






python网络爬虫这学期才开设的课程,我觉得越接触就觉得越是很神奇,曾经的我没想到我会接触到这样的课程。因为我高中是学习文科的,对政史这样的文字学科比较感兴趣,高中我是知道编程的,但仅仅只是知道,也不深入了解,就只是在看电视的时候会觉得编程语言好酷,没想到大学的我居然误打误撞选了编程的一门相关专业。
可能未来的我不会从事这门专业,但是依然不妨碍我对它的喜欢,它让我觉得计算机很神奇,很有趣,并且具有一定的挑战性,既然我接触到了它,那我希望我可以尽自己的所能获取一定的编程知识。
python抓取图片主要是动态网页的图片,这需要用到python的相关第三方库,如requests等,在抓取某东西时,一定要注意抓包(XHR),获取真实的URL,下面是我的课下实践,主要是图片的抓取。
import requests
import time
import pprint
url=("https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8539253244283893905&ipn=rj&ct=201326592&is"
"=&fp=result&fr=ala&word=%E8%8D%89%E5%8E%9F%E5%9B%BE%E7%89%87&queryWord=%E8%8D%89%E5%8E%9F%E5%9B%BE%E7%89%87&cl="
"2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc"
"=&expermode=&nojc=&isAsync=&pn=30&rn=30&gsm=1e&1717159589930=")
headers={
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari"
}
response=requests.get(url,headers=headers)
response.encoding='utf-8'
datas=response.json()
#pprint.pprint(datas)
count=0 #count=1
for picture in datas['data']:
title=picture.get('fromPageTitleEnc')
cover=picture.get('middleURL') #Invalid argument:无效参数
cover_response=requests.get(cover,headers=headers)
with open (f"D:\\python数据采集\\python爬虫\\图片爬取\\百度图片\\{count}.{title}.jpg","wb") as f:
f.write(cover_response.content)
count += 1
time.sleep(2)
print(f"第{count}张图片下载成功")上述代码是我的课下实践,让我们来运行一下:
 可以看到图片在正常下载,接下来让我们看看保存在文件夹中的图片:
可以看到图片在正常下载,接下来让我们看看保存在文件夹中的图片:
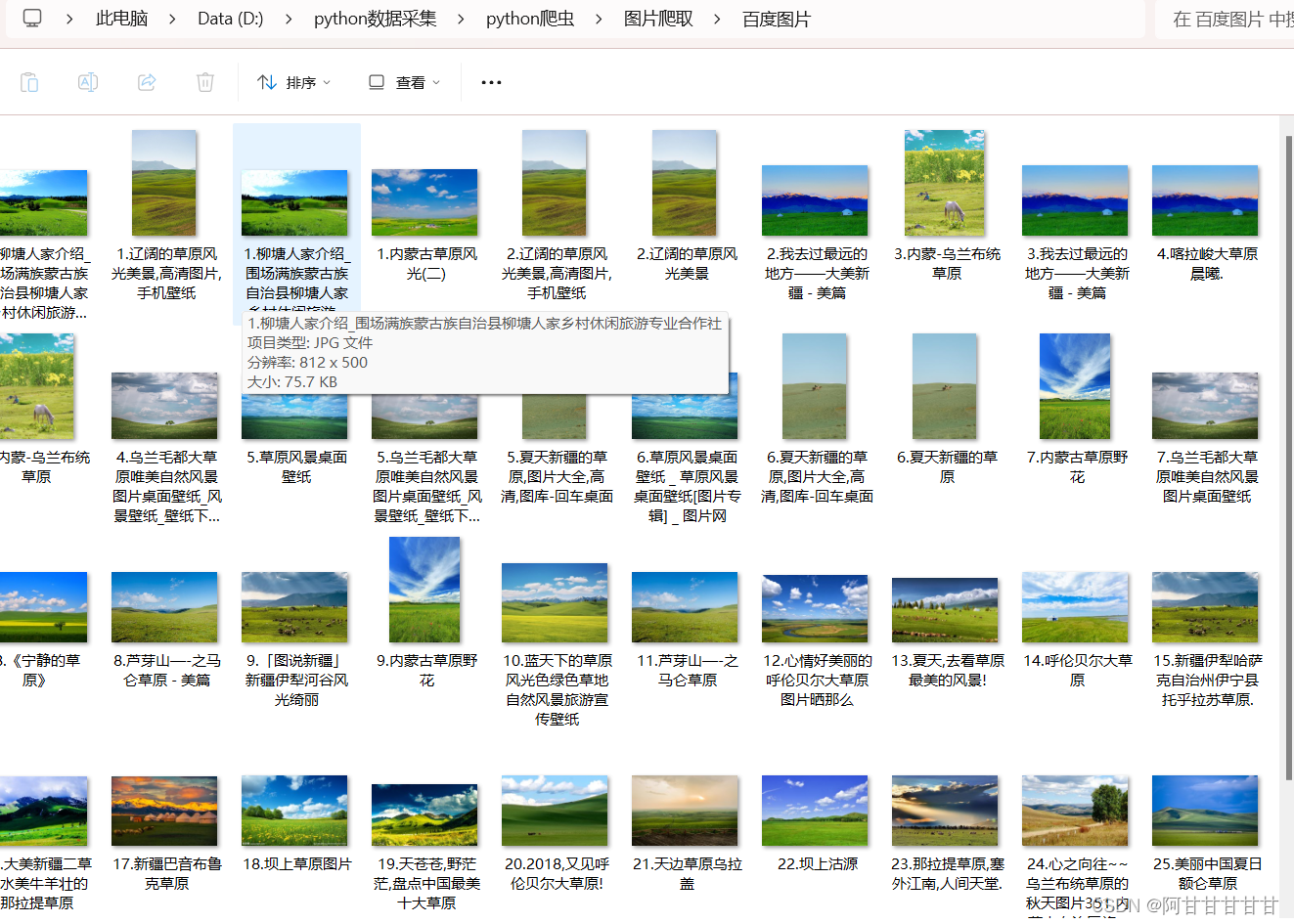 这样我们的图片就成功保存在我们的文件夹中了。
这样我们的图片就成功保存在我们的文件夹中了。
上面的代码我没有加入排错程序,为了程序的有效运行,我们也可以把它加上,看如下代码:
import requests
import pprint
import time
url="https://spa5.scrape.center/api/book/?limit=18&offset=0"
headers={
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari"
}
response=requests.get(url,headers=headers)
response.encoding="utf-8"
data=response.json()
count=1
print(f"该页一共有{len(data['results'])}张图片")
print("开始下载图片")
for item in data['results']:
title=item.get('name')
cover=item.get('cover')
print(f"第{count}张图片的链接为:",cover)
try:
cover_response=requests.get(cover,headers=headers) #重点语句,相当于一个转换
except:
print(f"连接超时,第{count}张图片下载失败")
countiue
else:
if cover_response.status_code == 200:
#with open(f"D:\\python数据采集\\python爬虫\\scrape图片\\{count}.{title}.jpg","wb") as f:
#写法一,,有“f”才会把图片逐一地保存下来,没有“f”图片会持续的跳转,并且图片命名就只是{count).{title}
with open(f"./scrape_pic/{count}.{title}.jpg","wb")as f:
#写法二 注意:必须在当前目录下创建一个文件,即“scrape_pic”
#有“f”才会把图片逐一地保存下来,没有“f”图片会持续的跳转, 并且图片命名就只是{count).{title}
f.write(cover_response.content)
print(f"第{count}张图片下载成功")
count += 1
else:
print(f"第{count}张图片下载失败,错误代码:{cover_response.status_code}")
time.sleep(2)
print("下载完成")这个代码就更完整一点,并且我写了相应的注释,方便我这样的小白能够看懂读懂反复记忆。
导入的pprint库是让json格式的文件打印出来格式化,方便看懂的,上边代码没用到,但也没影响。
导入的time库是设置延缓时间,让图片下载有个缓冲时间。
路过的大神如果发现有什么错误的话请多多指教。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









