







 本文介绍了如何使用Python的Tushare库获取上证50指数成分及权重,包括安装步骤、数据导入技巧、数据库操作及关键数据筛选。
本文介绍了如何使用Python的Tushare库获取上证50指数成分及权重,包括安装步骤、数据导入技巧、数据库操作及关键数据筛选。
ID:470827
第一次写文章请多多包涵,内容偏基础,主要自身 Python 水平不够,不太熟悉。
Tushare大数据社区 是国内开源免费的财经数据接口,数据丰富、获取简单、落地方便。具体可以在 Tushare 官网浏览,有8类数据接口可供选择。

安装Tushare:
首先 python 建议直接 安装 Anaconda 可以免去很多不便之处,包含大量的科学包,不过 Tushare等还需要手动用pip安装。
pip install tushare
上下两种方法均可,下面走的是清华镜像源,速度比较快。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tushare
本篇文章所需 import 库在此展示,以及 pandas 设置,在默认设置情况下超出一定行数或列数会折叠数据,根据需要选择以下设置,以便更好在控制台展示数据。
import tushare as ts
import pandas as pd
from sqlalchemy import create_engine
from sqlalchemy.types import VARCHAR, FLOAT
pd.set_option('expand_frame_repr', False) # True就是可以换行显示。设置成False的时候不允许换行
pd.set_option('display.max_columns', None) # 显示所有列
pd.set_option('display.max_rows', None) # 显示所有行
pd.set_option('colheader_justify', 'centre') # 显示居中对于 Pandas 不了解的可以先概览 教程 ,特别是 Pandas - DataFrame 一定要了解,Tushare 接口的返回格式均为 DataFrame ,可以用图中 type() 方法显示数据类型。
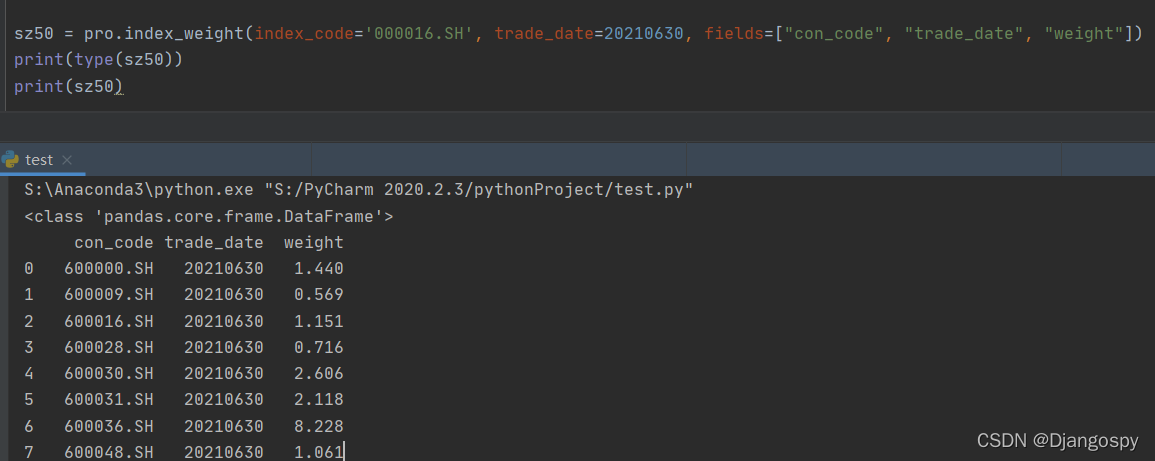
本次我们获取上证50 指数成分和权重 可以通过此连接进入 Tushare 官网查看具体样例。Tushare 官网为我们提供了 数据工具 可以在线输入参数调试并一键生成代码,复制到本地运行即可进一步调试。
index_code为指数代码,上证50:000016.SH,上证180:000010.SH,沪深300:399300.SZ。SH、SZ为上海深圳缩写,具体百度就可以获取代码。
sz50 = pro.index_weight(index_code='000016.SH', trade_date=20210630,
fields=["con_code", "trade_date", "weight"])trade_date 参数我当时找了好久,一直提示查不到数据,后来发现通过 start_date 与 end_date 两个参数可以获取两段时间内的 trade_date。再通过查出来的 trade_date 查询具体成分股与权重。(注:上证50成分股半年调整一次,一般在6月与12月,查询出来的其他月份为权重调整)
def getSZ50TradeDate():
start_date = int(input('上证50筛选开始时段:'))
end_date = int(input('上证50筛选结束时段:'))
sz50 = pro.index_weight(index_code='000016.SH', start_date=start_date,
end_date=end_date, fields=["trade_date"])
list = [];
count = 0
print("\n上证50 trade_date:")
for i in sz50["trade_date"]:
if (i not in list):
list.append(i)
for i in reversed(list):
print(i, end=" ")
count += 1
if count % 10 == 0:
print(end="\n")上面代码为获取交易日期,由于默认输出为倒叙不方便查看,将DataFrame格式转为List,reversed()一下,并且一行十个输出。
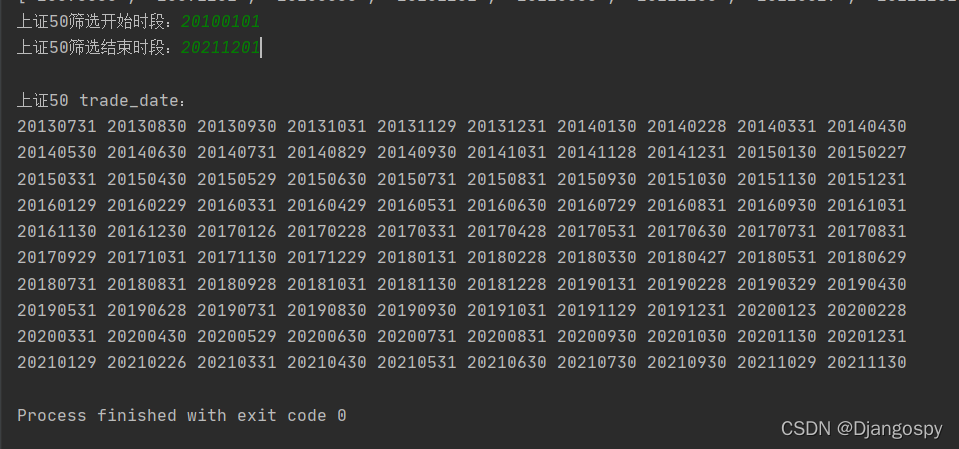
该接口至多返回100条数据,想要以往数据需要多次查询,接口最早数据为20090401,并且09-12年左右权重是一天调整一次,会查询出很多无用信息,想要查看成分股以往变动日期如下,我一个个查询过并对比 上证50官网 历史调整记录,想要看哪些股调入调出可以至 官网 查询。
# 历史上证50成分股变化日期
list=['20090630','20091231','20100630','20101231','20110630','20111230',
'20120629','20121231','20130628','20131231','20140630','20141231',
'20150630','20151231','20160630','20161230','20170630','20171229',
'20180629','20181228','20190628','20191231','20200630','20201231',
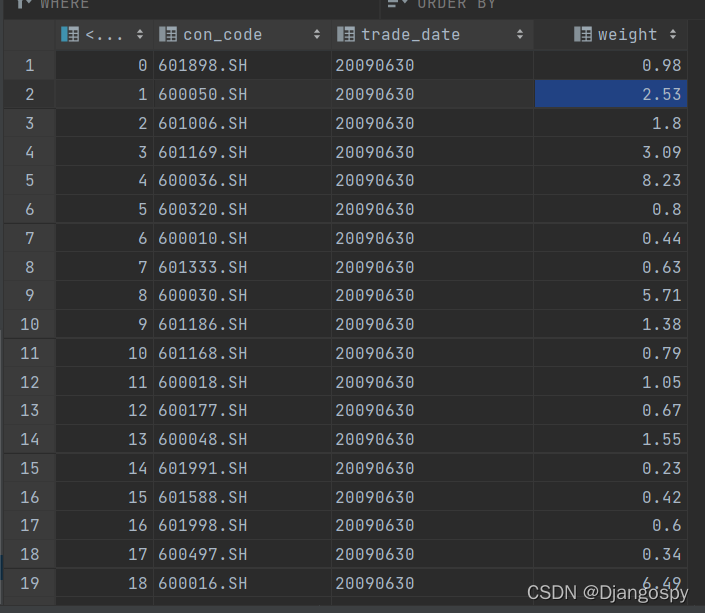
'20210630']这里用到了 ORM 框架 Sqlalchemy 来操作数据库,与以往通过 cursor() 操作数据库有些类似。ORM框架的作用就是把数据库表的一行记录与一个对象互相做自动转换。与 Tushare 相性较好,可以通过 to_sql 方法很容易将 list 存入数据库。
engine = create_engine('mysql+pymysql://root:root@localhost:3306/shares?charset=utf8')
for i in list:
print(' 正在写入 ' + i + ' 上证50成分股与权重')
sz50 = pro.index_weight(index_code='000016.SH', trade_date=i,
fields=["con_code", "trade_date", "weight"])
dtypedict = {
'con_code': VARCHAR(length=10),
'weight': FLOAT()
}
sz50.to_sql('sz50_index_weight', engine, if_exists='append', dtype=dtypedict)
engine.dispose()
print('写入完毕,数据库连接关闭')for 循环写入list中的历史成分股数据,当然如果只需写入一个 trade_date 去掉 for 循环即可。dtypedict 是 to_sql中的一个参数,用来对应数据库中的字段类型。这里奉上pandas.DataFrame.to_sql 官方文档 供大家参考。这里简单解释一下sz50.to_sql语句中的参数。
name:数据库名
engine:数据库连接
if_exists:如果存在数据可以选择 fail、replace、append 三个参数,即字面意思
dtype:对应数据库中的字段类型,建议写在外面比较方便阅读修改。记得要 import sqlalchemy.types 写法参考上文,可以很方便的将一些默认的 text 类型转为 VARCHAR(要记得写长度),或者转为你需要的类型。不过要注意的是,比如将 text 类型转为 VARCHAR ,那么所有 text 类型都将转为 VARCHAR。

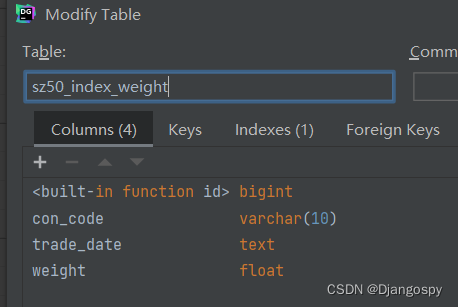
执行完后就能看到表结构都已经是改成功了。

















 2008
2008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









