






前言
初学Python,下面给大家展示三个有意思的小实验
正文
用Python语言实现水藻生长的迭代法应用·水藻指数函数迭代模型
原理:迭代法是一种步步为营,逐次推进,逐步接近的现代计算机求解问题的基本形式。迭代法的核心是建立迭代关系式。
问题:假设在空池塘中放入一颗水藻,该类水藻会每周长出4颗新的水藻,问12周后,池塘中有多少颗水藻?
要求:用Python语言编程实现上述问题的求解。记录并分析实验结果。
实验过程
a.基本原理
根据已知条件,第一周有一颗水藻,每过一周,一颗水藻会长出三颗新的水藻,那么,第二周的水藻数量为
1+4=5,
也就是说第二周会有5颗水藻。
第三周的时候,这5颗水藻各自又会新长出4颗水藻,水藻的数量变为
5+4+4+4+4+4=5+20=25,
第四周的时候,水藻数量变为125颗,第五周的时候,水藻数量变为625颗……
以此类推,每过一周,水藻的数量会增长至上一周的5倍,可以用函数公式来表示水藻的增长情况:设周数为n,水藻的数量为f (n),那么,f (n)与n的关系式为
b.程序源码
x=1 #第一周池塘中有1颗水藻
for i in range(11): #迭代11次,计算第2周到第12周的水藻数量
y=4*x #每周增加的水藻数量为4
x=x+y #计算本周水藻数量
print("第12周池塘中的水藻数量为:",x)c.运行结果
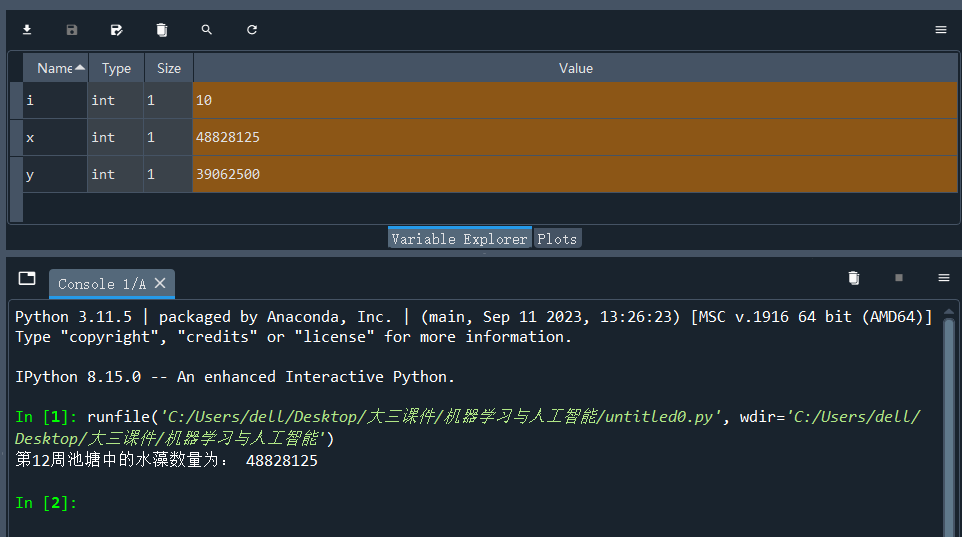
经MATLAB的命令行窗口检验,运算结果是对的。

线性回归与拟合
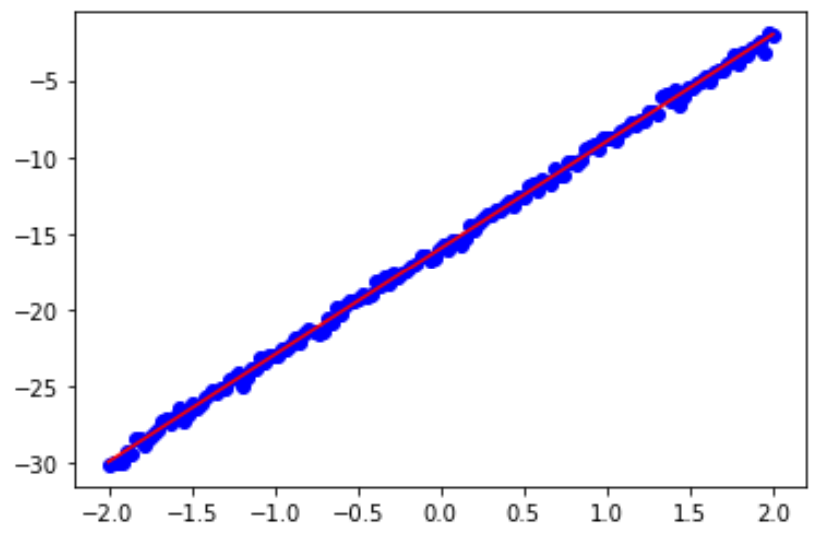
写出程序并生成图。先在x属于[-2,2]范围内任意做出350个点,其值由y=7x-16再加上一些随机噪音生成,然后画出这些点的拟合直线。
实验过程
a.基本原理
首先导入需要的库,包括random、matplotlib.pyplot和numpy。
生成x轴的数据,使用numpy的linspace函数生成-2到2之间的150个等间距的数。
生成y轴的数据,使用y=7x-16的公式生成基础数据,再加上一些随机噪音,使用numpy的randn函数生成150个随机数。
使用numpy的polyfit函数拟合一次函数,得到拟合直线的斜率和截距。
使用numpy的polyval函数根据拟合直线的斜率和截距计算出拟合直线的y值。
使用matplotlib.pyplot的scatter函数绘制散点图,使用plot函数绘制拟合直线,最后使用show函数显示图像。
b.程序源码
import random
import matplotlib.pyplot as plt
import numpy as np
#生成随机点
x=np.linspace(-2,2,150)
y=7*x-16+np.random.randn(150)*0.3
#画出散点图,用蓝色标识
colors='b'
plt.scatter(x,y,c=colors)
#拟合直线,用红色标识
z=np.polyfit(x,y,1)
p=np.poly1d(z)
plt.plot(x,p(x),"r-")
#显示图像
plt.show()c.运行结果
这里运行5次。
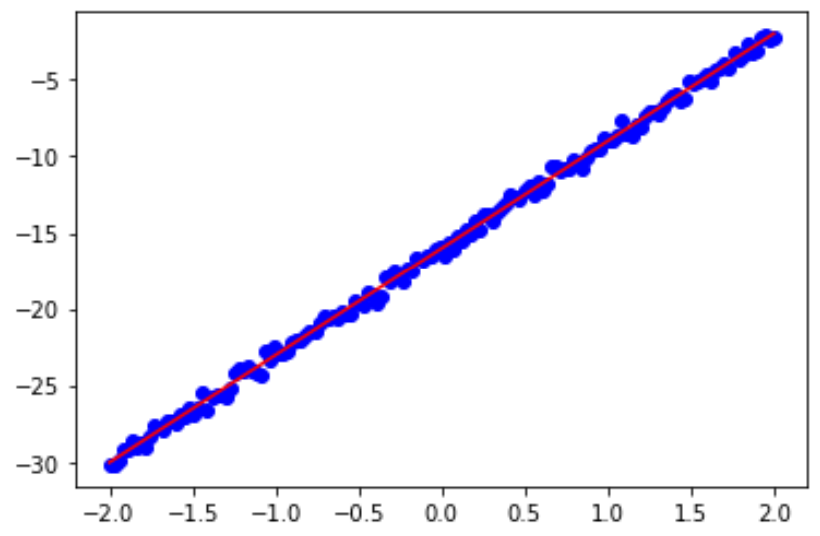
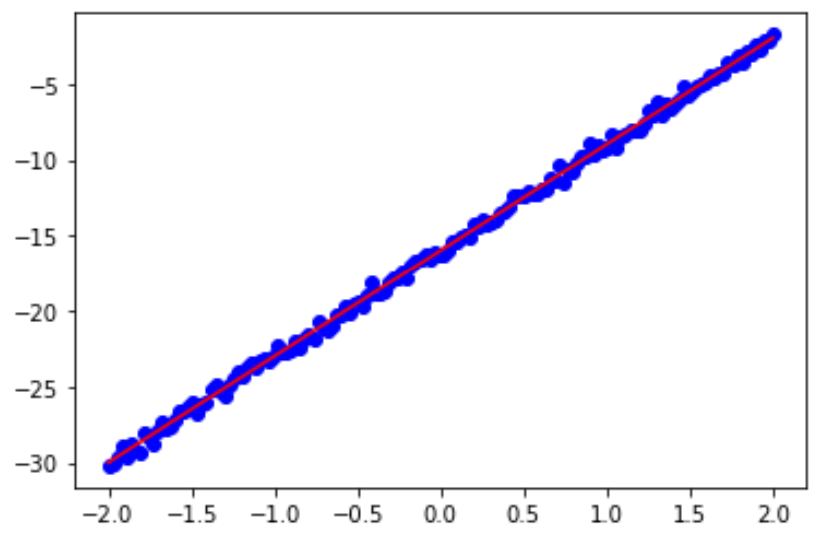
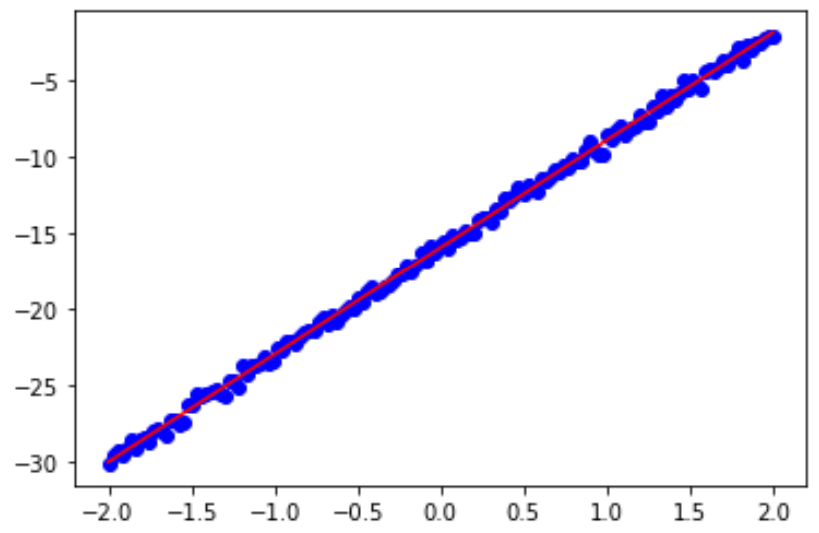

鸢尾花数据集
鸢尾花数据集iris.csv是一个著名的统计学数据集,被机器学习研究者大量使用。它包含150组实例,4种生物特征和每组实例对应的鸢尾花种类(setosa,versicolor,virginica)。试对其进行分类,并给出分类结果(分类模型不限)。
实验过程
a.基本原理
要使用Python对鸢尾花数据集进行分类,首先需要导入必要的库,然后加载数据,拆分数据集,训练模型,并测试模型。在这项任务中,可以使用scikit-learn库中的决策树分类器作为示例。
b.程序源码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
#加载数据
iris=load_iris()
X=iris.data
y=iris.target
#拆分数据集为训练集和测试集
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=42)
#创建决策树分类器并训练
clf=DecisionTreeClassifier()
clf.fit(X_train,y_train)
#在测试集上进行预测
y_pred=clf.predict(X_test)
#计算并打印分类精度
accuracy=accuracy_score(y_test,y_pred)
print(f"Accuracy:{accuracy}")c.运行结果

结语
计算机是大脑的延伸,程序语言的发展没有止境,它会越来越高级智慧化,接近人的自然语言。
Python,此即智慧之殿堂
















 5460
5460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











