







基本动态系统模型
卡尔曼滤波建立在线性代数和隐马尔可夫模型(hidden Markov model)上。其基本动态系统可以用一个马尔可夫链表示,该马尔可夫链建立在一个被高斯噪声(即正态分布的噪声)干扰的线性算子上的。系统的状态可以用一个元素为实数的向量表示。随着离散时间的每一个增加,这个线性算子就会作用在当前状态上,产生一个新的状态,并也会带入一些噪声,同时系统的一些已知的控制器的控制信息也会被加入。同时,另一个受噪声干扰的线性算子产生出这些隐含状态的可见输出。
为了从一系列有噪声的观察数据中用卡尔曼滤波器估计出被观察过程的内部状态,我们必须把这个过程在卡尔曼滤波的框架下建立模型。也就是说对于每一步k,定义矩阵Fk, Hk, Qk,Rk,有时也需要定义Bk,如下。

卡尔曼滤波模型假设k时刻的真实状态是从(k − 1)时刻的状态演化而来,符合下式:

其中
- Fk是作用在xk−1上的状态变换模型(/矩阵/矢量)。
- Bk是作用在控制器向量uk上的输入-控制模型。
- wk是过程噪声,并假定其符合均值为零,协方差矩阵为Qk的多元正态分布。
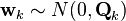
时刻k,对真实状态xk的一个测量zk满足下式:
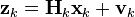
其中Hk是观测模型,它把真实状态空间映射成观测空间,vk是观测噪声,其均值为零,协方差矩阵为Rk,且服从正态分布。

初始状态以及每一时刻的噪声{x0, w1, ..., wk, v1 ... vk}都认为是互相独立的。
实际上,很多真实世界的动态系统都并不确切的符合这个模型;但是由于卡尔曼滤波器被设计在有噪声的情况下工作,一个近似的符合已经可以使这个滤波器非常有用了。更多其它更复杂的卡尔曼滤波器的变种,在下边讨论中有描述。
卡尔曼滤波器
卡尔曼滤波是一种递归的估计,即只要获知上一时刻状态的估计值以及当前状态的观测值就可以计算出当前状态的估计值,因此不需要记录观测或者估计的历史信息。卡尔曼滤波器与大多数滤波器不同之處,在於它是一种纯粹的时域滤波器,它不需要像低通滤波器等频域滤波器那样,需要在频域设计再转换到时域实现。
卡尔曼滤波器的状态由以下两个变量表示:
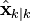 ,在时刻k的状态的估计;
,在时刻k的状态的估计;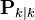 ,误差相关矩阵,度量估计值的精确程度。
,误差相关矩阵,度量估计值的精确程度。
卡尔曼滤波器的操作包括两个阶段:预测与更新。在预测阶段,滤波器使用上一状态的估计,做出对当前状态的估计。在更新阶段,滤波器利用对当前状态的观测值优化在预测阶段获得的预测值,以获得一个更精确的新估计值。
预测
-
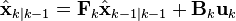 (预测状态)
(预测状态)
-
 (预测估计协方差矩阵)
(预测估计协方差矩阵)
-
更新
首先要算出以下三个量:
-
 (测量余量,measurement residual)
(测量余量,measurement residual)
-
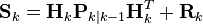 (测量余量协方差)
(测量余量协方差)
-
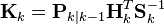 (最优卡尔曼增益)
(最优卡尔曼增益)
然后用它们来更新滤波器变量x与P:
-
 (更新的状态估计)
(更新的状态估计)
-
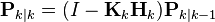 (更新的协方差估计)
(更新的协方差估计)
使用上述公式计算仅在最优卡尔曼增益的时候有效。使用其他增益的话,公式要复杂一些,请参见推导。
不变量(Invariant)
如果模型准确,而且 与
与 的值准确的反映了最初状态的分布,那么以下不变量就保持不变:所有估计的误差均值为零
的值准确的反映了最初状态的分布,那么以下不变量就保持不变:所有估计的误差均值为零
![\textrm{E}[\textbf{x}_k - \hat{\textbf{x}}_{k|k}] = \textrm{E}[\textbf{x}_k - \hat{\textbf{x}}_{k|k-1}] = 0](https://upload.wikimedia.org/math/4/c/4/4c4bbb2da083dae032f5a7930e7b5d80.png)
![\textrm{E}[\tilde{\textbf{y}}_k] = 0](https://upload.wikimedia.org/math/0/0/7/00703cccab98e464367ae2b34e9b1493.png)
且协方差矩阵准确的反映了估计的协方差:

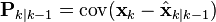
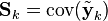
请注意,其中![\textrm{E}[\textbf{a}]](https://upload.wikimedia.org/math/c/d/3/cd34547a1cd577a331c13c681b2d1bf8.png) 表示
表示 的期望值,
的期望值, ![\textrm{cov}(\textbf{a}) = \textrm{E}[\textbf{a}\textbf{a}^T]](https://upload.wikimedia.org/math/d/2/7/d27f414efcd30770cfb2e541b1a61972.png) 。
。
实例
考虑在无摩擦的、无限长的直轨道上的一辆车。该车最初停在位置0处,但时不时受到随机的冲击。我们每隔△t秒即测量车的位置,但是这个测量是非精确的;我们想建立一个关于其位置以及速度的模型。我们来看如何推导出这个模型以及如何从这个模型得到卡尔曼滤波器。
因为车上无动力,所以我们可以忽略掉Bk和uk。由于F、H、R和Q是常数,所以时间下标可以去掉。
车的位置以及速度(或者更加一般的,一个粒子的运动状态)可以被线性状态空间描述如下:

其中 是速度,也就是位置对于时间的导数。
是速度,也就是位置对于时间的导数。
我们假设在(k-1)时刻与k时刻之间,车受到ak的加速度,其符合均值为0,标准差为σa的正态分布。根据牛顿运动定律,我们可以推出
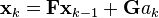
其中

且

我们可以发现
-
![\textbf{Q} = \textrm{cov}(\textbf{G}a) = \textrm{E}[(\textbf{G}a)(\textbf{G}a)^{T}] = \textbf{G} \textrm{E}[a^2] \textbf{G}^{T} = \textbf{G}[\sigma_a^2]\textbf{G}^{T} = \sigma_a^2 \textbf{G}\textbf{G}^{T}](https://upload.wikimedia.org/math/d/e/e/dee0b505f8b7b5270725e5f544fb53e4.png) (因为σa是一个标量)。
(因为σa是一个标量)。
在每一时刻,我们对其位置进行测量,测量受到噪声干扰。我们假设噪声服从正态分布,均值为0,标准差为σz。
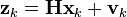
其中

且
![\textbf{R} = \textrm{E}[\textbf{v}_k \textbf{v}_k^{T}] = \begin{bmatrix} \sigma_z^2 \end{bmatrix}](https://upload.wikimedia.org/math/b/c/3/bc31fd596ea83fc789506857ab672644.png)
如果我们知道足够精确的车最初的位置,那么我们可以初始化

并且,我们告诉滤波器我们知道确切的初始位置,我们给出一个协方差矩阵:
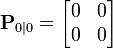
如果我們不确切的知道最初的位置与速度,那么协方差矩阵可以初始化为一个对角线元素是B的矩阵,B取一个合适的比较大的数。
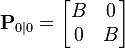
此时,与使用模型中已有信息相比,滤波器更倾向于使用初次测量值的信息。
推导后验协方差矩阵
按照上边的定义,我们从误差协方差开始推导如下:
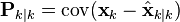
代入

再代入 

与

整理误差向量,得
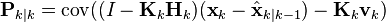
因为测量误差vk与其他项是非相关的,因此有
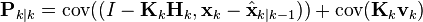
利用协方差矩阵的性质,此式可以写作

使用不变量Pk|k-1以及Rk的定义这一项可以写作 : 这一公式对于任何卡尔曼增益Kk都成立。如果Kk是最优卡尔曼增益,则进一步简化,請見下文。
这一公式对于任何卡尔曼增益Kk都成立。如果Kk是最优卡尔曼增益,则进一步简化,請見下文。
最优卡尔曼增益的推导
卡尔曼滤波器是一个最小均方误差估计器,后验状态误差估计(英文:a posteriori state estimate)是

我们最小化这个矢量幅度平方的期望值,![\textrm{E}[|\textbf{x}_{k} - \hat{\textbf{x}}_{k|k}|^2]](https://upload.wikimedia.org/math/d/a/c/dac65520055c06e789c58462cc7b7738.png) ,这等同于最小化后验估计协方差矩阵Pk|k的迹(trace)。将上面方程中的项展开、抵消,得到:
,这等同于最小化后验估计协方差矩阵Pk|k的迹(trace)。将上面方程中的项展开、抵消,得到:

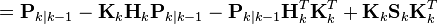
当矩阵导数是0的时候得到Pk|k的迹(trace)的最小值:

此处须用到一個常用的式子,如下:
从这个方程解出卡尔曼增益Kk:


这个增益称为最优卡尔曼增益,在使用时得到最小均方误差。
后验误差协方差公式的化简
在卡尔曼增益等于上面导出的最优值时,计算后验协方差的公式可以进行简化。在卡尔曼增益公式两侧的右边都乘以SkKkT得到
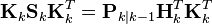
根据上面后验误差协方差展开公式,
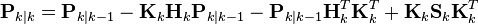
最后两项可以抵消,得到
-
 .
.
这个公式的计算比较简单,所以实际中总是使用这个公式,但是需注意这公式仅在使用最优卡尔曼增益的时候它才成立。如果算术精度总是很低而导致数值稳定性出现问题,或者特意使用非最优卡尔曼增益,那么就不能使用这个简化;必须使用上面导出的后验误差协方差公式。
Python代码
- # -*- coding=utf-8 -*-
- # Kalman filter example demo in Python
- # A Python implementation of the example given in pages 11-15 of "An
- # Introduction to the Kalman Filter" by Greg Welch and Gary Bishop,
- # University of North Carolina at Chapel Hill, Department of Computer
- # Science, TR 95-041,
- # http://www.cs.unc.edu/~welch/kalman/kalmanIntro.html
- # by Andrew D. Straw
- #coding:utf-8
- import numpy
- import pylab
- #这里是假设A=1,H=1的情况
- # 参数初始化
- n_iter = 50
- sz = (n_iter,) # size of array
- x = -0.37727 # truth value (typo in example at top of p. 13 calls this z)真实值
- z = numpy.random.normal(x,0.1,size=sz) # observations (normal about x, sigma=0.1)观测值
- Q = 1e-5 # process variance
- # 分配数组空间
- xhat=numpy.zeros(sz) # a posteri estimate of x 滤波估计值
- P=numpy.zeros(sz) # a posteri error estimate滤波估计协方差矩阵
- xhatminus=numpy.zeros(sz) # a priori estimate of x 估计值
- Pminus=numpy.zeros(sz) # a priori error estimate估计协方差矩阵
- K=numpy.zeros(sz) # gain or blending factor卡尔曼增益
- R = 0.1**2 # estimate of measurement variance, change to see effect
- # intial guesses
- xhat[0] = 0.0
- P[0] = 1.0
- for k in range(1,n_iter):
- # 预测
- xhatminus[k] = xhat[k-1] #X(k|k-1) = AX(k-1|k-1) + BU(k) + W(k),A=1,BU(k) = 0
- Pminus[k] = P[k-1]+Q #P(k|k-1) = AP(k-1|k-1)A' + Q(k) ,A=1
- # 更新
- K[k] = Pminus[k]/( Pminus[k]+R ) #Kg(k)=P(k|k-1)H'/[HP(k|k-1)H' + R],H=1
- xhat[k] = xhatminus[k]+K[k]*(z[k]-xhatminus[k]) #X(k|k) = X(k|k-1) + Kg(k)[Z(k) - HX(k|k-1)], H=1
- P[k] = (1-K[k])*Pminus[k] #P(k|k) = (1 - Kg(k)H)P(k|k-1), H=1
- pylab.figure()
- pylab.plot(z,'k+',label='noisy measurements') #观测值
- pylab.plot(xhat,'b-',label='a posteri estimate') #滤波估计值
- pylab.axhline(x,color='g',label='truth value') #真实值
- pylab.legend()
- pylab.xlabel('Iteration')
- pylab.ylabel('Voltage')
- pylab.figure()
- valid_iter = range(1,n_iter) # Pminus not valid at step 0
- pylab.plot(valid_iter,Pminus[valid_iter],label='a priori error estimate')
- pylab.xlabel('Iteration')
- pylab.ylabel('$(Voltage)^2$')
- pylab.setp(pylab.gca(),'ylim',[0,.01])
- pylab.show()
运行结果

















 876
876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









