









在经过了前两节的内容学习之后,我们对于RLHF(从人类反馈中进行强化学习)有了比较深入的认知,并且初步了解了RLHF中偏好数据集的引入,奖励模型的设置以及baseLLM的训练过程。在本节的学习中,我们将深入LLM的tune步骤,了解LLM的微调工作。
ML流水线
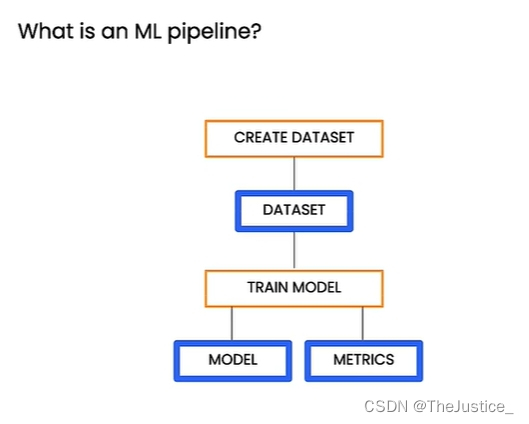
如上图所示,在我们想要批量实现机器学习的任务时,我们可以开发一条机器学习流水线,将其中的每个步骤封装成通用的类,在需要时进行调用即可。比如该图中就包括创建数据集,训练模型等步骤。该工作流图,橙色框表示工作中用到的一些组件,包含通用的代码框架,而蓝色框则表示组件生成的工件,比如生成的模型和指标可以帮助我们评估模型。
RLHF流水线
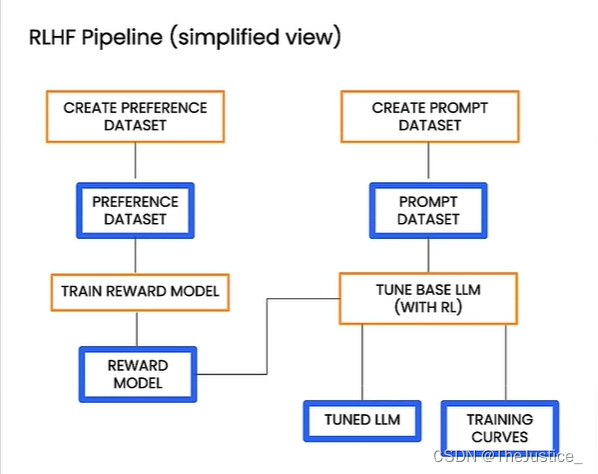
该图为RLHF工作流的基本框架,包含创建偏好数据集、训练奖励模型、创建prompt数据集以及用RL微调大模型等组件。在各组件共同配合下,能完成一个复杂的RLHF任务。
简单来说,就是创建两个数据集,训练两个模型。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









