







用:
if not (color_image == data_initial).all():
color_image和data_initial是两张大小相同的图片
color_image==data_initial输出逐个像素比较的True和False
如:
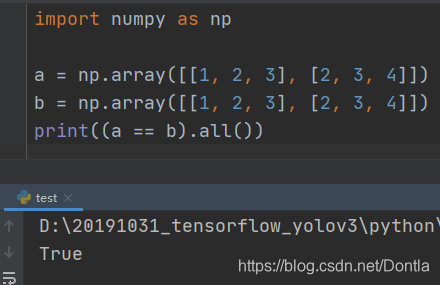
import numpy as np
a = np.array([[1, 2, 3], [2, 3, 4]])
b = np.array([[1, 2, 3], [2, 2, 4]])
print(a == b)
输出结果:
[[ True True True]
[ True False True]]
.all()方法就是如果数组里全是True,输出就为True,如果不全是True,输出就是False,这样就能判断两张图片是否相同了
文章目录
20230816
如何比较两张图片的差异
对比两张图片,判断它们是否相同,是一个常见的问题。在许多领域中都有实际应用,例如版权检测、盗版图像追踪、面部识别等等。本文将探讨几种主要的技术和方法,这些方法可以用来比较图像并确定它们之间的差异。
目录
- 基于像素的比较方法
- 基于特征的比较方法
- 使用深度学较方法
- 技术比较与投票
1. 基于像素的比较方法
基于像素的比较方法是最直接也是最简单的一种方式,它主要关注图像中每个像素的值。
1.1 简单的差分法
简单的差分法通过计算两个图像相同位置上的像素值之差来找出不同。如果所有像素的差值都为零,那么这两张图就完全相同。
import numpy as np
from PIL import Image
def compare_images(img1, img2):
image1 = Image.open(img1)
image2 = Image.open(img2)
array1 = np.array(image1)
array2 = np.array(image2)
difference = np.abs(array1 - array2)
return np.sum(difference)
print(compare_images('image1.png', 'image2.png'))
1.2 Mean Squared Error (MSE)
均方误差(MSE)是另一种常见的评价指标,它可以衡量两幅图像的“相似度”。它的计算公式如下:
MSE = Σ|I1 - I2|^2 / (height * width)
其中,I1和I2分别代表两个图像,height和width则代表图像的高和宽。
def mse(imageA, imageB):
err = np.sum((imageA.astype("float") - imageB.astype("float")) ** 2)
err /= float(imageA.shape[0] * imageA.shape[1])
return err
print(mse(array1, array2))
2. 基于特征的比较方法
2.1 直方图比较
直方图是表示图像中色彩分布的一种方式。通过比较两个图像的直方图,我们可以得到它们的相似度。
import cv2
def compare_histograms(image1, image2):
hist1 = cv2.calcHist([image1], [0], None, [256], [0,256])
hist2 = cv2.calcHist([image2], [0], None, [256], [0,256])
return cv2.compareHist(hist1, hist2, cv2.HISTCMP_CORREL)
print(compare_histograms(array1, array2))
2.2 特征点匹配
特征点匹配是图像处理中的一个重要环节,常见的特征点检测算法有SIFT、SURF、ORB等。
def feature_matching(img1, img2):
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1,des2,k=2)
good = []
for m,n in matches:
if m.distance < 0.75*n.distance:
good.append([m])
return len(good)
print(feature_matching(image1, image2))
3. 使用深度学习的比较方法
深度学习提供了更复杂但效果更好的方法来比较图像。卷积神经网络(CNN)可以用来学习图像的深层特征,并将这些特征用于比较。
3.1 利用预训练模型
使用预训练的模型(如VGG16,ResNet等)来提取图像特征。
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input
model = VGG16(weights='imagenet', include_top=False)
def extract_features(img_path, model):
img = image.load_img(img_path, target_size=(224, 224))
img_data = image.img_to_array(img)
img_data = np.expand_dims(img_data, axis=0)
img_data = preprocess_input(img_data)
features = model.predict(img_data)
return features
3.2 利用Siamese网络
Siamese网络是一种特殊的神经网络,它接收一对输入,并输出这对输入的相似度。
from keras.models import Model
from keras.layers import Input, Conv2D, Lambda, merge, Dense, Flatten, MaxPooling2D
from keras.optimizers import Adam
input_shape = (105, 105, 1)
left_input = Input(input_shape)
right_input = Input(input_shape)
# build convnet to use in each siamese 'leg'
convnet = Sequential()
convnet.add(Conv2D(64, (10,10), activation='relu', input_shape=input_shape,
kernel_initializer=W_init, kernel_regularizer=l2(2e-4)))
convnet.add(MaxPooling2D())
convnet.add(Conv2D(128, (7,7), activation='relu',
kernel_regularizer=l2(2e-4), kernel_initializer=W_init, bias_initializer=b_init))
convnet.add(MaxPooling2D())
convnet.add(Conv2D(128, (4,4), activation='relu', kernel_initializer=W_init, bias_initializer=b_init, kernel_regularizer=l2(2e-4)))
convnet.add(MaxPooling2D())
convnet.add(Conv2D(256, (4,4), activation='relu', kernel_initializer=W_init, bias_initializer=b_init, kernel_regularizer=l2(2e-4)))
convnet.add(Flatten())
convnet.add(Dense(4096, activation="sigmoid",kernel_regularizer=l2(1e-3), kernel_initializer=W_init,bias_initializer=b_init))
# encode each of the two inputs into a vector with the convnet
encoded_l = convnet(left_input)
encoded_r = convnet(right_input)
# merge two encoded inputs with the L1 distance between them, and connect to prediction output layer
L1_distance = lambda x: K.abs(x[0]-x[1])
both = merge([encoded_l, encoded_r], mode = L1_distance, output_shape=lambda x: x[0])
prediction = Dense(1,activation='sigmoid',bias_initializer=b_init)(both)
siamese_net = Model(input=[left_input,right_input],output=prediction)
optimizer = Adam(0.00006)
siamese_net.compile(loss="binary_crossentropy",optimizer=optimizer)
4. 技术比较与投票
在上述的技术中,有些方法对某些类型的图像比较有效,而对其他类型的图像则可能不尽如人意。选择哪种方法取决于具体的应用场景和需求。
基于像素的方法简单易实现,但对图像的大小、旋转、亮度等因素非常敏感。
基于特征的方法能够克服一些基于像素方法的缺点,能够处理不同大小和角度的图像。但是它们通常需要更复杂的计算和更长的时间。
深度学习方法可以提取图像的深层特征,能够处理更复杂的情况,但是需要大量的数据进行训练,且计算成本较高。
ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ
ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ
ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ
ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ ᅟᅠ


















 214
214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











