









前引:在C++编程中,异常处理是构建健壮、可维护代码的核心技术。它允许开发者优雅地处理运行时错误,避免程序崩溃,提升软件可靠性。本文将以C++异常机制为核心,系统讲解异常的基本概念、抛出与捕获语法(包括
try、catch和throw关键字的使用),以及常见陷阱和最佳实践。同时,为了强化实战能力,文章还将融入C++ STL中map容器的精选习题,帮助读者在数据存储和检索场景中巩固异常处理技巧。通过理论与实践的结合,您将掌握高效、安全的C++编程之道!
目录
【一】异常处理介绍
C++ 的异常处理机制是一种用于处理程序运行时错误的强大工具,它通过 分离错误检测与错误处理 来提升代码的可读性和健壮性。以下将从核心语法、工作机制、最佳实践到常见误区,全面解析 C++ 异常处理!
【二】异常处理的三大关键字
C++ 异常处理的核心由三个关键字构成:try、throw、catch
C++的处理异常由这三个组成,下面我们来分别介绍一下它们的使用!
【三】try 的理解
try 你可以理解为划分出现异常处理的区域
例如:
try { //监测目标 }
try块包裹可能抛出异常的代码
【四】throw 的理解
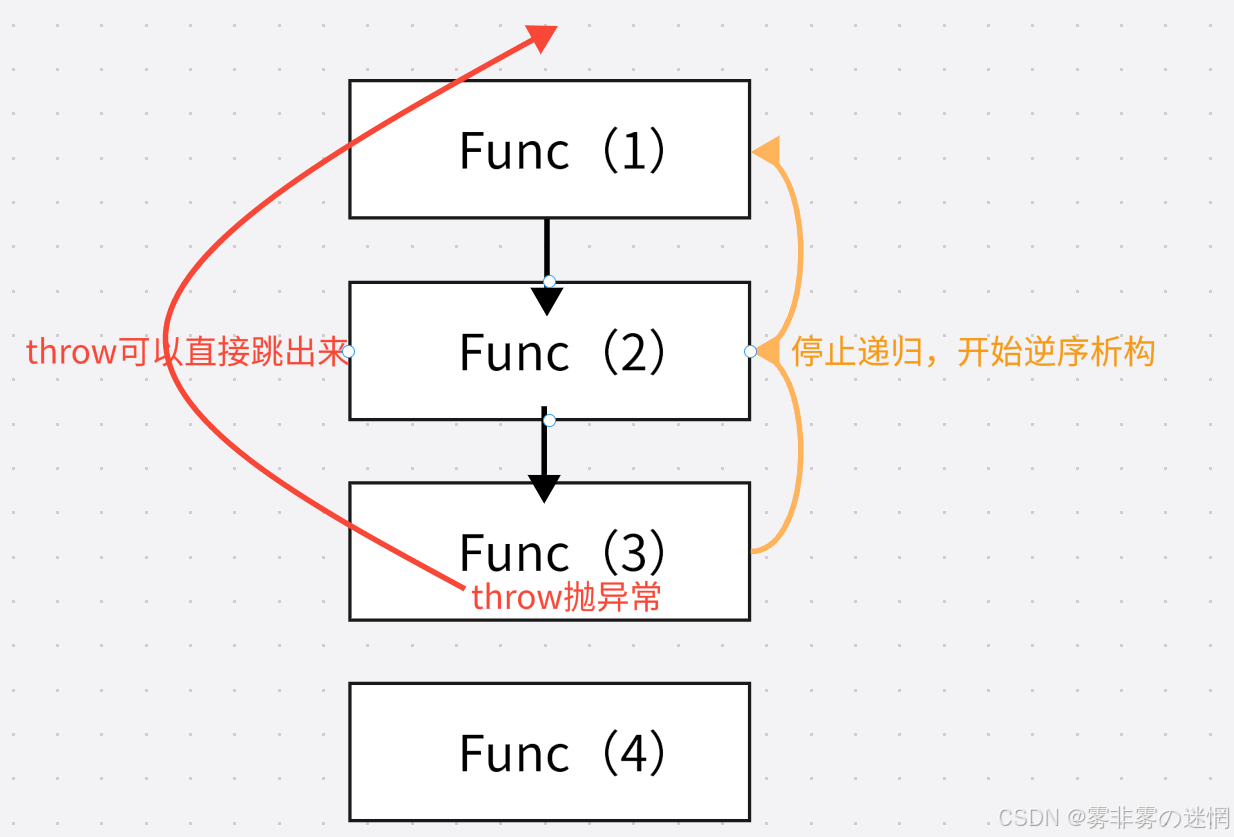
throw 用来抛异常,当抛异常时,当前函数的执行流程立即终止,局部对象按逆序析构(栈展开)然后控制权跳转到最近的能匹配该异常类型的
catch块,例如递归时抛异常:
【五】catch 的理解
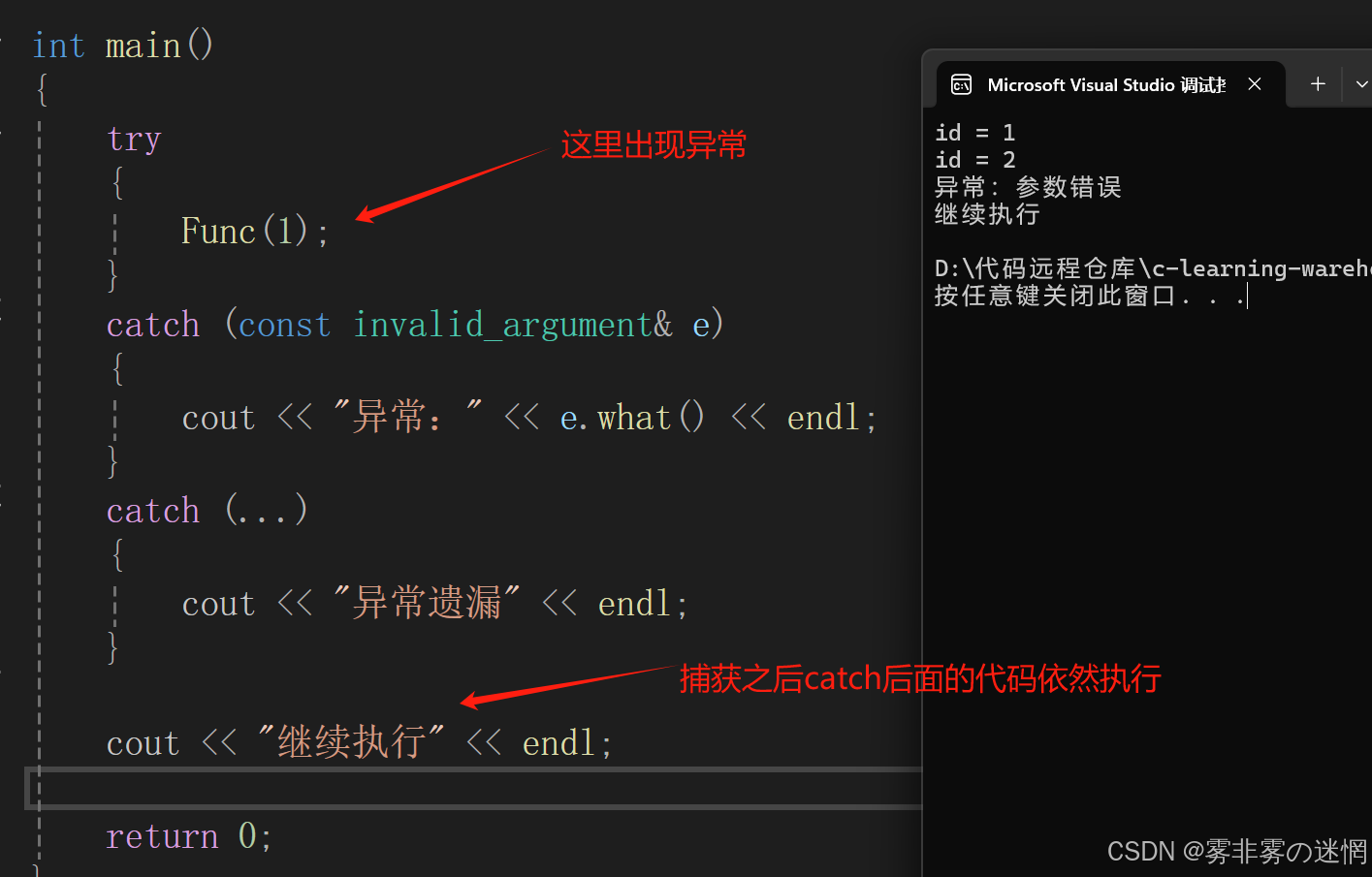
catch块用于捕获并处理特定类型、自定义类型的异常,即接收抛出的异常通常搭配(如what()方法返回错误描述)若块内无异常抛出,
catch块会被跳过;若有异常抛出,则立即跳转到对应的catch块依然会执行catch后面的代码。异常如果被捕获,程序会跳到catch后面继续执行,否则会报错
【七】noexcept
C++11 引入
noexcept关键字,用于声明函数不会抛出异常,语法有两种:void func() noexcept; // 函数承诺不抛出异常 void func() noexcept(true); // 等价于noexcept void func() noexcept(false); // 显式允许抛出异常(可省略)
- 作用:
- 编译器可针对
noexcept函数优化(如减少异常处理的额外开销)- 若
noexcept函数抛出异常,程序会直接调用std::terminate()终止(避免未定义行为)- 最佳实践:对于明确不会抛出异常的函数,应声明为
noexcept,提升代码可信度
【八】异常处理的灵活使用
(1)标准类型抛异常
throw如果是想抛标准库异常类(定义在<stdexcept>头文件中)
类名 含义 std::exception所有标准异常的基类(纯虚类) std::runtime_error运行时错误(如文件不存在) std::invalid_argument参数无效(如非法输入) std::out_of_range越界访问(如数组越界) std::bad_alloc内存分配失败( new抛出)
现在我来写一个完整的标准异常处理,来为大家进行讲解:
void Func(int id)
{
if (id == 3)
{
//如果满足条件,就抛异常
throw invalid_argument("参数错误");
}
cout << "id = " << id << endl;
Func(id + 1);
}
int main()
{
try
{
//包裹检测目标
Func(1);
}
catch (const invalid_argument& e)
{
//catch反馈
cout << "异常:" << e.what() << endl;
}
return 0;
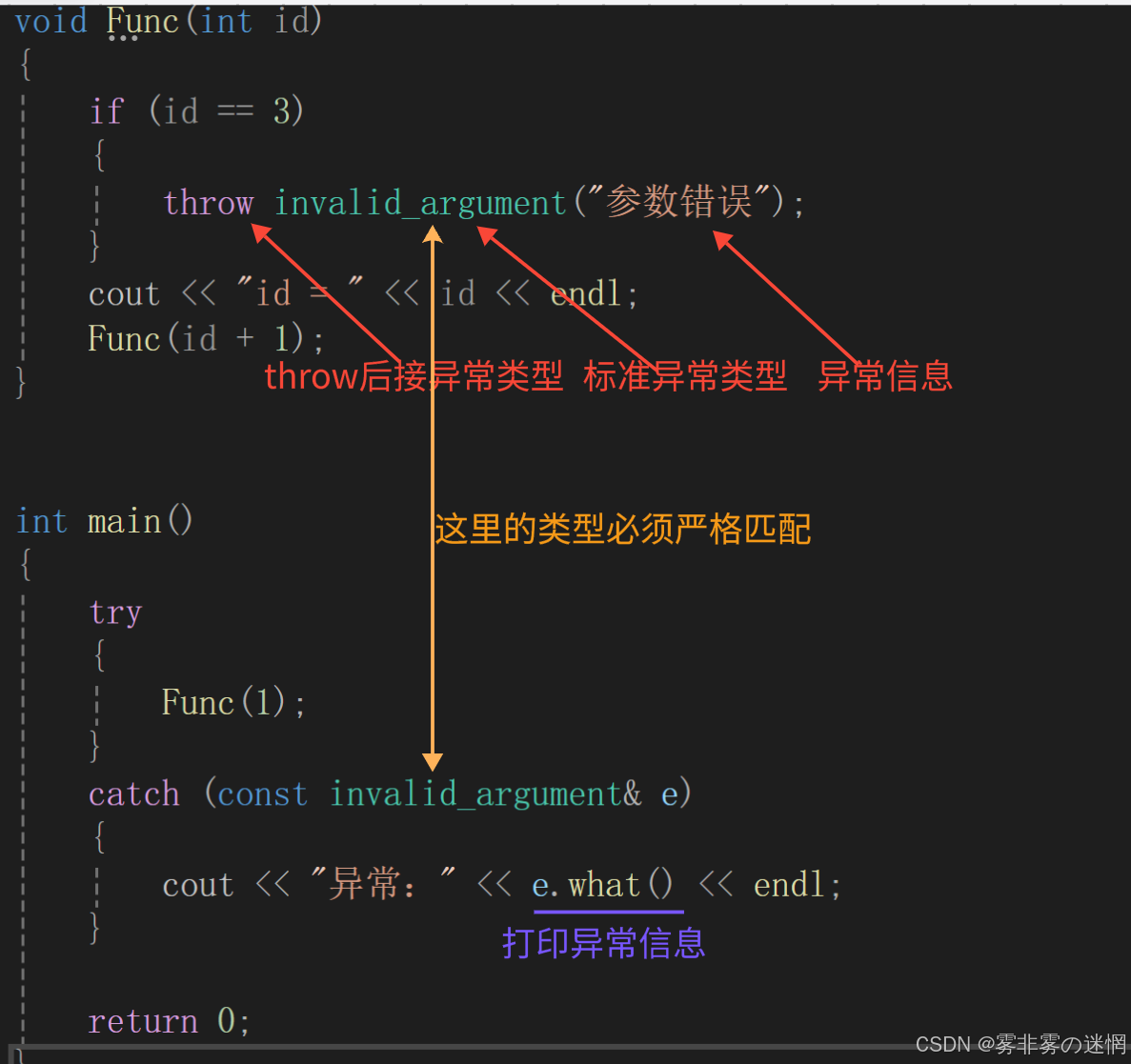
}注意:
(1)异常类型与catch声明的类型必须严格匹配,
exception作为所有标准异常的基类,可 以匹配任意标准异常(2)在catch定义中,我们可以调用 what()来反馈“异常信息”
(2)自定义类型抛异常
自定义异常通常由自己决定异常类型
下面我来写一个完整的自定义异常处理,进行讲解:
class stack_t :public exception
{
public:
//构造
stack_t(const string message_ = "")
:message(message_)
{ }
void push_back(int date) const
{
if (node == nullptr)
{
throw stack_t("空指针");
}
}
//what函数的实现:返回throw异常的信息
const char* what() const noexcept override
{
return message.c_str();
}
private:
string message;
stack_t* node = nullptr;
};
int main()
{
stack_t V;
// 捕获自定义异常
try
{
V.push_back(1);
}
catch (const stack_t& e)
{
std::cout << "捕获到自定义异常:" << e.what() << std::endl;
}
return 0;
}下面我们来解释一下原理:
(1)通过自定义对象内部的构造函数来完成string的存储
(2)内部实现what函数返回存储的字符串

【七】异常处理的建议
(1)异常的捕获最好是搭配 what()来使用,可以快速定位抛出异常的位置

(2)catch 块建议使用 const &,这样可以避免拷贝带来的开销和支持多态

(3)建议来一个万能的catch兜底:catc(...),防止抛出的异常遗漏导致报错

(4)抛异常和catch声明的类型必须严格匹配
【八】前K个高频单词
(1)题目链接

https://leetcode.cn/problems/top-k-frequent-words![]() https://leetcode.cn/problems/top-k-frequent-words
https://leetcode.cn/problems/top-k-frequent-words
(2)原理讲解

大意:即给你一个存储string的vector,这里面的单词可能重复,返回前 k 个重复的单词(单词按字典序排序),那么我们的步骤应该是:先确定每个单词出现的个数,再涉及到排序
统计次数:
我们直接将数据全部导入到 map 容器用来统计次数:上一篇有学过 map 的operator【】是可以插入数据,并返回这个数据的 value 的
map<string, int> V1; //导入数据进map并统计 for (const auto& e : words) { V1[e]++; }
排序:
此时我们统计出了每个单词的出现次数,但是 map 不能拿到随机排序
所以我们再创建一个 vector 用来排序:先按照出现次数排,如果单词次数相同按照字典序排
注意:如果直接使用 sort 是按照字典序排的,所以我们需要使用仿函数指定排序
//仿函数 struct dict { bool operator()(pair<string, int> p1, pair<string, int> p2) { //先按second次数排序或者等于的情况下按照字典序排序 return p1.second == p2.second ? p1.first<p2.first : p1.second>p2.second; } };//放数据到vector排序 vector<pair<string, int>> V2(V1.begin(), V1.end()); sort(V2.begin(), V2.end(), dict());
提取:
此时我们完成了单词的全部排序,现在我们提取前 k 个元素返回即可
//取vector的前 k 个元素返回 vector<string> V3; for (int i = 0; i < k; i++) { V3.push_back(V2[i].first); } return V3;
(3)代码展示
//仿函数 struct dict { bool operator()(pair<string, int> p1, pair<string, int> p2) { //先按second次数排序或者等于的情况下按照字典序排序 return p1.second == p2.second ? p1.first<p2.first : p1.second>p2.second; } }; class Solution { public: vector<string> topKFrequent(vector<string>& words, int k) { map<string, int> V1; //导入数据进map并统计 for (const auto& e : words) { V1[e]++; } //放数据到vector排序 vector<pair<string, int>> V2(V1.begin(), V1.end()); sort(V2.begin(), V2.end(), dict()); //取vector的前 k 个元素返回 vector<string> V3; for (int i = 0; i < k; i++) { V3.push_back(V2[i].first); } return V3; } };


















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









