







什么是后缀数组啊~就是把一个字符串的所有后缀字串排个序的数组。
以下摘自《后缀数组——处理字符串的有力工具》罗穗骞
后缀数组:后缀数组SA是一个一维数组,它保存1..n的某个排列SA[1],
SA[2],……,SA[n],并且保证Suffix(SA[i])<Suffix(SA[i+1]),1≤i<n。
也就是将S的n个后缀从小到大进行排序之后把排好序的后缀的开头位置顺次放入SA中。
名次数组:名次数组Rank[i]保存的是Suffix(i)在所有后缀中从小到大排列的“名次”。
简单的说,后缀数组是“排第几的是谁?”,名次数组是“你排第几?”。容易看出,后缀数组和名次数组为互逆运算。
怎么比较一个字符串:
每一位按字典序比较……简单易懂。
硬做的时间复杂度是多少呢……假设字符串长n,那么快排是 O(nlog(n)) ,字符串两两比较大小是n,也就是 O(n2log(n)) ……
水平不够,接下来就只讲学到的倍增算法。
规定:
sa[i]表示排名为i的后缀是第几个后缀
rank[i]表示第i个后缀排名第几
显然,这两个数组是对偶的,我们可以通过这样一个for循环实现转换
for (i = 1; i <= n; i++) rank[ sa[i] ] = i;
那么什么是倍增算法呢?首先你要知道倍增就是1、2、4、8、16…这样的,然后这个算法就是按照这个顺序下去,求出长度为 2k 的字串的排序,从而实现后缀的排序。
以下摘自《后缀数组——处理字符串的有力工具》罗穗骞
k从0开始,每次加1,当2k大于n以后,每个字符开始的长度为2k的子字符串便相当于所有的后缀。并且这些子字符串都一定已经比较出大小,即rank值中没有相同的值,那么此时的rank值就是最后的结果。每一次排序都利用上次长度为2k-1的字符串的rank值,那么长度为2k的字符串就可以用两个长度为2k-1的字符串的排名作为关键字表示,然后进行基数排序,便得出了长度为2k的字符串的rank值。
举个栗子:
(以下二元组表示(rank[i],rank[i+k]))
S=”aabaaaab”
当k=0,
rank[]=1 1 2 1 1 1 1 2
当k=1,
我们得到的字串是:
aa,ab,ba,aa,aa,aa,ab,b\0
写成二元组可以是:
(1,1)(1,2)(2,1)(1,1)(1,1)(1,1)(1,2)(2,0)
rank[]=1 2 4 1 1 1 2 3
当k=2,
我们得到的字串是…
写成二元组可以是:
(1,4)(2,1)(4,1)(1,1)(1,2)(1,3)(2,0)(3,0)
rank[]=4 6 8 1 2 3 5 7
此时已经将八个后缀全部分出顺序,可以结束算法。
那么这里涉及到双关键字排序,怎么排序呢?用快排显然是
O(nlogn)
的,还能不能更快呢?
好像可以用基数排序……
多关键字的基数排序,我们从后面的关键字开始排,然后只需保持排序的稳定性,即可实现多关键字排序。
在这里,第二关键字排序的结果可以直接从上一阶段的sa数组获得。
接下来图片讲解……

这个二元组是已经按第一关键字排了一遍了,那么我们要让它得出最后结果,首先如图,很容易懂。
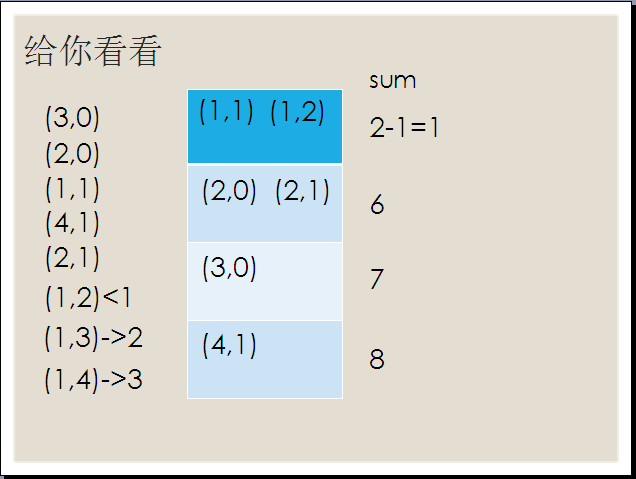
然后像这样从下往上推……你懂的……

显然最后是这样的,这样基数排序就完成了。
倍增算法最多需要进行logn次排序。
使用基数排序,就可以在线性时间内完成一次排序。
因此,总的时间复杂度
O(nlogn)
模板代码:
const int N = int(2e5)+10;
int cmp(int *r,int a,int b,int l){
return (r[a]==r[b]) && (r[a+l]==r[b+l]);
}
// 用于比较第一关键字与第二关键字,
// 比较特殊的地方是,预处理的时候,r[n]=0(小于前面出现过的字符)
int wa[N],wb[N],ws[N],wv[N];
int rank[N],height[N];
void DA(int *r,int *sa,int n,int m){ //此处N比输入的N要多1,为人工添加的一个字符,用于避免CMP时越界
int i,j,p,*x=wa,*y=wb,*t;
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[x[i]=r[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) sa[--ws[x[i]]]=i; //预处理长度为1
for(j=1,p=1;p<n;j*=2,m=p) //通过已经求出的长度J的SA,来求2*J的SA
{
for(p=0,i=n-j;i<n;i++) y[p++]=i; // 特殊处理没有第二关键字的
for(i=0;i<n;i++) if(sa[i]>=j) y[p++]=sa[i]-j; //利用长度J的,按第二关键字排序
for(i=0;i<n;i++) wv[i]=x[y[i]];
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[wv[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) sa[--ws[wv[i]]]=y[i]; //基数排序部分
for(t=x,x=y,y=t,p=1,x[sa[0]]=0,i=1;i<n;i++)
x[sa[i]]=cmp(y,sa[i-1],sa[i],j)?p-1:p++; //更新名次数组x[],注意判定相同的
}
}
void calheight(int *r,int *sa,int n){ // 此处N为实际长度
int i,j,k=0; // height[]的合法范围为 1-N, 其中0是结尾加入的字符
for(i=1;i<=n;i++) rank[sa[i]]=i; // 根据SA求RANK
for(i=0;i<n; height[rank[i++]] = k ) // 定义:h[i] = height[ rank[i] ]
for(k?k--:0,j=sa[rank[i]-1]; r[i+k]==r[j+k]; k++); //根据 h[i] >= h[i-1]-1 来优化计算height过程
}
char str[N];
int sa[N];
int main(){
char str[N];
scanf("%s",str);
int n = strlen(str);
str[n]=0;
da(str,sa,n+1,128); //注意区分此处为n+1,因为添加了一个结尾字符用于区别比较
calheight(str,sa,n);
}还有一种dc3,然而我并不懂,只知道是
O(n)
,然而常数特别大。
模板代码:
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<cmath>
#include<vector>
#include<algorithm>
using namespace std;
const int maxn = int(3e6)+10;
const int N = maxn;
#define F(x) ((x)/3+((x)%3==1?0:tb))
#define G(x) ((x)<tb?(x)*3+1:((x)-tb)*3+2)
int wa[maxn],wb[maxn],wv[maxn],ws[maxn];
int c0(int *r,int a,int b)
{return r[a]==r[b]&&r[a+1]==r[b+1]&&r[a+2]==r[b+2];}
int c12(int k,int *r,int a,int b)
{if(k==2) return r[a]<r[b]||r[a]==r[b]&&c12(1,r,a+1,b+1);
else return r[a]<r[b]||r[a]==r[b]&&wv[a+1]<wv[b+1];}
void sort(int *r,int *a,int *b,int n,int m)
{
int i;
for(i=0;i<n;i++) wv[i]=r[a[i]];
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[wv[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) b[--ws[wv[i]]]=a[i];
return;
}
void dc3(int *r,int *sa,int n,int m) //涵义与DA 相同
{
int i,j,*rn=r+n,*san=sa+n,ta=0,tb=(n+1)/3,tbc=0,p;
r[n]=r[n+1]=0;
for(i=0;i<n;i++) if(i%3!=0) wa[tbc++]=i;
sort(r+2,wa,wb,tbc,m);
sort(r+1,wb,wa,tbc,m);
sort(r,wa,wb,tbc,m);
for(p=1,rn[F(wb[0])]=0,i=1;i<tbc;i++)
rn[F(wb[i])]=c0(r,wb[i-1],wb[i])?p-1:p++;
if(p<tbc) dc3(rn,san,tbc,p);
else for(i=0;i<tbc;i++) san[rn[i]]=i;
for(i=0;i<tbc;i++) if(san[i]<tb) wb[ta++]=san[i]*3;
if(n%3==1) wb[ta++]=n-1;
sort(r,wb,wa,ta,m);
for(i=0;i<tbc;i++) wv[wb[i]=G(san[i])]=i;
for(i=0,j=0,p=0;i<ta && j<tbc;p++)
sa[p]=c12(wb[j]%3,r,wa[i],wb[j])?wa[i++]:wb[j++];
for(;i<ta;p++) sa[p]=wa[i++];
for(;j<tbc;p++) sa[p]=wb[j++];
return;
}好了,那么后缀数组有个卵子什么用呢?
在后缀排完序以后,可以求出相邻排名的两个后缀的最长公共前缀,然后任何两个后缀的最长公共前缀
就转化为rmq问题了。
那么怎么求最长公共前缀呢?
注意到如果两个后缀A和B的最长公共前缀长度为x,那么A和B各自去掉开头一位的后缀C和D,它们的最长公共前缀长度就是x-1也就是说,如果后缀A和其前一名B的最长公共前缀为x (x>0) ,那么后缀A去掉开头一位的后缀C和C的前一名D,它们的最长公共前缀至少是x-1。
也就是说我们可以先处理原串S[0..n-1]和其前一名的最长公共前缀,然后再算A[1..n-1]和其前一名的最长公共前缀…
时间复杂度显然是 O(n) ,代码:
k=0;
for (i=0;i<n;i++)
{
if (k>0) k--;
j=sa[rank[i]-1];
while (st[i+k]==st[j+k]) k++;
height[rank[i]]=k;
}
据说后缀数组能做很多事情,然而我并不会,那么先这样了。















 100
100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









