






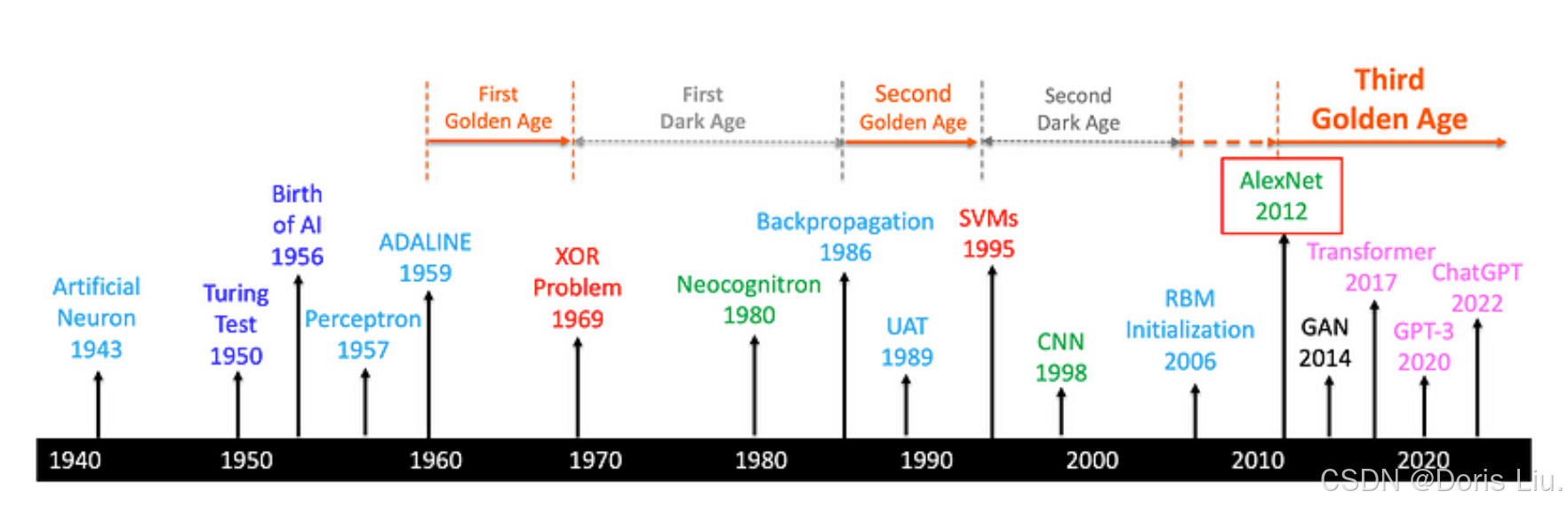
过去几十年来,人工智能(AI)和深度学习取得了显著进步,改变了计算机视觉、自然语言处理和机器人等领域。本文概述了人工智能历史上使用深度学习的重要里程碑,从早期的神经网络模型到现代的大型语言模型和多模态人工智能系统。
1.人工智能的诞生(1956)
人工智能(AI)的概念已经存在了几个世纪,但我们今天所知的现代人工智能领域是在20世纪中期开始形成的。人工智能"(Artificial Intelligence)一词是计算机科学家和认知科学家约翰-麦卡锡(John McCarthy)于1956年在Dartmouth人工智能夏季研究项目上首次提出的。
Dartmouth会议通常被认为是人工智能这一研究领域的发源地。这次会议汇集了一批计算机科学家、数学家和认知科学家,共同讨论创造能够模拟人类智能的机器的可能性。与会者包括马文-明斯基(Marvin Minsky)、纳撒尼尔-罗切斯特(Nathaniel Rochester)和克劳德-香农(Claude Shannon)等著名人士。

马文-明斯基、克劳德-香农、雷-所罗门诺夫和其他科学家参加达特茅斯人工智能夏季研究项目(照片:玛格丽特-明斯基)
1.1人工智能的演变:从基于规则的系统到深度学习
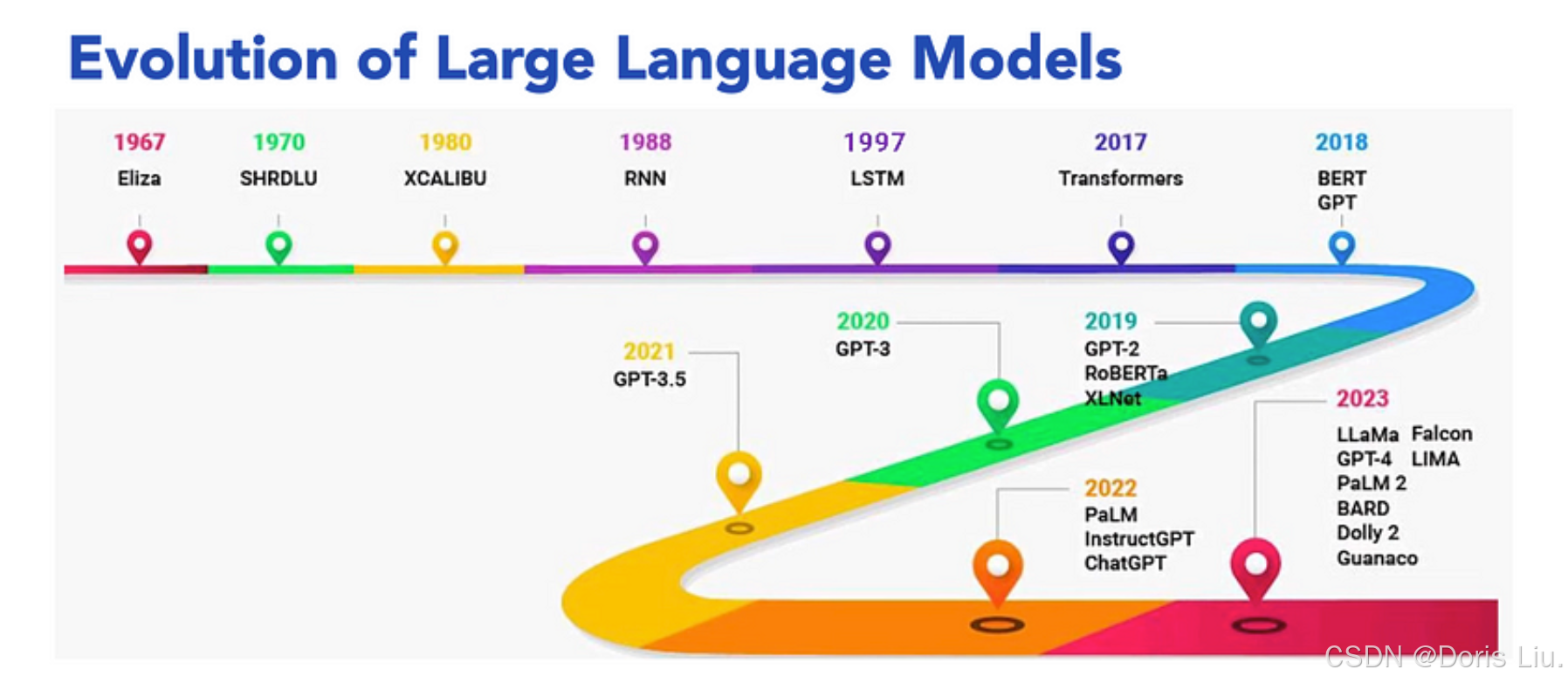
人工智能的发展始于20世纪50年代,当时人们开发了用于国际象棋和解决问题等任务的算法,第一个人工智能程序“逻辑理论家”于1956年诞生。20世纪60和70年代,出现了基于规则的专家系统,如MYCIN,它可以协助复杂的决策过程。20世纪80年代出现了机器学习,它使人工智能系统能够从数据中学习并随着时间的推移不断改进,为现代深度学习技术奠定了基础。
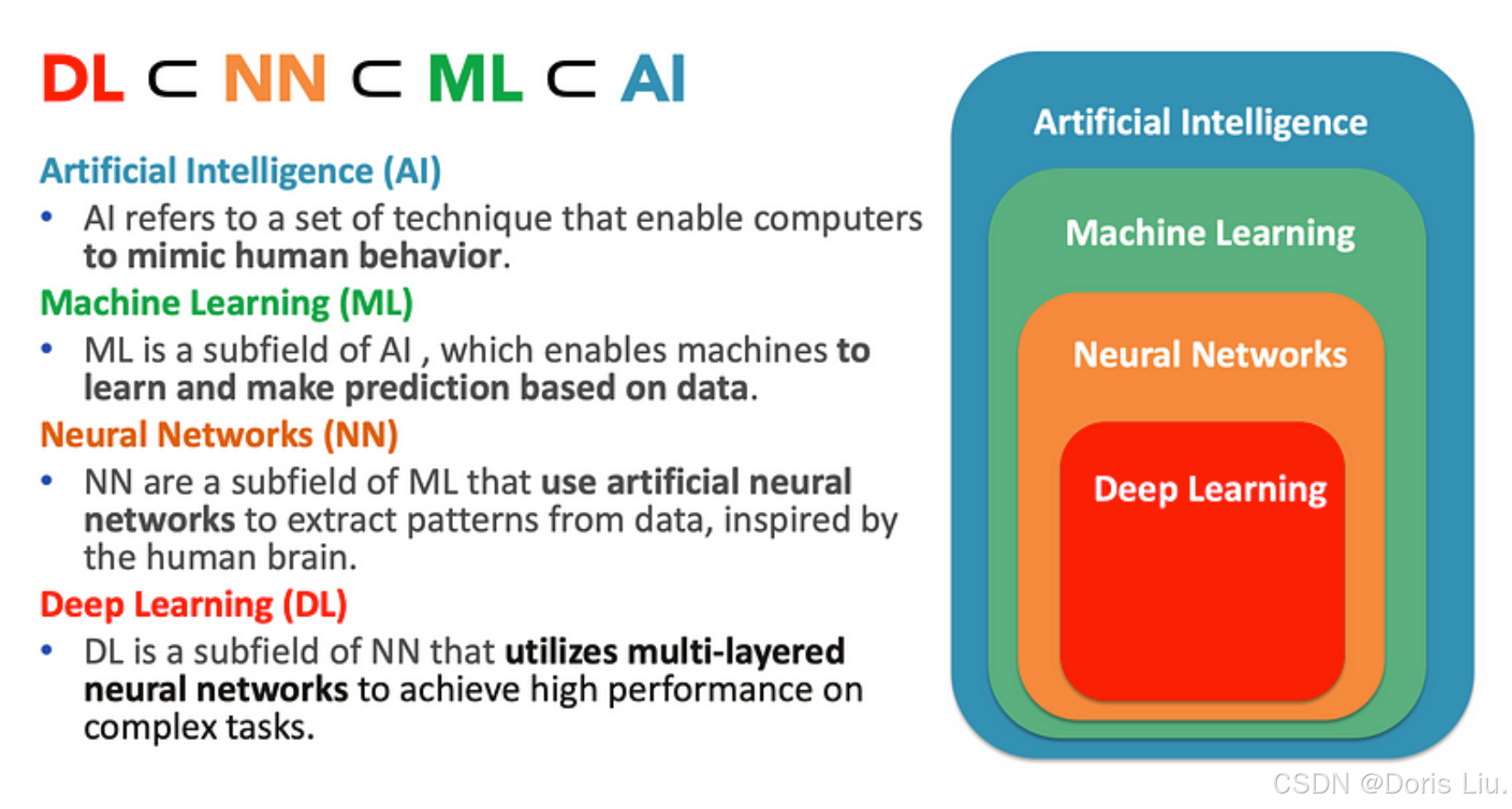
如今,大多数尖端的人工智能技术都是由深度学习技术驱动的,它已经改变了人工智能的格局。深度学习是机器学习的一个专门分支,它利用多层人工神经网络从原始输入数据中提取复杂特征。在本文中,我们将探讨人工智能的历史,重点介绍深度学习在其发展过程中的作用。
2.早期人工神经网络
2.1 Muclloch-Pitts神经元(1943)
神经网络的概念可追溯到1943年,当时沃伦-麦库洛克(Warren McCulloch)和沃尔特-皮茨(Walter Pitts)提出了第一个人工神经元模型。麦库洛克-皮茨(MP)神经元模型是对生物神经元的突破性简化。该模型通过聚合二进制输入,并使用阈值激活函数在聚合的基础上做出决策,从而产生二进制输出{0,1},为人工神经网络奠定了基础。
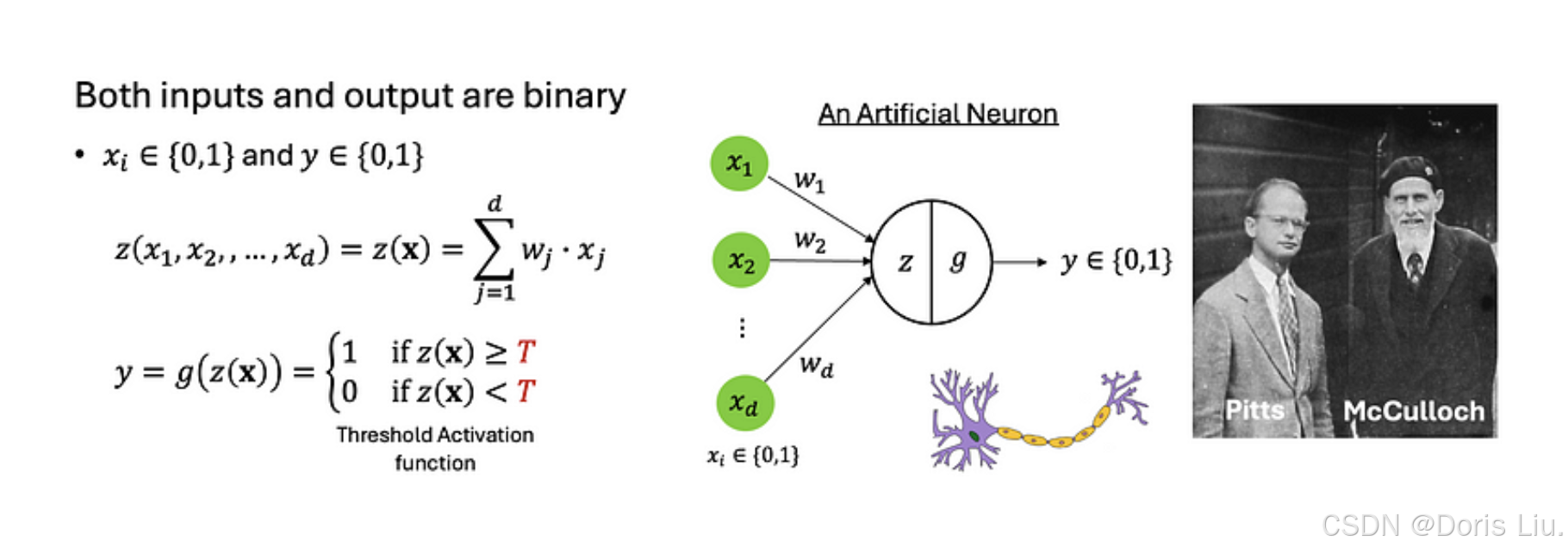
这个简化模型捕捉到了神经元行为的本质--接收多个输入,对它们进行整合,并根据整合信号是否超过阈值产生二进制输出。尽管简单,但MP神经元模型能够执行基本的逻辑运算,展示了神经计算的潜力。
2.2 Rosenblatt感知器模型(1957)
1957年,弗兰克-罗森布拉特(Frank Rosenblatt)推出了能够学习和识别模式的单层神经网络--感知器。与MP神经元相比,Perceptron模型是一种更通用的计算模型,旨在处理实值输入,并调整权重以尽量减少分类误差。
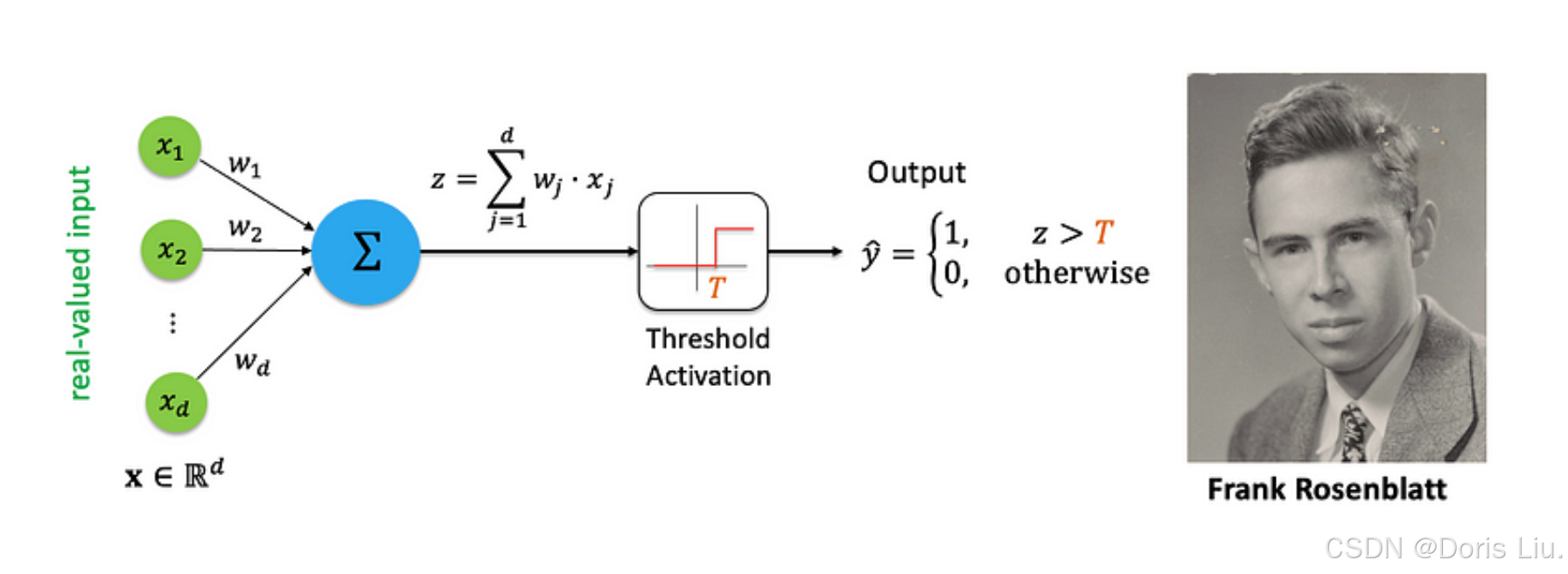
罗森布拉特还为感知器开发了一种监督学习算法,使网络能够直接从训练数据中学习。
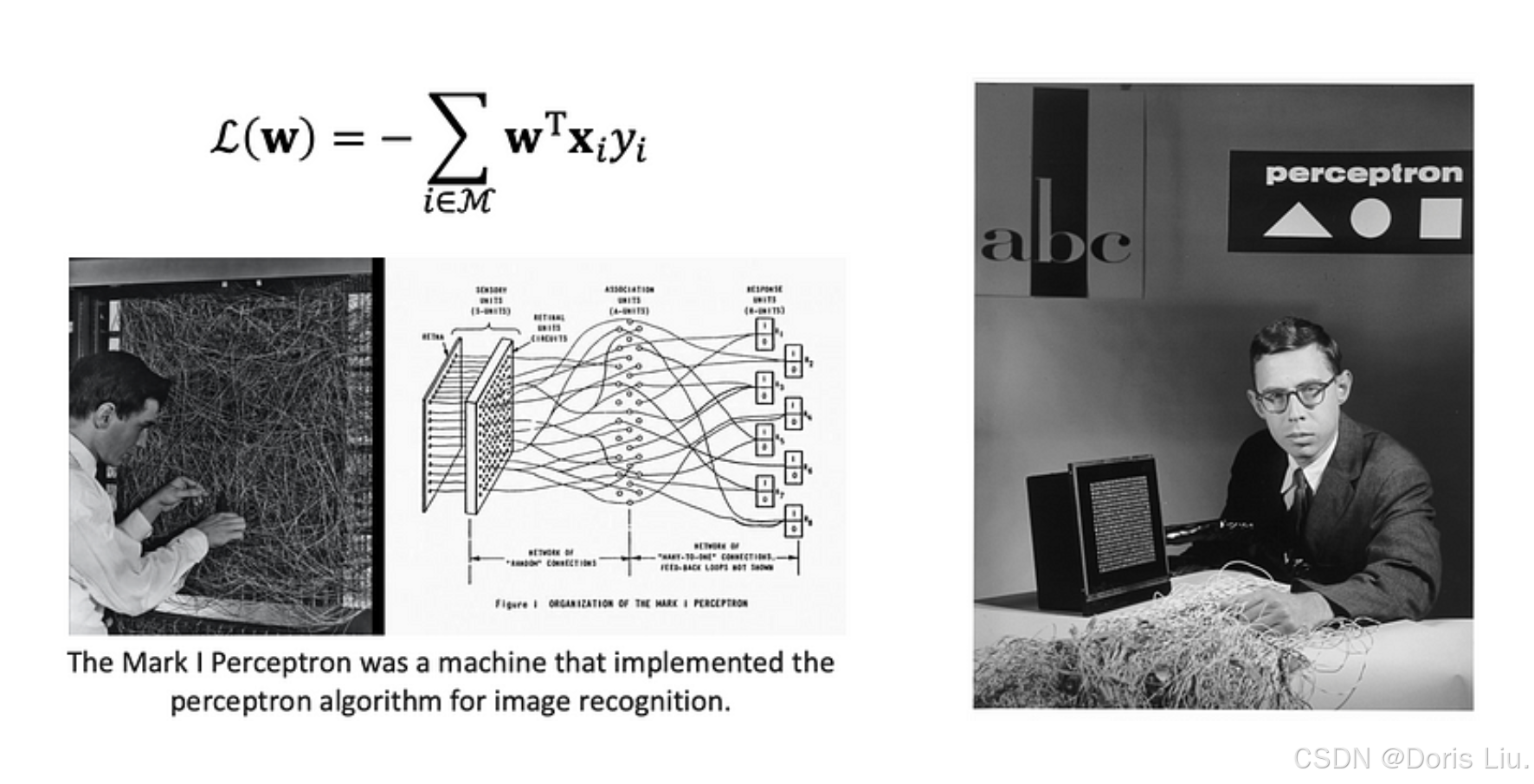
罗森布拉特雄心勃勃地宣称感知器具有识别个人和翻译不同语言的能力,这在当时引起了公众对人工智能的极大兴趣。Perceptron模型及其相关学习算法标志着神经网络发展的重要里程碑。然而,一个关键的局限性很快就显现出来:Perceptron的学习规则在遇到非线性可分离的训练数据时无法收敛。
2.3 ADALINE(1959)
1959年,维德罗和霍夫推出了ADALINE(自适应线性神经元又称德尔塔学习规则),这是对Perceptron学习规则的改进。ADALINE解决了二进制输出和噪声敏感性等限制,并能对非线性可分离数据进行学习和收敛,是神经网络发展的一大突破。
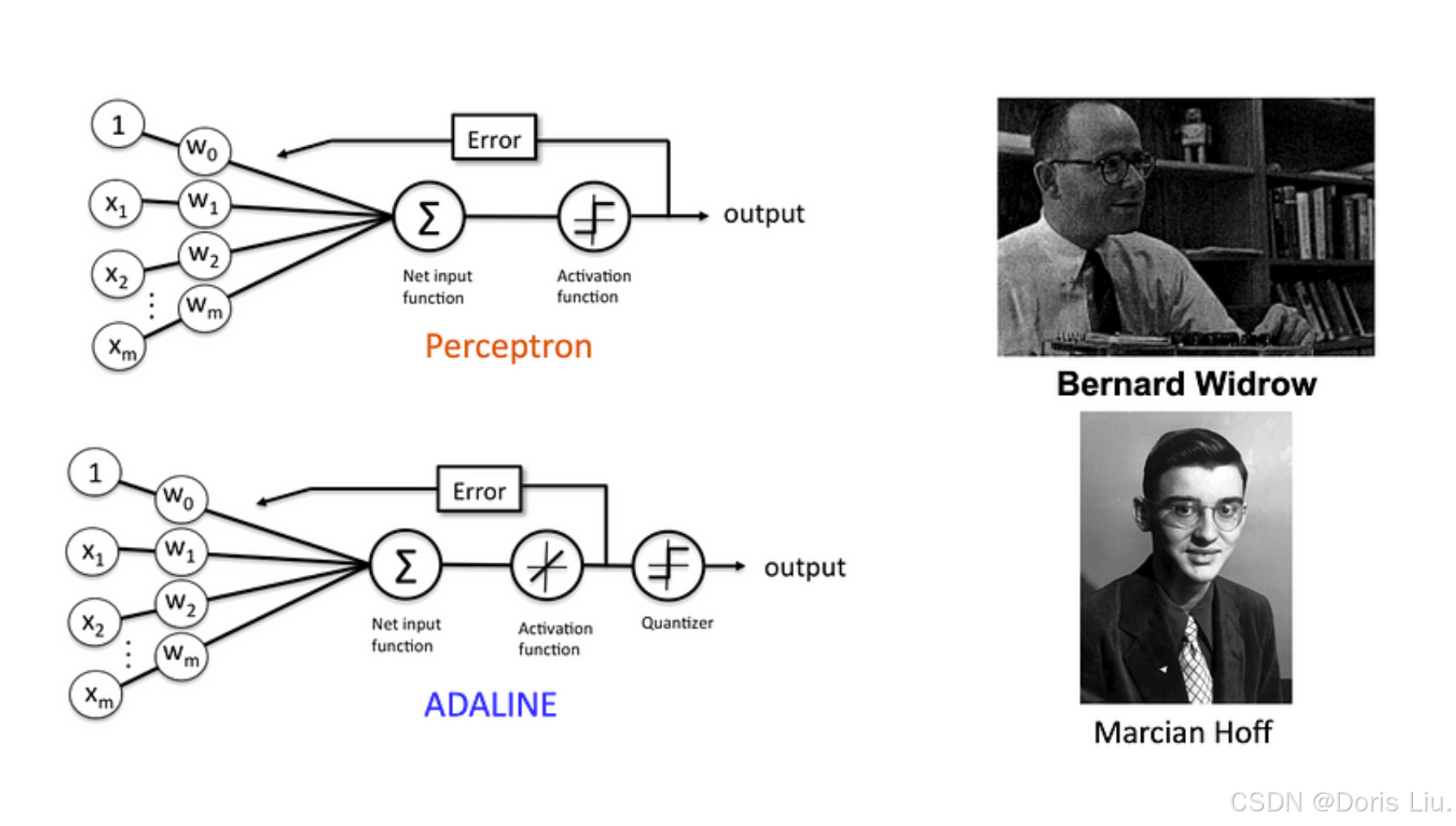
ADALINE的主要功能包括
- 线性激活函数:与Perceptron的阶跃函数不同,ADALINE使用线性激活函数,因此适用于回归任务和连续输出。
- 最小均方(LMS)算法:ADALINE采用LMS算法,该算法可将预测输出与实际输出之间的均方误差降至最低,从而提供更高效、更稳定的学习过程。
- 自适应权重:LMS算法可根据输出误差自适应地调整权重,从而使ADALINE即使在存在噪声的情况下也能有效地学习和收敛。
ADALINE的推出标志着神经网络第一个黄金时代的开始,它克服了Rosenblatt感知器学习的局限性。这一突破实现了高效学习、连续输出和对嘈杂数据的适应,引发了该领域的创新浪潮并取得了飞速发展。
然而,与Perceptron一样,ADALINE仍局限于线性可分离问题,无法解决更复杂的非线性任务。后来XOR问题凸显了这一局限性,促使人们开发出更先进的神经网络架构。
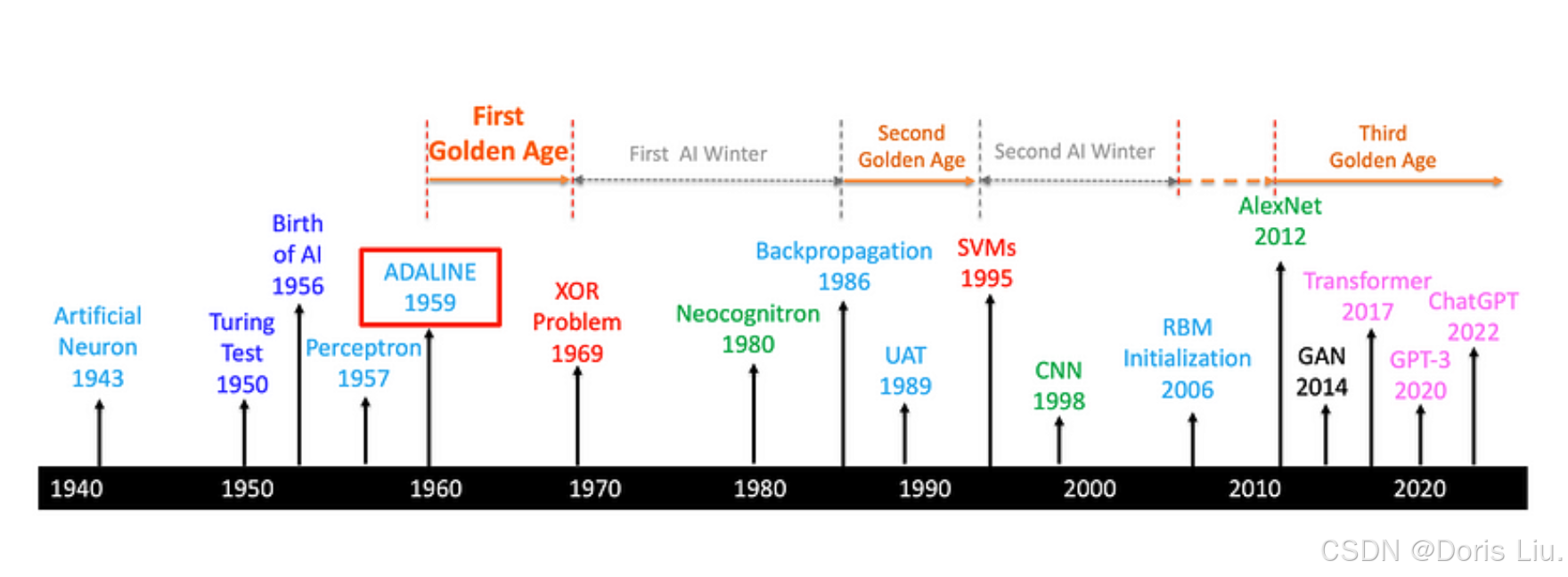
2.4 XOR问题(1969)
1969年,马文-明斯基(Marvin Minsky)和西摩-帕帕特(Seymour Papert)在他们的著作《Perceptrons》中强调了单层感知器的一个关键局限性。他们证明,由于感知器的线性决策边界,感知器无法解决简单的二元分类任务--异或问题(XOR)。XOR问题不是线性可分的,也就是说,没有一个线性边界可以正确地对所有输入模式进行分类。

这一发现凸显了对能够学习非线性决策边界的更复杂神经网络架构的需求。Perceptron局限性的暴露导致人们对神经网络失去信心,以及向符号人工智能方法的转变,标志着从20世纪70年代初到80年代中期的“第一个神经网络黑暗时代”的开始。
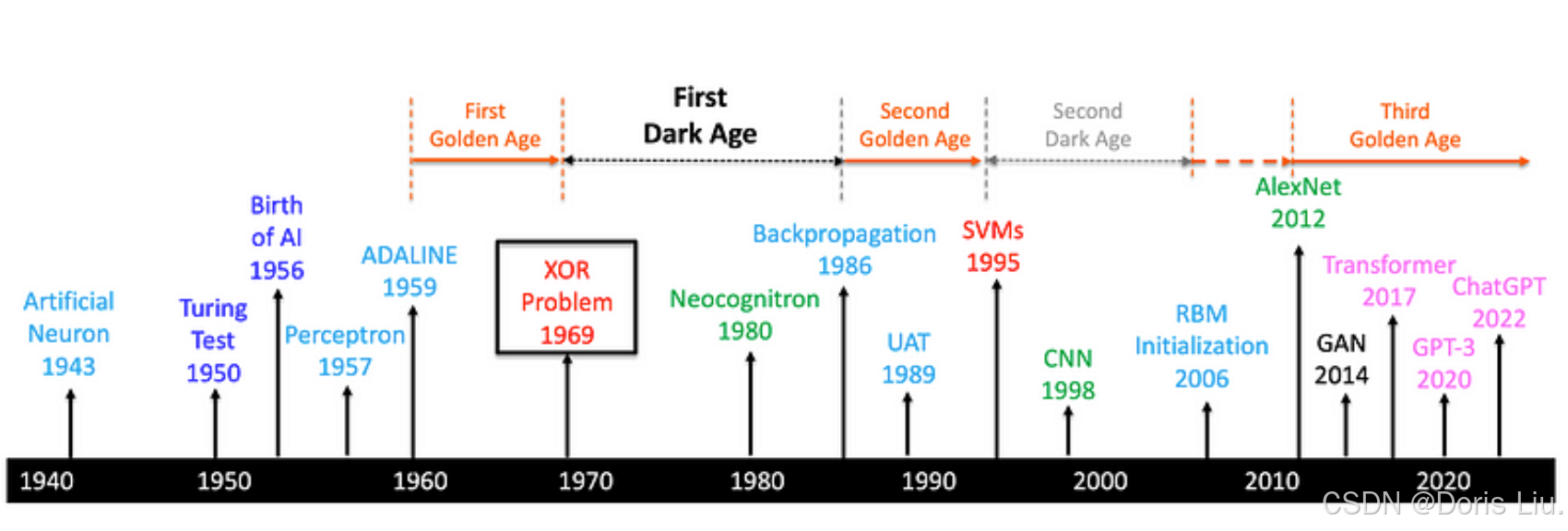
神经网络的第一个黑暗时代
然而,从解决XOR问题中获得的洞察力让研究人员认识到,需要能捕捉非线性关系的更复杂的模型。这一认识最终促成了多层感知器和其他先进神经网络模型的发展,为后来几十年神经网络和深度学习的复兴奠定了基础。
3.多层感知器(1960年代)
多层感知器(MLP)于20世纪60年代问世,是对单层感知器的改进。它由多层相互连接的神经元组成,能够解决单层模型的局限性。苏联科学家A.G.Ivakhnenko和V.Lapa在Perceptron的基础上,为MLP的发展做出了重大贡献。
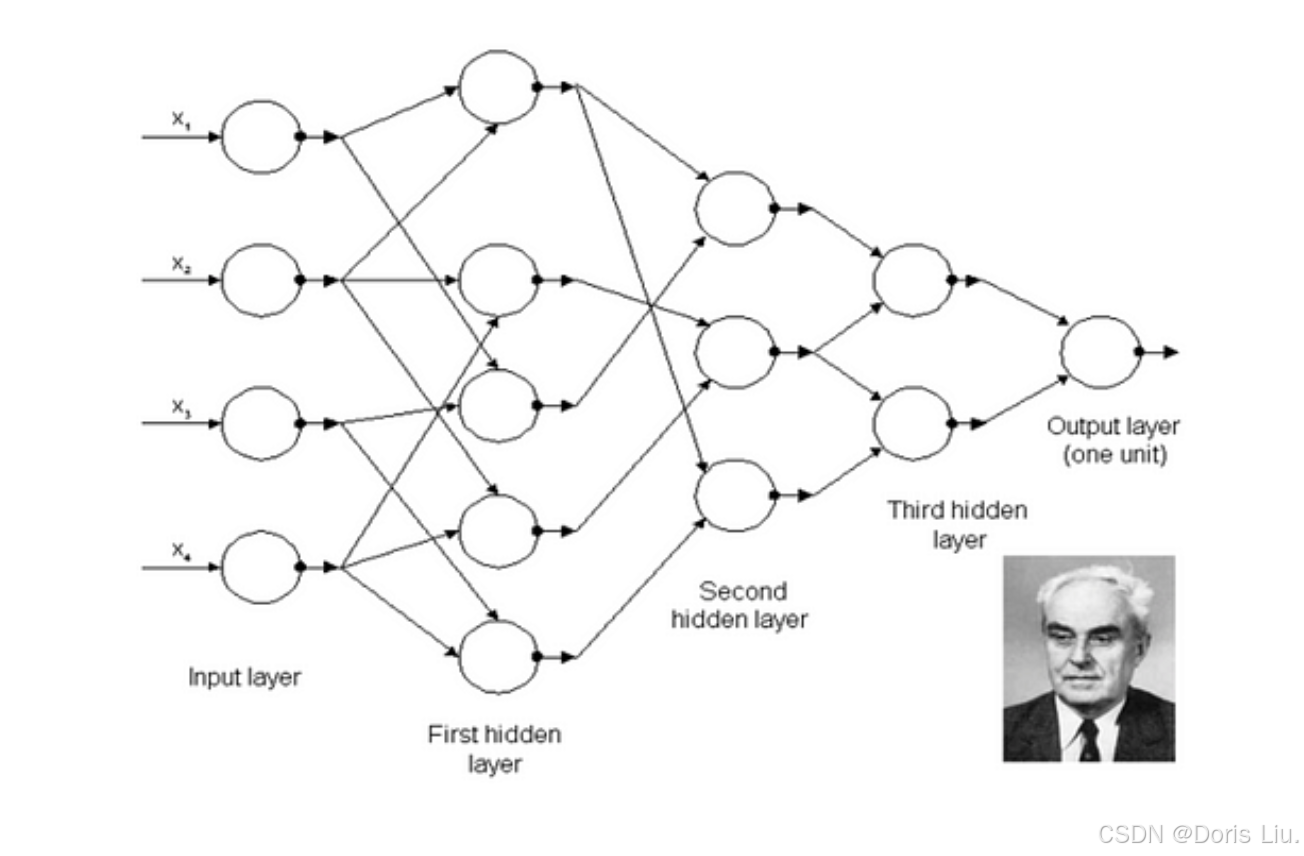
3.1 隐藏层
增加隐藏层后,MLP可以捕捉并表示数据中复杂的非线性关系。这些隐藏层大大增强了网络的学习能力,使其能够解决非线性分离的问题,如XOR问题。
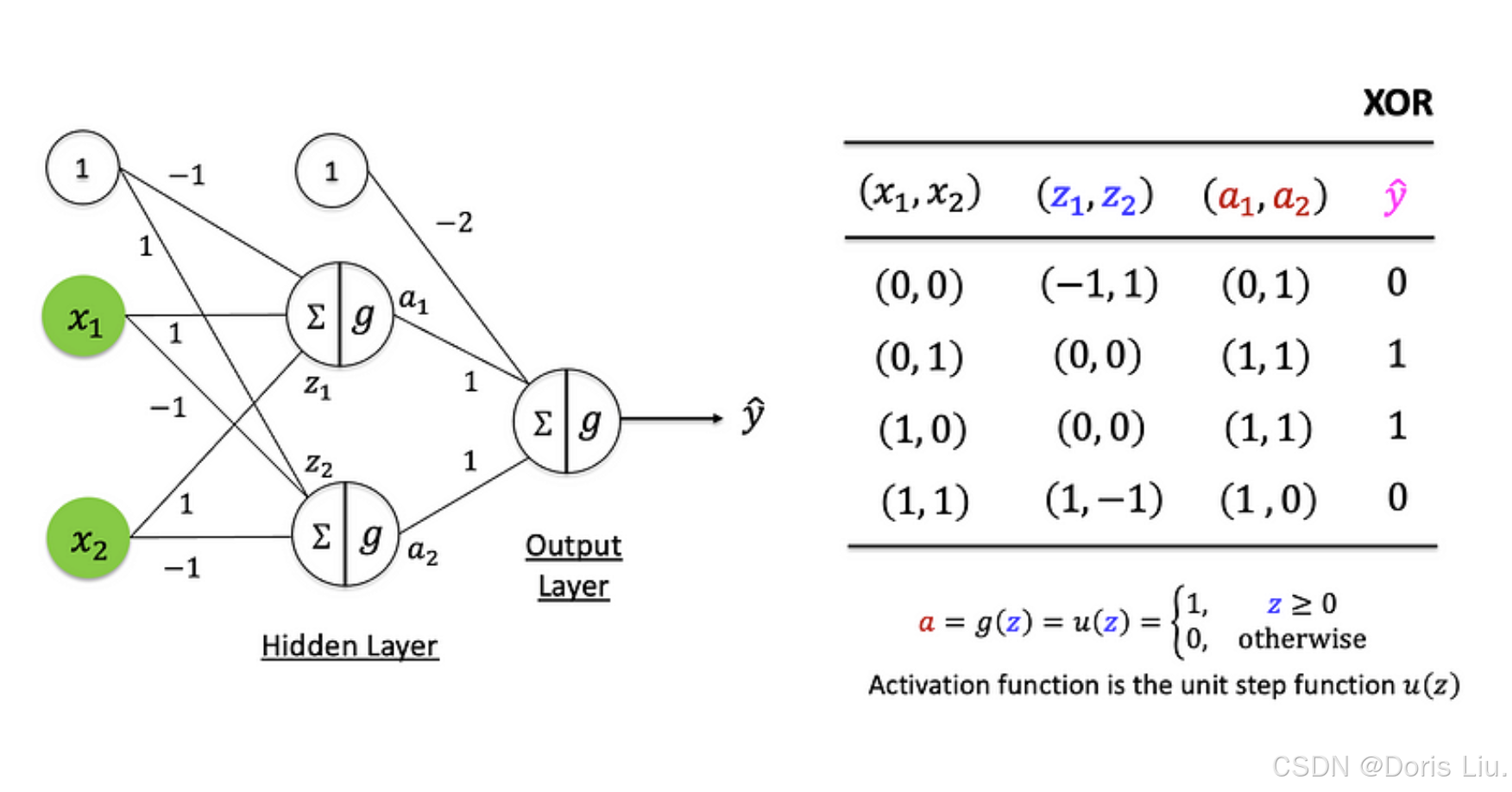
3.2 MLP的历史背景与挑战
MLP标志着神经网络研究的重大进展,展示了深度学习架构解决复杂问题的潜力。然而,在二十世纪六七十年代,MLP的发展受到了一些阻碍:
- 缺乏训练算法:早期的MLP模型缺乏能有效调整网络权重的高效训练算法。由于缺乏反向传播算法,因此很难对多层深度网络进行训练。
- 计算限制:当时的计算能力不足以处理训练深度神经网络所需的复杂计算。这一限制减缓了MLP的研发进度。
1986年,随着反向传播算法的重新发现和发布,神经网络的第一个黑暗时代结束了,从而开启了神经网络的第二个黄金时代。
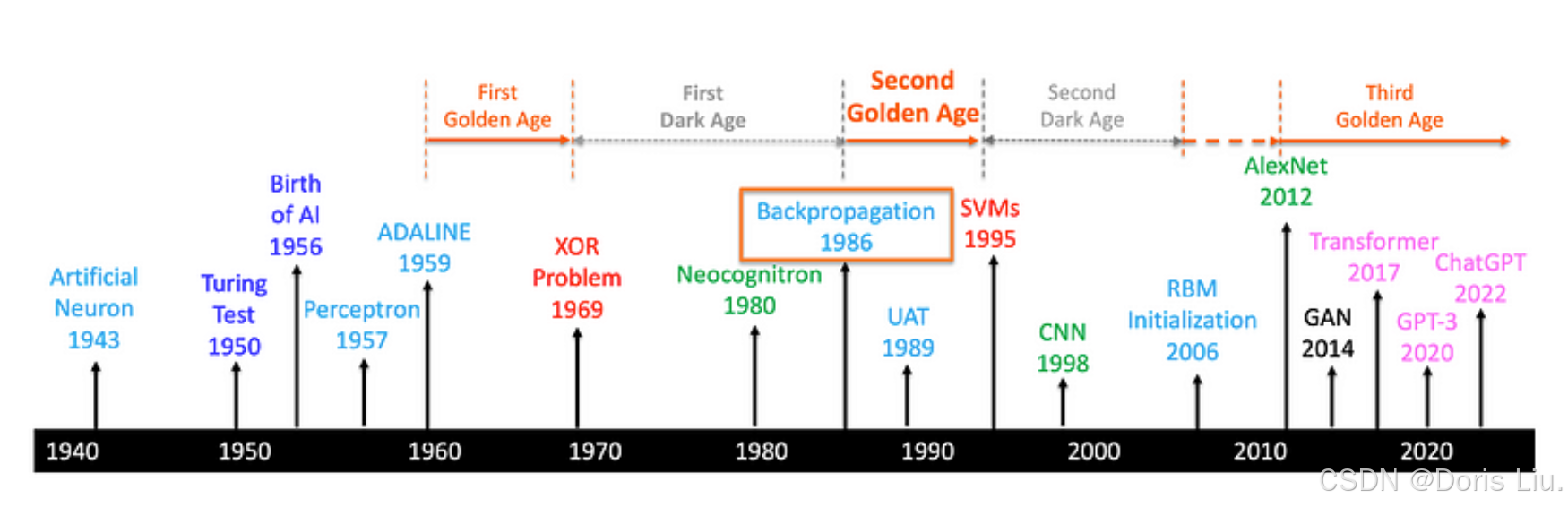
4.反向传播
1969年,XOR问题凸显了感知器(单层神经网络)的局限性。研究人员意识到,多层神经网络可以克服这些局限性,但他们缺乏训练这些复杂网络的实用算法。反向传播算法花了17年时间才被开发出来,使神经网络能够在理论上逼近任何函数。有趣的是,后来人们发现,这种算法其实在其发表之前就已经发明了。如今,反向传播算法已成为深度学习的基本组成部分,自上世纪六七十年代诞生以来,已经历了重大的进步和完善。

4.1 早期发展(1970年代)
- Seppo Linnainmaa(1970年):提出了自动微分的概念,这是反向传播算法的关键组成部分。
- Paul Werbos,(1974年):提出使用微积分的链式法则来计算误差函数相对于网络权重的梯度,从而实现了多层神经网络的训练。
4.2 完善与普及(1980年代)
- David Rumelhart、Geoffrey Hinton和Ronald Williams(1986年):提出反向传播是训练深度神经网络的实用高效方法,并演示了其在各种问题中的应用。
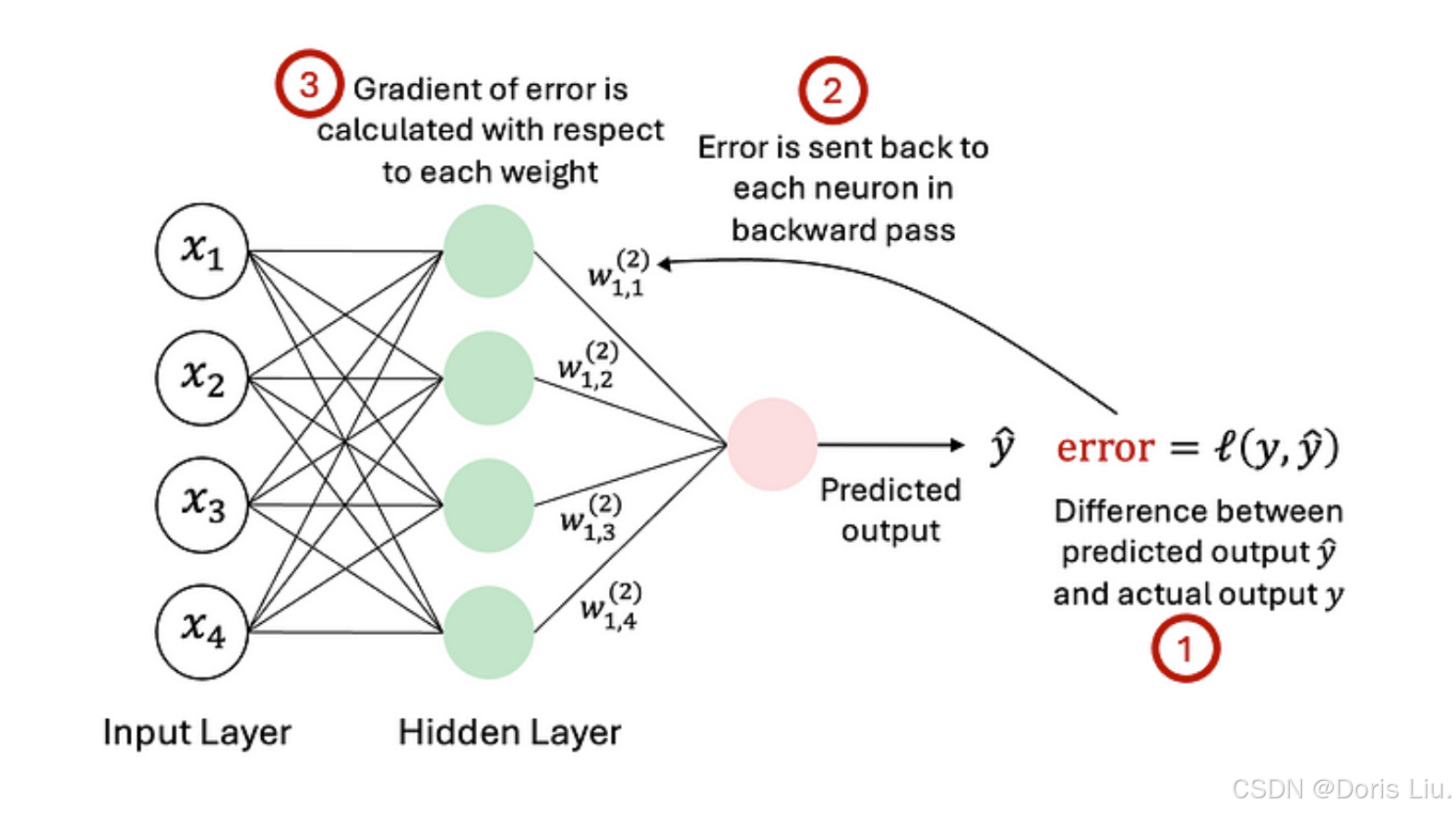
4.3 反向传播的主要特点
- 梯度下降:反向传播法与梯度下降法结合使用,可使误差函数最小化。该算法会计算网络中每个权重的误差梯度,从而反复更新权重以减少误差。
- 链式法则:反向传播算法的核心是微积分链式法则的应用。该规则可将误差梯度分解为一系列偏导数,并通过网络反向传递进行高效计算。
- 分层计算:反向传播以逐层方式运行,从输出层开始,向后延伸至输入层。这种分层计算可确保梯度在网络中正确传播,从而实现深度架构的训练。
4.4 通用近似定理(1989)
George Cybenko于1989年提出的通用近似定理为多层神经网络的功能提供了数学基础。该定理指出,只要有足够的神经元并使用非线性激活函数,具有单隐层的前馈神经网络就能以任意精确度逼近任何连续函数。该定理强调了神经网络的强大功能和灵活性,使其广泛的适用于应用领域。
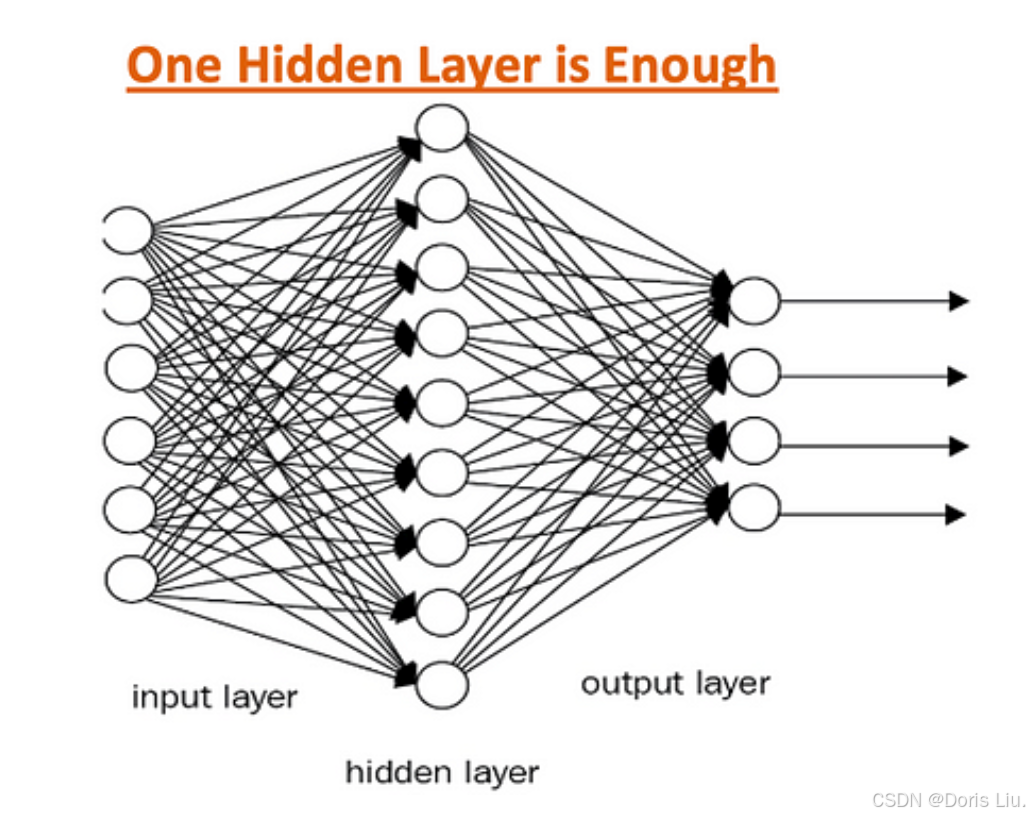
具有单个隐藏层的多层神经网络可以将任何连续函数近似到任何所需的精度,从而解决各个领域的复杂问题。
4.5第二个黄金时代(1980年代末-1990年代初)
反向传播和通用近似定理(UAT)的发展标志着神经网络第二个黄金时代的开始。反向传播提供了训练多层神经网络的有效方法,使研究人员能够训练更深、更复杂的模型。UAT为多层神经网络的使用提供了理论依据,并增强了人们对其解决复杂问题能力的信心。在20世纪80年代末和90年代初这一时期,人们对多层神经网络的兴趣再次高涨,该领域也取得了重大进展。
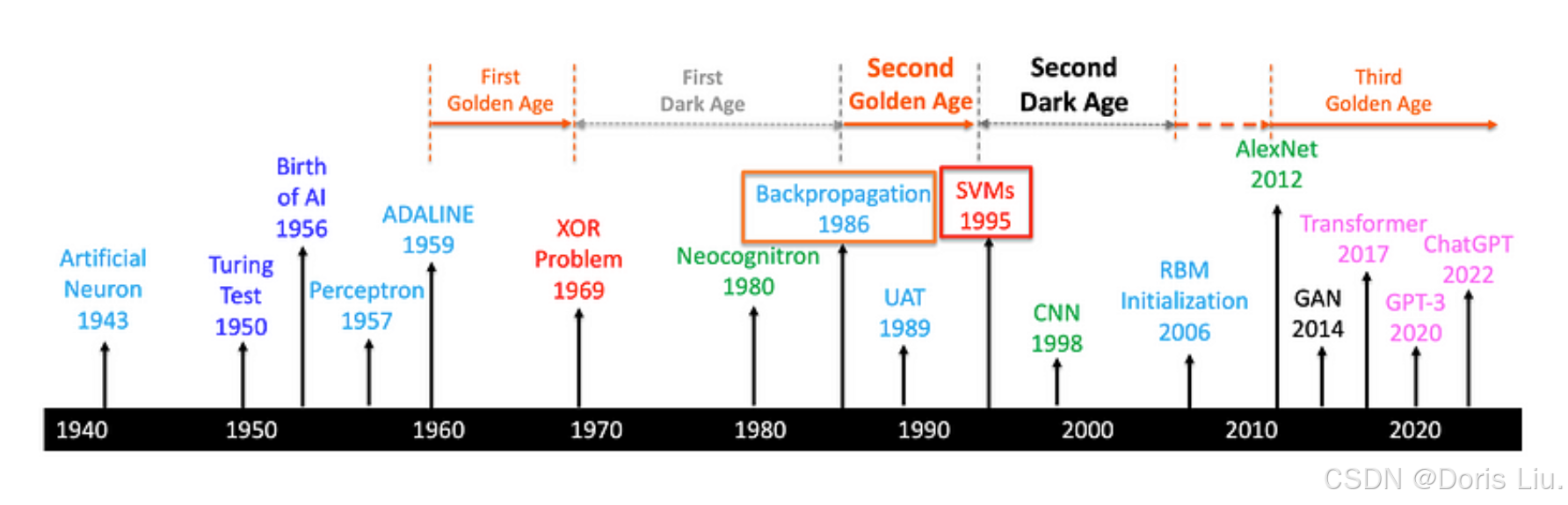
4.6第二个黑暗时代(1990年代初-2000年代初)
然而,由于多种原因,神经网络领域在20世纪90年代初至21世纪初经历了“第二个黑暗时代”:
- 支持向量机(SVM)的兴起,为分类和回归任务提供了一种数学上的优雅方法。
- 计算限制,因为训练深度神经网络仍然耗时且需要大量硬件。
- 过度拟合和泛化问题,早期的神经网络在训练数据上表现良好,但在未见过的数据上却表现不佳,这使得它们在实际应用中的可靠性大打折扣。
这些挑战导致许多研究人员将注意力从神经网络上转移开,造成该领域一度停滞不前。
4.7 深度学习的复苏(2000年末至今)
神经网络领域在2000年代末和2010年代初经历了一次复兴,其驱动力来自于以下方面的进步:
- 深度学习架构(CNN、RNN、Transformers、扩散模型)
- 硬件(GPU、TPU、LPU)
- 大规模数据集(ImageNet、COCO、OpenWebText、WikiText等)
- 训练算法(SGD、Adam、dropout)
这些进步带来了计算机视觉、自然语言处理、语音识别和强化学习方面的重大突破。通用近似定理与实际进展相结合,为深度学习技术的广泛应用和成功铺平了道路。
5.卷积神经网络(1980年代 - 2010年代)
卷积神经网络(CNN)极大地改变了深度学习的面貌,尤其是在计算机视觉和图像处理领域。从20世纪80年代到2010年代,卷积神经网络在架构、训练技术和应用方面取得了长足的进步。
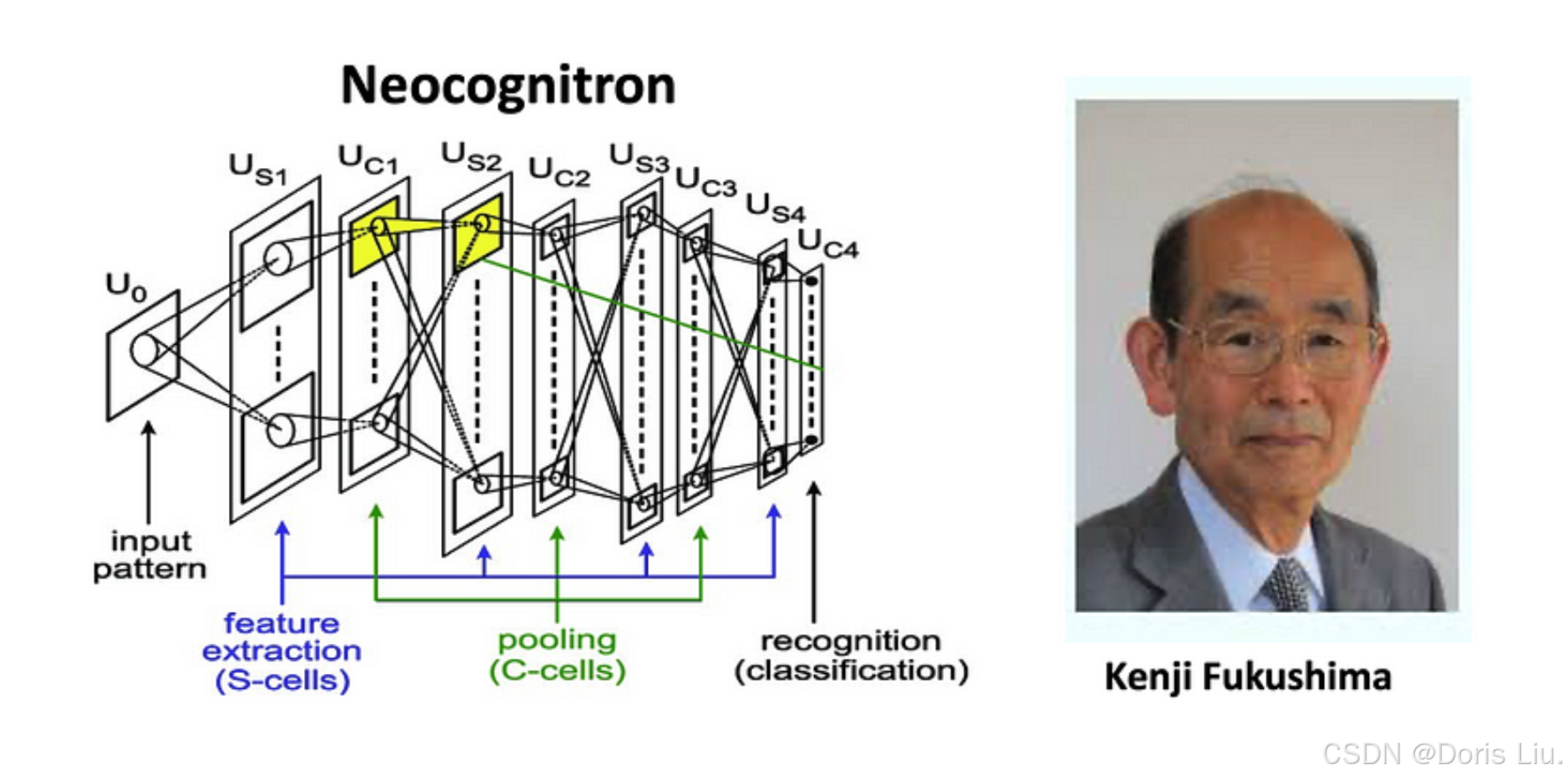
5.1 早期发展(1989-1998)
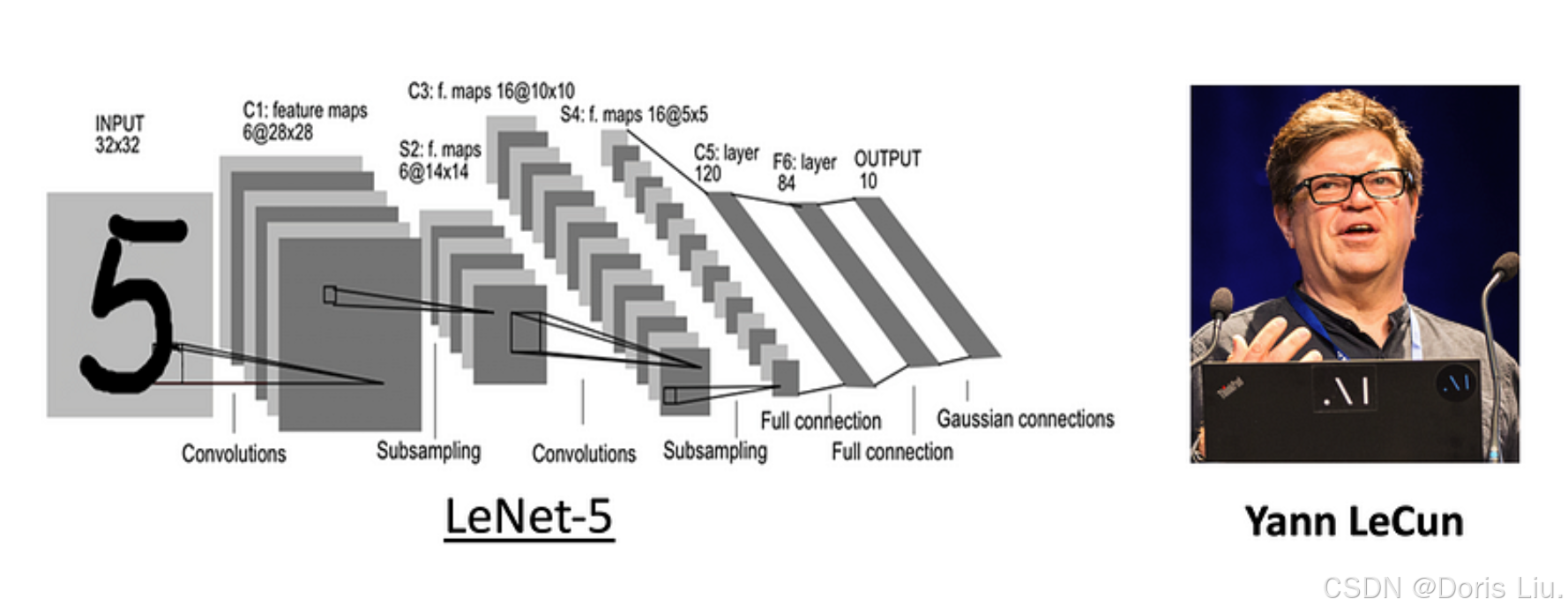
20世纪80年代,Kenji Fukushima首次提出了CNN的概念,他提出的Neocognitron是一种模仿人类视觉皮层结构的分层神经网络。这一开创性工作为CNN的发展奠定了基础。20世纪80年代末和90年代初,Yann LeCun及其团队进一步开发了CNN,推出了专为手写数字识别设计的LeNet-5架构。
5.2 CNN的关键组件
CNN由三个关键部分构成:
- 卷积层:这些层通过应用一组可学习的滤波器,自动学习输入图像的空间层次特征。
- 汇集层:汇集层减少了输入的空间维度,提高了对变化的稳健性,并降低了计算负荷。
- 全连接层:继卷积层和池化层之后,全连接层用于完成分类任务,整合从之前的层中学习到的特征。
5.3CNN的主要特性
- 本地接收区域:CNN使用局部感受字段来捕捉输入数据中的局部模式,因此在图像和视觉任务中非常有效。
- 共享权重:在卷积层中使用共享权重可减少网络中的参数数量,使其更高效、更易于训练。
- 翻译不变性:池化层引入了平移不变性,使网络能够识别输入图像中的任何位置的模式。
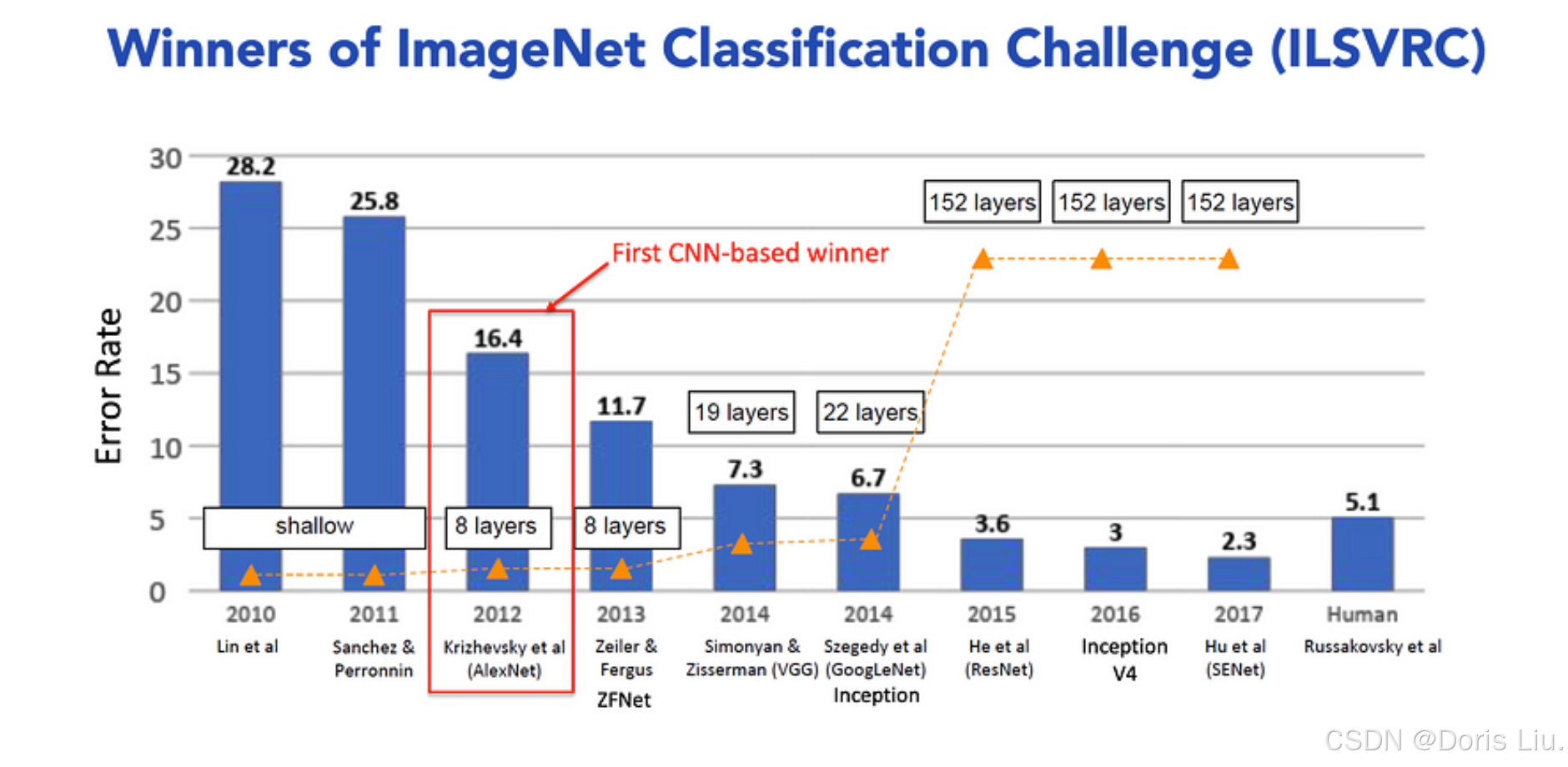
5.4 CNN的崛起:AlexNet的影响(2012)
2012年,AlexNet在“ImageNet大规模视觉识别挑战赛”(ILSVRC)中脱颖而出,取得了重大胜利,标志着图像分类领域的重大突破,这是CNN发展史上的一个重要里程碑。
ILSVRC是一项年度图像识别基准测试,在由1000多万张注释图像组成的数据集上对算法进行评估,这些图像被分为1000个类别。
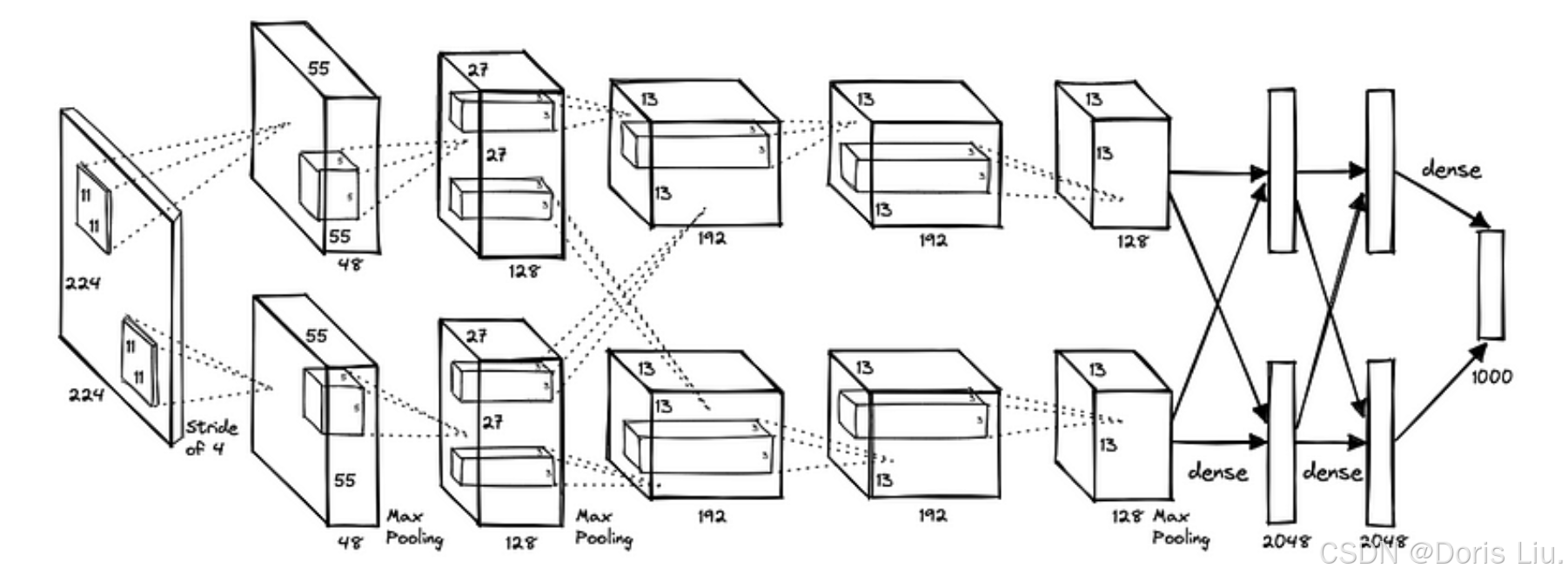
AlexNet的架构(2012)
AlexNet的创新包括
- ReLU激活函数:引入ReLU是为了克服传统激活函数的问题,ReLU能够加快训练速度并提高性能。
- 丢弃正则化:这项技术通过在训练过程中随机丢弃单元来减少过度拟合。
- 数据增强:通过人为增加训练数据的多样性来增强训练数据集,从而提高泛化能力。
AlexNet的成功标志着CNN发展的转折点,为进一步推动图像分类和物体检测的发展铺平了道路。
AlexNet开启了神经网络的第三个黄金时代
当前的黄金时代(2010年代至今)以深度学习、大数据和强大计算平台的融合为标志。在这个时代,图像识别、自然语言处理和机器人技术都取得了令人瞩目的突破。正在进行的研究继续推动人工智能能力的发展。
AlexNet开启了神经网络的第三个黄金时代
5.5 后续架构
继AlexNet之后,又出现了几种有影响力的架构:
- VGGNet(2014年):VGGNet由牛津大学视觉几何小组开发,它强调使用更小的卷积滤波器(3x3)来构建更深层次的架构,从而实现了出色的准确性。
- GoogLeNet/Inception(2014年):引入初始模块,使网络能够有效捕捉多尺度特征。
- ResNet(2015 年):残差网络(Residual Networks)引入了跳转连接,从而能够训练非常深的网络,同时缓解梯度消失问题。
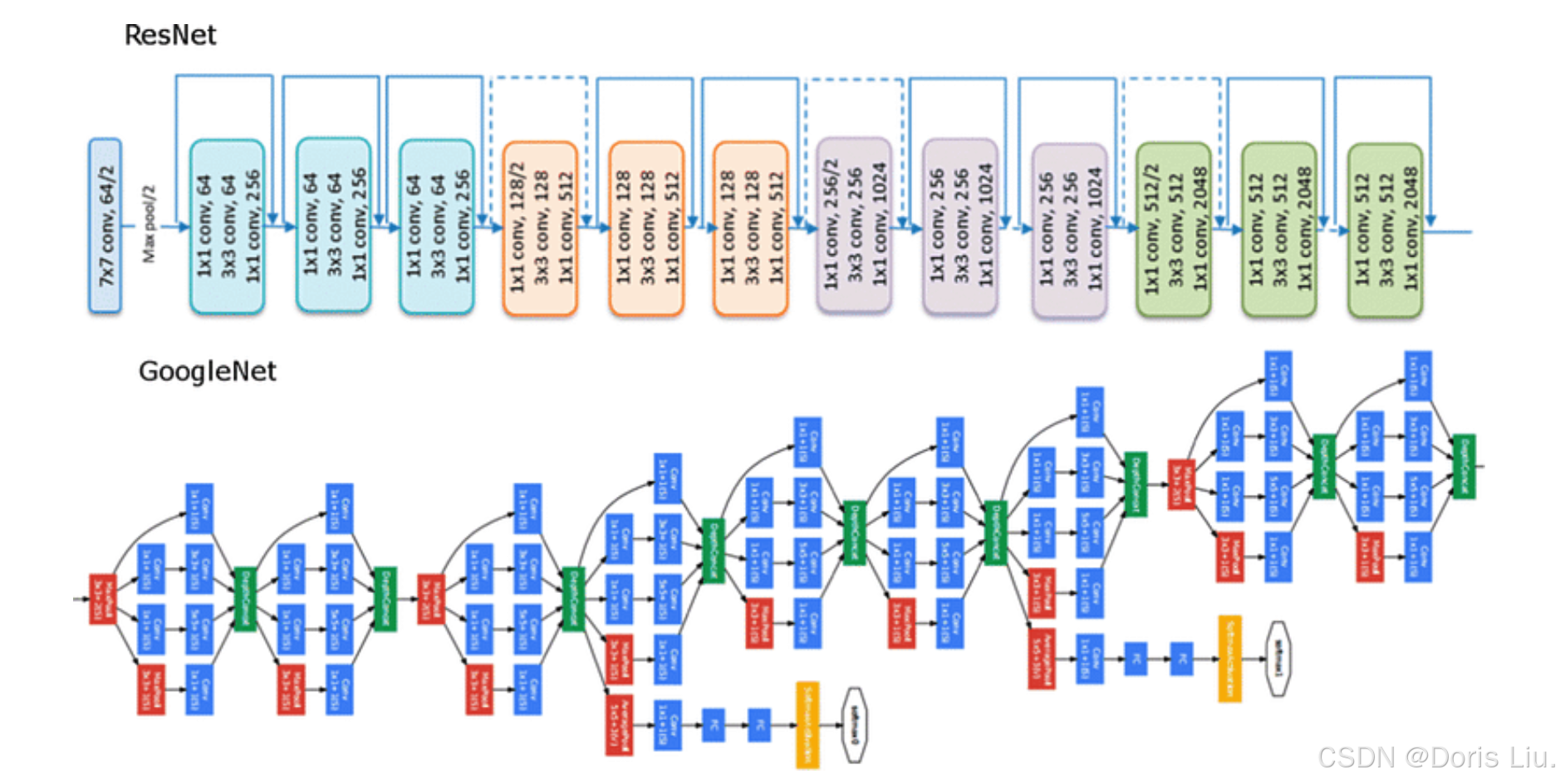
ResNet和GoogeNet架构
5.6 CNN的应用
CNN的进步给各个领域带来了革命性的变化:
- 计算机视觉:CNN已成为现代计算机视觉的支柱,在图像分类、物体检测和语义分割方面取得了突破性进展。
- 医学成像:CNN可用于疾病诊断、肿瘤检测和图像引导手术等任务,显著提高诊断准确性。
- 自动驾驶汽车:CNN是自动驾驶汽车感知系统不可或缺的组成部分,使其能够解释和应对周围环境。
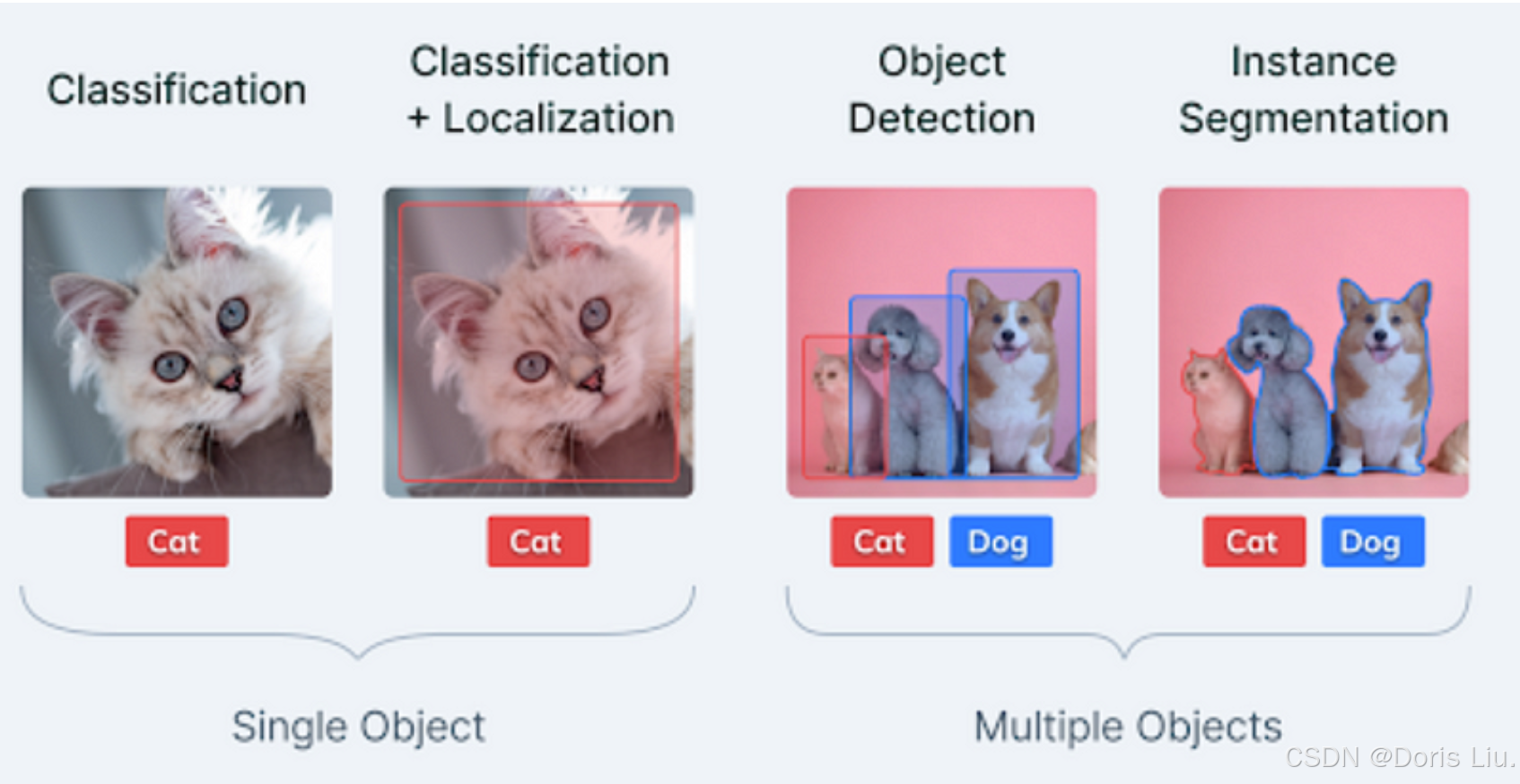
CNN的计算机视觉应用
CNN从诞生到现在成为深度学习的基石,其发展历程说明了CNN对人工智能的深远影响。CNN的成功也为深度学习的进一步发展铺平了道路,并激发了其他专业神经网络架构(如RNN和Transformers)的发展。CNN的理论基础和实践创新极大地推动了深度学习技术在各个领域的广泛应用和成功。
6.递归神经网络(1986-2017)
递归神经网络(RNN)是一种处理序列和时间数据的强大架构。与前馈神经网络不同,RNN设计用于处理输入序列,因此在语言建模、时间序列预测和语音识别等任务中特别有效。
6.1 早期发展(1980s-1990s)
RNN的概念可追溯到20世纪80年代,约翰-霍普菲尔德(John Hopfield)、迈克尔-乔丹(Michael I. Jordan)和杰弗里-埃尔曼(Jeffrey L. Elman)等先驱为这些网络的发展做出了贡献。约翰-霍普菲尔德于1982年提出的霍普菲尔德网络为理解神经网络中的递归连接奠定了基础。乔丹网络和埃尔曼网络分别于20世纪80年代和90年代提出,是捕捉连续数据中时间依赖性的早期尝试。
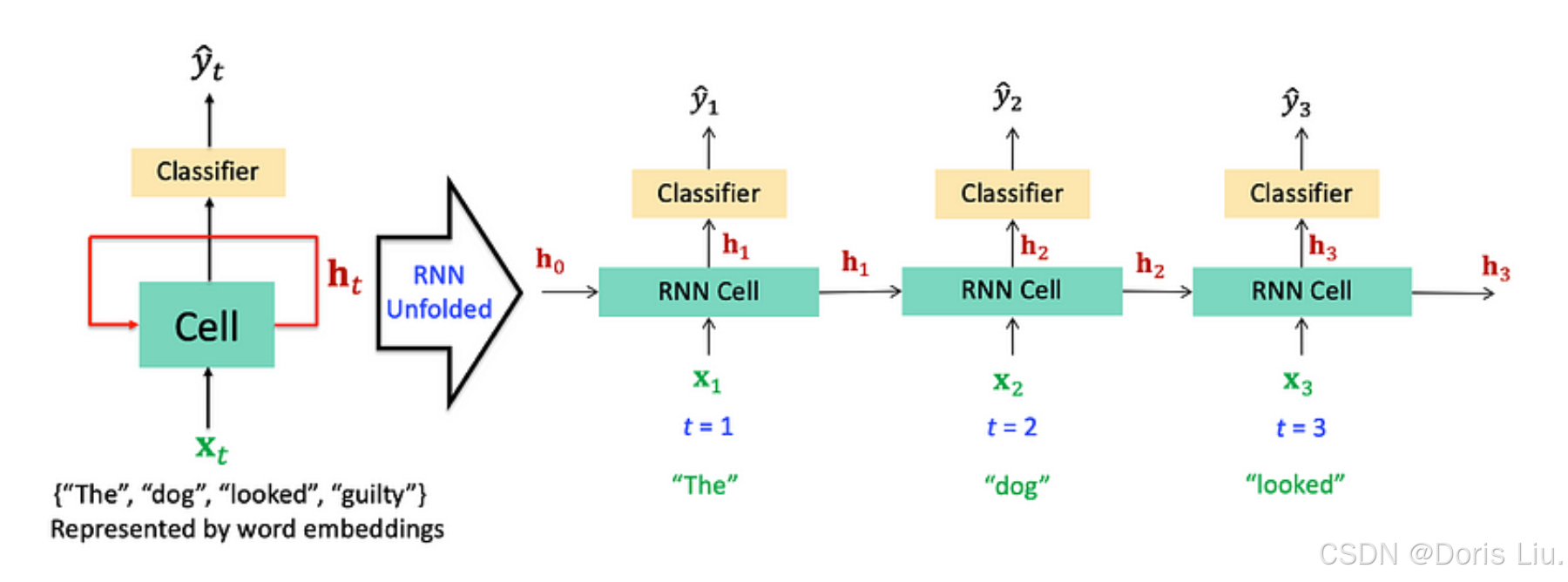
6.2 LSTM模型、GRU模型和Seq2Seq模型(1997 — 2014)
- 长短期记忆(LSTM)网络(1997年):Sepp Hochreiter和Jürgen Schmidhuber引入了长短期记忆(LSTM)网络,解决了传统RNN中梯度消失的问题。LSTM使用门控机制来控制信息流,从而能够捕捉连续数据中的长期依赖关系。
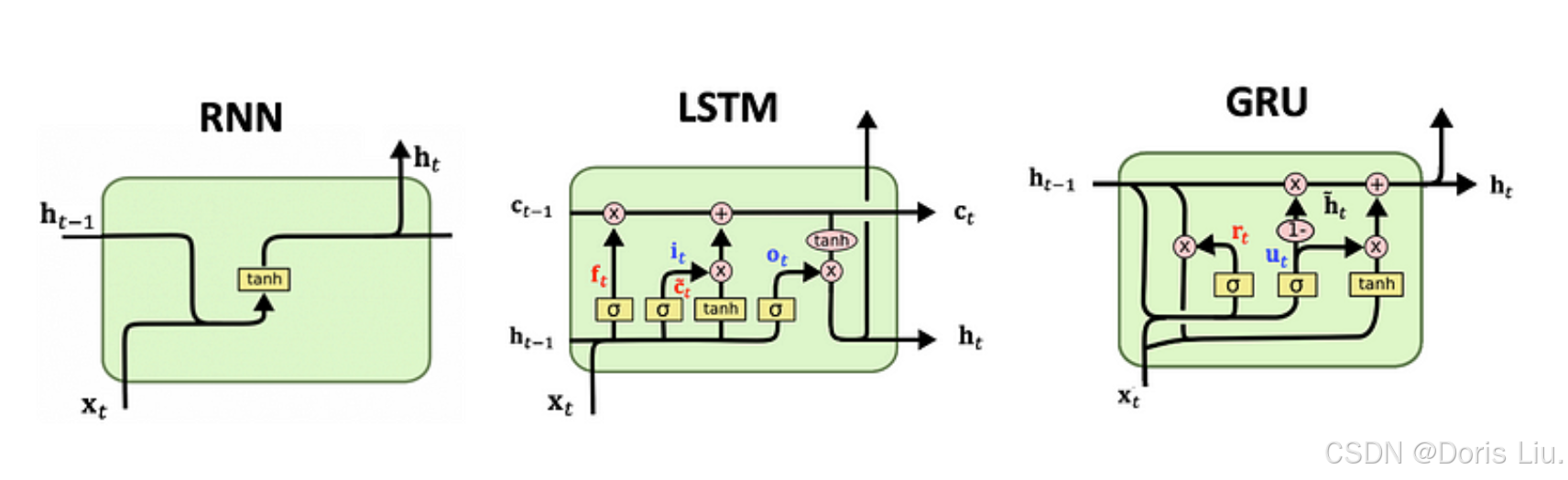
- 门控递归单元(GRUs)(2014年): Kyunghyun Cho等人提出了门控递归单元(GRUs),它是LSTM的简化版,也使用门控机制来控制信息流。与LSTMs相比,GRU的参数更少,训练速度通常更快。
- 序列到序列模型(Seq2Seq)(2014年):Ilya Sutskever和他的团队推出了Seq2Seq模型,该模型使用编码器-解码器架构将输入序列映射到输出序列。该模型已广泛应用于机器翻译、语音识别和文本摘要等任务。
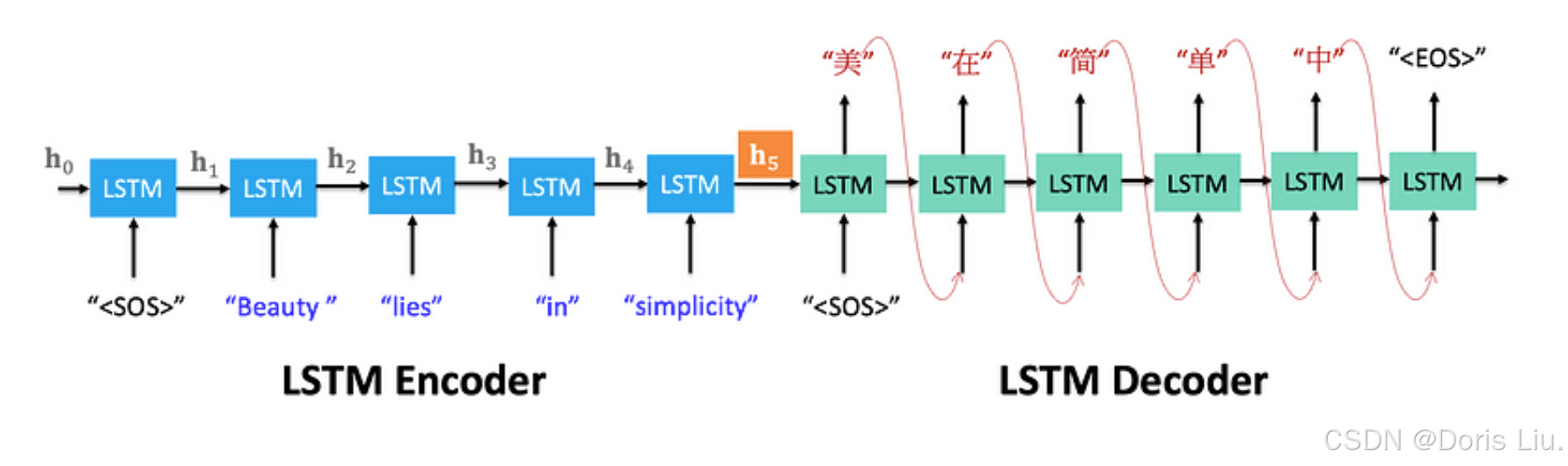
6.3 RNN的主要特征:递归连接
RNN使用递归连接来维持隐藏状态,以捕捉前一时间步骤的信息。这样,网络就能为连续数据中的时间依赖性建模。
通过时间反向传播(BPTT):RNN采用一种名为“时间反向传播”(BPTT)的反向传播变体进行训练,这种变体会随着时间的推移展开递归网络,并将标准反向传播算法应用于展开的网络。
门控机制:先进的RNN架构(如LSTM和GRU)使用门控机制来控制信息流,有助于缓解梯度消失问题,并使网络能够捕捉长期依赖关系。
6.4 RNN的应用
RNN对多个领域产生了重大影响,包括
- 自然语言处理:RNN彻底改变了自然语言处理领域,使语言建模、机器翻译、情感分析和文本生成等任务取得了重大进展。
- 语音识别:RNN广泛应用于语音识别系统中,通过模拟口语中的时间依赖关系,将语音信号转换为文本。
- 时间序列预测:RNN对于时间序列预测非常有效,它可以模拟连续数据中的时间依赖关系,从而预测未来值。
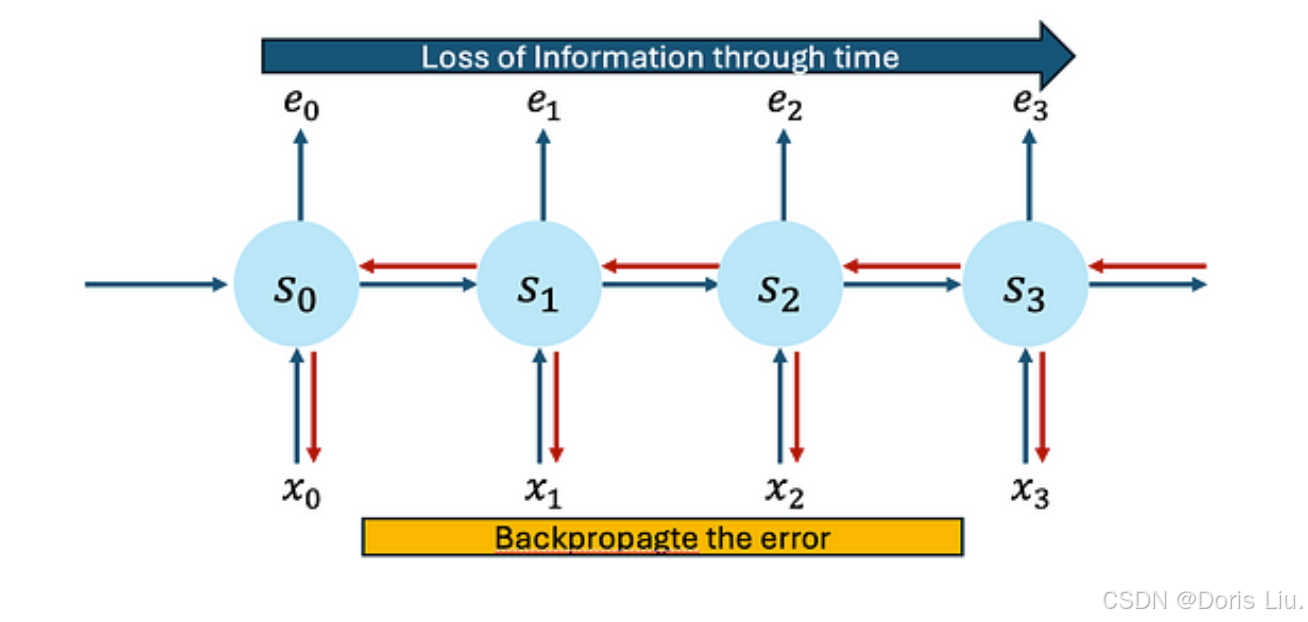
6.5 RNN的挑战
尽管RNN取得了成功,但也面临着一些挑战:
- 消失梯度和爆炸梯度:传统的RNN难以解决这些问题,尽管LSTM和GRUs提供了一些解决方案。
- 计算复杂性:训练RNN可能会耗费大量资源,尤其是在大型数据集上。
- 并行化:RNN的顺序性使并行训练和推理过程变得复杂。
RNN的成功为深度学习的进一步发展铺平了道路,并激发了其他专业神经网络架构(如Transformers)的发展,这些架构在各种序列数据任务中实现了最先进的性能。RNN的理论基础和实践创新极大地推动了深度学习技术在各个领域的广泛应用和成功。
7.Transformer模型(2017至今)
Transformer凭借其处理连续数据的卓越能力,改变了深度学习的格局,在从自然语言处理(NLP)到计算机视觉等众多领域中发挥着举足轻重的作用。
7.1 Transformer简介(2017)
Transformer模型是由Vaswani等人(2017年)在开创性论文“Attention is All You Need”中提出的。该模型摒弃了传统的RNNs顺序处理,转而采用自我注意机制,从而实现了并行处理,并能更好地处理长程依赖关系。
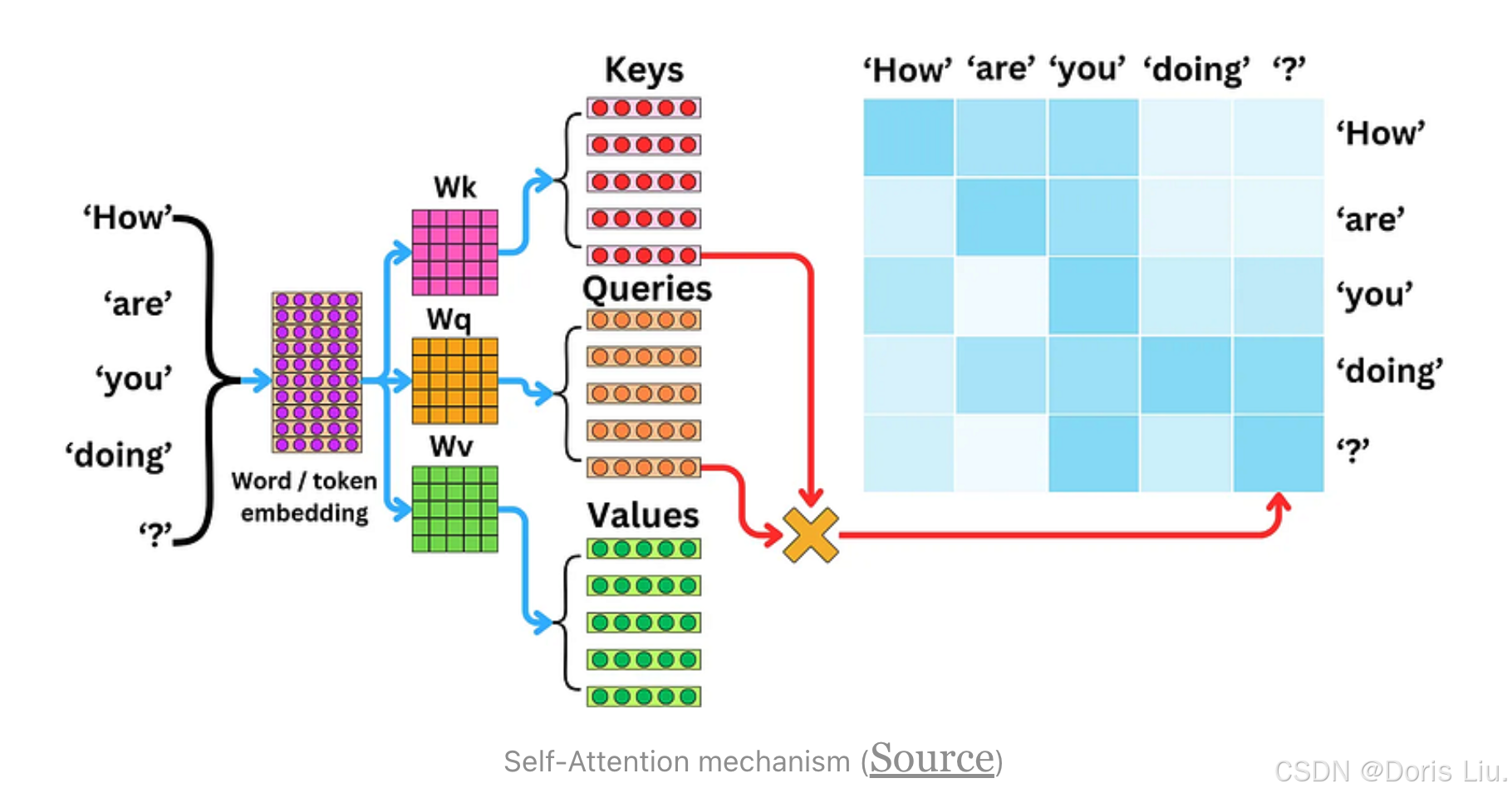
7.2 Transformers的主要特点
- 自我关注机制:允许序列中的每个位置关注所有位置,比RNN或LSTM更灵活地捕捉上下文。
- 并行化:通过同时处理所有输入数据来提高训练速度,这与RNN的顺序性形成鲜明对比。
- 编码器-解码器结构:编码器和解码器堆栈都利用自注意和前馈神经网络层,并通过位置编码来保持序列顺序。
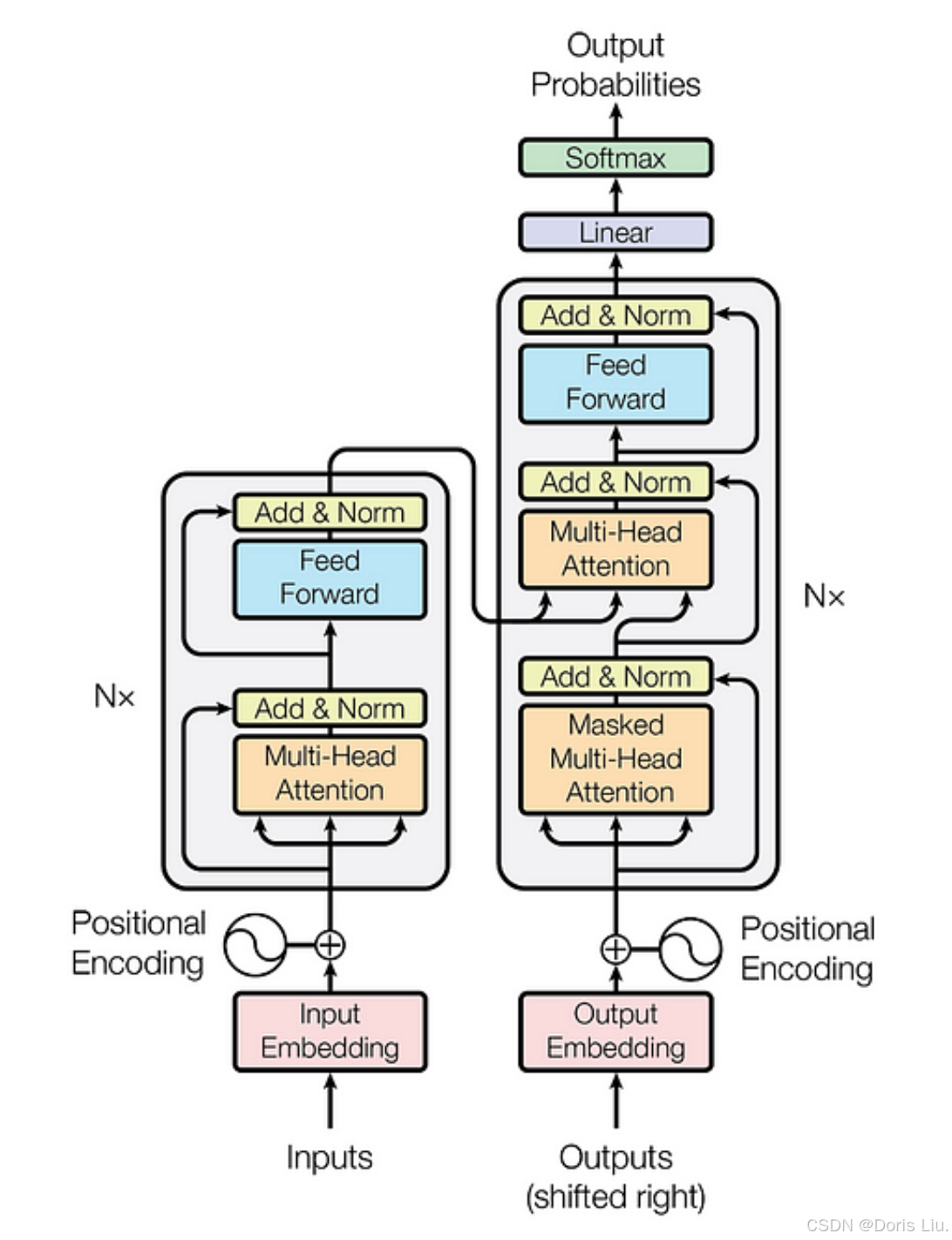
原始Transformer结构具有编码器-解码器结构和多头注意力
基于transformer的语言模型
7.3基于Transformer的语言模型(2017年至今)
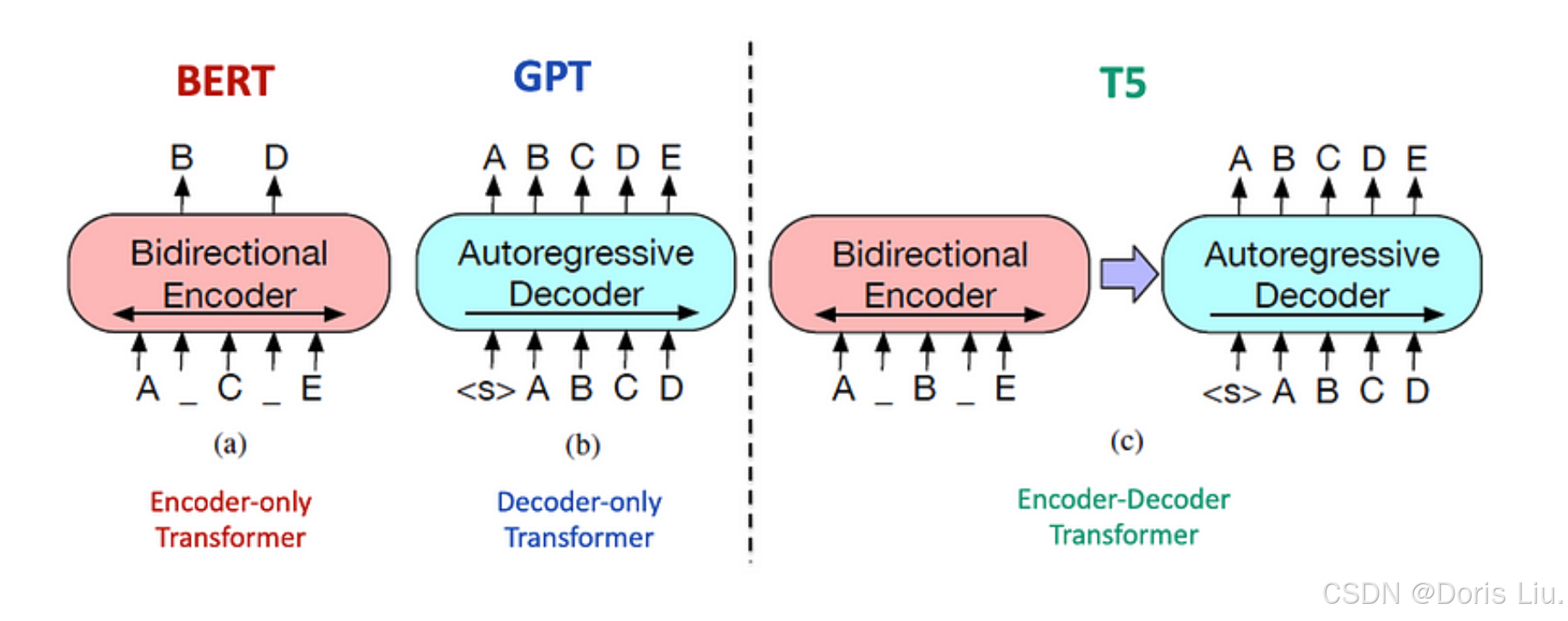
- BERT(2018):来自Transformer的双向编码器表征(Bidirectional Encoder Representations from Transformers),一种仅编码器的Transformers模型,通过对遮蔽语言建模和下一句预测进行预训练,彻底改变了NLP。
- T5(2019):文本到文本传输模型,是一种编码器-解码器的Transformers模型,它将NLP任务重构为文本到文本格式,简化了模型架构和训练。
OpenAI 的 GPT 系列:
- GPT(2018):生成式预训练transformer模型(Generative Pre-trained Transformer)是由OpenAI推出的自回归解码器专用transformer,专注于预测文本序列中的下一个单词,展示了令人印象深刻的语言理解和生成能力。
- GPT-2(2019年):与前者相比,它的规模要大得多,并展示了零镜头任务性能等新兴能力,由于它能够生成连贯的文本(尽管有时会产生误导),引发了关于人工智能潜在滥用问题的讨论。
- GPT-3(2020年):GPT-3拥有1750亿个参数,进一步扩大了语言模型的应用范围,在微调最小的任务中表现出色,即所谓的“少量学习”。GPT-3是一种仅用于解码的transformer模型,其自回归架构使其能够根据序列中的前一个单词,一次生成一个单词的文本。
- ChatGPT(2022):GPT-3.5系列模型的微调版本,针对对话式参与进行了优化,展示了指令调整使模型响应与用户意图相一致的威力。
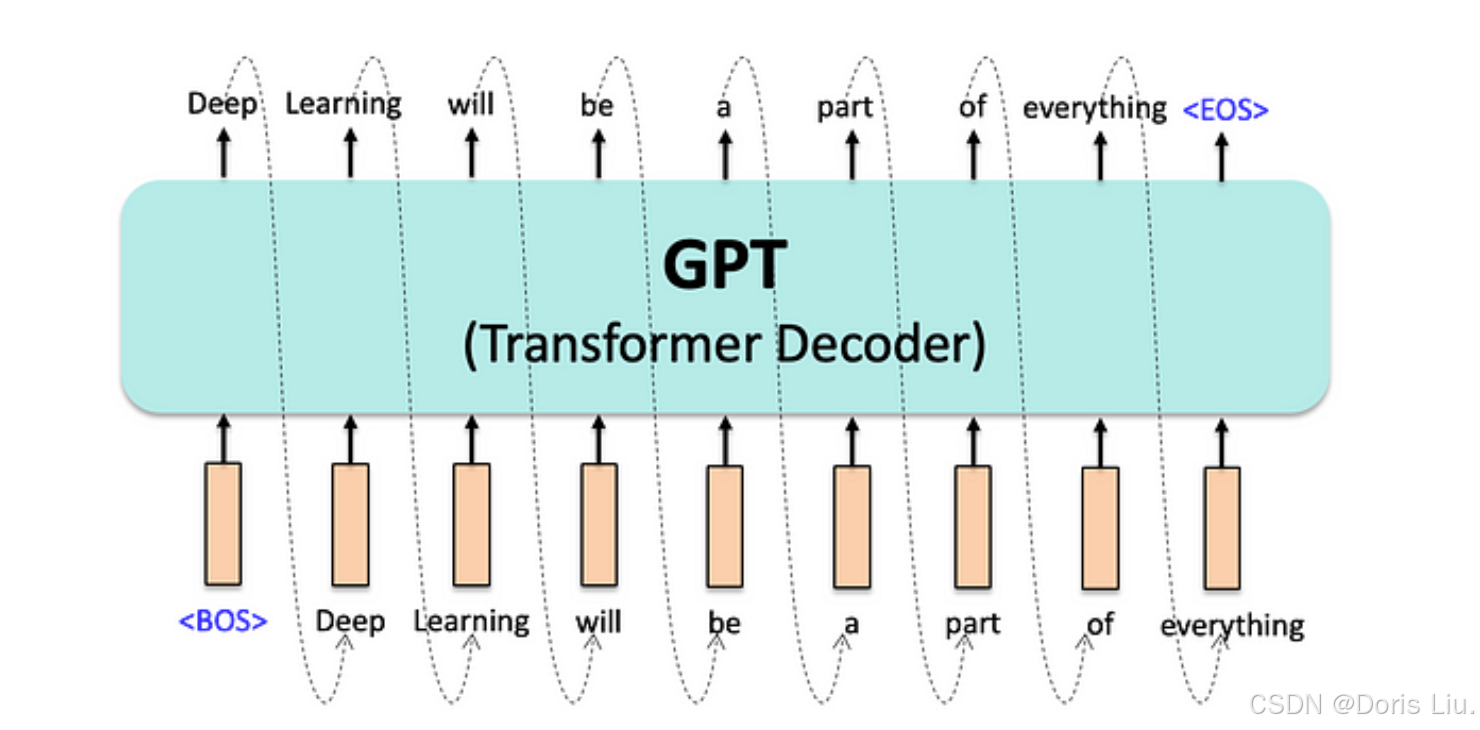
GPT 的自回归语言模型架构旨在根据之前输入的标记预测序列中的下一个标记
7.4 其他知名的大型语言模型(LLM)
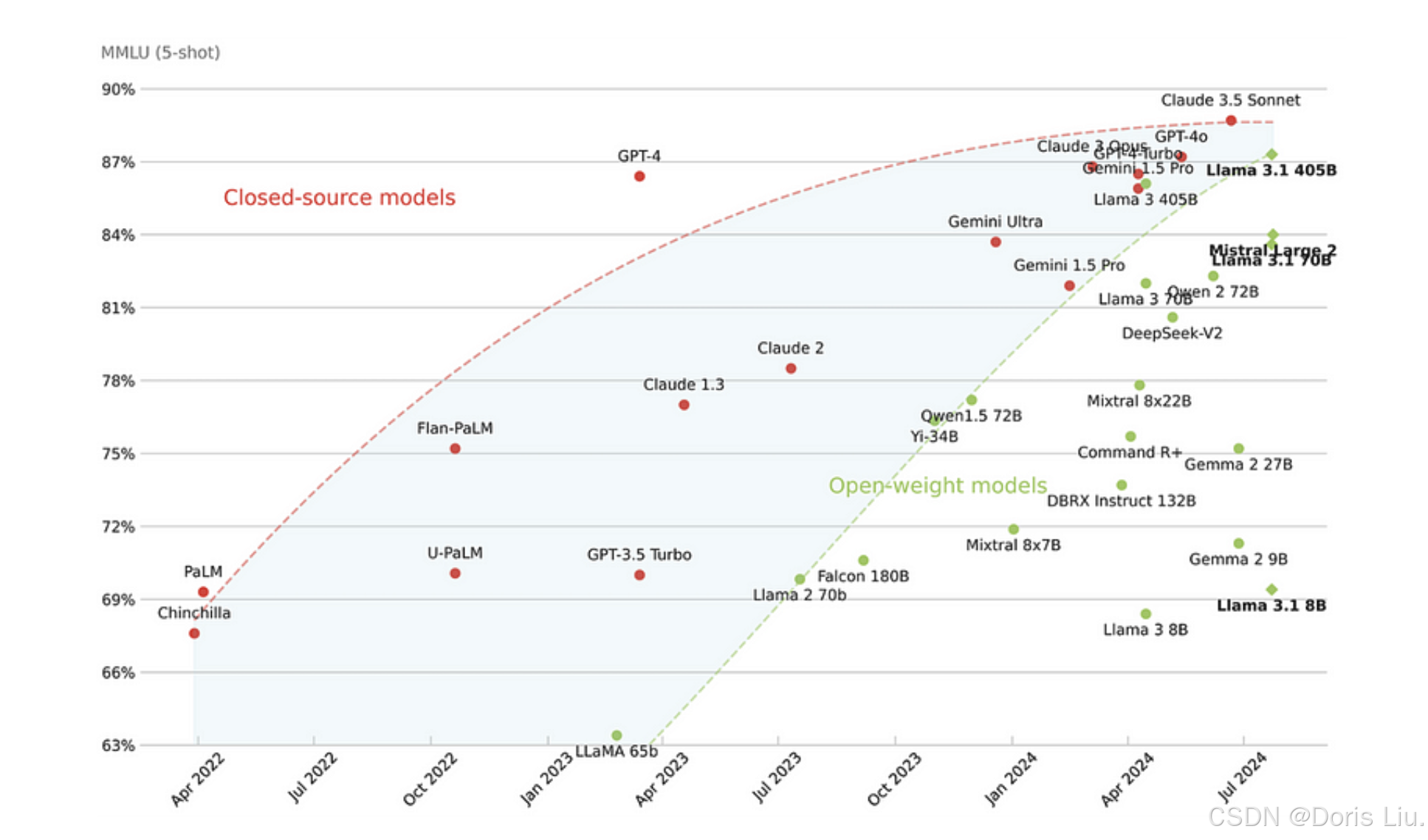
大型语言模型(LLM)的面貌因各种著名模型而大大丰富,每种模型都具有独特的功能和人工智能方面的进步。下面是一些著名LLM的最新概述:
- Anthropic's Claude(2022年):优先考虑人工智能产出的安全性和伦理因素,旨在与人类价值观保持一致。
- Meta的LLaMA(2023年):针对不同的计算需求提供不同规模的模型,在自然语言处理基准测试中取得了令人瞩目的成绩。
- Mistral.AI的Mistral(2023年):兼顾高性能和资源效率,是实时应用的理想选择,侧重于开源人工智能解决方案。
- Alibaba的Qwen(2023年):创建高质量的中英文双语人工智能模型,促进跨语言应用并鼓励创新。
- 微软的Phi(2023年):强调在各种应用中的通用性和集成性,采用先进的训练技术来实现上下文理解和用户交互。
- Google的Gemma系列(2024年):轻量级、最先进的开放式模型,适用于文本生成、摘要和提取等各种应用,注重性能和效率。
https://www.analyticsvidhya.com/blog/2023/07/build-your-own-large-language-models/
 https://readmedium.com/fine-tune-llama-3-1-ultra-efficiently-with-unsloth-7196c7165bab
https://readmedium.com/fine-tune-llama-3-1-ultra-efficiently-with-unsloth-7196c7165bab
8.多模式模型(2023年至今)
8.1 GPT-4V(2023年)和GPT-4-o(2024年)
GPT-4V(2023年)将多模态功能集成到已经非常强大的基于文本的模型中,标志着人工智能发展迈出了重要一步。它不仅能处理和生成文本内容,还能处理和生成图像内容,为更全面的人工智能交互奠定了基础。

GPT-4-o(2024)是GPT-4V的进化版,它通过复杂的上下文理解增强了多模态集成。与前代产品相比,GPT-4-o具有更好的跨媒体一致性、根据文本提示生成高级图像以及基于视觉输入的精细推理能力。此外,GPT-4-o还包括先进的道德调整培训机制,确保其输出结果不仅准确,而且负责任,符合人类价值观。
8.2 谷歌的“双子座”(2023年至今)
- Gemini Pro(2023年):谷歌的Gemini推出了一系列专为多模态任务设计的模型,集成了文本、图像、音频和视频处理功能。尤其是Gemini Pro,它以其可扩展性和高效性脱颖而出,使高级人工智能可用于从实时分析到跨不同媒体格式的复杂内容生成等各种应用。
- Gemini的多模式功能:Gemini模型(包括适用于不同规模应用的Ultra和Nano版本)设计用于执行需要理解多种数据类型的任务。它们在视频摘要、多模态翻译和交互式学习环境等任务中表现出色,体现了谷歌致力于推动人工智能在多媒体环境中发挥作用的决心。

8.3 Claude3.0和Claude3.5(2023年至今)
- Claude3.0(2023年)由Anthropic推出,该模型侧重于提高人工智能响应的安全性和可靠性,并在上下文理解和伦理考虑方面有所改进。它旨在提高对话性和帮助性,同时严格遵守避免有害或有偏见输出的原则。
- Claude3.5(2024年)进一步完善了Claude 3.0的功能,在复杂任务中提供了更好的性能,提高了处理效率,对用户请求的处理更加细致入微。该版本还强调了多模态交互,虽然它主要擅长文本和逻辑任务,但在处理视觉或其他感官输入方面也有新的功能,可为用户带来更全面的体验。
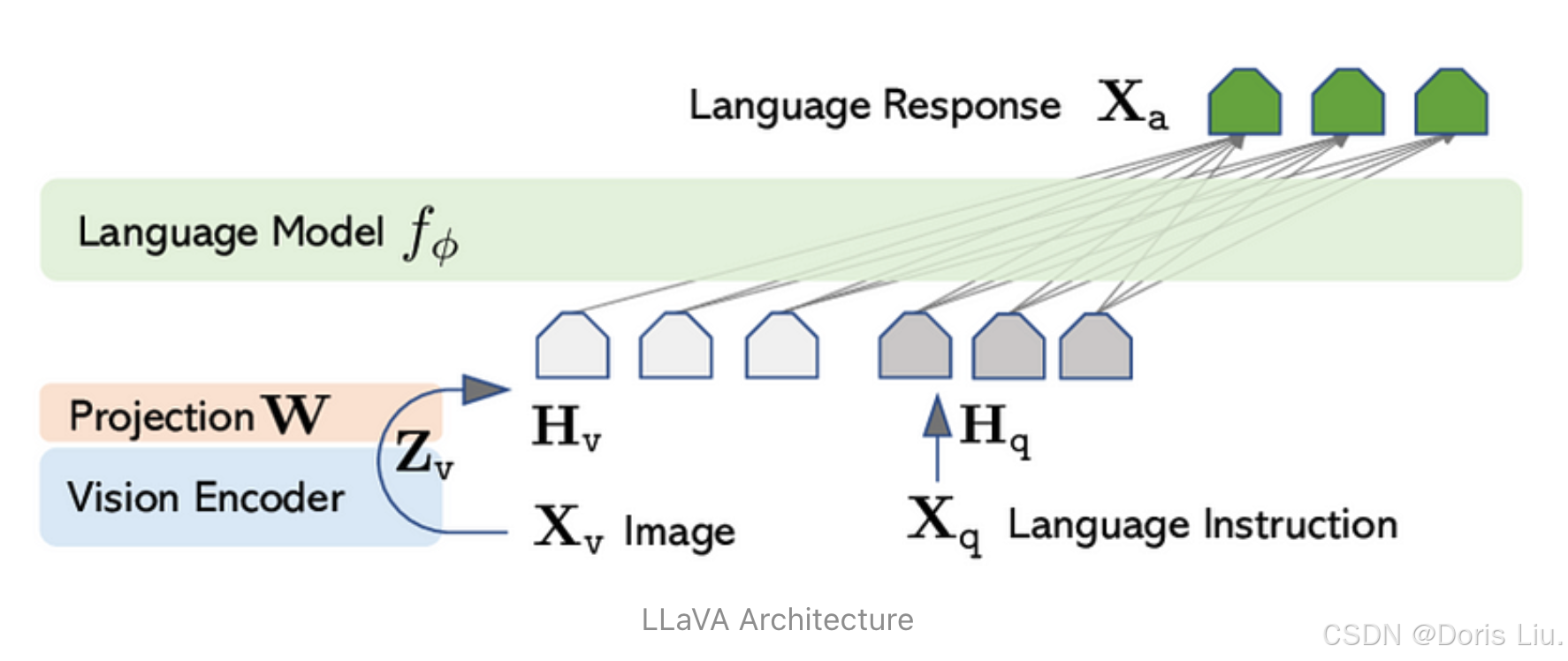
8.4 LLaVA(2023)
LLaVA(大型语言和视觉助理)是多模态人工智能的一种创新方法,它将语言理解与视觉处理相结合。LLaVA开发于2023年,可以解释图像并将图像与文本内容联系起来,从而能够回答有关图像的问题、描述视觉内容,甚至根据视觉线索生成文本。其架构充分利用了transformer模型的优势,在需要视觉和语言理解的任务中实现了最先进的性能。该模型因其开源性而备受瞩目,鼓励了多模态人工智能应用领域的进一步研究和开发。
8.5 OpenAI Sora (2024)
OpenAI Sora是一种新的文本到视频生成模型,它扩展了OpenAI多模态人工智能产品的功能。该模型允许用户根据文本描述创建视频,有效弥合了文本与动态视觉内容之间的差距。Sora与多模态框架的整合增强了创造性应用的潜力,使用户能够以最少的输入生成丰富的多媒体内容。这一发展标志着我们朝着能够理解和生成复杂媒体形式的更直观、更互动的人工智能系统迈出了重要一步。
9.扩散模型(2015至今)
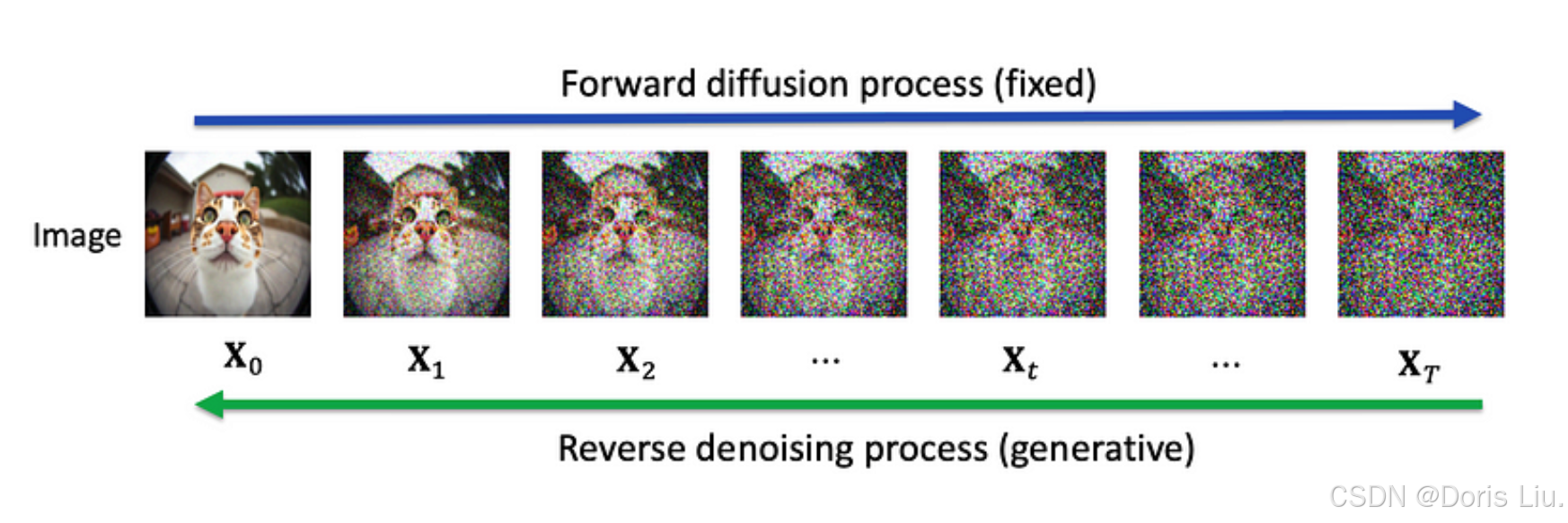
扩散模型是生成模型中颇具影响力的一类,它为从错综复杂的数据分布中创建高保真样本提供了一种全新的方法。它们的方法与GANs和VAEs等传统模型不同,采用了渐进式去噪技术,在众多应用中表现出色。
9.1 扩散模型简介(2015)
Sohl-Dickstein等人(2015年)的论文引入了扩散模型,为这一研究奠定了基础。他们构思了一个生成过程,在这个过程中,逆转逐渐增加的噪点可以将噪点重新转化为结构化数据。
9.2 扩散模型的主要特点
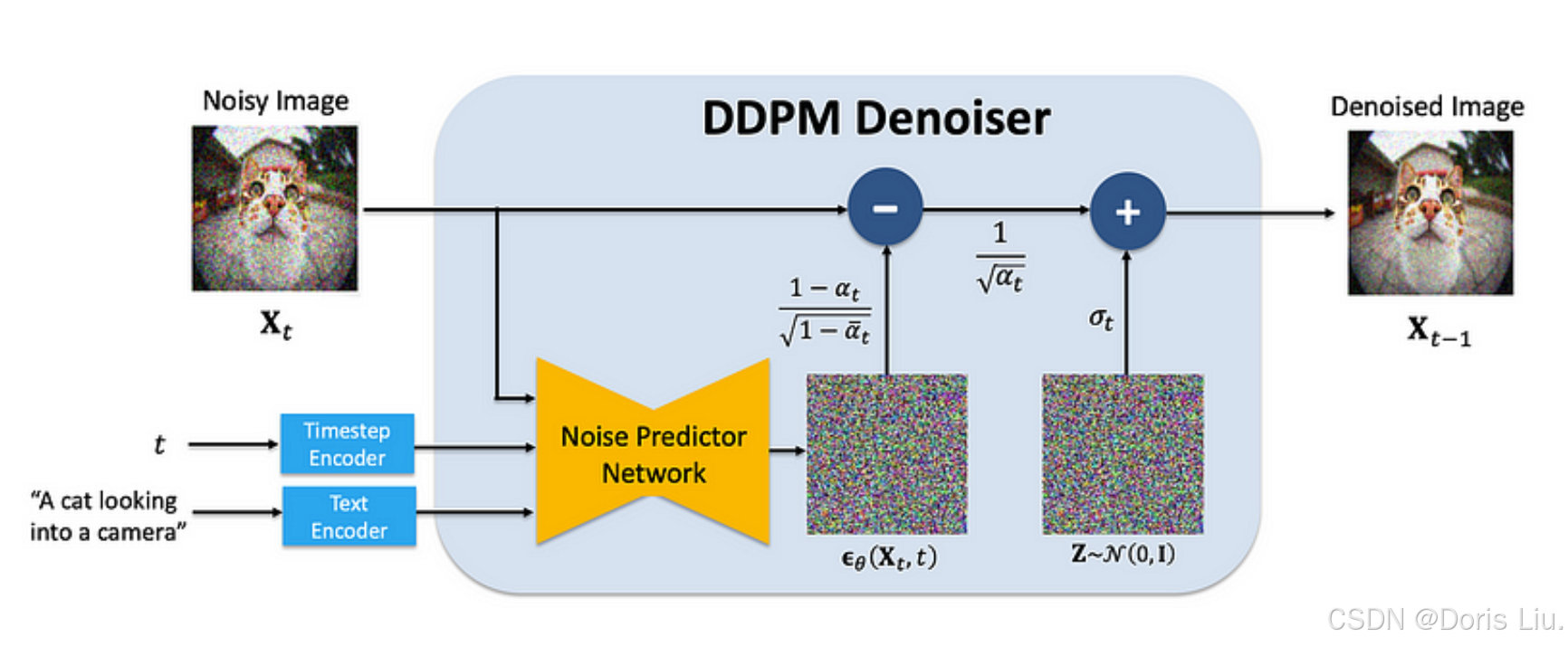
- 去噪过程:这些模型分步添加噪点(前向过程),并学习逆转噪点(后向过程),从而有效地去噪生成样本。
- 马尔可夫链:这两个过程都是马尔可夫链结构,每个前向步骤都会增加高斯噪点,模型在反向过程中学会去除噪点。
- 训练目标:目的是最大限度地减少每一步预测噪点与实际噪点之间的差异,优化证据下限(ELBO)的一种形式。
- 稳定性和稳健性:与GAN相比,它们具有更好的稳定性,可避免模式崩溃等问题,从而持续生成多样化的高质量输出。
9.3 扩散模型的进步(2020年至今)
- 去噪扩散概率模型(DDPM)(2020):完善扩散过程,为图像合成设定新基准。
- 去噪扩散隐式模型(DDIM)(2021):通过非马尔可夫采样提高效率,使生成过程更加灵活。
- 基于分数的随机微分方程生成模型(2021):利用随机微分方程高效生成样本。
- 潜在扩散模型(2022年):成为流行的文本到图像生成系统(如稳定扩散)的基础,极大地推动了人工智能生成图像领域的发展,并为更易用、更高效的人工智能生成工具铺平了道路。
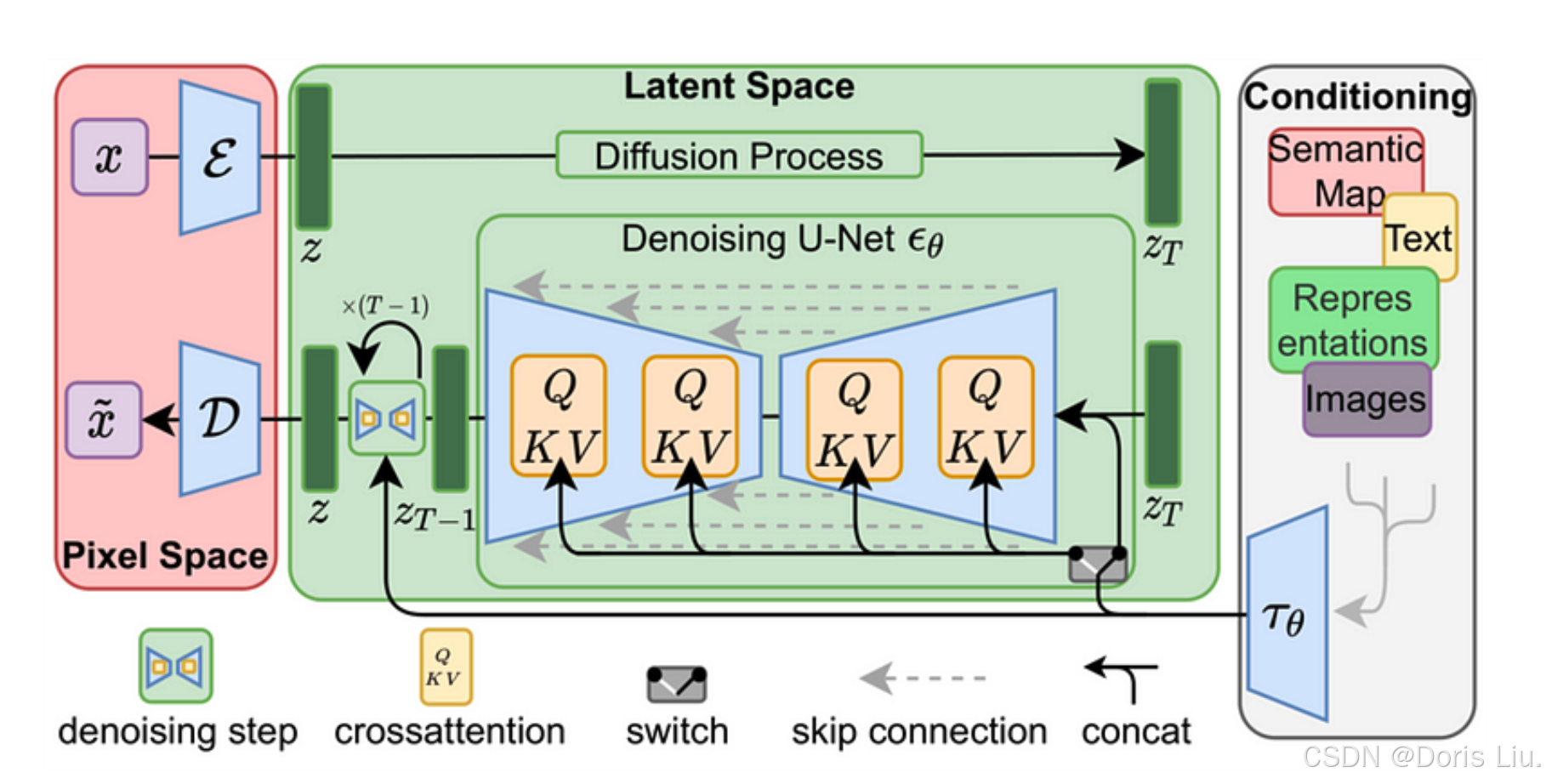
9.4 应用
- 文本到图像的生成:DALL-E3和Stable Diffusion3等模型在根据文字描述生成高质量图像方面表现出色,其中DALL-E3提供了详细而准确的视觉效果,而Stable Diffusion则提供了一个开放源代码的替代方案,使图像生成技术的使用更加民主化。

- FLUX.1(2024):黑森林实验室(Black Forest Lab)推出了用于人工智能图像生成的高级扩散模型FLUX.1,该模型具有速度快、质量高和适应性强等特点。FLUX.1有三个版本(Schnell、Dev和Pro),利用整流Transformer等创新技术生成高度逼真的图像。FLUX.1可以生成文本并处理手指和脚趾等细节,这是一款优秀图像生成器所需的一切功能。

由FLUX.1 Shenell模型生成的图像,其简单内容为“一个侧面写有FLUX.1字样的咖啡杯”。咖啡杯的高质量图像,上面的文字“FLUX.1”清晰可见,展示了FLUX.1生成文字的能力
- DreamBooth(2022):可在特定对象的少量图像上训练扩散模型,从而生成个性化图像。
- LoRA(2022):该技术允许使用最少的附加参数对扩散模型进行微调,从而使模型更容易适应特定任务或数据集。

单一概念生成的定性比较。左栏显示了每个概念的参考图像。基于LoRA的方法在保真度方面优于自定义扩散。此外,“正交适配”和“SBoRA”的性能与“混合展示”不相上下,同时还引入了正交约束,在多概念场景中更具优势。
- ControlNet(2023):在草图或深度图等附加输入上为扩散模型设定条件,从而对生成的图像提供更多控制。

带有姿态控制的ControlNet稳定扩散
- Multi-SBoRA(2024):Multi-SBoRA是一种为多个概念定制扩散模型的新方法。它使用正交标准基向量构建用于微调的低秩矩阵,允许区域性和非重叠权重更新,从而减少跨概念干扰。这种方法保留了预训练模型的知识,减少了计算开销,提高了模型的灵活性。实验结果表明,Multi-SBoRA在保持独立性和减少串扰效应的同时,实现了多概念定制的最佳性能。
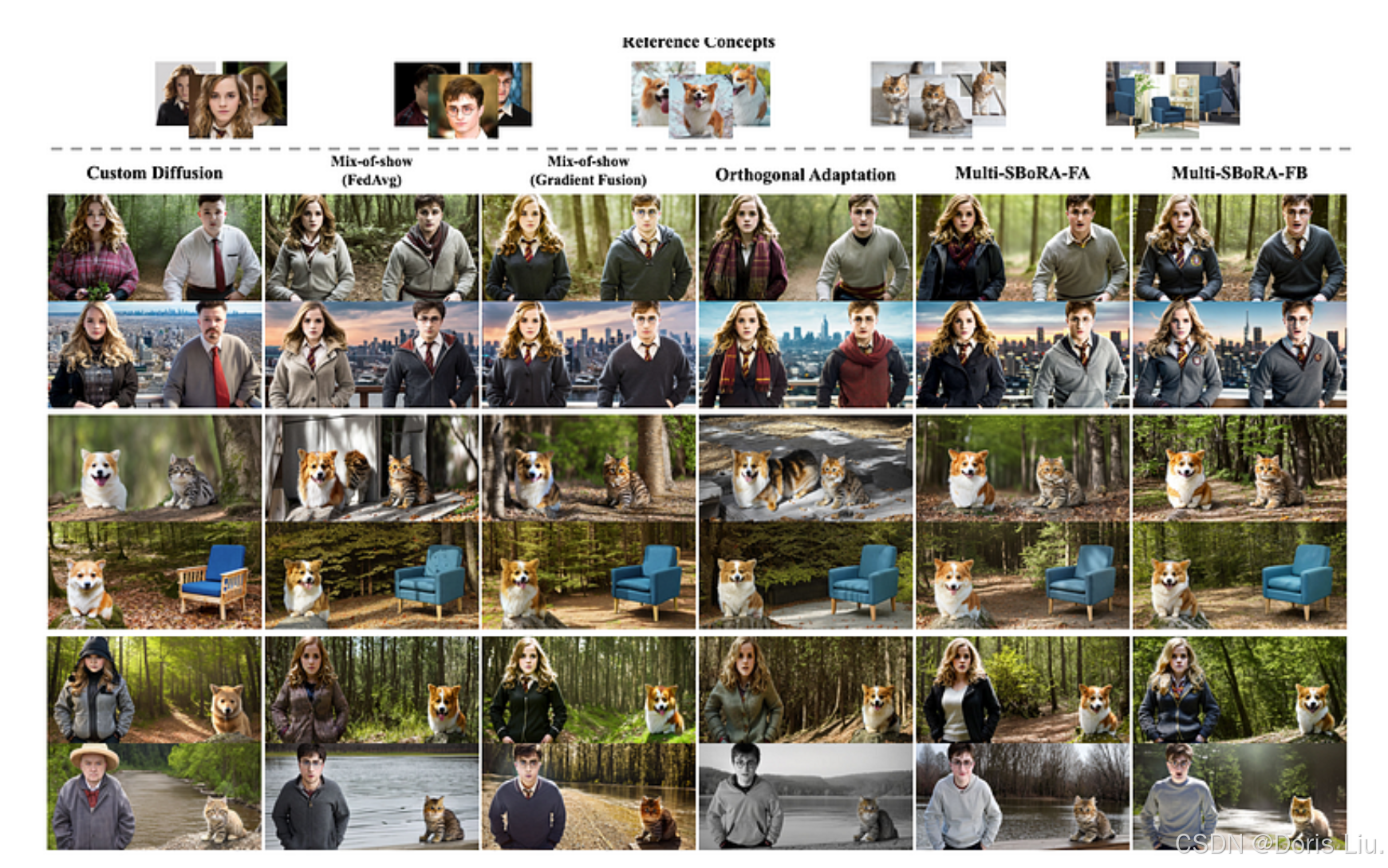
多概念生成的定性比较。结果分为三种情况:(1)字符生成,(2)物体生成,(3)字符和物体组合生成。最上面一行显示了每个概念的参考图像。缺乏正交设计的方法(如自定义扩散和混合显示)会明显丢失概念特征,尤其是在具有复杂面部特征的角色中。正交适配法能更好地保留特征,但可能会损害模型的整体知识,导致模型崩溃。相比之下,我们提出的方法效果更佳,既能有效保留每个概念的特征,又能确保更稳定的生成。
扩散模型研究的发展轨迹预示着一个充满希望的未来,即在优化速度和质量的同时,结合各种人工智能架构优势的集成模型将大有可为。
10.总结
人工智能和深度学习的历史以重大进展和变革性创新为标志。从早期的神经网络到卷积神经网络(CNNs)、循环神经网络(RNNs)、Transformer和扩散模型等复杂架构,该领域已经在各个领域掀起了一场革命。
最近的进步促成了大型语言模型(LLM)和大型多模态模型(LMM)的发展,如OpenAI的GPT-4o、谷歌的Gemini Pro、Antropic的Claude3.5Sonnet和Meta的LLaMA3.1,这些模型展示了令人印象深刻的自然语言和多模态能力。此外,生成式人工智能(包括文本到图像和文本到视频生成模型,如Midjourney、DALL-E3、Stable Diffusion、FLUX.1和Sora)也取得了突破性进展,拓展了人工智能的创造潜力。
扩散模型也已成为功能强大的生成模型,并有多种应用。随着研究继续集中于开发更高效、可解释和有能力的模型,人工智能和深度学习对社会和技术的影响只会越来越大。这些进步正在推动传统领域的创新,并为创造性表达、问题解决和人机协作创造新的可能性。
作者:LM Po 翻译:Doris 转载请注明。


















 2424
2424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











