






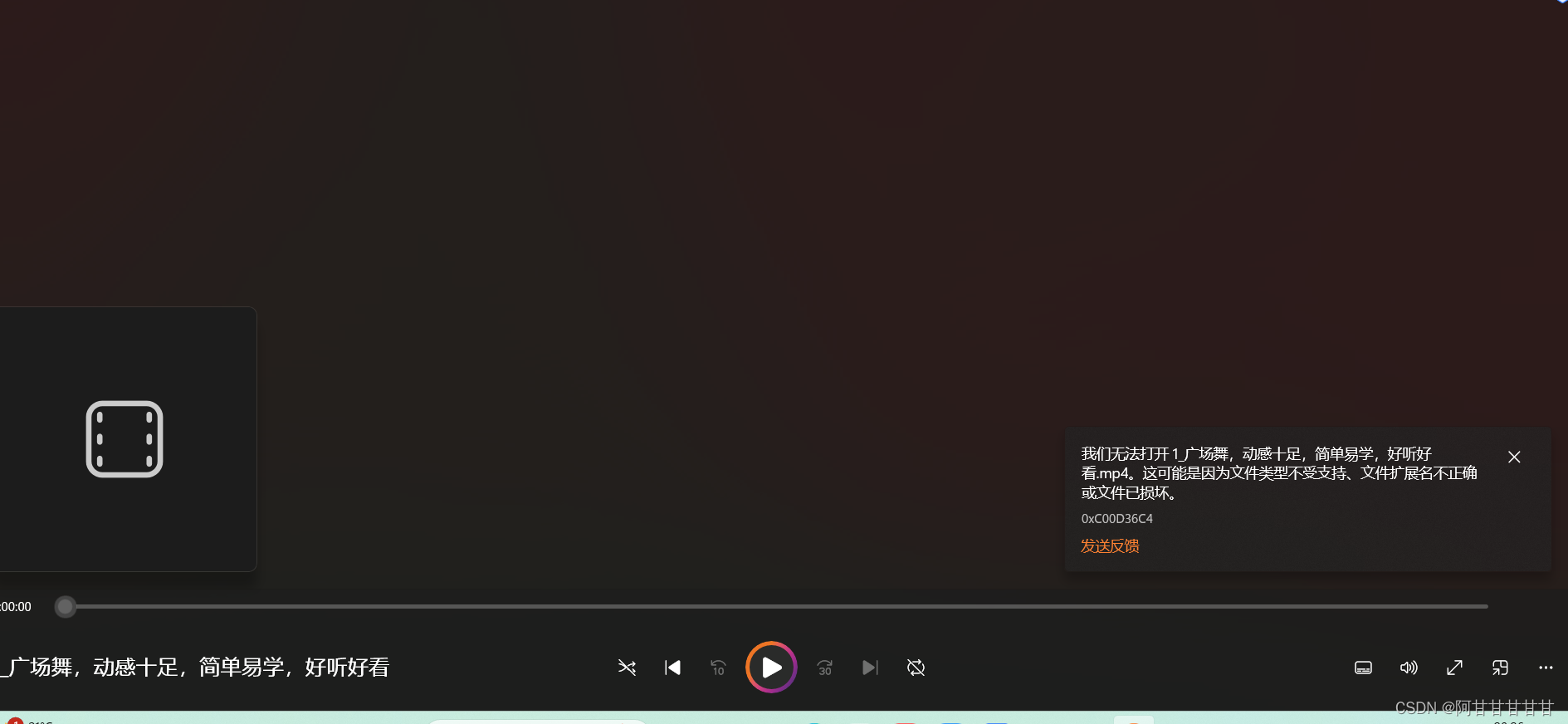
朋友们,最近在学习python网络爬虫,就只是很浅的一点,所以总是遇到很多问题。我昨天试着抓取百度上的广场舞视频,程序代码都可以正常运行,视频文件也下载下来了,可是就是打不开这些视频文件,这是为什么呢?路过的大神们指点指点小白吧。。。
import requests
import time
import pprint
url=("https://tv.360kan.com/v1/recomm/list?q=%E5%B9%BF%E5%9C%BA%E8%88%9E%E8%A7%86%E9%A2%91&from=so_video_result_"
"like&start=0&count=30&psid=264b04aa6d69c8c66119367993f9baef")
headers={
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari"
}
response=requests.get(url,headers=headers)
response.encoding='utf-8'
datas=response.json()
#data=datas['data']
#pprint.pprint(datas)
count=1
for item in datas['data']['result']:
#for _item_ in data['result']:
title = item.get('title')
_title_=title.replace('/',"-")+".mp4"
# try:
# title=_item_.get('title')
# vedio = _item_.get('video_urlpc')
# except AttributeError:
# print("期待为字典,实际是{}".format(type(item)))
vedio = item.get('video_urlpc')
vedio_response=requests.get(vedio,headers=headers)
with open (f"D:\\python数据采集\\python爬虫\\图片爬取\\视频\\{count}_{_title_}","wb") as f:
f.write(vedio_response.content)
count += 1
time.sleep(2)
print("下载成功")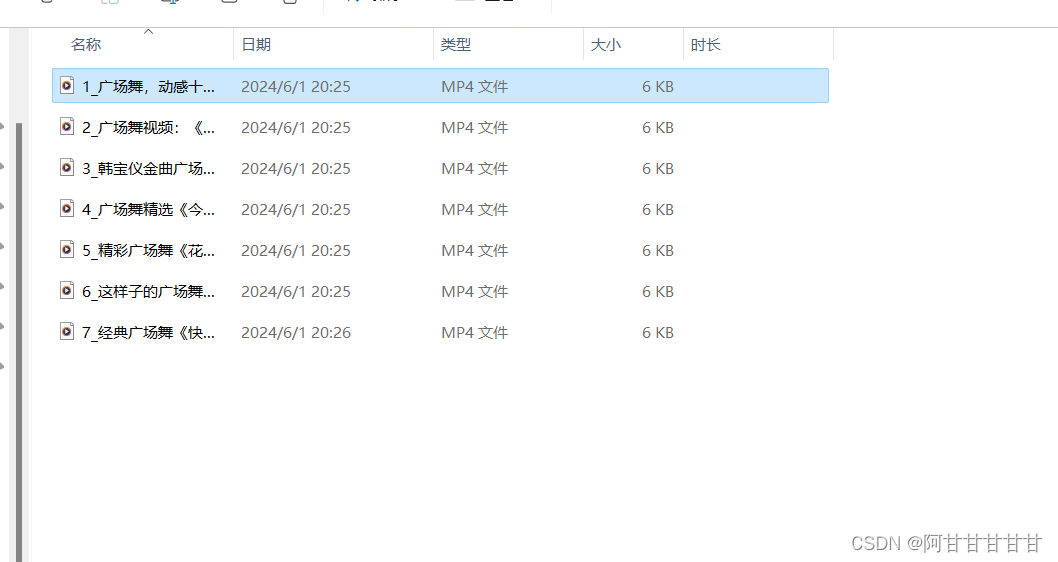















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









