







文章目录
- 一、理论篇
-
- 1. 什么是LLM
- 2. LLM发展历史
- 3. LLM构建流程
- 4. LLM主流架构
- 5. LLM评估指标
- 6. LLM排行榜
- 7. LLaMA的网络结构
- 8. 为什么需要残差网络
- 9. Transformer架构中,encoder给decoder传递的是什么?
- 8. LLM从海量文本中学习到了什么
- 12. 如何消除模型幻觉
- 16. 思维链promting是啥
- 17. chatGPT中的语言模型跟传统语言模型最大区别
- 18. 代码预训练可以增强LLM推理能力
- 20. flash-attention为什么能加速
- 21. 什么是bpe算法
- 22. Decoder在训练时,输入是真实标注label,但实际使用时输入的是上一次的解码结果
- 23. gpt4距离超越人类智力还有多远
- 24. deepseek相比普通大模型有什么特点
- 25. transformer的矩阵维度变化过程
- 26.强化学习是如何做权重调整的
- 27.DPO算法是如何优化模型权重的
- 28. vllm的paged attention是怎么回事?
- 29. 为什么总是对k、v进行缓存,为什么不对历史的q进行缓存呢?
- 30. GPT3有96层,KV缓存应该是每一层都会有缓存吧,所以KV Cache纬度应该不止[n,96,128]吧?
- 31. vllm的prefix caching技术和kv缓存是不是一码事
- 32.kv缓存为什么attention的每一层都只是最后一个token变化
- 33. 在有kv缓存的时候,为什么经过那么多的计算,每一层的输入的前n-1个向量仍然可以保持不变
- 34.残差连接和归一化是如何对每个token独立操作的?
- 35. MHA(Multi-Head Attention)、MQA(Multi-Query Attention)、GQA(Group-Query Attention)有什么区别
- 36. Qwen大模型的演进历史
- 37. 稀疏注意力的机制中,Longformer和Reformer方法具体指的是什么?
- 38.请详细解释下qwen2所采用的滑动窗口注意力和全注意力是什么?
- 39.如果我现在期望训练一个扩大context length的大模型,应该怎么办,涉及哪些技术
- 40.什么是soft token
- 41. 什么是旋转位置编码,它跟绝对位置编码有什么区别和联系?
- 二、实践篇
-
- 1. 如何下载模型
- 3. prompt提示应该怎么写效果会更好
- 4. 预训练数据集概览
- 5. InstructGPT模型微调数据集
- 6. 指令微调数据集格式
- 7. 训练数据准备阶段
- 8. 如何对训练加速
- 10. llma-index能比较方便构建文档索引,并直接提问
- 11. 金融领域评测数据集
- 12. 如何加速Qwen模型的推理速度
- 13. LoRa和QLoRA有什么区别?
- 14. 训练大模型的一键流程框架
- 17. chatGPT的输入有长度限制,怎么办
- 19. 如何制作"针对某个pdf的问答机器人"
- 20. 开源项目
- 21. GPT模型的token和汉字的换算关系
- 22. GPT3.5的价格如何?
- 23. 什么是LoRA训练
- 24. 目前已有的大规模参数训练框架
- 25. 训练模型需要多大的显存
- 26. 使用vllm部署模型
- 27. 模型训练模式
- 28. 多轮对话
- 29. 模型不收敛怎么办
- 三、应用篇
- 四、参考文档
- 待阅读
一、理论篇
1. 什么是LLM
LLM其实就是large language model,大语言模型。AGI其实就是Artificial General Intelligence。NLP大致可以分为两大任务:NLP理解类任务 和 NLP生成类任务。这两类任务的差异主要体现在输入输出形式上。
- 理解类任务的特点是,输入一个句子(文章),或者两个句子,模型最后判断属于哪个类别,所以本质上都是分类任务,比如文本分类、句子关系判断、情感倾向判断等。
- 生成类任务的特点是,给定输入文本,对应地,模型要生成一串输出文本,比如聊天机器人、机器翻译、文本摘要、问答系统等。
NLP各种任务其实收敛到了两个不同的预训练模型框架里:
- 对于NLP理解类任务,其技术体系统一到了以Bert为代表的“预训练+Fine-tuning”模式;
- 对于NLP生成类任务,其技术体系统一到了以GPT为代表的“自回归语言模型(即从左到右单向语言模型)+Zero /Few Shot Prompt”模式。
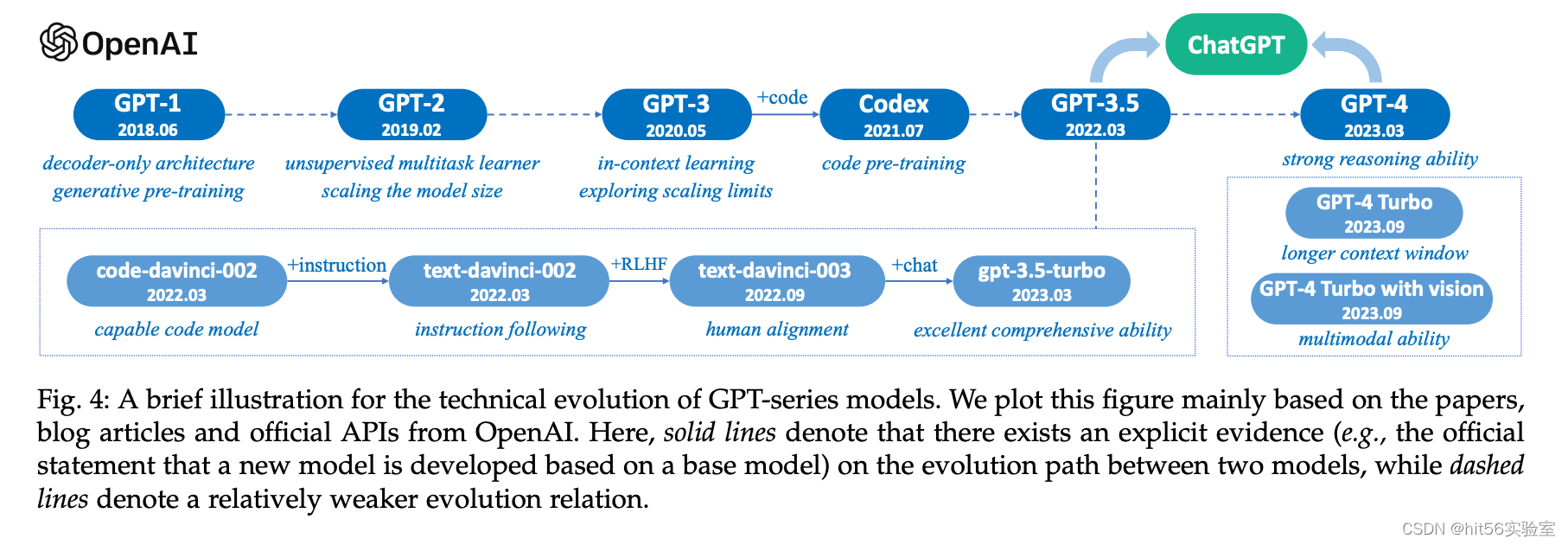
2. LLM发展历史
- 【Transformer模型】:2017年6月,Google发布论文《Attention is all you need》,首次提出Transformer模型,成为GPT发展的基础。
- 【GPT模型】:2018年6月,OpenAI 发布论文《Improving Language Understanding by Generative Pre-Training》,首次提出GPT模型。
- 【GPT2模型】:2019年2月,OpenAI 发布论文《Language Models are Unsupervised Multitask Learners》,GPT2使用了与GPT1相同的模型和架构,但GPT2更加侧重于 Zero-shot 设定下语言模型的能力。在 GPT1的基础上引入任务相关信息作为输出预测的条件,将 GPT1 中的条件概率 p(output|input) 变为p(output|input; task);并继续增大训练的数据规模 以及模型本身的参数量,最终在Zero-shot的设置下对多个任务都展示了巨大的潜力。这样的思想事实上是在传达只要模型足够大,学到的知识足够多,任何有监督任务都可以通过无监督的方式来完成,即任何任务都可以视作生成任务。
- 【GPT3模型】:2020年5月,OpenAI 发布论文《Language Models are Few-Shot Learners》。GPT3使用了与GPT2相同的模型和架构。GPT3最显著的特点就是大。大体现在两方面,一方面是模型本身规模大,参数量众多,具有96层 Transformer Decoder Layer,每一层有96个128维的注意力头,单词嵌入的维度也达到了12288;另一方面是训练过程中使用到的数据集规模大,达到了45TB。在这样的模型规模与数据量的情况下,GPT3在多个任务上均展现出了非常优异的性能,延续 GPT2将无监督模型应用到有监督任务的思想,GPT3在Few-shot,One-shot 和 Zero-shot 等设置下的任务表现都得到了显著的提升。
- 【Instruction GPT模型】:2022年2月底,OpenAI 发布论文《Training language models to follow instructions with human feedback》,该论文公布了InstructionGPT,它跟GPT3的网络结构是一样的,区别在于训练阶段的不同,instructGPT使用了标注数据进行fine-tune。
- 【ChatGPT模型】:2022年11月30日,OpenAI推出ChatGPT,全网火爆。
总结:GPT系列模型架构相同,主要差异点在于数据的size和quality:

GPT3从45TB数据里面只用了570GB,约1.2%,由此可见数据预处理过滤之厉害程度![手动狗头]
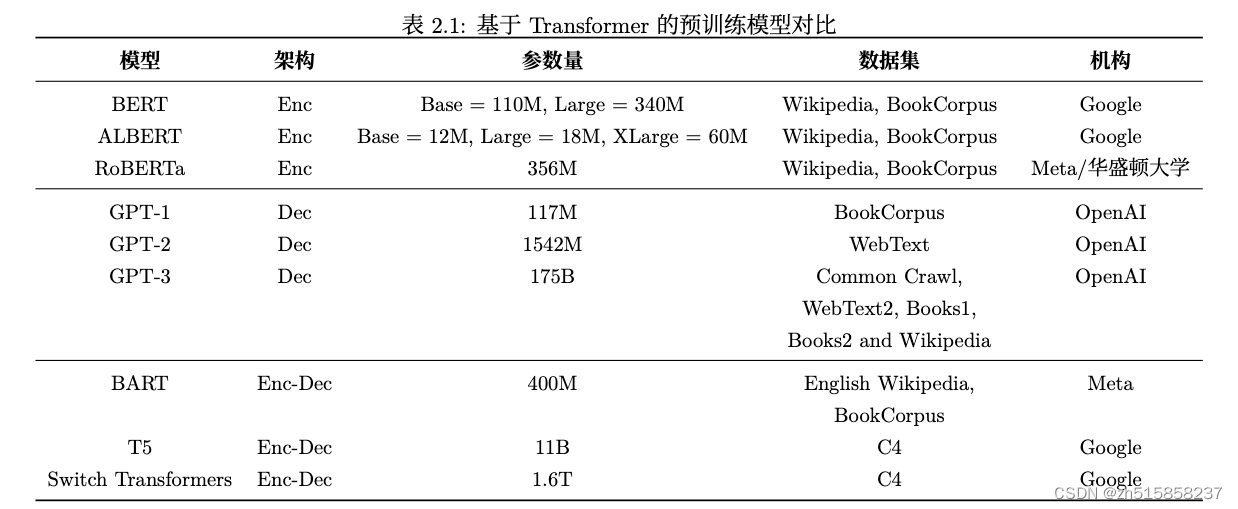
基于Transformer的预训练模型参数量对比如下:
3. LLM构建流程

(1)预训练阶段: 使用超大规模文本对模型进行训练,训练任务为“预测下一个token”,训练的数据量往往需要几万亿token。
(2)对齐阶段:
2.1 指令微调:使用指令数据,让模型的输出格式与人类对齐,使其具备chat的能力。从5.4w人工标注的指令集中抽取1.3w,在GPT-3大模型上微调。也就是说从测试用户提交的 prompt 中随机抽取一批,靠专业的标注人员,给出指定 prompt 的高质量答案,然后用这些人工标注好的 < prompt,answer > 数据来 Fine-tune GPT 3.5 模型,从而让 GPT 3.5 初步具备理解指令中蕴含的意图的能力;
2.2 奖励函数:基于新模型生成一批数据集<prompt,response>,重组成3.3w排序对形式,人工标注后,用于训练奖励模型。奖励模型结构同基座LLM,论文里全部用6B级别,规模大了反而不好。也就是说,随机抽样一批用户提交的 prompt,然后使用第一阶段 Fine-tune 好的冷启动模型为每个 prompt 生成 K 个不同的回答,再让标注人员对 K 个结果进行排序,以此作为训练数据,通过 pair-wise learning to rank 模式来训练reward model;
2.3 强化学习:使用人类反馈或者偏好数据来训练模型,使模型的输出更加符合人类的价值观或者预期行为。利用上一阶段学好的 RM 模型,靠 RM 打分结果来更新预训练模型参数。RLHF的具体实现,RM奖励模型作为critic(评论家),SFT阶段的大模型作为actor(行动家),二者相互配合,actor学习指令集,critic评估打分,再更新权重,进入下一轮。论文里对比两种损失函数,后采用混合预训练损失PPT_ptx,兼顾预训练的效果。
4. LLM主流架构
The Practical Guides for Large Language Models按照模型结构整理了大模型的进化树。现有 LLMs 的主流架构大致可以分为三大类,即Encoder-Decoder、Causal Decoder、Prefix Decoder:
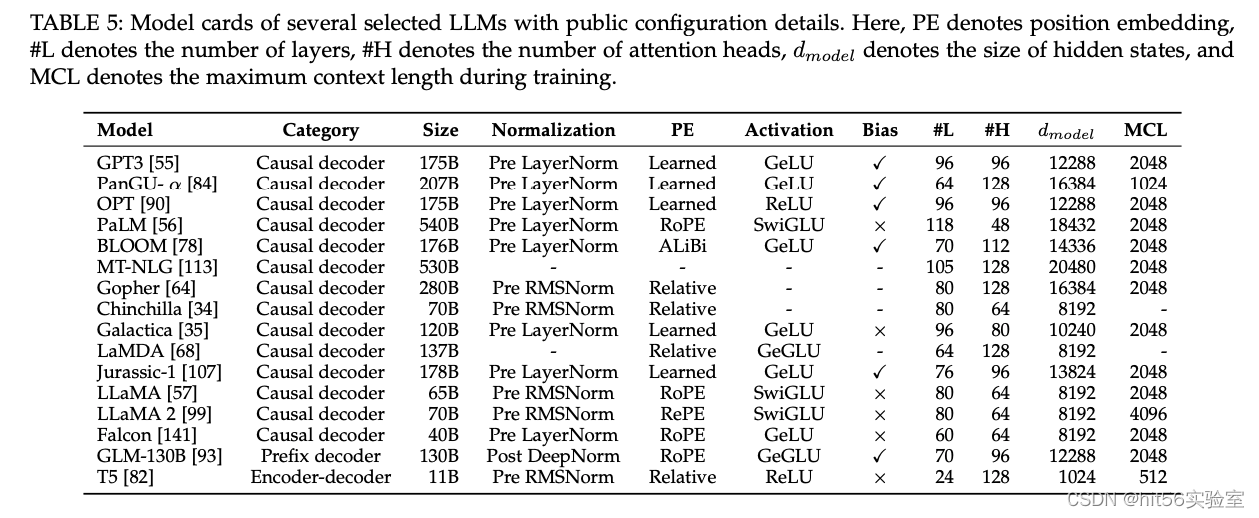
Encoder-Only结构:BERT系列
Decoder-Only结构:GPT系列,成员最多
Encoder-Decoder结构:BART、T5
5. LLM评估指标
| 测试集名称 | 排行榜 | 语言 | 备注 |
|---|---|---|---|
| MMLU(Massive Multitask Language Understanding) | 排行榜 | 英文 | 这是最值得注意的测试集,它考虑了 57 个学科,从人文到社科到理工多个大类的综合知识能力。DeepMind 的 Gopher 和 Chinchilla 这两个模型甚至只看 MMLU 的分数。 |
| C-Eval(A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models) | 排行榜 | 中文 | 覆盖人文,社科,理工,其他专业四个大方向,52 个学科(微积分,线代 …),从中学到大学研究生以及职业考试,一共 13948 道题目的中文知识和推理型测试集,管它叫 C-Eval,来帮助中文社区研发大模型。是上海交大和清华联合研发的中文大语言模型测试集。 |
| GSM8k(Grade School Math 8K) | 排行榜 | 数学 | 是由 OpenAI 发布的一个由 8.5K 高质量的语言多样化的小学数学应用题组成的数据集,要求根据给定的场景和两个可能的解决方案,选择最合理的方案。 |
| BBH(BIG-Bench Hard) | 英文 | BBH是一个挑战性任务 Big-Bench 的子集。Big-Bench 目前包括 204 项任务。任务主题涉及语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等方面。BBH 是从 204 项 Big-Bench 评测基准任务中大模型表现不好的任务单独拿出来形成的评测基准。 | |
| HellaSwag | 推理 | ||
| TruthfulQA | 安全性 | 该数据集旨在挑战语言模型的事实准确性,尤其是在多个选项中选择正确答案时。它的主要目标是测试模型是否能够正确回答涉及事实和常识的问题。也就是语言模型在面对具有多个可能答案的情况时,能否选出符合实际的那个。 |
6. LLM排行榜
国内排行榜:opencompass(上海AI实验室推出的)
国外排行榜:chatbot-arena-leaderboard
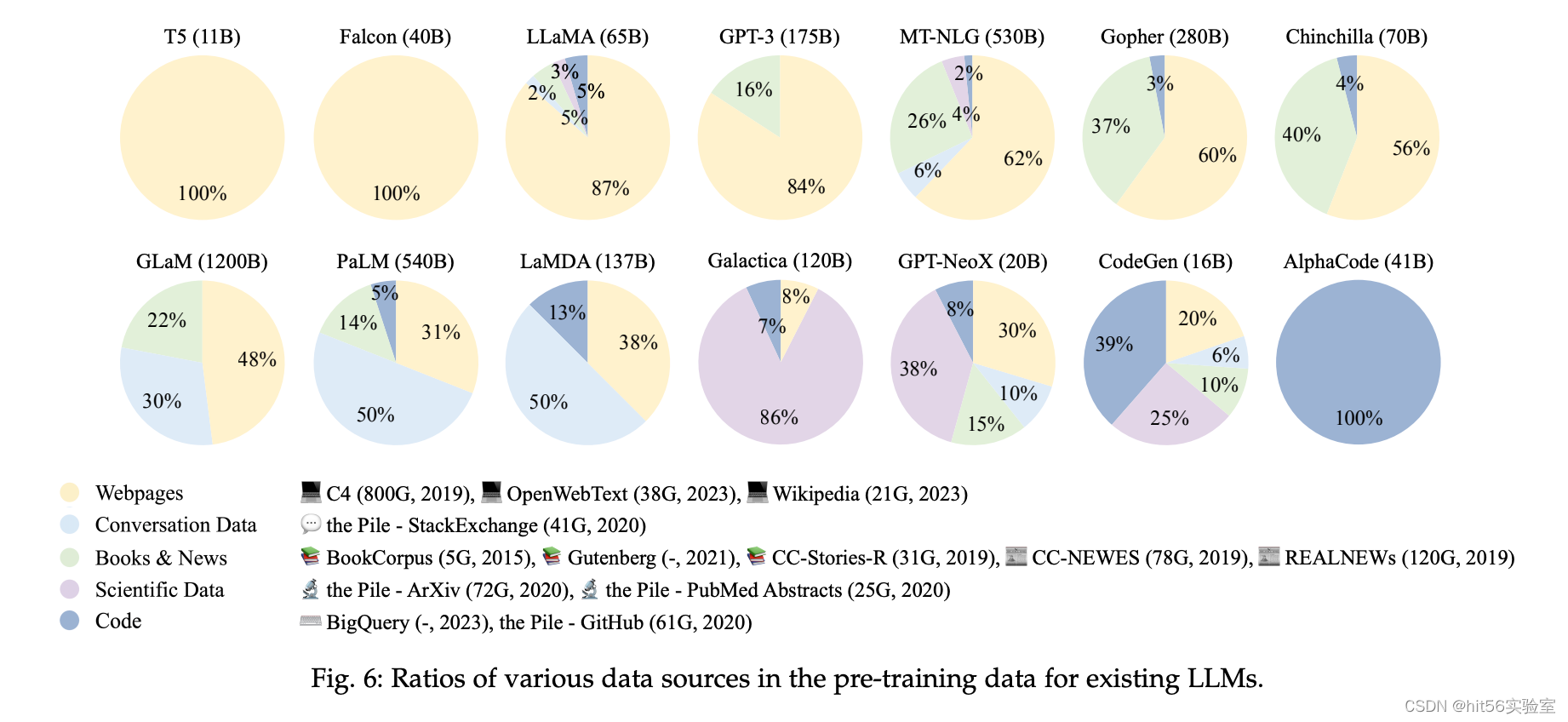
从下面不同的LLMs 预训练数据源分布,可以看出:垂直领域的模型之所以有价值,是因为有了垂直领域的数据:
7. LLaMA的网络结构
当前,绝大多数大语言模型都采用了类似GPT 的架构,但是在层归一化位置、归一化函数、激活函数、位置编码等细节上各有不同。LLaMA的模型结构如下:

8. 为什么需要残差网络
因为残差网络可以缓解梯度消失的现象,而缓解梯度消失的原因是,下面的连乘积即使由于网络太深导致最后接近0,但是由于1的存在,梯度就不会完全消失:
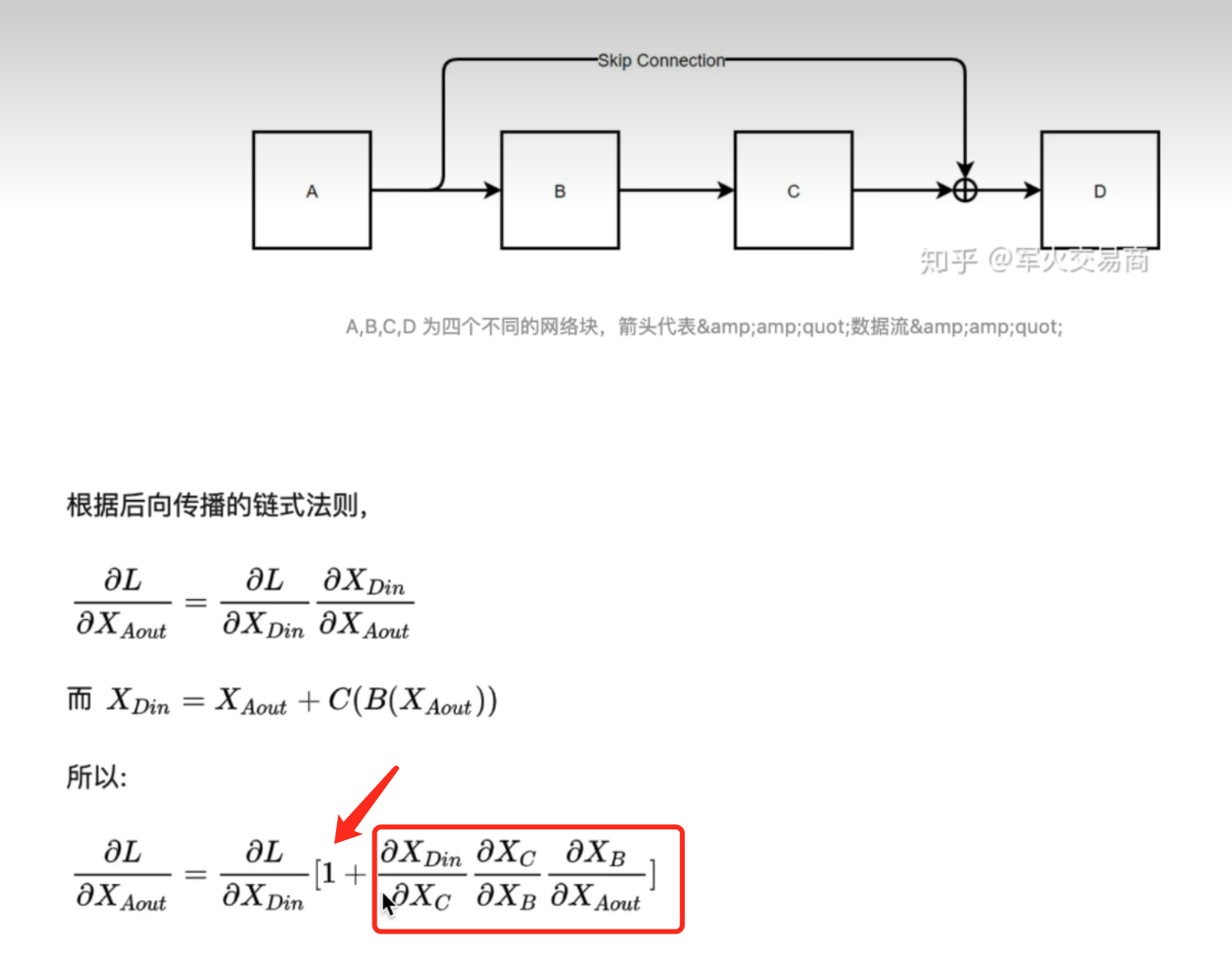
9. Transformer架构中,encoder给decoder传递的是什么?
encoder给decoder传递的是K、V矩阵,而decoder产生的Q矩阵。
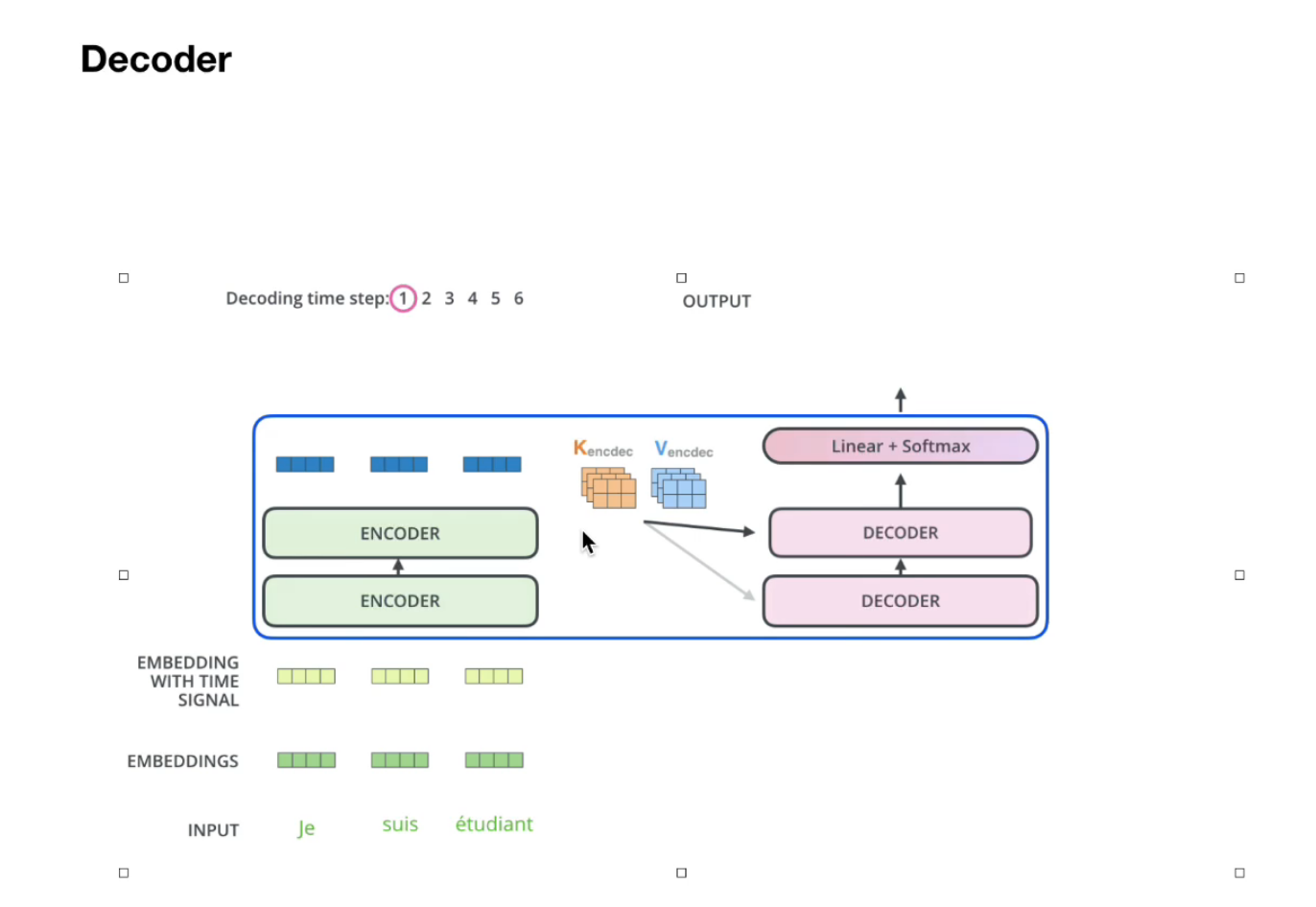
8. LLM从海量文本中学习到了什么
- 学到了“语言类知识”
LLM可以学习各种层次的语言学知识:浅层语言知识比如词法、词性、句法等知识存储在Transformer的低层和中层,而抽象的语言知识比如语义类知识,广泛分布在Transformer的中层和高层结构中。 - 学到了“世界知识”
世界知识指的是在这个世界上发生的一些真实事件(事实型知识,Factual Knowledge),以及一些常识性知识(Common Sense Knowledge)。比如“拜登是现任美国总统”、“拜登是美国人”、“乌克兰总统泽连斯基与美国总统拜登举行会晤”,这些都是和拜登相关的事实类知识;而“人有两只眼睛”、“太阳从东方升起”这些属于常识性知识。LLM确实从训练数据中吸收了大量世界知识,而这类知识主要分布在Transformer的中层和高层,尤其聚集在中层。而且,随着Transformer模型层深增加,能够学习到的知识数量逐渐以指数级增加(可参考:BERTnesia: Investigating the capture and forgetting of knowledge in BERT)。LLM可以看作是一种以模型参数体现的隐式知识图谱。
《When Do You Need Billions of Words of Pre-training Data?》这篇文章研究了预训练模型学习到的知识量与训练数据量的关系。它的结论是:对于Bert类型的语言模型来说,由于语言学知识相对有限且静态,只需1000万到1亿单词的语料,就能学好句法语义等语言学知识,但是如果要学习事实类知识,由于事实类知识则数量巨大,且处于不断变化过程中,则要更多的训练数据。随着训练数据量的增加,预训练模型在各种下游任务中效果越好,这说明从增量的训练数据中学到的更主要是世界知识。
12. 如何消除模型幻觉
首先,为什么会产生幻觉?这主要原因是用于训练语言模型的大数据语料库在收集时难免会包含一些错误的信息,这些错误知识都会被学习,存储在模型参数中,相关研究表明模型生成文本时会优先考虑自身参数化的知识,所以更倾向生成幻觉内容。
因此有以下几个可能的手段来减少幻觉:
- 数据阶段: 使用置信度更高的数据,消除原始数据中本来的错误和不一致地方。
- 训练阶段:有监督学习算法非常容易使得求知型查询产生幻觉。在模型并不包含或者知道答案的情况下,有监督训练仍然会促使模型给出答案。而使用强化学习方法,则可以通过定制奖励函数,将正确答案赋予非常高的分数,将放弃回答的答案赋予中低分数,将不正确的答案赋予非常高的负分,使得模型学会依赖内部知识选择放弃回答,从而在一定程度上缓解模型的幻觉问题。
- 基于后处理:在生成输出后,对其进行迭代评估和调整。对于摘要等任务,只有在生成整个摘要后才能准确评估,因此后期修正方法更为有效。缺点是不改变模型本身。
- 基于知识检索增强的方式:模型幻觉很大程度来源之一是外部知识选择不正确,因此用更强的检索模型搜索知识,返回更加有用的知识,也是消除对话回复幻觉的有效途径。
16. 思维链promting是啥
思维链(few-shot CoT,Chain of Thought)Prompting,这个方向目前是LLM推理研究的主方向。
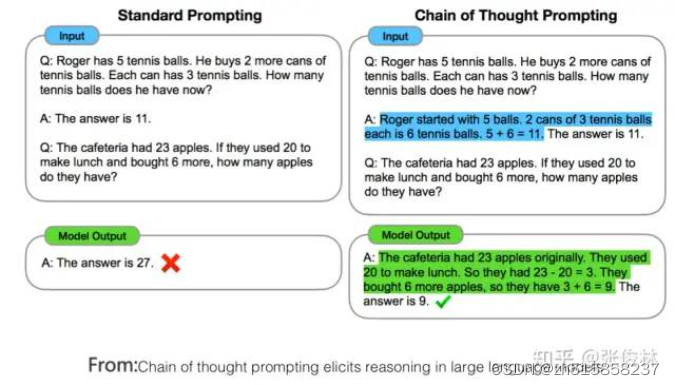
CoT的主体思想其实很直白;为了教会LLM模型学会推理,给出一些人工写好的推理示例,示例里把得到最终答案前,一步步的具体推理步骤说清楚,而这些人工写的详细推理过程,就是思维链Prompting,具体例子可参照上图中蓝色文字部分。CoT的意思是让LLM模型明白一个道理;就是在推理过程中,步子不要迈得太大,否则很容易出错,改变思维模式,化大问题为小问题,步步为营,积小胜为大胜。最早明确提出CoT这个概念的文章是“Chain of thought prompting elicits reasoning in large language models”,论文发布于22年1月份,虽然做法很简单,但是应用CoT后LLM模型的推理能力得到了巨大提升,GSM8K数学推理测试集准确率提高到60.1%左右。
17. chatGPT中的语言模型跟传统语言模型最大区别
目标不一样。传统语言模型主要是预测一句话中下一个词是什么。而instructGPT的目标是:Follow the user’s instructions helpfully, honestly, and harmlessly.。
18. 代码预训练可以增强LLM推理能力
以“Self Consistency”方法为例,在大多数据集合上的性能提升,都直接超过了20到50个百分点,这是很恐怖的性能提升,而其实在具体推理模型层面,我们什么也没做,仅仅是预训练的时候除了文本,额外加入了程序代码而已。
越大的LLM模型学习效率越高,也就是说相同训练数据量,模型越大任务效果越好,说明面对的即使是同样的一批训练数据,更大的LLM模型相对规模小一些的模型,从中学到了更多的知识。
当模型参数规模未能达到某个阀值时,模型基本不具备解决此类任务的任何能力,体现为其性能和随机选择答案效果相当,但是当模型规模跨过阀值,LLM模型对此类任务的效果就出现突然的性能增长。也就是说,模型规模是解锁(unlock)LLM新能力的关键,随着模型规模越来越大,会逐渐解锁LLM越来越多的新能力。思维链(Chain of Thought)Prompting是典型的增强LLM推理能力的技术,能大幅提升此类任务的效果。
问题是,为何LLM会出现这种“涌现能力”现象呢?上述文章以及《Emergent Abilities of Large Language Models》给出了几个可能的解释:
一种可能解释是有些任务的评价指标不够平滑。比如说有些生成任务的判断标准,它要求模型输出的字符串,要和标准答案完全匹配才算对,否则就是0分。所以,即使随着模型增大,其效果在逐步变好,体现为输出了更多的正确字符片段,但是因为没有完全对,只要有任何小
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2149
2149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}