







 本文介绍了滴滴在单通道语音分离技术上的进展,特别是在复杂声学环境下的目标说话人提取与抑制。文章探讨了语音分离的现状、原理,包括频域和时域方法的优缺点,并提出了一种迭代精炼适应(IRA)机制来提高模型的鲁棒性。实验表明,IRA机制在无噪和含噪场景下都能显著提升说话人提取的性能,且说话人抑制技术在去除导航音方面表现出优于传统回声消除的优势。
本文介绍了滴滴在单通道语音分离技术上的进展,特别是在复杂声学环境下的目标说话人提取与抑制。文章探讨了语音分离的现状、原理,包括频域和时域方法的优缺点,并提出了一种迭代精炼适应(IRA)机制来提高模型的鲁棒性。实验表明,IRA机制在无噪和含噪场景下都能显著提升说话人提取的性能,且说话人抑制技术在去除导航音方面表现出优于传统回声消除的优势。

桔妹导读:为了将目标语音从含多种干扰(如车噪、导航音、车内FM等)的复杂声学环境中分离出来同时尽量减小对原始语音的损伤,提高人机交互、客服听音等的效率,滴滴结合了在前端信号处理的多年研发积累与该领域的前沿研究,在单通道语音分离任务上取得了较大的进展。本文重点介绍单通道语音分离的研究现状、原理和目标说话人提取(或抑制)的框架、改进和一些实验结果及demo展示。
语音分离(Speech Separation),就是在一个有多个说话人同时说话的场景里,把不同说话人的声音分离出来。目标说话人提取(Target Speaker Extraction)则是根据给定的目标说话人信息,把混合语音当中属于目标说话人的声音抽取出来。
下图汇总了目前主流的语音分离和说话人提取技术在两个不同的数据集上的性能,一个是 WSJ0-2mix 纯净数据集,只有两个说话人同时说话,没有噪声和混响。WHAM是与之相对应的含噪数据集。可以看到,对于纯净数据集,近两年单通道分离技术在 SI-SDRi 指标上有明显的进步,图中已PSM方法为界,PSM之前的方法都是基于频域的语音分离技术,而PSM之后的绝大多数(除了deep CASA)都是基于时域的语音分离方法。
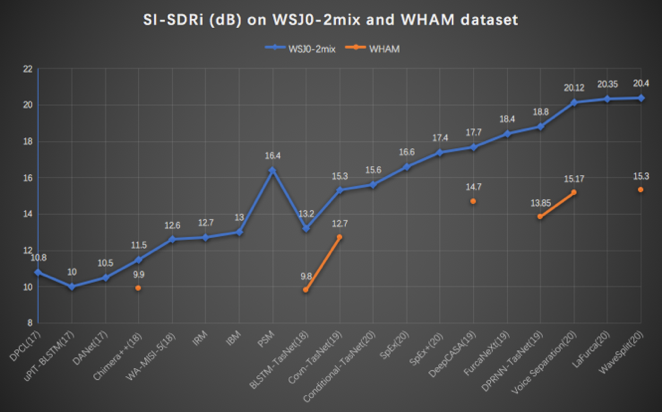
噪声场景相对更贴近于真实的环境。目前,对于噪声场景下的分离技术性能的研究还不是特别完备,我们看到有一些在安静环境下表现比较好的方法,在噪声环境下性能下降比较明显,大多存在几个 dB 的落差。同时,与纯净数据集相比,噪声集合下各种方法的性能统计也不是很完备。
通常来讲,单通道语音分离可以用“Encoder-Separator-Decoder”框架来描述。其中, Encoder可以理解为将观测信号变换到另外的一个二维空间中,比如离散傅里叶变换将时域信号变换到频域,1-D CNN将时域信号变换到一个二维潜空间中;Separator在变换域当中进行语音的分离,学习出针对不同声源的mask,与混合信号做一个元素级别相乘,由此实现变换域中的语音分离操作;Decoder 就是把分离后的信号反变换到一维时域信号。这套框架既可适用于频域的分离方法,也可用于时域的分离方法。
大部分 Encoder 都是通过线性变换完成的,通过一组滤波器将时域混合语音变换到另外的一个二维空间当中。滤波器组的设计是值得研究的。最简单的方法是用固定的滤波器,比如短时傅里叶变换。此外,人们更愿意用data-driven的方式学习滤波器组的系数,比如常用1-D CNN。所以,单通道的语音分离,便可以依据此划分为频域和时域两类方法。
第一类是基于频域的语音分离方法。这种方法的优点是可以与传统的信号处理方法更好的相融。频域法中的encoder多数情况下由傅里叶变换实现。在多通道场景下,可以与后端的频域波束形成更好的配合。第二个优点就是 Separator中 Mask 的可解释性比较强,即通过网络学出来的特征更加稀疏和结构化。这种方法的缺点也比较明显。第一,傅里叶变换本身是一种通用的变换,也是信号处理当中的经典变换,但它并不一定适用于分离任务。第二个比较明显的问题是相位重建比较困难。Separator中学习Mask通常利用的是幅度谱,而在语音重构的时候会利用混合语音的相位,所以会有语音失真的产生。第三,因为要做傅里叶变换需要有足够的采样点保证频率分辨率,所以延时比较长,对于对时延要求比较高的场景,频域分离法会有限制。
第二类方法是时域分离法。它的第一个优点是用一种 data-driv
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









