







 本文详细介绍了Hadoop2.0中HDFS HA(High Availability)的原理,包括HDFS1.0的单点故障问题,HDFS HA的解决方法,如Active和Standby Namenode的主备切换,以及基于JournalNode的共享存储系统。还讨论了Zookeeper在主备切换中的角色和Namenode的健康监测机制。
本文详细介绍了Hadoop2.0中HDFS HA(High Availability)的原理,包括HDFS1.0的单点故障问题,HDFS HA的解决方法,如Active和Standby Namenode的主备切换,以及基于JournalNode的共享存储系统。还讨论了Zookeeper在主备切换中的角色和Namenode的健康监测机制。
本节主要介绍了HDFS HA(High Availability)的原理、主备切换过程以及基于JournalNode的共享存储系统。
1. 前言
在当初介绍Hadoop2.0时,我们简单提到了Hadoop框架中MapReduce的不足与改进。(即设计了新的资源管理框架YARN)。
那么,Hadoop2.0针对HDFS在Hadoop1.0的存在的问题如何改进了呢?
HDFS在Hadoop1.0中主要存在以下两个问题:
① 单一名称节点,所以可能产生单点失效问题。
② 单一名称节点,所以无法实现资源隔离。
所以针对HDFS以上两个问题,Hadoop2.0进行以下改进:
① 设计了HDFS HA,提供名称节点热备机制。
② 设计了HDFS Federation,管理多个命名空间。
本节主要对HDFS HA进行介绍。
2. HDFS HA(Availability)
2.1 HDFS1.0 组件及其功能回顾
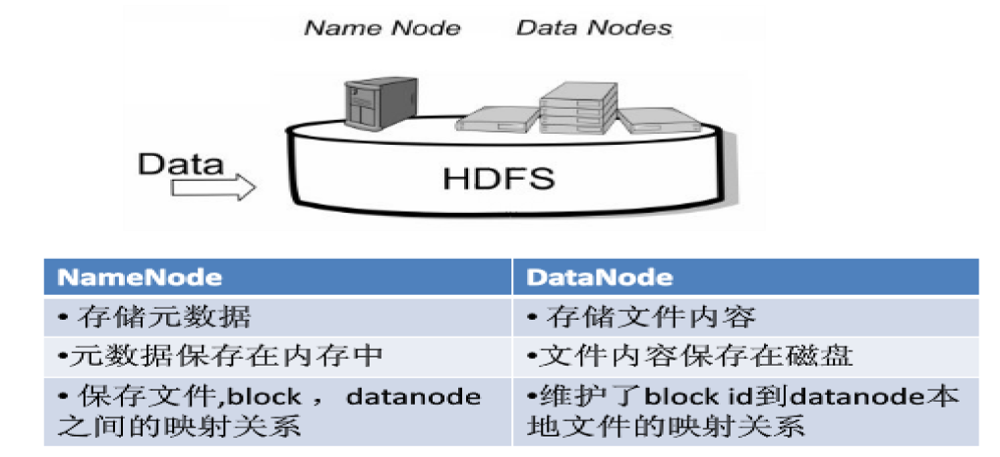
① Namenode
- 名称节点
namenode负责管理分布式文件系统的命名空间namespace,保存了两个核心的数据结构:FsImage和EditLog。
- FsImage用于维护文件系统树以及文件树中所有文件和文件夹的元数据。
- 操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作。
- 名称节点记录了每个文件中各个块所在的数据节点中的位置信息。
② Datanode
- 数据节点
datanode是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送所存储的块的列表。 - 每个数据节点中的数据都会被保存在各自节点的本地Liunx文件系统中。
两者功能如下图:
2.2 HDFS 1.0 单点故障问题
HDFS运行原理如下图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 730
730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









