







protobuf快速上手
一,序列化与反序列化
🚀序列化:将结构化数据转化为字节序列的过程叫做序列化。
🚀反序列化:将字节序列转化为结构化的数据叫做反序列化。
序列化与反序列化的场景
🚀网络传输:在网络传输中,通常不是直接传输对象这种结构化的数据,而是先将其序列化,接收端在接收后再将其反序列化为对象。
🚀数据持久化:将数据持久化存储在文件或者是数据库中时,也要做序列化处理。
常用的工具
🚀常用的工具有json,xml,protobuf。
protobuf与前两者不同的是,经过protobuf序列化后形成的是二进制序列,前两者形成的是文本序列。
二,protobuf工作原理
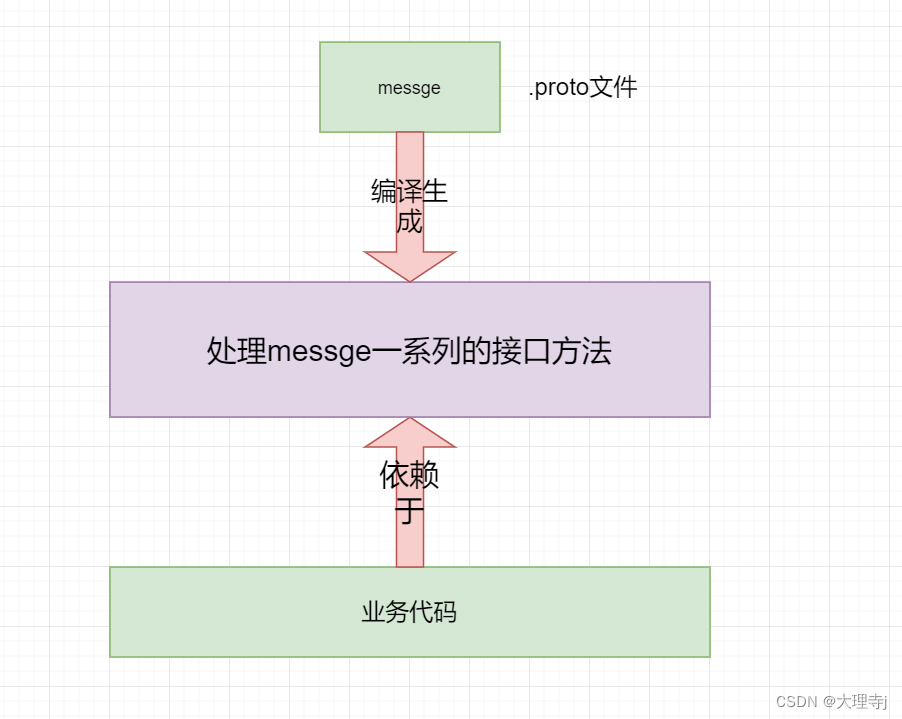
🚀将.proto文件编译生成.h和.cc文件(以C++为例),编译生成的头文件和源文件中就实现了序列化和反序列化以及对字段的set和get方法等。
🚀我们的业务代码是依赖于生成的头文件和源文件的。
三,快速上手
protobuf中的数据类型
🚀prtobuf中的数据类型分为:标量数据类型和特殊数据类型。
标量数据类型如下:
| type | notes | C++ type |
|---|---|---|
| double | double | |
| float | float | |
| int32 | 使⽤变⻓编码[1]。负数的编码效率较低⸺——若字段可能为负值,应使⽤sint32代替。 | int32 |
| int64 | 使⽤变⻓编码[1]。负数的编码效率较低⸺——若字段可能为负值,应使⽤sint64代替。 | int64 |
| uint32 | 使⽤变⻓编码[1]。 | uint32 |
| uint64 | 使⽤变⻓编码[1]。 | uint64 |
| sint32 | 使⽤变⻓编码[1]。符号整型。负值的编码效率⾼于常规的int32类型。 | int32 |
| sint64 | 使⽤变⻓编码[1]。符号整型。负值的编码效率⾼于常规的int64类型。 | int64 |
| fixed32 | 定⻓4字节。若值常⼤于2^28则会⽐uint32更⾼效。 | uint32 |
| fixed64 | 定⻓8字节。若值常⼤于2^56则会⽐uint64更⾼效。 | uint64 |
| sfixed32 | 定⻓4字节。 | int 32 |
| sfixed64 | 定⻓8字节。 | int64 |
| bool | bool | |
| string | 包含UTF-8和ASCII编码的字符串,⻓度不能超过2^32。 | string |
| bytes | 可包含任意的字节序列但⻓度不能超过2^32。 | string |
.proto文件格式
//在.proto问价手举声明语法版本
syntax = “proto3”;
//packeage声明符
package XXX; //这就是一个命名空间,防止明明污染
//定义消息 messge
//messge命名规范使用驼峰法命名,首字母大写
messge PeopleInfo
{
string name = 1; //这里的1为字段标号
int age = 2; //字段编号1-2^29 - 1 其中19000-19999不可用(在protobuf协议实现时进行了预留)。
}
🚀messge就如同C++中的class一样。
编译选项
protoc -I proto文件的路径--cpp_out=./(目标文件生成的路径 ./代表当前路径下) XXX.proto(要编译的proto文件)
🚀不写-I选项表示在当前路径下搜索.proto文件。
syntax = "proto3";
package contacts;
message PeopleInfo
{
string name = 1;
int32 age = 2;
};
protoc --cpp_out=./ contacts.proto
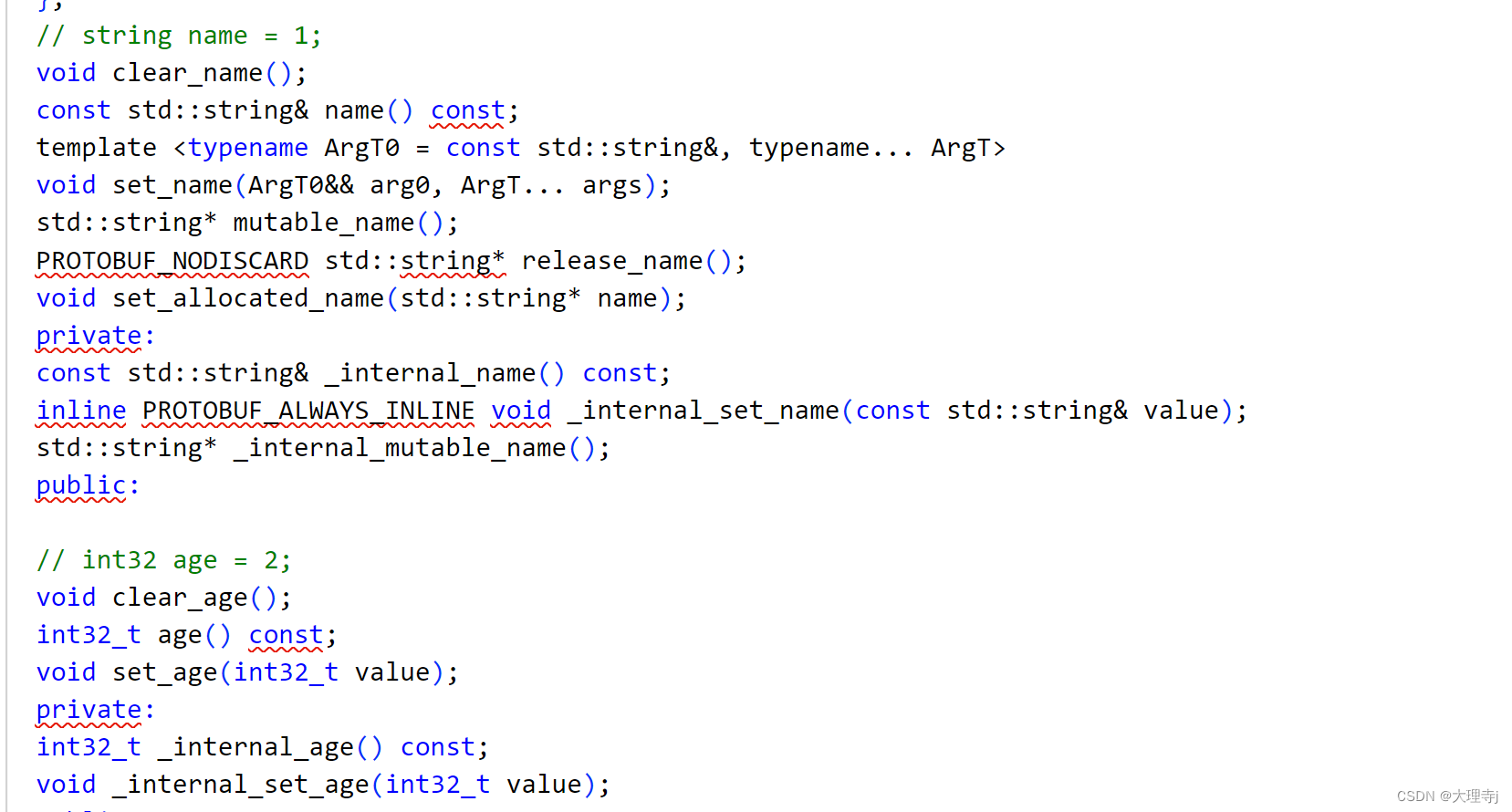
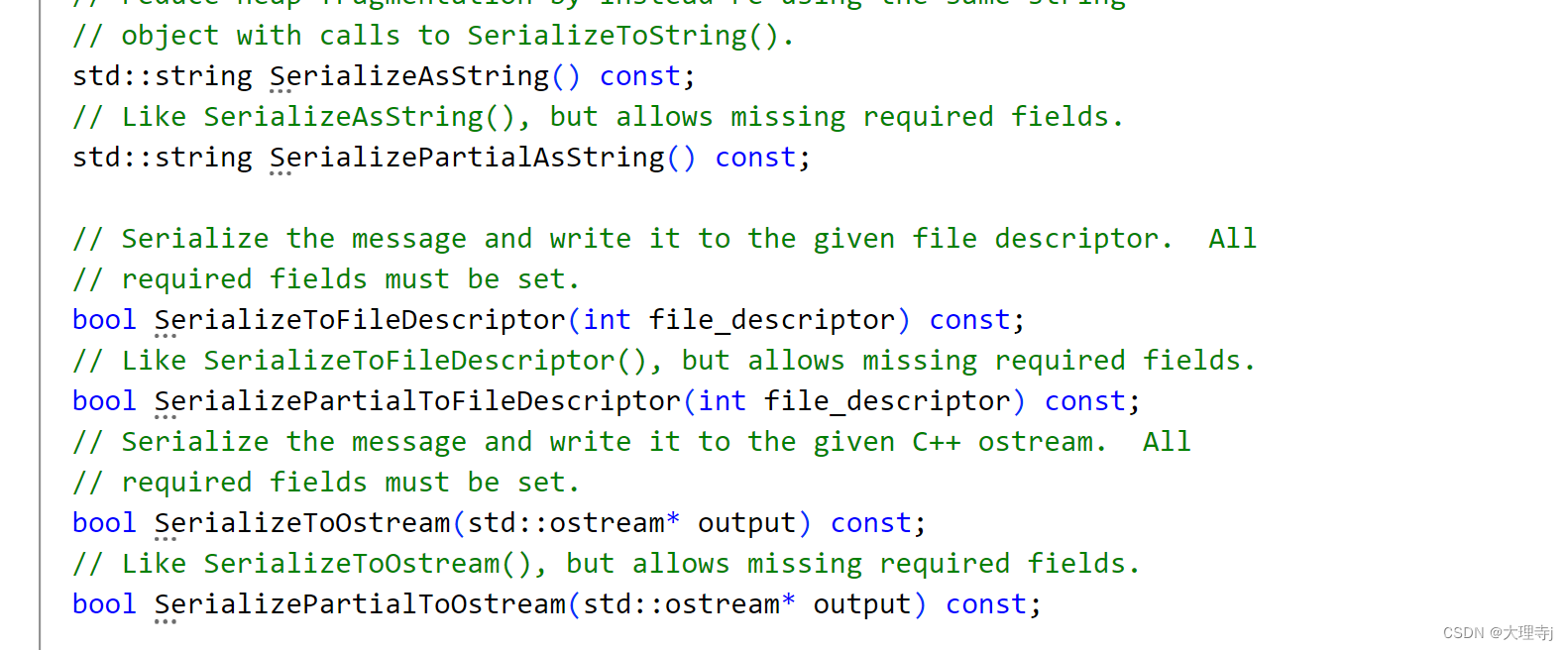
编译后生成了头文件和源文件,里面实现了属性字段的get/set方法,以及序列化和反序列化方法。
快速上手
🚀将上述的PeopleInfo对象,进行序列化和反序列化,并将结果打印出来。
#include <iostream>
#include <string>
#include "contacts.pb.h"
using namespace std;
int main()
{
GOOGLE_PROTOBUF_VERIFY_VERSION;
// GOOGLE_PROTOBUF_VERIFY_VERSION
//宏: 验证没有意外链接到与编译的头⽂件不兼容的库版本。
//如果检测到版本不匹配,程序将中⽌。注意,每个 .pb.cc ⽂件在启动时都会⾃动调⽤此宏。
//在使⽤ C++ Protocol Buffer 库之前执⾏此宏是⼀种很好的做法,但不是绝对必要的。
string people_str;
contacts::PeopleInfo people;
people.set_name("赵四");
people.set_age(29);
if (!people.SerializeToString(&people_str))
{
cout << "序列化错误" << endl;
return -1;
}
cout << "序列化成功 : " << people_str << endl;
contacts::PeopleInfo person;
if (!person.ParseFromString(people_str))
{
cout << "反序列化错误" << endl;
return -1;
}
cout << "反序列化成功:" << endl
<< "姓名:" << person.name() << endl
<< "年龄:" << person.age() << endl;
google::protobuf::ShutdownProtobufLibrary();
// 在程序结束时调⽤ ShutdownProtobufLibrary(),
//为了删除 Protocol Buffer 库分配的所有全局对象。
//对于⼤多数程序来说这是不必要的,因为该过程⽆论如何都要退出,
//并且操作系统将负责回收其所有内存。
//但是,如果你使⽤了内存泄漏检查程序,该程序需要释放每个最后对象,
//或者你正在编写可以由单个进程多次加载和卸载的库,
//那么你可能希望强制使⽤ Protocol Buffers 来清理所有内容。
return 0;
}
🚀由于protobuf实现时使用了C++11的语法所以要加-std=c++11的编译选项,并且使用了libprotobuf.so的第三方库,也要加上编译选项-lprotobuf。
四,通讯录demo
🚀写一个通讯录的demo,将通讯录的信息序列化后写入到文件中,再将文件中的数据读取出来并反序列化得到结构化数据。
编写proto文件
syntax = "proto3";
package phone;
message Phone{
string phone_numbers = 1;
}
syntax = "proto3";
package contacts2;
//1.一个proto文件可以定义多个messge(消息体)
message Phone{
string number = 1;
}
//3.可以将另一个proto文件中的消息体引入
//import "phone.proto";
message PeopleInfo{
string name = 1; //字段编号
int32 age = 2;
//2.支持嵌套定义
// messge Phone{
// string phone_numbers = 1;
// }
//repeated 关键字用来定义数组
//repeated Phone.Phone phone_array = 3;
repeated Phone phone_array = 3;
}
message Contact{
repeated PeopleInfo people = 1;
}
🚀repeated关键字就类似于C++中定义数组。
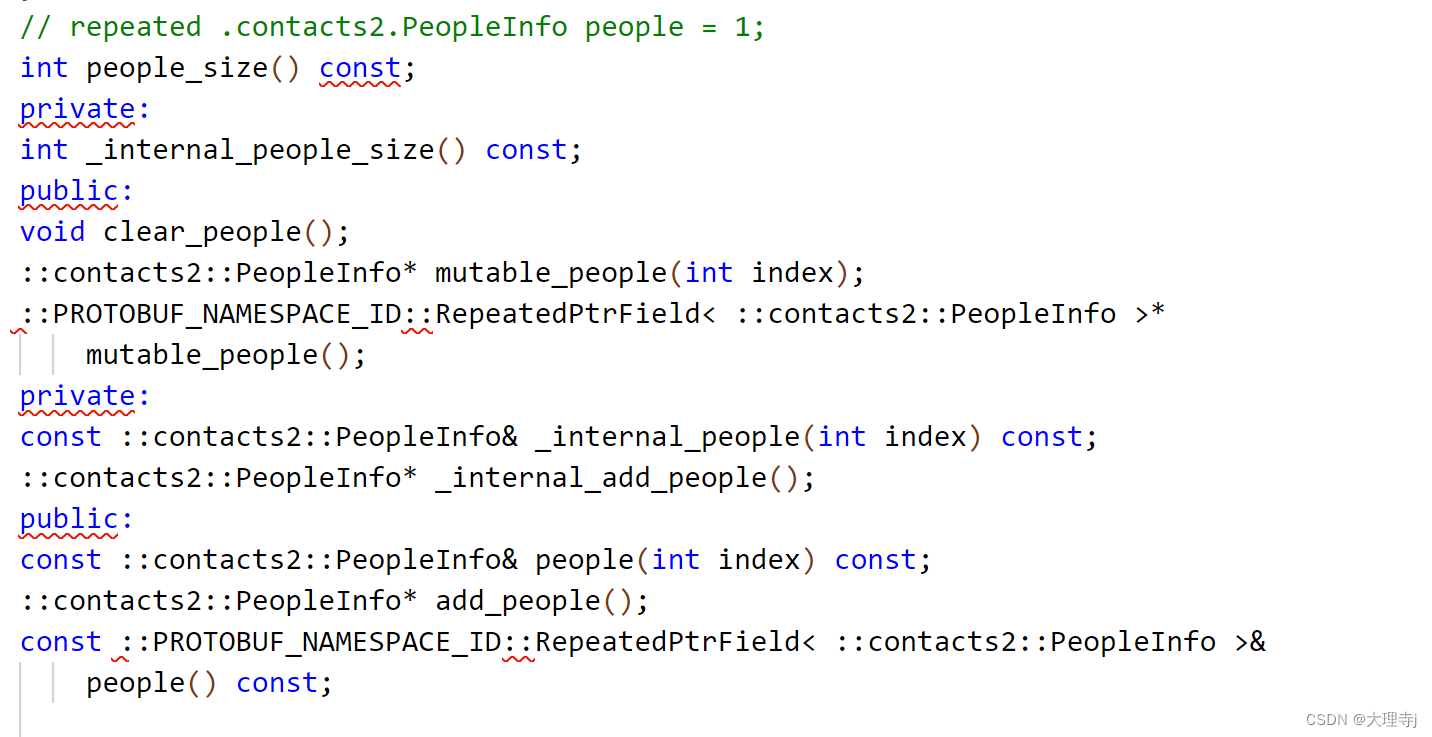
🚀对于Contact类中存储的PeopleInfo的数组,所以提供 了获取数组大小,获取数组某个下标的元素,添加数组元素等方法。
编写C++代码
main.cc
#include <iostream>
#include <fstream>
#include "contacts.pb.h"
using namespace std;
bool AddPerson(contacts2::PeopleInfo *p)
{
string name;
int age;
string number;
cout << "---------------------------------------------" << endl;
cout << "---------联系人姓名:";
getline(cin, name);
cout << "---------联系人年龄: ";
cin >> age;
cin.ignore(256, '\n');
p->set_name(name);
p->set_age(age);
for (int i = 1;; i++)
{
cout << "[第" << i << "个]电话号码(输出空结束): ";
getline(cin, number);
if (number.size() == 0)
break;
contacts2::Phone *ptr = p->add_phone_array();
ptr->set_number(number);
}
cout << "---------------------------------------------" << endl;
return true;
}
int main()
{
GOOGLE_PROTOBUF_VERIFY_VERSION;
// 1.从文件中读取出通讯录信息
contacts2::Contact contact;
fstream input("contacts.bin", ios::in | ios::binary);
if (!input)
{
cout << "contacts.bin not exist,create a new file!" << endl;
}
else if (!contact.ParseFromIstream(&input))//支持从直接从流中序列化和反序列化
{
cerr << "反序列化失败!" << endl;
input.close();
return -1;
}
// 2.添加联系人
if (!AddPerson(contact.add_people()))
{
input.close();
cout << "添加联系人失败!" << endl;
return -1;
}
cout << "添加联系人成功!" << endl;
fstream output("contacts.bin", ios::out | ios::binary | ios::trunc);
// 3.序列化
if (!contact.SerializeToOstream(&output))
{
cout << "序列化失败!" << endl;
input.close();
output.close();
return -1;
}
cout << "序列化成功!" << endl;
input.close();
output.close();
google::protobuf::ShutdownProtobufLibrary(); // 清除全局对象资源
return 0;
}
read.cc
#include <iostream>
#include <fstream>
#include "contacts.pb.h"
using namespace std;
int main()
{
contacts2::Contact contact;
fstream input("contacts.bin", ios::in | ios::binary);
if (!contact.ParseFromIstream(&input))
{
cout << "反序列化失败" << endl;
return -1;
}
for (int i = 0; i < contact.people_size(); i++)
{
cout << "-----------"
<< "联系人" << i + 1 << "-------------" << endl;
const ::contacts2::PeopleInfo &person = contact.people(i);
cout << "姓名:" << person.name() << endl;
cout << "年龄:" << person.age() << endl;
for (int j = 0; j < person.phone_array_size(); j++)
{
const ::contacts2::Phone &phone = person.phone_array(j);
cout << "第" << j + 1 << "个号码:" << phone.number() << endl;
}
}
return 0;
}
Makefile
.PHONY:all
all:test read
test:main.cc contacts.pb.cc
g++ -o $@ $^ -std=c++11 -lprotobuf
read:read.cc contacts.pb.cc
g++ -o $@ $^ -std=c++11 -lprotobuf
.PHONY:clean
clean:
rm -f test read
运行结果
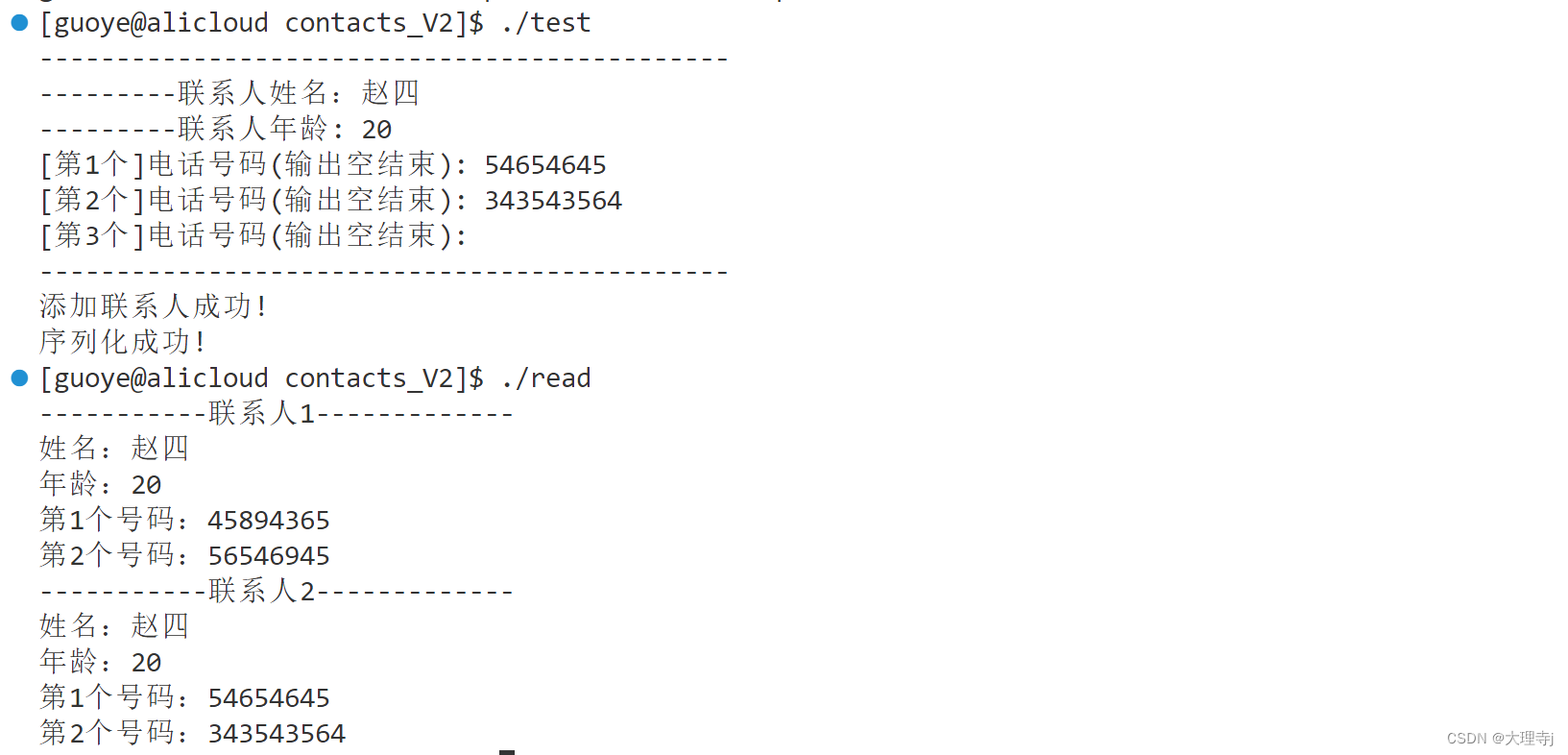
hexdump

hexdump:是Linux下的⼀个⼆进制⽂件查看⼯具,它可以将⼆进制⽂件转换为ASCII、⼋进制、⼗进制、⼗六进制格式进⾏查看。
-C: 表⽰每个字节显⽰为16进制和相应的ASCII字符
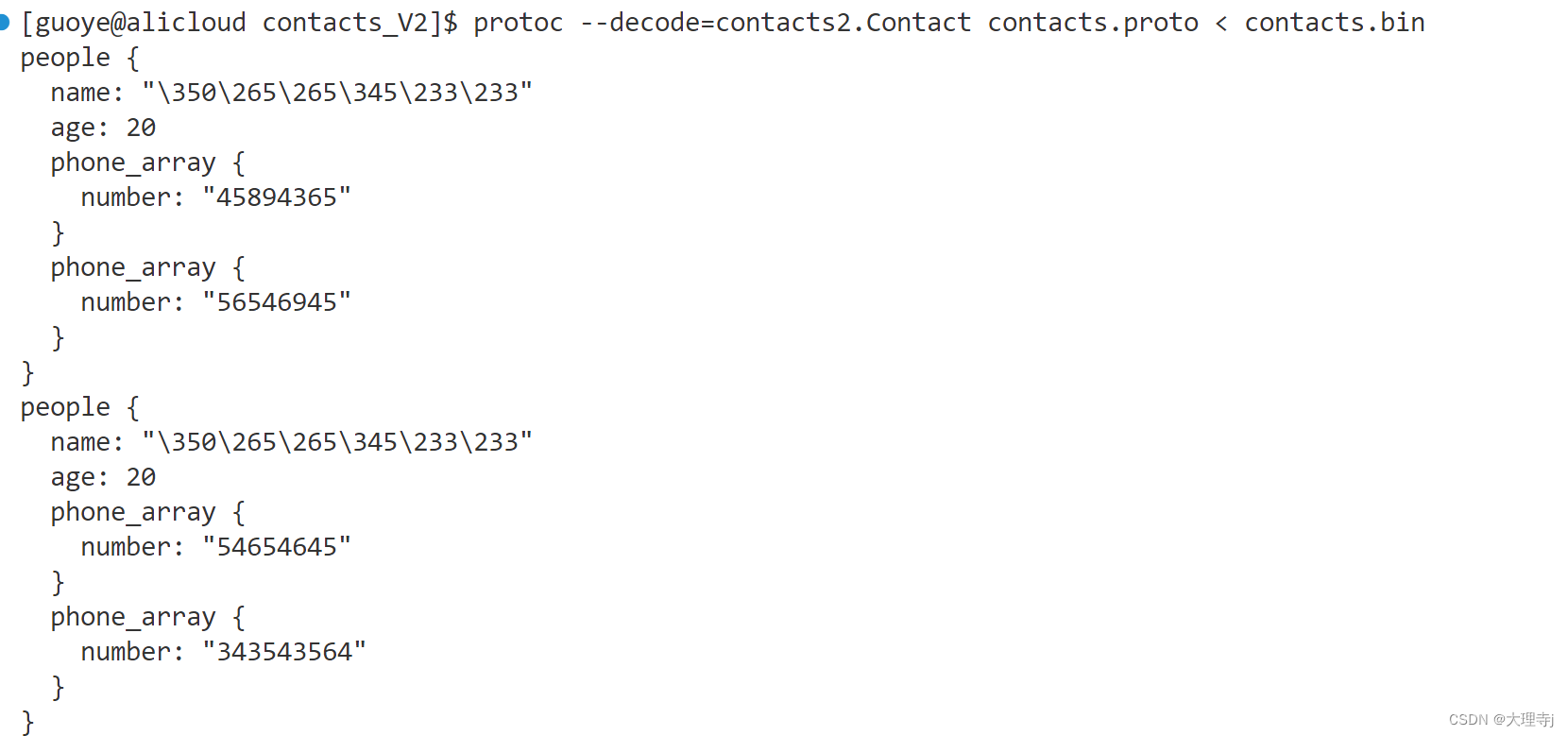
protoc --decode
🚀protoc --decode ,表⽰从标准输⼊中读取给定类型的⼆进制消息,并将其以⽂本格式写⼊标准输出。 消息类型必须在 .proto ⽂件或导⼊的⽂件中定义。
protoc --decode=contacts2.Contact contacts.proto < contacts.bin
//在这⾥是将utf-8汉字转为⼋进制格式输出了
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











