







大纲:使用LTP分析中文语料
工具:Jupyter Notebook
版本:4.2.13、pyltp等
(1)安装LTP4.2.13解析器
!pip install ltp==4.2.13
## 下载地址http://github.com/HIT-SCIR/ltp报错
由于我正在魔法上网,显示
'ReadTimeoutError("HTTPSConnectionPool(host='files.pythonhosted.org', port=443): Read timed out. (read timeout=15)")':
解决方法
断开梯*子,安装完成。
安装还是很快的(比起stanza)。
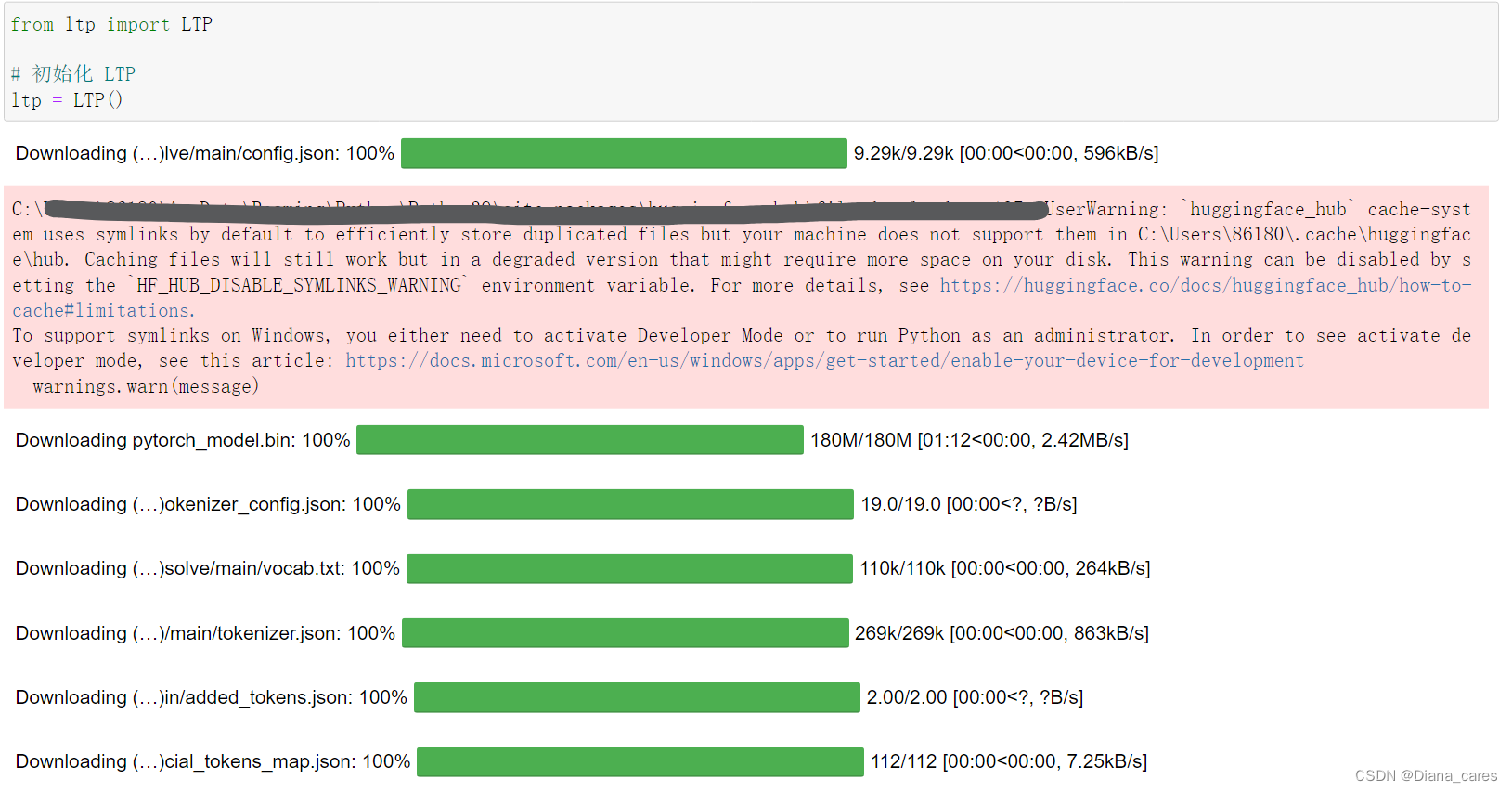
载入语言模型
报错
文件配置缺失
'(MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /LTP/small/resolve/main/config.json (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x0000023A9DDA5940>, 'Connection to huggingface.co timed out. (connect timeout=10)'))"), '(Request ID: 835b8bc1-022e-42da-ac94-942d553ee046)')' thrown while requesting HEAD https://huggingface.co/LTP/small/resolve/main/config.json
config.json not found in HuggingFace Hub
FileNotFoundError: config.json not found in LTP/small
解决方法
魔法上网重新下载 LTP 模型文件后,问题解决。
读取中文文本
# 读取文本文件
with open('OriTxt.txt', 'r', encoding='utf-8') as f:
text = f.read()
print("Text read from file:", text) 分析文本
分析文本
报错
AttributeError Traceback (most recent call last) ~\AppData\Local\Temp\ipykernel_1416\2863297660.py in <module> 1 # 分析文本 ----> 2 segments, hidden = ltp.seg(text) 3 pos_tags = ltp.pos(hidden) 4 ner_tags = ltp.ner(hidden) 5 srl = ltp.srl(hidden) ~\AppData\Roaming\Python\Python39\site-packages\torch\nn\modules\module.py in __getattr__(self, name) 1612 if name in modules: 1613 return modules[name] -> 1614 raise AttributeError("'{}' object has no attribute '{}'".format( 1615 type(self).__name__, name)) 1616 AttributeError: 'LTP' object has no attribute 'seg'
解决方法
LTP 对象没有 seg 这个属性:在 LTP 4.2.13 版本中,seg 方法已经被移除,相关的分词功能可能已经整合到了其他方法中。可以通过查看 LTP 的官方文档来获取最新的使用方法。
问题在于——找不到4.2.13 版本的说明文档o(╥﹏╥)o
(2)换用pyltp解析器
安装解析器+载入模型+分词测试
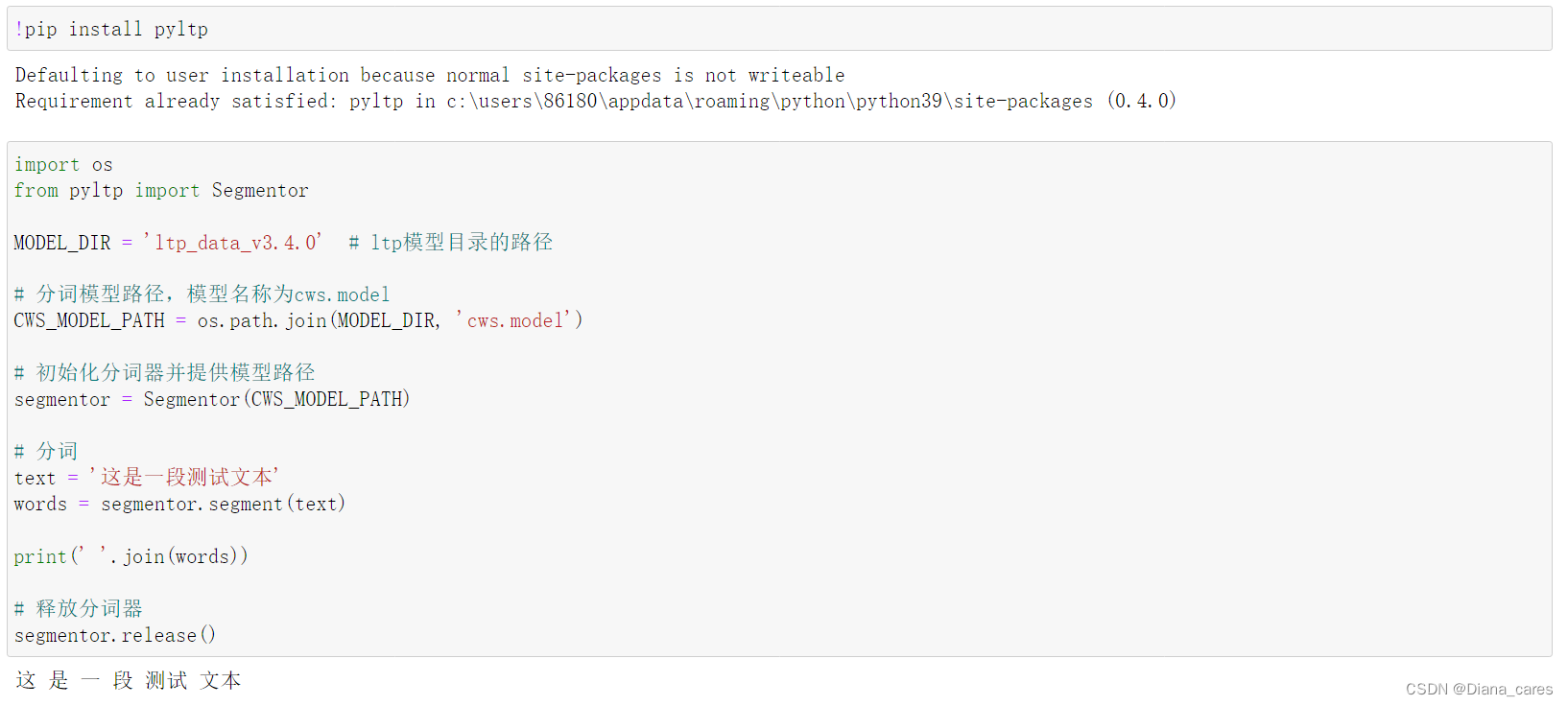
设置模型的路径
# 设置LTP模型目录的路径
MODEL_DIR = 'ltp_data_v3.4.0'
# 分词模型路径
CWS_MODEL_PATH = os.path.join(MODEL_DIR, 'cws.model')
# 词性标注模型路径
POS_MODEL_PATH = os.path.join(MODEL_DIR, 'pos.model')
# 依存句法分析模型路径
PARSER_MODEL_PATH = os.path.join(MODEL_DIR, 'parser.model')初始化
# 初始化分词器、词性标注器、依存句法分析器
segmentor = Segmentor()
postagger = Postagger()
parser = Parser()
# 加载模型
segmentor.load(CWS_MODEL_PATH)
postagger.load(POS_MODEL_PATH)
parser.load(PARSER_MODEL_PATH)报错
TypeError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_1416\258433275.py in <module>
15
16 # 初始化分词器、词性标注器、依存句法分析器
---> 17 segmentor = Segmentor()
18 postagger = Postagger()
19 parser = Parser()
TypeError: __init__(): incompatible constructor arguments. The following argument types are supported:
1. pyltp.Segmentor(model_path: str, lexicon_path: str = None, force_lexicon_path: str = None)
Invoked with:
解决方法
原方法先创建了实例,然后分别调用load方法加载模型。实质上和解决方法是一样的,不应该有区别。报错可能是因为在初始化时没有指定模型路径,尝试在初始化时传入模型路径:
# 初始化分词器、词性标注器、依存句法分析器
segmentor = Segmentor(CWS_MODEL_PATH)
postagger = Postagger(POS_MODEL_PATH)
parser = Parser(PARSER_MODEL_PATH)
已解决。
分析文本
# 读取文本文件
with open('OriTxt.txt', 'r', encoding='utf-8') as file:
# 打开结果文件以写入模式
with open('ResultChi.txt', 'w', encoding='utf-8') as result_file:
# 逐行处理
for line in file:
# 分词
words = segmentor.segment(line.strip())
# 词性标注
postags = postagger.postag(words)
# 依存句法分析
arcs = parser.parse(words, postags)
# 写入结果到文件
for i in range(len(words)):
result_file.write(f"词: {words[i]}, 词性: {postags[i]}, 依存关系: {arcs[i].relation})
# 释放资源
segmentor.release()
postagger.release()
parser.release()报错
AttributeError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_1416\1723950574.py in <module>
34 # 打印结果
35 for i in range(len(words)):
---> 36 print(f"词: {words[i]}, 词性: {postags[i]}, 依存关系: {arcs[i].head}, 关系类型: {arcs[i].relation}")
37
38 # 释放资源
AttributeError: 'tuple' object has no attribute 'head'
解决方法
这个错误表明 pyltp 库返回的 arcs 是一个元组(tuple),而不是一个对象,所以无法通过 .relation 访问属性。在 pyltp 中,arcs 返回的是一个包含多个元组的元组,每个元组表示一个词与其父节点的依存关系。
下面是修改后的代码:
import os
from pyltp import Segmentor, Postagger, Parser
# 设置LTP模型目录的路径
MODEL_DIR = 'ltp_data_v3.4.0'
# 分词模型路径
CWS_MODEL_PATH = os.path.join(MODEL_DIR, 'cws.model')
# 词性标注模型路径
POS_MODEL_PATH = os.path.join(MODEL_DIR, 'pos.model')
# 依存句法分析模型路径
PARSER_MODEL_PATH = os.path.join(MODEL_DIR, 'parser.model')
# 初始化分词器、词性标注器、依存句法分析器
segmentor = Segmentor()
postagger = Postagger()
parser = Parser()
# 加载模型
segmentor.load(CWS_MODEL_PATH)
postagger.load(POS_MODEL_PATH)
parser.load(PARSER_MODEL_PATH)
# 读取文本文件
with open('OriTxt.txt', 'r', encoding='utf-8') as file:
# 逐行处理
for line in file:
# 分词
words = segmentor.segment(line.strip())
# 词性标注
postags = postagger.postag(words)
# 依存句法分析
arcs = parser.parse(words, postags)
# 打印结果
for i in range(len(words)):
print(f"词: {words[i]}, 词性: {postags[i]}, 依存关系: {arcs[i][1]}")
## index修改
# 释放资源
segmentor.release()
postagger.release()
parser.release()这里修改了 print 语句中的 arcs[i].relation 为 arcs[i][1],因为 arcs[i] 是一个元组,arcs[i][1] 表示该元组的第二个元素,即依存关系。
根据 pyltp 的文档,它的 parse 方法返回的 arcs 元组包含两个元素,第一个是 head(父节点的索引),第二个是 relation(依存关系的标签)。
打印结果完成:
 并且保存在原目录下新文件'ResultChi.txt'中。
并且保存在原目录下新文件'ResultChi.txt'中。
# 读取文本文件
with open('OriTxt.txt', 'r', encoding='utf-8') as file:
# 打开结果文件以写入模式
with open('ResultChi.txt', 'w', encoding='utf-8') as result_file:
# 逐行处理
for line in file:
# 分词
words = segmentor.segment(line.strip())
# 词性标注
postags = postagger.postag(words)
# 依存句法分析
arcs = parser.parse(words, postags)
# 写入结果到文件
for i in range(len(words)):
result_file.write(f"词: {words[i]}, 词性: {postags[i]}, 依存关系: {arcs[i][1]}\n")pirsl.model
3.4.0 版本 SRL模型 pisrl.model 如在windows系统下不可用,可以到 此链接 下载支持windows的语义角色标注模型。
下载后直接放在model文件夹里。
http://model.scir.yunfutech.com/server/3.4.0/pisrl_win.model
完整代码
!pip install pyltp
import os
from pyltp import Segmentor, Postagger, Parser
# 设置LTP模型目录的路径
MODEL_DIR = 'ltp_data_v3.4.0'
# 分词模型路径
CWS_MODEL_PATH = os.path.join(MODEL_DIR, 'cws.model')
# 词性标注模型路径
POS_MODEL_PATH = os.path.join(MODEL_DIR, 'pos.model')
# 依存句法分析模型路径
PARSER_MODEL_PATH = os.path.join(MODEL_DIR, 'parser.model')
# 初始化分词器、词性标注器、依存句法分析器
segmentor = Segmentor(CWS_MODEL_PATH)
postagger = Postagger(POS_MODEL_PATH)
parser = Parser(PARSER_MODEL_PATH)
# 读取文本文件
with open('OriTxt.txt', 'r', encoding='utf-8') as file:
# 打开结果文件以写入模式
with open('ResultChi.txt', 'w', encoding='utf-8') as result_file:
# 逐行处理
for line in file:
# 分词
words = segmentor.segment(line.strip())
# 词性标注
postags = postagger.postag(words)
# 依存句法分析
arcs = parser.parse(words, postags)
# 写入结果到文件
for i in range(len(words)):
result_file.write(f"词: {words[i]}, 词性: {postags[i]}, 依存关系: {arcs[i][1]}\n")
# 释放资源
segmentor.release()
postagger.release()
parser.release()














 2596
2596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









