







论文阅读CVPR2021 RLNAS-Neural Architecture Search with Random Labels
目录
CVPR2021 RLNAS-Neural Architecture Search with Random Labels
3.2 文中方法:Random Label NAS(RLNAS)
4.1. Search Space and Training Setting

基于随机标签的NAS
零:摘要
文章研究了一种新的神经结构搜索范式——随机标签搜索。(这一任务听起来很不直观,因为随机标签很少提供关于每个候选体系结构性能的信息)文章提出了一种新的基于易收敛假设的NAS,它在搜索过程中只需要随机标签。该算法包括两个步骤:首先,使用随机标签训练一个超网;其次,从超网络中提取权重在训练过程中变化最大的子网。在多个数据集(如NASBench-201和ImageNet)和多个搜索空间(如DARTS-like和MobileNet-like)上评估大量实验。实现了相当甚至更好的结果,尽管对手使用完整的基础事实标签进行搜索。作者希望的发现能够激发对NAS本质的新理解。
一:介绍
大多数现有的网络连接存储框架可以概括为嵌套的双层优化,公式如下:

Score( )是指在验证集上评估的性能指标,NAS旨在搜索获得最佳验证性能的体系结构,作者在下文中将它命名为performance-based NAS,NAS倾向于选择具有快速收敛的网络,这也意味着具有快速收敛和高性能的架构之间可能存在高度相关性(简称为易收敛假设:ease-of-convergence hypothesis for short),受此启发作者提出了convergence-based NAS,公式如下:

其中convergence( )是衡量收敛速度的某个指标。作者首先研究标签在两个框架(基于性能的NAS和基于易收敛性的NAS)中的作用,在基于性能NAS中,可行的标签在两个搜索步骤中都很关键,对于公式(1)(2)都需要Labels。然而在基于性能的NAS中,公式(3)不需要labels,因为不需要得到精确度模型,只需要一个衡量收敛的速度的东西,只有公式(4)需要。因此,得出结论,在基于收敛性的NAS中,标签要求比基于性能的NAS弱得多。基于此,作者提出了(RLNAS),只需要随机标签进行搜索。在公式(4)中采用随机标签优化每个采样架构a的权重,在公式(3)中引入定制的角度度量[21]来测量训练和初始化的权重之间的距离,其估计相应架构的收敛速度。为了加快搜索过程,RLNAS进一步利用One-Shot NAS来优化公式(3)和公式(4)。
分成两步流水线:首先训练一个带有随机标签的超网络,然后使用进化搜索从超网络中提取收敛速度最快的子网络,尽管RLNAS没有使用任何可行的标签,但它在多个基准上的性能仍然与许多有监督/无监督的方法相当甚至更好。
作者认为RLNAS的潜力可能包括:
(1)简单但更强的基线。与广泛使用的随机搜索[24]基线相比,RLNAS强大得多,可以为未来的NAS算法提供更严格的验证。
(2)潜在的更好的泛化能力。由于RLNAS仅使用随机标签进行搜索,因此对于搜索到的架构,它不太可能偏向某个数据集,这在实验中也得到支持。
(3)启发对NAS的新认识。由于RLNAS的性能和许多有监督的NAS框架一样好,一方面进一步验证了易收敛假设的有效性。另一方面,它表明,特定任务上的NAS或GT标签对当前的NAS算法没有多大帮助,这意味着现有NAS方法找到的体系结构可能仍然是次优的。
二:相关工作
目前NAS分为Supervised Neural Architecture Search和Unsupervised Neural Architecture Search。由于角度的不可微性,作者遵循One-Shot NAS机制来研究基于收敛的NAS。UnNAS表明,在没有基础事实标签的情况下,权重共享NAS仍然可以工作,但很难得出标签完全没有必要的结论。本文中介绍的随机标签与以前的完全不同监督信息,帮助彻底消除标签对NAS的影响。作者直接用角度度量来搜索架构。
三:方法
如引言中所述,为了利用单镜头NAS的机制,首先简要回顾一下单路径单镜头(SPOS) [19]作为预备。在SPOS框架的基础上,提出了随机标签网络连接存储方法。
3.1 基础:SPOS
SPOS是一次性方法之一,它将网络连接存储优化问题分解为两个连续的步骤:首先训练超级网络,然后搜索体系结构。与其他一次性方法不同,SPOS通过随机训练超网进一步分离候选体系结构的权重。具体来说,SPOS将超网中的候选架构视为单个路径,并在每次迭代中统一激活单个路径来优化相应的权重。因此,超网训练步骤可以表示为:
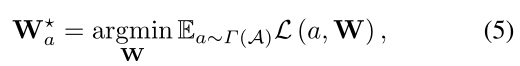
其中,L()表示在具有GT标签的训练数据集上优化的目标函数,γ(A)是∈ A的均匀分布。在超网训练到收敛后,SPOS执行体系结构搜索,如下所示:
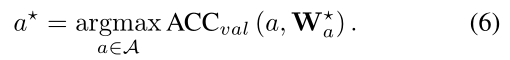
通过初始化种群,SPOS进行交叉和变异以生成新的候选架构,并使用验证精度作为适应度来保持候选架构具有最高性能。如此反复,直到进化算法收敛到最优架构。
3.2 文中方法:Random Label NAS(RLNAS)
随机标签NAS(RLNAS)两个解耦优化步骤的结合,由单路径和进化搜索组成的超网络结构使SPOS简单但灵活。遵循SPOS机制,解耦基于收敛的优化公式(3)和(4)分为以下两步。首先,使用随机标签训练超级网络:
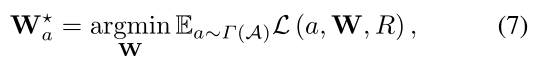
其中R代表随机标签;其他符号遵循与公式(5)中相同的定义。其次,以基于收敛的度量convergence( )为适应度的进化算法从超网中搜索最优架构:

3.2.1介绍生成随机标签的机制,3.2.2介绍并使用基于角度的度量作为convergence( )估计模型收敛速度。
3.2.1 Random Labels Mechanism
在表征学习领域,深度神经网络(DNNs)具有用部分随机标签拟合数据集的能力[45]。此外,[31]试图理解当在具有完全随机标签的自然图像上训练时,dnn学习什么,并且实验证明在完全随机标签上的预训练可以在特定条件下加速下游任务的训练。对于NAS领域,虽然在搜索阶段追求的是最优的模型架构而不是模型表示,但是模型表示仍然涉及到模型评估阶段。然而,神经架构搜索能否在随机标签设置中工作仍是一个未决问题。鉴于此,作者尝试研究随机标签对NAS优化问题的影响。首先介绍生成随机标签的机制。具体而言,随机标签服从离散均匀分布,离散变量的数量默认等于数据集的图像类别(其他可能的方法在第节4.3中讨论。在数据预处理过程中对不同图像对应的随机标签进行采样,这些图像标签对在整个模型优化过程中不会发生变化。
3.2.2 Angle-based Model Evaluation Metric
最近,[36]发现通过NAS算法搜索的体系结构共享相同的快速收敛模式。以此规则为突破口,作者尝试设计模型评估模型融合视角下的度量。[6]首先用基于角度的度量来测量独立训练模型的收敛性。该度量被定义为初始模型wights和训练模型之间的角度。ABS [21]将这一指标引入NAS社区,并使用它逐步缩小搜索空间。与ABS不同,关注带有随机标签的优化问题,并采用基于角度的度量来直接搜索架构,而不是缩小搜索空间。在扩展角度以指导架构搜索之前,首先回顾ABS [21]中的角度度量。
Review Angle Metric in ABS。超网表示为一个有向无环图,表示为A(O,E),其中O是特征节点集,E是两个特征节点之间的连接集(每个连接被实例化为一个替代操作)。ABS用唯一的输入节点Oin和唯一的输出节点Oout定义了A(O,E)。候选体系结构是从超级网络中采样的,它被表示为a(O,E~)。候选架构的特征节点O与SuperNet相同,但子集edges E~ ∈ E。ABS使用一个权重向量V (a,W)来表示一个模型,并通过连接从Oin到 Oout开始的所有路径的权重来构造V (a,W)。权重为W0的初始化候选体系结构和权重为Wt的训练好的体系结构之间的距离为:
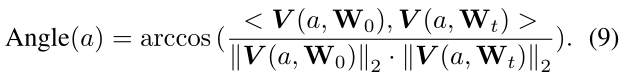
Extensive Representation of Weight Vector(权重向量的扩展表示)。如上所述,ABS定义了只有一个输入节点和一个输出节点的超网络。然而,对于一些搜索空间,它们由具有多个输入节点和输出节点的单元结构组成。例如,DARTS中的每个单元都有两个输入节点,每个单元的输出节点由所有中间节点的输出通过级联组成,这促使作者将所有中间节点视为架构拓扑识别的输出节点。一般来说,通过连接来自Oin to Oout的所有路径的权重来重新定义权重向量V (a,W)。
参数化非加权运算(Parameterize Non-weight Operations.)。为了解决具有相同可学习权重的候选体系结构之间的冲突,ABS参数化非权重操作(“池化”、“跳层连接”和“无”)。‘池化’运算(平均池化’和‘最大池化’都是)赋有维数为[O,C,K,K]的固定张量(O和C分别代表输出通道和输入通道,K是内核大小),所有元素都是1/K^2。与ABS用空向量赋值“跳层连接”不同,作者提出了一种替代的参数化方法,将维数为[0,C,1,1]的单位张量赋给“跳层连接”操作。作者针对不同的搜索空间调整参数化方法,例如,空权重和单位张量分别分配给NAS-Bench-201和DARTS或MobileNet类搜索空间中的“跳层连接”。差异的原因可能与搜索空间的复杂性有关。“无”操作不需要被参数化为ABS,它确定了组成权重向量V的路径的数量。如果路径中有“无”,则该路径中操作的权重将不会涉及角度计算。
四:实验
4.1. Search Space and Training Setting
作者在三个现有的流行搜索空间上分析和评估RLNAS:NAS-Bench-201[15],DARTS [30]和MobileNet类搜索空间[5]。
4.2. Searching Results

五:结论
RLNAS在两个下游任务和各种搜索空间中具有很强的泛化能力,没有花哨的功能。
六:附录

















 683
683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









