







一、简介
- Milvus简介
Milvus 于 2019 年开源,主要用于存储、索引和管理通过深度神经网络和机器学习模型产生的海量向量数据。
Milvus 向量数据库专为向量查询与检索设计,能够为万亿级向量数据建立索引。与传统关系型数据库不同,Milvus 主要用于自下而上地处理非结构化数据向量。非结构化数据没有统一的预定义模型,因此可以转化为向量。
随着互联网不断发展,电子邮件、论文、物联网传感数据、社交媒体照片、蛋白质分子结构等非结构化数据已经变得越来越普遍。如果想要使用计算机来处理这些数据,需要使用 embedding 技术将这些数据转化为向量。随后,Milvus 会存储这些向量,并为其建立索引。Milvus 能够根据两个向量之间的距离来分析他们的相关性。如果两个向量十分相似,这说明向量所代表的源数据也十分相似。
2. 特征向量是什么?
向量又称为 embedding vector,是指由embedding技术从离散变量(如xxx等各种非结构化数据)转变而来的连续向量。在数学表示上,向量是一个由浮点数或者二值型数据组成的 n 维数组。通过现代的向量转化技术,比如各种人工智能(AI)或者机器学习(ML)模型,可以将非结构化数据抽象为 n 维特征向量空间的向量。这样就可以采用最近邻算法(ANN)计算非结构化数据之间的相似度。
3.术语表
Collection
包含一组 entity,可以等价于关系型数据库系统中的表。
Entity
包含一组 field。field 与实际对象相对应。field 可以是代表对象属性的结构化数据,也可以是代表对象特征的向量。primary key 是用于指代一个 entity 的唯一值。
你可以自定义 primary key,否则 Milvus 将会自动生成 primary key。请注意,目前 Milvus 不支持 primary key 去重,因此有可能在一个 collection 内出现 primary key 相同的 entity。
Field
Entity 的组成部分。Field 可以是结构化数据,例如数字和字符串,也可以是向量。
Milvus 2.0 现已支持标量字段过滤。
Segment
Milvus 在数据插入时通过合并数据自动创建的数据文件。一个 collection 可以包含多个 segment。一个 segment 可以包含多个 entity。在搜索中,Milvus 会搜索每个 segment,并返回合并后的结果。
Sharding
Shard 是指将数据写入操作分散到不同节点上,使 Milvus 能充分利用集群的并行计算能力进行写入。默认情况下单个 collection 包含 2 个分片(shard)。目前 Milvus 采用基于主键哈希的分片方式,未来将支持随机分片、自定义分片等更加灵活的分片方式。
Partition 的意义在于通过划定分区减少数据读取,而shard 的意义在于多台机器上并行写入操作。
Partition
把 collection 中的数据根据一定规则在物理存储上分成多个部分。这种对 collection 数据的划分就叫分区(partitioning)。每个 partition 可包含多个segment。
索引
索引基于原始数据构建,可以提高对 collection 数据搜索的速度。Milvus 支持多种索引类型。
向量
一种类型的 field,代表对象的特征。非结构化数据可以通过各种 AI 模型和 embedding 技术转化为向量。
目前,一个实体最多只能包含一个向量。
4.为什么选择使用 Milvus?
高性能:性能高超,可对海量数据集进行向量相似度检索。
高可用、高可靠:Milvus 支持在云上扩展,其容灾能力能够保证服务高可用。
混合查询:Milvus 支持在向量相似度检索过程中进行标量字段过滤,实现混合查询。
开发者友好:支持多语言、多工具的 Milvus 生态系统。
二、下载&安装
https://milvus.io/docs/v2.1.x/install_standalone-docker.md
三、SpringBoot项目整合milvus
1.pom引入
<dependency>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
<version>2.1.0</version>
</dependency>
2.MilvusServiceClient
需要跟milvus交互都需要调用MilvusServiceClient,我这里的做法是把它定义成一个Bean,需要用到的地方依赖注入
配置文件需新增 milvus.host milvus.port
@Configuration
public class MilvusConfig {
@Value("${milvus.host}")
private String host; //milvus所在服务器地址
@Value("${milvus.port}")
private Integer port; //milvus端口
@Bean
public MilvusServiceClient milvusServiceClient() {
ConnectParam connectParam = ConnectParam.newBuilder()
.withHost(host)
.withPort(port)
.build();
return new MilvusServiceClient(connectParam);
}
}
3.常用api
https://milvus.io/api-reference/java/v2.1.0/About.md
4.依赖冲突问题
<dependency>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
<version>2.1.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
</exclusion>
</exclusions>
</dependency>
四、docker离线部署milvus集群
本地有网环境下,下载好镜像
docker pull milvus
然后打包镜像
docker save -o milvus.tar milvusdb/milvus:v2.2.0
tar包上传到服务器
踩坑,用rz上传大文件有点问题,可以用这个脚本(其他文章中有)上传
放到目标文件夹中
Python myhttp.py 8001
导入镜像
docker load -i milvus.tar
自行安装docker-compose
官网拉取配置文件,重命名为docker-compose.yml
启动milvus
docker-compose up -d

启动network报错
解决办法:
docker network create milvus --subnet 172.24.24.0/24
启动成功如下
五、性能测试一
索引
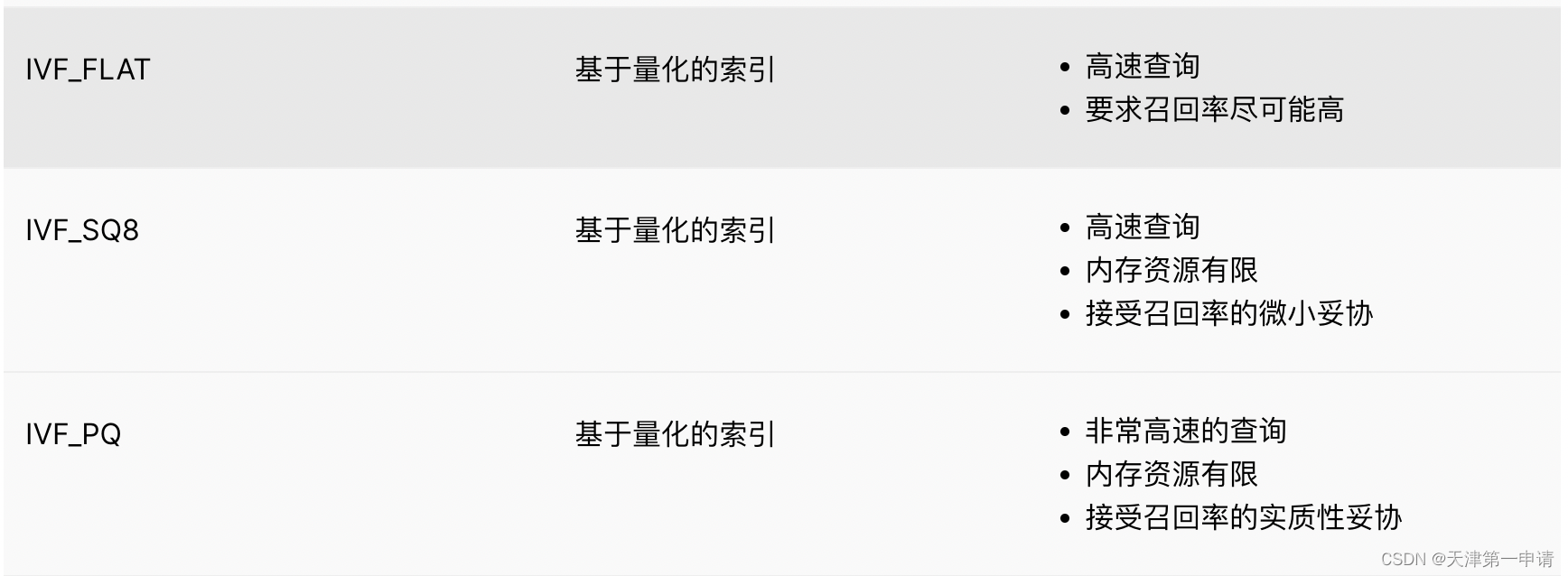
IVF_SQ8
IVF_FLAT 不执行任何压缩,因此它生成的索引文件与原始的原始非索引矢量数据的大小大致相同。例如,如果原始 1B SIFT 数据集为 476 GB,则其 IVF_FLAT 索引文件会稍大(~470 GB)。将所有索引文件加载到内存中将消耗 470 GB 的存储空间。
当磁盘、CPU 或 GPU 内存资源有限时,IVF_SQ8 是比 IVF_FLAT 更好的选择。该索引类型可以通过执行标量量化将每个 FLOAT(4 个字节)转换为 UINT8(1 个字节)。这减少了 70-75% 的磁盘、CPU 和 GPU 内存消耗。对于 1B SIFT 数据集,IVF_SQ8 索引文件仅需要 140 GB 的存储空间。
- 索引构建参数
- 搜索参数
IVF_PQ
PQ(Product Quantization)将原始高维向量空间均匀分解为m低维向量空间的笛卡尔积,然后对分解后的低维向量空间进行量化。乘积量化代替计算目标向量到所有单元中心的距离,使得计算目标向量到每个低维空间的聚类中心的距离,大大降低了算法的时间复杂度和空间复杂度.
IVF_PQ 在量化向量的乘积之前执行 IVF 索引聚类。它的索引文件比 IVF_SQ8 还要小,但也会导致搜索向量时的精度损失。
环境
采用docker离线搭建的单机集群
查看cpu核数

硬盘和内存使用情况
亿级数据,采用ivfpq索引, 需要固态硬盘102g 内存也大概100多g

可视化工具Attu
http://10.153.108.18:8000/#/
测试结果
5000万 数据 IVF_SQ8 nlist 16384 nprobe 512
1并发

5并发

10并发

以下全是30并发
nlist 建议 4 × sqrt(n)
1000万数据 分片2 IVF_SQ8 nprobe 512, nlist 40000
搜索改成异步搜索

nprobe 16 nlist 40000

索引改为IVF_PQ

4000万数据 IVF_PQ nlist 40000 nprobe 16

8000万数据集 IVF_PQ nlist 40000 nprobe 16

1亿 IVF_PQ nlist 40000 nprobe 16

1亿 nlist 40000 nprobe 512

1亿 nlist 40000 nprobe 1024 30并发

cpu使用情况
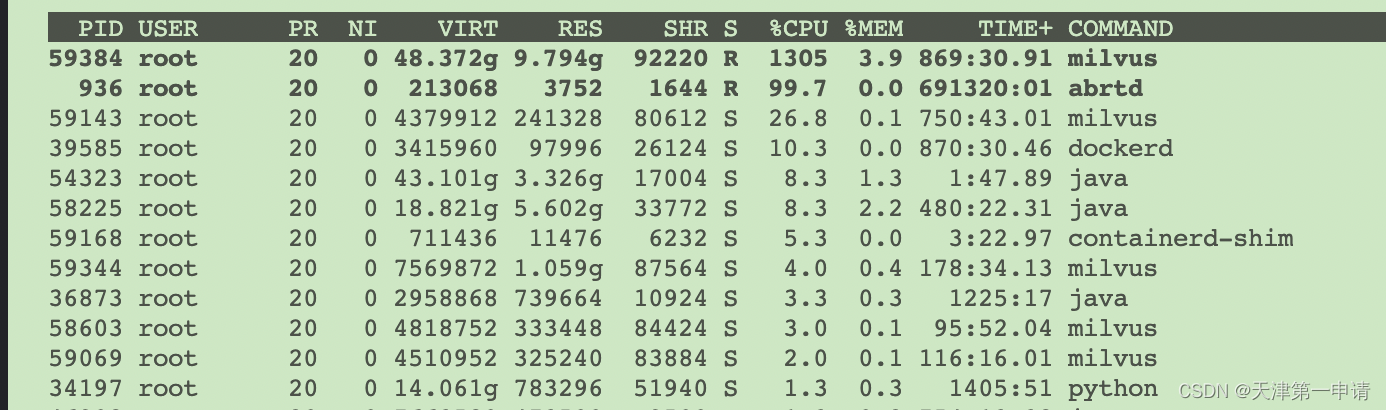
1亿 nlist 40000 nprobe 1024 10并发

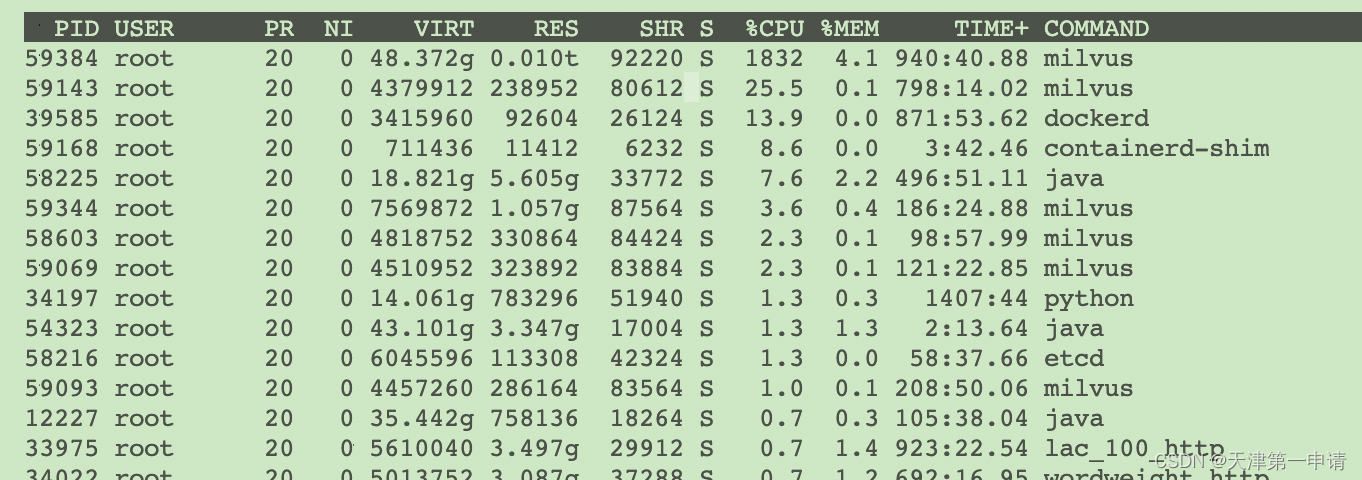
















 2755
2755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









