







在网络爬虫之Requests库详解文章中,我们可以很方便的获取网页内容即网页源代码,但通常我们所需要的只是里面的部分数据,这时就需要对网页内容进行解析,从而提取出有意义的数据。比较常见的方法有正则表达式、HTML或XML解析库等。本文我们就给大家介绍一个非常流行、实用、高效的网页解析第三方库-BeautifulSoup。
BeautifulSoup是Python的一个HTML或XML的第三方解析库,可以用它方便地从网页中提取数据。它提供一些简单的、Python式的函数来处理导航、搜索、修改分析树等功能。它是一个工具箱,利用它可以省去很多烦琐的提取工作,提高了解析效率。
(1)安装BeautifulSoup库和lxml库:pip install BeautifulSoup4 和 pip install lxml
(2)导入BeautifulSoup类:from bs4 import BeautifulSoup
(3)创建BeautifulSoup对象,传递网页内容以及解析的方法,例如:
soup = BeautifulSoup(text, "html.parser")
(4)通过soup.prettify()方法对网页内容进行格式化输出。
(5)获取网页中的标签及其内容,例如:soup.标签名、soup.标签名.string等。
BeautifulSoup类的基本元素

简单程序演示基本元素用法
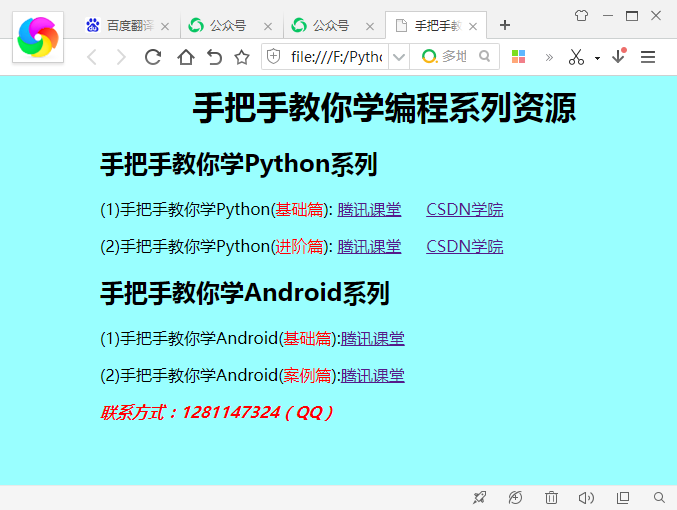
m_page.html文件内容如下:
<html>
<head>
<title>手把手教你学编程</title>
</head>
<body bgcolor="#99FFFF" style="margin-left:100px">
<h3><!-- 编辑于 2022年4月7日 --></h3>
<h1 align="center">手把手教你学编程系列资源</h1>
<h2>手把手教你学Python系列</h2>
<p>(1)手把手教你学Python(<font color="#FF0000">基础篇</font>):
<a href="https://ke.qq.com/course/1581404">腾讯课堂</a>
<a href="https://edu.csdn.net/course/detail/30784" style="margin-left:20px">CSDN学院</a></p>
<p>(2)手把手教你学Python(<font color="#FF0000">进阶篇</font>):
<a href="https://ke.qq.com/course/2026380">腾讯课堂</a>
<a href="https://edu.csdn.net/course/detail/30785" style="margin-left:20px">CSDN学院</a></p>
<h2>手把手教你学Android系列</h2>
<p>(1)手把手教你学Android(<font color="#FF0000">基础篇</font>):<a href="https://ke.qq.com/course/235882">腾讯课堂</a></p>
<p>(2)手把手教你学Android(<font color="#FF0000">案例篇</font>):<a href="https://ke.qq.com/course/235881">腾讯课堂</a></p>
<p><b><i><font color="red">联系方式:1281147324(QQ)</font></i></b></p>
</body>
</html>页面效果如下:
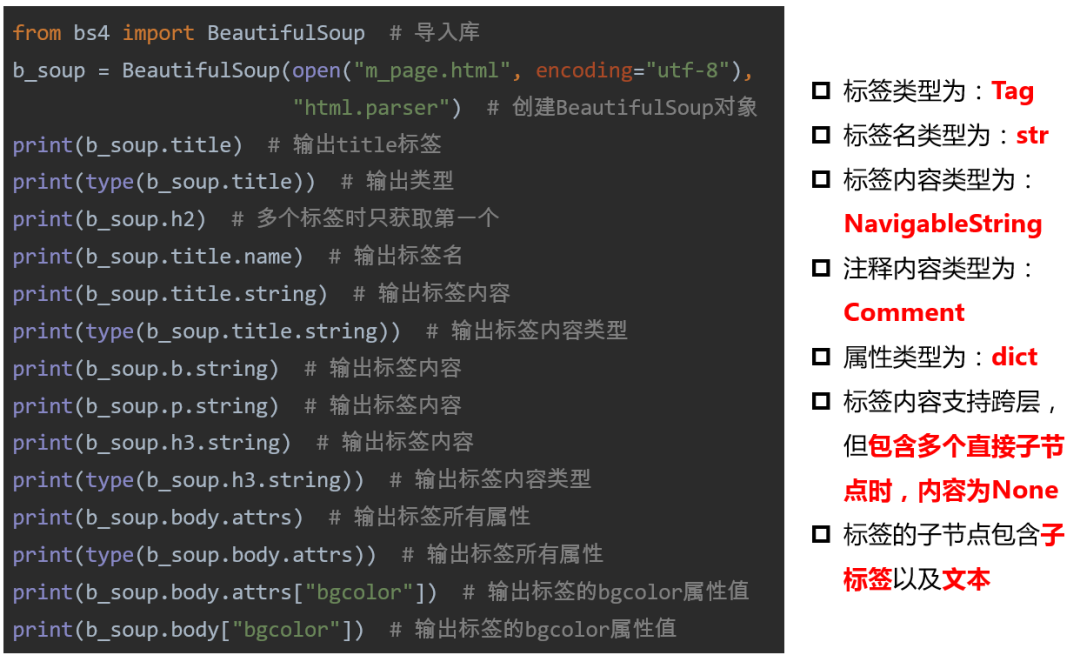
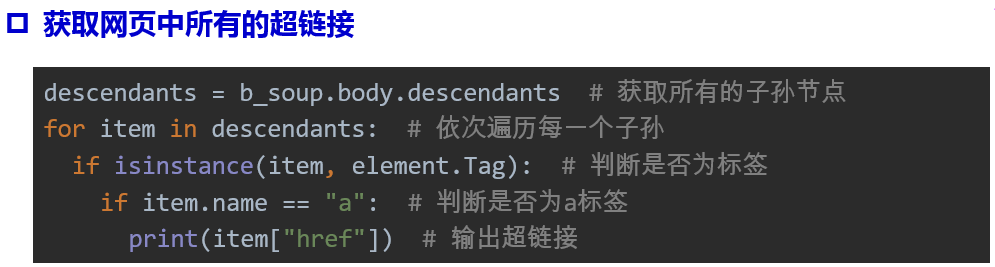
网页标签遍历的主要属性

标签树遍历示意图(m_page.html文件)
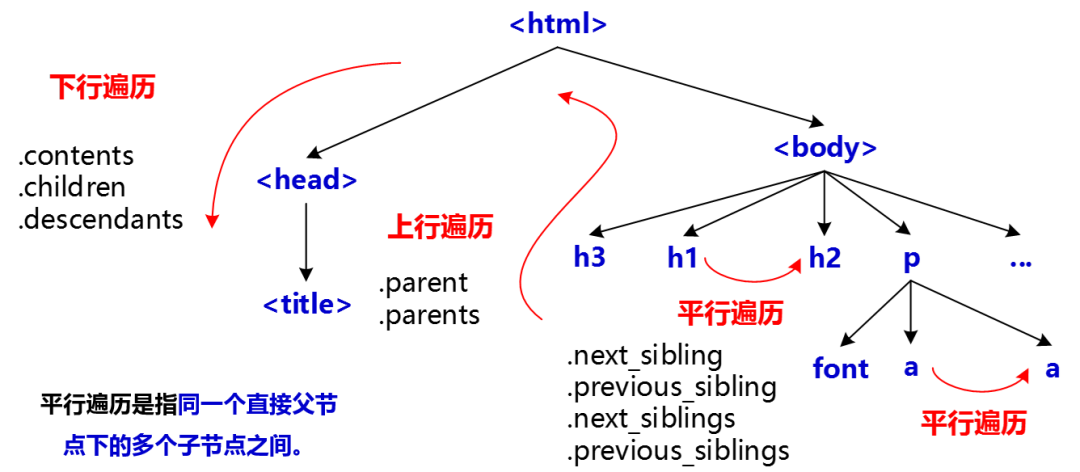
标签树遍历示例

m_test.html文件内容如下:
<html>
<head>
<title>手把手教你学编程</title>
<style>
.python{
background-color:#9DF;
padding:10;
}
.android{
background-color:#9CF;
padding:10;
}
body{
background-color:#000;
width:1000px;
margin:auto;
}
#content{
background-color:#dFF;
height:800px;
}
.title{
font-size:20px;
font-weight:bold;
color:#00F;
}
.stress{
font-weight:bold;
font-style:italic;
text-decoration:underline;
padding-left:2px;
padding-right:6px;
color:#F00;
}
a{
color:#909;
text-decoration:underline;
}
a:hover{
color:#00F;
font-size:large;
}
</style>
</head>
<body>
<div id="content">
<h1 align="center">手把手教你学编程系列资源</h1>
<div class="python">
<p class="title">手把手教你学Python系列</p>
<p>(1)手把手教你学Python(<span class="stress">基础篇</span>):
<a href="https://ke.qq.com/course/1581404">腾讯课堂</a>
<a href="https://edu.csdn.net/course/detail/30784" style="margin-left:20px">CSDN学院</a></p>
<p>(2)手把手教你学Python(<span class="stress">进阶篇</span>):
<a href="https://ke.qq.com/course/2026380">腾讯课堂</a>
<a href="https://edu.csdn.net/course/detail/30785" style="margin-left:20px">CSDN学院</a></p>
</div>
<div class="android">
<p class="title">手把手教你学Android系列</p>
<p>(1)手把手教你学Android(<span class="stress">基础篇</span>):<a href="https://ke.qq.com/course/235882">腾讯课堂</a></p>
<p>(2)手把手教你学Android(<span class="stress">案例篇</span>):<a href="https://ke.qq.com/course/235881">腾讯课堂</a></p>
<p class="stress">联系方式:1281147324(QQ)</p>
</div>
</div>
</body>
</html>页面效果如下:

想一想,尝试实现下述要求。(提示:class属性值是一个列表。)
-
输出所有包含class属性的p标签
-
输出所有class属性为“stress”的标签
-
输出class属性为“python”的div下的所有超链接
通过标签遍历虽然可以查找到每一个标签,但过程比较繁琐,效率不高。在BeautifulSoup中为我们提供了一些高效的方法可以根据条件快速查找到符合条件的标签。
标准选择器
-
find_all(name,attrs,recursive,text):查找所有符合条件的节点,name 表示标签名,attrs表示属性字典,recursive 表示是否递归查找,默认为True,text 表示查找内容,返回结果为ResultSet;
-
find()用法和findall() 一样,但返回的是第一个符合条件的内容;
-
find_parents():返回所有祖先节点;
-
find_parent():返回直接父节点;
-
find_all_next():返回节点后所有符合条件的节点;
-
find_next():返回节点后面第一个符合条件的节点;
-
find_next_siblings():返回后面的所有兄弟节点;
-
find_next_sibling():返回后面的第一个兄弟节点;
-
find_all_previous():返回节点前所有符合条件的节点;
-
find_previous():返回节点前面第一个符合条件的节点;
-
find_previous_siblings():返回前面所有兄弟节点;
-
find_previous_sibling():返回前面的第一个兄弟节点;
标 准 选 择 器 示 例

CSS 选 择 器 示 例

实战案例-获取各省份的大学信息
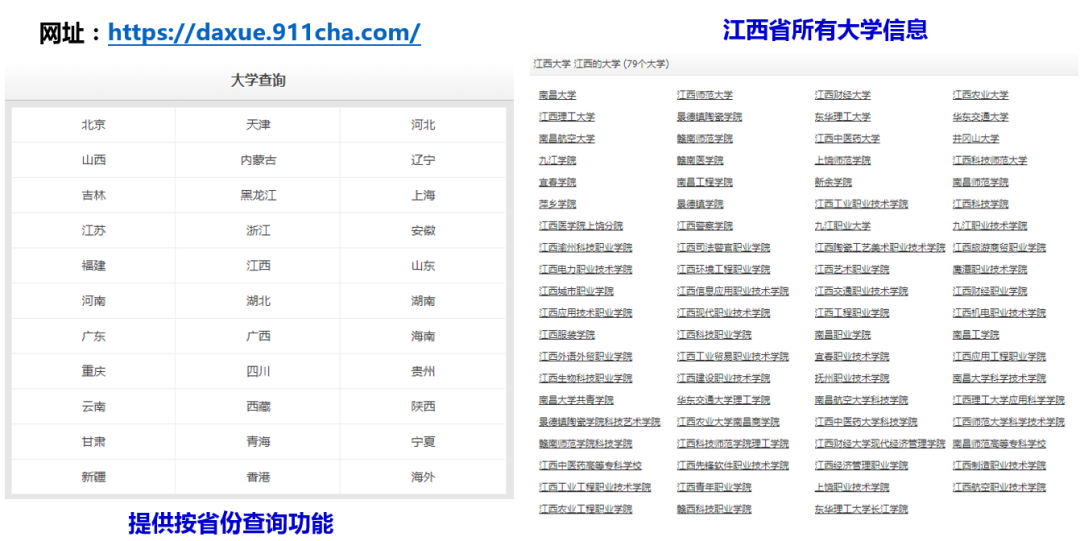
代码参考
import requests
from bs4 import BeautifulSoup
def get_text(url):
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '} # 构建请求头
res = requests.get(url, headers=headers) # 发送请求
res.encoding = res.apparent_encoding # 设置编码格式
res.raise_for_status() # 是否成功访问
return res.text # 返回网页源代码
except Exception as e:
print(e) # 抛出异常, 打印异常信息
def parse_province(text): # 解析网页获取省份及其链接
b_soup = BeautifulSoup(text, "html.parser") # 构建BeautifulSoup对象
ul_tag = b_soup.find(class_="txt3 center") # 找到ul标签
a_tags = ul_tag.select("li a") # 找到所有a标签
province_dict = {} # 定义字典
for item in a_tags: # 循环遍历每一个超链接
province_dict[item.string] = item["href"][2:] # 以省份为键,链接为值构建字典
province_dict.pop("海外") # 删除不需要的记录
return province_dict # 返回结果
def get_schools_by_province(url): # 获取某个省份的所有学校信息
temp_content = get_text(url) # 请求网页,得到网页源代码
b_soup = BeautifulSoup(temp_content, "html.parser") # 构建BeautifulSoup对象
a_tags = b_soup.select("ul.l4 li a") # 获取所有的学校超链接
schools = [] # 定义列表,保存该省份所有的学校
for item in a_tags: # 循环遍历每一个标签
schools.append(item.string) # 获取标签内容即学校信息
return schools # 返回学校信息
if __name__ == '__main__':
index_url = "https://daxue.911cha.com/" # 起始页网址
content = get_text(index_url) # 请求网页获取源代码
provinces = parse_province(content) # 获取省份及其链接
with open("schools.txt", mode="w", encoding="utf-8") as fp: # 保存到文件
for key, value in provinces.items():
print("当前解析的省份为:", key, index_url + value)
school_list = get_schools_by_province(index_url + value) # 获取某个省份的院校列表
for school in school_list:
fp.write(",".join([school, key]) + "\n") # 保存学校、省份信息,单独占一行
完整的课件下载网址:Python网络爬虫课件(含多个实例)-Python文档类资源-CSDN下载

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











