







QQ开放平台搭建和优化个人本地LLM群机器人(一):架构搭建和使用微调大模型
前言:为什么选择QQ开放平台机器人?
众所周知,QQ平台上有许多成熟的,或收费或免费的第三方机器人,为什么要选择QQ开放平台的呢?
其实是笔者之前并没有使用这些的经验
最主要的原因是这些第三方机器人虽然支持的功能丰富,但是同样也承担着停运的风险;而本教程所专注的是使用本地大模型来搭建和优化应用,QQ开放平台足以支持这一目标。实际上,本教程希望能通过QQ开放平台机器人来构建一个便捷的远程使用本地LLM的交互手段,从这一点上来说,纯文字的,简洁的交互方式是可以接受的。
当然,QQ开放平台搭建的机器人同样有很多缺点和不足,要知道,QQ开放平台官方文档QQ 机器人 | QQ机器人文档中最初应该是想要做成专门针对频道的机器人的,而对于群的支持是在最近几个月添加的,文档中对其描述和功能介绍都甚少不过正好不用看长篇大论
在正式进入教程之前,有几点需要注意
-
本教程仅会专注于群机器人,而不会介绍频道机器人的使用
-
目前,测试中的群机器人只能在小于20人的群中部署
本期主要介绍如何申请QQ机器人,使用ollama部署微调后的大模型并添加记忆
源码在github取用
QQ开放平台申请机器人
首先,登录QQ 开放平台,通过QQ就行了
进入之后拉到下面的应用管理进行创建机器人

创建的时候要求提供名字,用途之类的,随便填写一下就行了
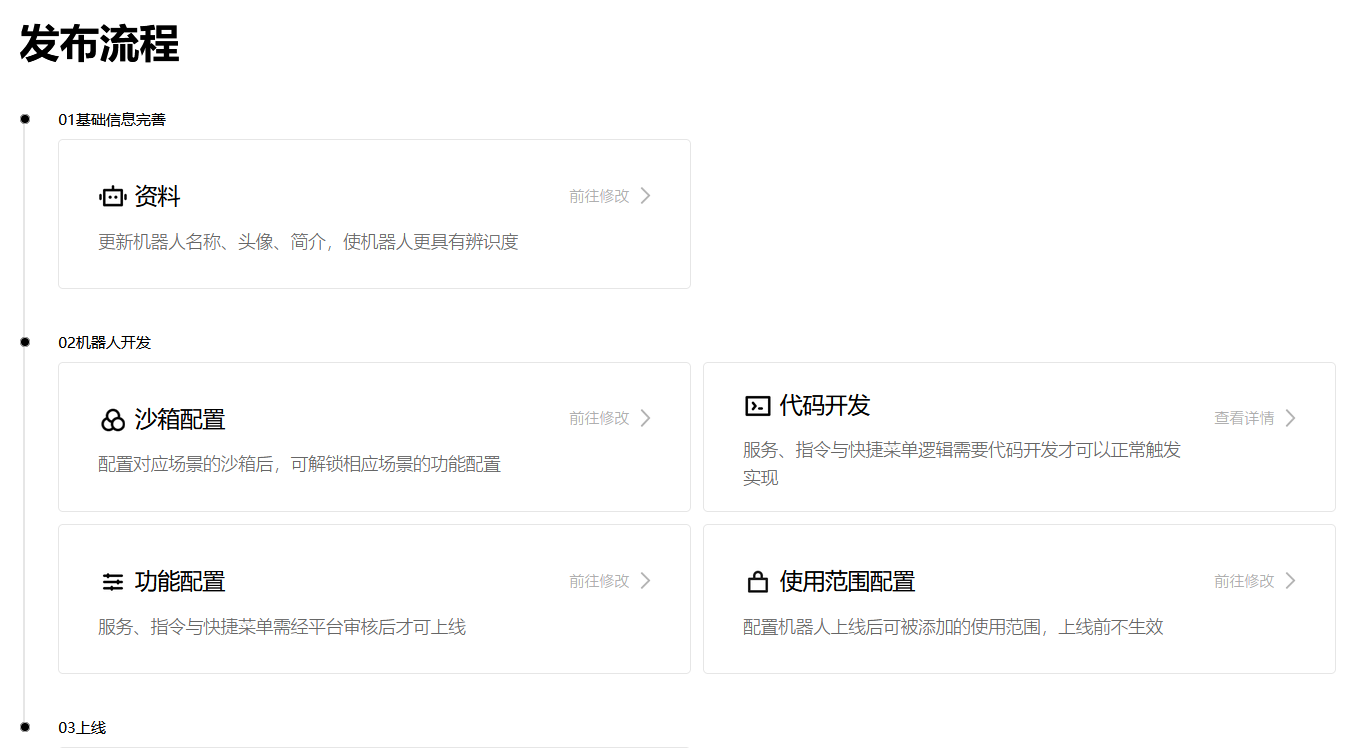 进去自己的机器人之后,右边进来可以看到发布流程,一共3步骤,因为我们基本不涉及上线成为公域机器人,第三部分基本不用管了
进去自己的机器人之后,右边进来可以看到发布流程,一共3步骤,因为我们基本不涉及上线成为公域机器人,第三部分基本不用管了
先点进图中的沙箱配置
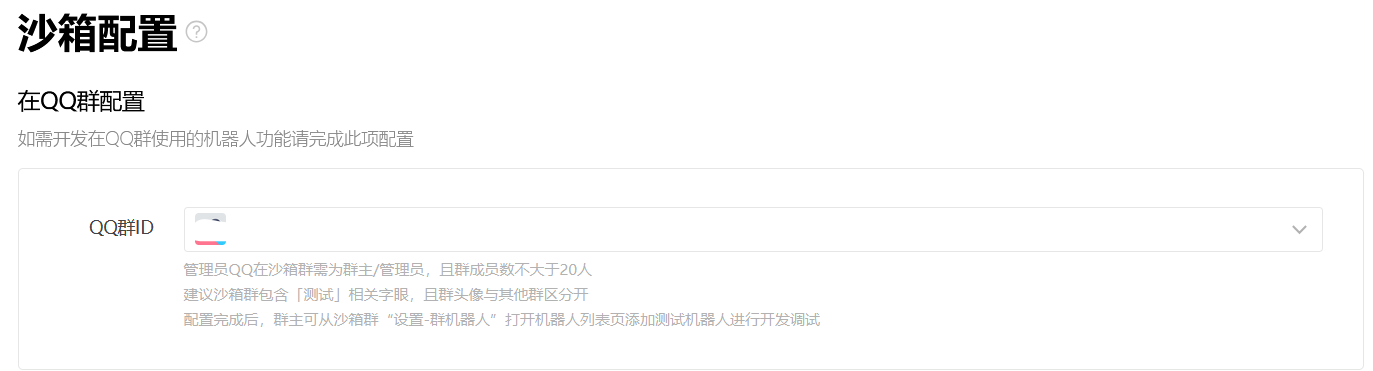 在这里可以选择自己是群主/管理员的群,配置沙箱,之后可以在相应的群里面邀请配置之后的机器人
在这里可以选择自己是群主/管理员的群,配置沙箱,之后可以在相应的群里面邀请配置之后的机器人
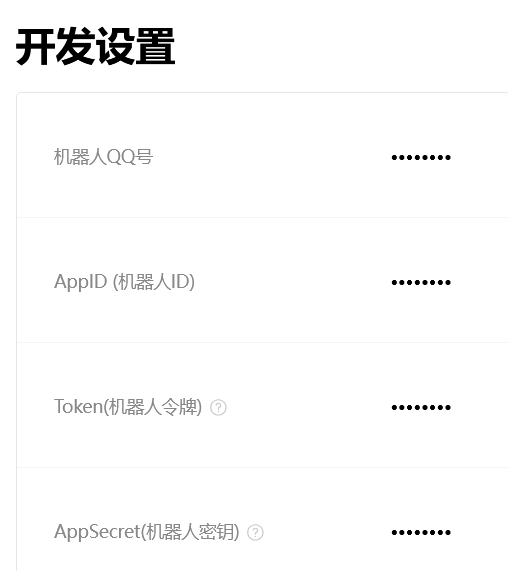
左边栏内可以看到一个开发设置,这个里面得到AppID和AppSecret,之后要用
接下来使用PythonSDK来进行开发
建议使用conda虚拟环境来进行管理
conda create -n your_env python==3.10
conda activate your_env
pip install qq-botpy
可以把整个仓库都下下来进行研究,不过群机器人的例子很少,这里只需要下载两个文件
- config.example.yaml下载下来之后把名称改为example.yaml
打开来可以看到里面只有两个参数,就是之前在开发设置里面看到的AppID和AppSecret,填入即可 - 群内@回复消息
这个是官方的at机器人回复文字消息的实例,现在还支持富媒体信息的回复,以后可以用到
打开文件,注意在MyClient里面添加is_sandbox=True,因为我们这个目前是在沙箱的测试模式,不然无法连接,这个地方和添加IP白名单没有关系
if __name__ == "__main__":
intents = botpy.Intents(public_messages=True)
client = MyClient(intents=intents, is_sandbox=True)
client.run(appid=test_config["appid"], secret=test_config["secret"])
这时就可以运行此文件进行测试了,终端显示on_ready就表明机器人已经上线了,我们可以在群里@机器人,这时机器人会原样输出接受到的文字
本地LLM部署
ollama
本地运行大模型的框架有许多,如vllm, llamacpp, ollama等
因为消费级PC或笔记本都是windows平台,考虑到部署便利性,我们直接使用ollama进行一站式的LLM部署(Linux也可以)
ollama下载
windows平台是下载exe文件,Linux直接一行命令就可以下载
接下来直接在终端输入
ollama --version
可以看到版本信息,就说明已经成功运行了
接下来我们可以直接开始下载大模型,不过,默认模型的下载路径是在C盘,顾虑这一点的朋友可以自行更改# Ollama修改默认模型存储位置
使用ollama的方便之处在于可以直接提供便捷的模型下载,不需要过高的网络条件
 在网站的Search models里面可以直接搜索模型下载
在网站的Search models里面可以直接搜索模型下载
例如,llama3.1点开,左边下拉栏里面有各种版本的
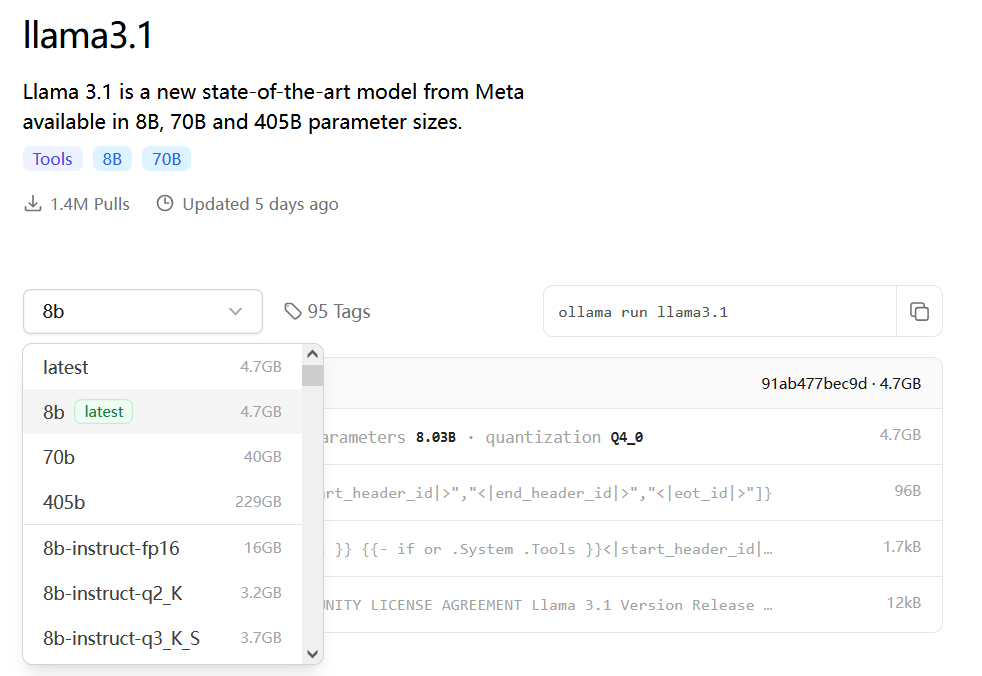 右边的命令在终端运行可以直接下载
右边的命令在终端运行可以直接下载
我们直接根据左边的模型大小要求,下载后缀带instruct的模型
笔者的显卡有12GB,便选择ollama run llama3.1:8b-instruct-q8_0,模型大小8.5GB,运行起来大概占用显存10GB左右
下载完成之后,我们可以直接在终端和终端对话看下效果
输入/bye退出
导入微调后的GGUF模型
为什么我们要使用本地LLM进行部署?最大的好处是可以直接使用经过各种微调的更加奇奇怪怪好用的大模型
虽然也可以使用api的方式来使用性能远强于本地的大模型,不过目前大模型的各种安全对齐导致这写大模型没法对存在安全风险的问题人类的三大欲望进行回答,所以,部署各种私人微调后的大模型也是别有一番乐趣
笔者在huggingface上面进行搜索,很快找到了一些基于llama3.1进行微调,解除安全对齐
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1144
1144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









