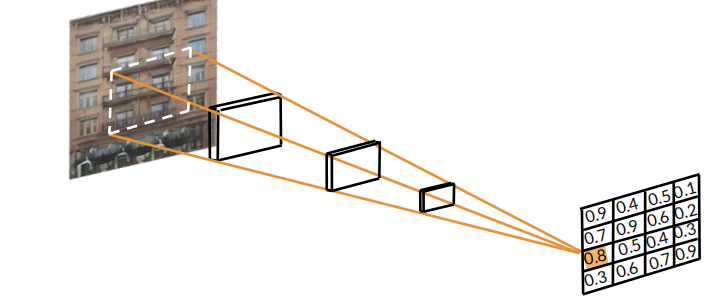
辨别器的主要作用是通过将不同的区域分段来进行识别,并不是对单个像素进行简单的对比,这也就叫做所谓的PatchGAN。其优点便是能够对区域进行整体分析,而不是仅仅对像素进行比较。我们都应该能得出,像素比较的颗粒度较为细,在进行损失函数或者差异分析时容易出现对差别太过敏感的问题。
Pix2Pix 模型: U-Net

U-Net是Pix2PixGAN的一种结构,其类似于Encoder和Decoder的方式,前半部分绿色的encoder通过逐层将特征进行提取,将对应的主要特征存储到仿射空间 laten space中。而Decoder则是将仿射空间中的特征向量再解码到实际的图像空间,得到我们所需要的图片。而每一层所对应的encoder和decoder则通过Skip connection进行数据的交流。这样可以使得数据不再顺序传输和处理,而形成一些简单的网,使得在编码过程中所丢失的图像信息得到保存。
Pix2Pix 模型:损失函数 Pixel Distance Loss Term
损失函数取经典的BCEloss作为对抗神经网络的损失函数,并且取真实图像与生成图像的差距来作为额外的像素损失。我们的目标是让生成的图片和实际的图片靠近,使得其能够生成可以媲美真实图片的假图片。而为什么用像素距离,主要是输出图片和生成的图片都是经过标记的,因此何种初始图片生成目标图片是标记好的。因此计算像素距离并加入一个\lambda便可以缓缓地加入额外的模型训练的监督。

Pix2Pix 整体模型
U-Net 模型用于作为生成器生成可用图片

PatchGAN 辨别器用于将实际输入与生成或者真实图片进行识别比较,得到一个分类矩阵(Classification Matrix),并通过分类矩阵与零矩阵以及一矩阵进行比较而得到一个辨别器的损失函数。如果是生成的图片,使分类矩阵与全零矩阵进行比较;如果是实际图片,使得其与全一矩阵进行比较;这样就能够判断出辨别器的分辨准确性。

U-net损失函数主要是比较分类矩阵与真实矩阵的差距以及加入像素距离的方式来实现。

总结
通过Pix2Pix Patch GANs可以实现图像的转化,而图像的转化会帮助艺术创作者创造更加有趣的艺术作品,这样可以解放艺术创作者的双手,让他们去做更加有意义和创作的事情,而不是用画笔绘画等等。其通过U-Net和PatchGANs分辨器来实现了图片数据的对应。这个模型可以做到非常真实的结果输出,但是其缺点也是显而易见,其需要标记好的图片对应来训练网络,而不能直接输入图片。这就使得其在某些研究领域的应用有一定的局限性。而CycleGANs便可以解决数据标注的问题。
参考文献 Reference
(Optional) The Pix2Pix Paper
Want to know more about image-to-image translation and the research behind the components of Pix2Pix? Take a look at the original paper!
Image-to-Image Translation with Conditional Adversarial Networks (Isola, Zhu, Zhou, and Efros, 2018): https://arxiv.org/abs/1611.07004
(Optional Notebook) Pix2PixHD
Please note that this is an optional notebook, meant to introduce more advanced concepts if you're up for a challenge, so don't worry if you don't completely follow!
In this notebook, you will learn about Pix2PixHD, which synthesizes high-resolution images from semantic label maps. Proposed in High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs (Wang et al. 2018), Pix2PixHD improves upon Pix2Pix via multiscale architecture, improved adversarial loss, and instance maps.
(Optional Notebook) Super-resolution GAN (SRGAN)
Please note that this is an optional notebook meant to introduce more advanced concepts. If you’re up for a challenge, take a look and don’t worry if you can’t follow everything. There is no code to implement—only some cool code for you to learn and run!
In this notebook, you will learn about Super-Resolution GAN (SRGAN), a GAN that enhances the resolution of images by 4x, proposed in Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (Ledig et al. 2017). You will also implement the architecture and training in full and be able to train it on the CIFAR dataset.
(Optional) Lecture Notes W2
You can download this week's lecture notes from this post in our Discourse community.
(Optional) More Work Using PatchGAN
Want to see how a GAN can fill-in cropped-out portions of an image? Read about how PGGAN does that by using PatchGAN!
Patch-Based Image Inpainting with Generative Adversarial Networks (Demir and Unal, 2018): https://arxiv.org/abs/1803.07422
(Optional Notebook) GauGAN
Please note that this is an optional notebook meant to introduce more advanced concepts. If you’re up for a challenge, take a look and don’t worry if you can’t follow everything. There is no code to implement—only some cool code for you to learn and run!
In this notebook, you will learn about GauGAN, which synthesizes high-resolution images from semantic label maps, which you implement and train. GauGAN is based around a special denormalization technique proposed in Semantic Image Synthesis with Spatially-Adaptive Normalization (Park et al. 2019)
















 368
368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











