







本节将以一个实例讲解MapReduce开发。主要涉及点为二次排序、Partition。
1. 例子介绍
1.1 输入数据
① 假设有一个网站,有三个不同的页面,分为web1、web2、web3。
② 有三个用户(jones、lee、oscar)访问了其中几个页面。
③ 记录了三个用户访问页面的时间。
初始数据如下:
| name | time | info |
|---|---|---|
| jones | 100 | web1 |
| lee | 60 | web3 |
| lee | 20 | web1 |
| oscar | 120 | web1 |
| jones | 900 | web1 |
| lee | 60 | web2 |
| jones | 30 | web3 |
| oscar | 500 | web2 |
| oscar | 30 | web3 |
第一列为用户名,第二列为访问时间,第三列为访问的页面。列与列之间用tab(即\t)间隔。
2.2 输出数据
可以发现,数据与数据之间是散乱排布的。所以我们做以下的处理:
① 按照姓名分类。将姓名相同的分为一组。
② 将分好组的数据内部排序。即相同姓名的数据按照访问时间降序排序。
③ 不同姓名的组按照字典序进行排序。
所以输出数据如下所示:
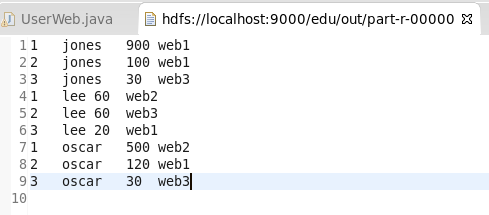
| Num | name | time | info |
|---|---|---|---|
| 1 | jones | 900 | web1 |
| 2 | jones | 100 | web1 |
| 3 | jones | 30 | web3 |
| 1 | lee | 60 | web2 |
| 2 | lee | 60 | web3 |
| 3 | lee | 20 | web1 |
| 1 | oscar | 500 | web2 |
| 2 | oscar | 120 | web1 |
| 3 | oscar | 30 | web3 |
第一列是将同一姓名排序的序列。
第二列是姓名。
第三列是访问不同网页的时间(不同组内降序排列)。
第四列为访问的网页。
2. 代码实现
2.1 项目准备
① 创建Map/Reduce porject。这里项目名为mapreduce2,包名为com.jkb.mapreduce,类名为UserWeb。
② 复制hadoop配置文件到src目录下。
cd $HADDOP_HOME
cd etc/hadoop
cp core-site.xml hdfs-site.xml log4j.properties ~/workspace/mapreduce2/src 2.2 Map类实现
public static WebMap extends Mapper<Object, Text, Text, Text> {
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 对输入的数据进行切分
String[] line = value.toString[].split("\t");
if (line.length == 3) {
String name = line[0]; // 姓名
String time = line[1]; // 停留时间
String infor = line[2]; // 访问网站
/*
这里将输出两部分:
① name + time
② time + infor
*/
context.write(new Text(name + "\t" + time), new Text(time + "\t" + infor));
}
}
}2.3 定制Partitioner
在MapReduce程序中,Partitioner决定Map节点的输出将被分区到哪个Reduce节点。MaPReduce提供的默认的Partitioner是HashPartitioner,它根据每条数据记录的主键值进行Hash操作,获得一个非负整数的Hash码,然后用当前作业的Reduce节点数(分区数)进行取模运算,以此决定该记录将分区到哪个Reduce节点。当Hash函数足够理想时,所有的记录将能被均匀地分区到各个Reduce节点上,并且保证具有同一个主键地记录将被分区到同一个Reduce节点上。
public static class Partition extends Partitioner<Text, Text> {
@Override
public int getPartition(Text key, Text value, int number) {
String name = key.toString().split("\t")[0];
int hash = name.hashCode();
return Math.abs(hash % number);
}
}2.4 WritableComparator类实现
①排序
public static class Sort extends WritableComparator {
protected Sort() {
super(Text.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
Text h1 = new Text(((Text) w1).toString().split("\t")[0]);
Text h2 = new Text(((Text) w2).toString().split("\t")[0]);
IntWritable M1 = new IntWritable(Integer.valueOf(((Text) w1).toString().split("\t")[1]));
IntWritable M2 = new IntWritable(Integer.valueOf(((Text) w2).toString().split("\t")[1]));
// 二次排序
int R;
if (h1.equals(h2)) {
R = M2.compareTo(M1);
} else {
R = h1.compareTo(h2);
}
return R;
}
}② 分组
public static class Group extends WritableComparator {
protected Group() {
super(Text.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
Text h1 = new Text(((Text) w1).toString().split("\t")[0]);
Text h2 = new Text(((Text) w2).toString().split("\t")[0]);
int R;
if (h1.equals(h2)) {
R = 0;
} else {
R = h1.compareTo(h2);
}
return R;
}
}2.5 Reduce实现
public static class WebReduce extends Reducer<Text, Text, IntWritable, Text> {
@Override
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int count = 0;
String name = key.toString().split("\t")[0];
for (Text t : values) {
count++;
StringBuffer buffer = new StringBuffer();
buffer.append(name);
buffer.append("\t");
buffer.append(t.toString());
context.write(new IntWritable(count), new Text(buffer.toString()));
}
}
}2.6 启动job实现
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (args.length != 4) {
System.out.println("error");
System.exit(0);
}
int SplitMB = Integer.valueOf(args[2]);
String dst = args[0];
String out = args[1];
Configuration conf = new Configuration();
conf.set("mapreduce.input.fileinputformat.split.maxsize", String.valueOf(SplitMB * 1024 * 1024));
conf.set("mapred.min.split.size", String.valueOf(SplitMB * 1024 * 1024));
conf.set("mapreduce.input.fileinputformat.split.minsize.per.node", String.valueOf(SplitMB * 1024 * 1024));
conf.set("mapreduce.input.fileinputformat.split.minsize.per.rack", String.valueOf(SplitMB * 1024 * 1024));
// 删除目录
Path outputPath = new Path(out);
outputPath.getFileSystem(conf).delete(outputPath, true);
Job job = new Job(conf);
FileInputFormat.addInputPath(job, new Path(dst));
FileOutputFormat.setOutputPath(job, new Path(out));
job.setNumReduceTasks(Integer.valueOf(args[3]));
job.setPartitionerClass(Partition.class);
job.setGroupingComparatorClass(Group.class);
job.setSortComparatorClass(Sort.class);
job.setMapperClass(WebMap.class);
job.setReducerClass(WebReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
job.setJarByClass(UserWeb.class);
job.waitForCompletion(true);
}2.7 完整代码
package com.jkb.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class UserWeb {
public static class WebMap extends Mapper<Object, Text, Text, Text> {
@Override
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
// 切分
String[] line = value.toString().split("\t");
if (line.length == 3) {
String name = line[0]; // 姓名
String time = line[1]; // 停留时间
String infor = line[2]; // 信息
context.write(new Text(name + "\t" + time), new Text(time
+ "\t" + infor));
}
}
}
public static class Partition extends Partitioner<Text, Text> {
@Override
public int getPartition(Text key, Text value, int number) {
String name = key.toString().split("\t")[0];
int hash = name.hashCode();
return Math.abs(hash % number);
}
}
// 可以序列化
public static class Sort extends WritableComparator {
protected Sort() {
super(Text.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
Text h1 = new Text(((Text) w1).toString().split("\t")[0]);
Text h2 = new Text(((Text) w2).toString().split("\t")[0]);
IntWritable M1 = new IntWritable(Integer.valueOf(((Text) w1)
.toString().split("\t")[1]));
IntWritable M2 = new IntWritable(Integer.valueOf(((Text) w2)
.toString().split("\t")[1]));
// 二次排序
int R;
if (h1.equals(h2)) {
R = M2.compareTo(M1);
} else {
R = h1.compareTo(h2);
}
return R;
}
}
public static class Group extends WritableComparator {
protected Group() {
super(Text.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
Text h1 = new Text(((Text) w1).toString().split("\t")[0]);
Text h2 = new Text(((Text) w2).toString().split("\t")[0]);
int R;
if (h1.equals(h2)) {
R = 0;
} else {
R = h1.compareTo(h2);
}
return R;
}
}
public static class WebReduce extends
Reducer<Text, Text, IntWritable, Text> {
@Override
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
int count = 0;
String name = key.toString().split("\t")[0];
for (Text t : values) {
count++;
StringBuffer buffer = new StringBuffer();
buffer.append(name);
buffer.append("\t");
buffer.append(t.toString());
context.write(new IntWritable(count),
new Text(buffer.toString()));
}
}
}
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
if (args.length != 4) {
System.out.println("error");
System.exit(0);
}
int SplitMB = Integer.valueOf(args[2]);
String dst = args[0];
String out = args[1];
Configuration conf = new Configuration();
conf.set("mapreduce.input.fileinputformat.split.maxsize",
String.valueOf(SplitMB * 1024 * 1024));
conf.set("mapred.min.split.size", String.valueOf(SplitMB * 1024 * 1024));
conf.set("mapreduce.input.fileinputformat.split.minsize.per.node",
String.valueOf(SplitMB * 1024 * 1024));
conf.set("mapreduce.input.fileinputformat.split.minsize.per.rack",
String.valueOf(SplitMB * 1024 * 1024));
// 删除目录
Path outputPath = new Path(out);
outputPath.getFileSystem(conf).delete(outputPath, true);
Job job = new Job(conf);
FileInputFormat.addInputPath(job, new Path(dst));
FileOutputFormat.setOutputPath(job, new Path(out));
job.setNumReduceTasks(Integer.valueOf(args[3]));
job.setPartitionerClass(Partition.class);
job.setGroupingComparatorClass(Group.class);
job.setSortComparatorClass(Sort.class);
job.setMapperClass(WebMap.class);
job.setReducerClass(WebReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
job.setJarByClass(UserWeb.class);
job.waitForCompletion(true);
}
}
3. 运行项目
首先构造数据上传到HDFS /edu/mr2。
这里可以导出包,使用hadoop jar 包名.类名 导出包名 /edu/mr2 /edu/out 128 1运行。
也可以直接使用Eclipse运行。
结果如下所示:
4. 总结
本节开始涉及MapReduce进阶使用,难度有所提升。
参考资料
网易云课堂微专业 大数据工程师















 4001
4001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









